 Ciro Santilli
Ciro SantilliBig goals:
- the pursuit of AGI
- physics simulations, including scientific visualization software
- formalization of mathematics
Just art:
- useless mathy stuff
- incredibly nifty little tools that are just so satisfying to use it is mind blowing:
- media related stuff
- FFmpeg one liners!
Examples under cmake:
- cmake/hello: just print a message in CMake itself and exit. No compilation.
- cmake/hello_c: C hello world
- cmake/option:
set()andoption()basic examples - cmake/multi_executable
- cmake/multi_file
- cmake/multi_file_recursive
- cmake/shared_lib_external
Some linker related answers by Ciro Santilli:
Not possible it seems:
We use the term "automatic programming" to mean "generating code from natural language".
The ultimate high level of which is of course to program with:which is basically the goal of artificial general intelligence, especially according to The Employment Test definition of AGI.
computer, make money
The term has not always had that sense:sums it up.
automatic programming has always been a euphemism for programming in a higher-level language than was then available to the programmer
But in the current AI boom, this is the sense that matters, so that's what we will go with.
Bibliography:
- OpenAI's GPT-4-turbo can generate and run Python code if it detects that the prompt would be better answered by Python, e.g. maths
Whitepaper: storage.googleapis.com/deepmind-media/DeepMind.com/Blog/alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorithms/AlphaEvolve.pdf
Basically they require users to hand-code a metric and provide a program skeleton with some parts of the code marked to be replaced, and then the system focuses on modifying the code regions in question to optimize the metric.
All the novel results they announced were in constraint satisfaction problems or optimization problem. Their results are still awesome, but it's not very different from AlphaGo style things.
Bibliography:
Appears to be a very small number of newly created problems?
The tests are present in a gzip inside the Git repo: github.com/openai/human-eval/blob/master/data/HumanEval.jsonl.gz These researchers.
To get a quick overview of the problems with jq:
jq -r '"==== \(.task_id) \(.entry_point)\n\(.prompt)"' <HumanEval.jsonl The first two problems are:so we understand that it takes as input an empty function with a docstring and you have to fill the function body.
==== HumanEval/0 has_close_elements
from typing import List
def has_close_elements(numbers: List[float], threshold: float) -> bool:
""" Check if in given list of numbers, are any two numbers closer to each other than
given threshold.
>>> has_close_elements([1.0, 2.0, 3.0], 0.5)
False
>>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)
True
"""
==== HumanEval/1 separate_paren_groups
from typing import List
def separate_paren_groups(paren_string: str) -> List[str]:
""" Input to this function is a string containing multiple groups of nested parentheses. Your goal is to
separate those group into separate strings and return the list of those.
Separate groups are balanced (each open brace is properly closed) and not nested within each other
Ignore any spaces in the input string.
>>> separate_paren_groups('( ) (( )) (( )( ))')
['()', '(())', '(()())']
"""The paper also shows that there can be other defined functions besides the one you have to implement.
This one focuses on improving speed of important numerical algorithms as compared to popular implementations.
The general pattern can be seen by observing the optimization of: algotune.io/aes_gcm_encryption_anthropic_claude-opus-4-1-20250805.html This shows the chat that the system had.
They define an OS interface to edit files and run right on the prompt, and tell at each stage how many credits are left for a given API and what the speedup was. Amazing. Each task has a $1 budget per provider. Then their software parses commands out of the LLM output and sends formatted responses back. Quite amazing that it works at all.
All pieces of code seem to be in Python, and the speedups come mainly from using more advanced external computing libraries, like compiling with Cython or using faster external libraries that are pre-compiled, or more parallel. So it is not that impressive from a purely algorithmic point of view, but it is not bad either.
Correctness is checked automatically by comparing the optimized solution to the original non-optimized one likely for certain inputs.
Their most interesting subset, the
-hard one, appears to be present at: huggingface.co/datasets/bigcode/bigcodebench-hard in Parquet format. OMG why.The tests make free usage of the Python standard library and other major external libraries, e.g. huggingface.co/datasets/bigcode/bigcodebench-hard/viewer/default/v0.1.0_hf?views%5B%5D=v010_hf&row=0 uses FTPlib. Kind of cool.
They even test graph plotting? huggingface.co/datasets/bigcode/bigcodebench-hard/viewer/default/v0.1.0_hf?views%5B%5D=v010_hf&row=11 How does it evaluate?
By Princeton people.
This one aims to solve GitHub issues. It appears to contain 2,294 real-world GitHub issues and their corresponding pull requests.
Evaluation is simply based on "does the pull request make some pre-written failing test cases pass".
The dataset appears to be at: huggingface.co/datasets/princeton-nlp/SWE-bench in Parquet format.
Tasks from Upwork.
Lowering means translating to a lower level representation.
Raising means translating to a higher level representation.
Decompilation is basically a synonym, or subset, of raising.
Tagged
Saves preprocessor output and generated assembly to separate files.
- preprocessor:
- assembly:
Very hot stuff! It's like ISA-portable assembly, but with types! In particular it also it deals with calling conventions for us (since it is ISA-portable). TODO: isn't that exactly what C does? :-) LLVM IR vs C
Documentation: llvm.org/docs/LangRef.html
Example: llvm/hello.ll adapted from: llvm.org/docs/LangRef.html#module-structure but without double newline.
To execute it as mentioned at github.com/dfellis/llvm-hello-world we can either use their crazy assembly interpreter, tested on Ubuntu 22.10:This seems to use
sudo apt install llvm-runtime
lli hello.llputs from the C standard library.Or we can Lower it to assembly of the local machine:which produces:and then we can assemble link and run with gcc:or with clang:
sudo apt install llvm
llc hello.llhello.sgcc -o hello.out hello.s -no-pie
./hello.outclang -o hello.out hello.s -no-pie
./hello.outhello.s uses the GNU GAS format, which clang is highly compatible with, so both should work in general.Reproducible builds allow anyone to verify that a binary large object contains what it claims to contain!
Bibliography:
Survey by Ciro Santilli: math.stackexchange.com/questions/1985/software-for-drawing-geometry-diagrams/3938216#3938216
Many plotting software can be used to create mathematics illustrations. They just tend to have more data-oriented rather than explanatory-oriented output.
Tagged
Tagged
Ciro Santilli has some good related articles listed under: the best articles by Ciro Articles.
Tagged
Good library to render text in OpenGL, see also: stackoverflow.com/questions/8847899/opengl-how-to-draw-text-using-only-opengl-methods/36065835#36065835
The fact that they kept the standard open source makes them huge heroes, see also: closed standard.
Shame that many (most?) of their proposals just die out.
Good modern OpenGL tutorial in retained mode with shaders, see also: stackoverflow.com/questions/6733934/what-does-immediate-mode-mean-in-opengl/36166310#36166310
Examples at: two-js/.
Feels good. Maybe not ultra featured, and could have more simple examples in docs, but still good.
One of the main features of Two.js appears to be the fact that it can natively render to either SVG and canvas, rather than creating SVG through DOM hacks as done by other projects.
One specific software project, typically with a single executable file format entry point.
As mentioned at Section "Computer security researcher", Ciro Santilli really tends to like people from this area.
Also, the type of programming Ciro used to do, systems programming, is particularly useful to security researchers, e.g. Linux Kernel Module Cheat.
The reason he does not go into this is that Ciro would rather fight against the more eternal laws of physics rather than with some typo some dude at Apple did last week and which will be patched in a month.
Ciro Santilli found out that he likes computer security researchers and vice versa.
It's a bit the same reason why he likes physicists: you can't bullshit with security.
You can't just talk nice and hope for people to belive you.
You can't not try to break things and just keep everyone happy in their false illusion of safety.
You can't do a half job.
If you do any of that, you will get your ass handed to you in a little gift bag.
All of this is closely linked to Ciro Santilli's self perceived creative personality and being naughty and creative are correlated.
A superstar security researcher with some major exploits from in the 2000's.
Oh yeah, that felt good. A few months before he died.
Tagged
Ermm, as of February 2021, I was able to update my 2FA app token with the password alone, it did not ask for the old 2FA.
So what's the fucking point of 2FA then? An attacker with my password would be able to login by doing that!
Is it that Google trusts that particular action because I used the same phone/known IP or something like that?
The fatal flaw of OAuth is that websites have to enable specific providers, they can't just automatically select the correct OAuth for a given email domain. This means that the vast majority of websites will only provide the most widely popular providers such as Google, and the like, which means people won't have decent privacy.
So you are just better off with password logins and a decent password manager.
A cross browser, cross platform, and server-encrypted password manager is a must after Snowden!!! E.g. Proton Pass. And governments should obviously provide one to its citizens, or else be spied upon by the USA obviously: Governments should provide basic Internet infrastructure.
Tagged
Do as I say, not as I do: Ciro Santilli's Stack Overflow suspension for vote fraud script 2019, meta.stackoverflow.com/questions/381577/is-it-ok-to-have-links-on-how-to-create-sock-puppets-and-gain-rep-fraudulently-i/381635#381635.
LockPickingLawyer SAINTCON keynote (2021)
Source. SAINTCON is "Utah's Premiere Security Conference".- youtu.be/IH0GXWQDk0Q?t=900 mentions that Alfred Charles Hobbs commented in 1853:
Rogues are very keen in their profession, and know already much more than we can teach them
Basically the opposite of security through obscurity, though slightly more focused on cryptography.
Tagged
This is really good.
It allows the client to prepare a single request that gets all the data it wants to fill up a given webpage, rather than doing several separate requests.
So it only gets exactly what it needs, and in a single request.
Very sweet. This is the future of the web.
- no formatting;
- stackoverflow.com/questions/2614764/how-to-create-a-hex-dump-of-file-containing-only-the-hex-characters-without-spac
- unix.stackexchange.com/questions/10826/shell-how-to-read-the-bytes-of-a-binary-file-and-print-as-hexadecimal/758531#758531
- stackoverflow.com/questions/2003803/show-hexadecimal-numbers-of-a-file/77262369#77262369
- stackoverflow.com/questions/9515007/linux-script-to-convert-byte-data-into-a-hex-string/77262375#77262375
This pattern works well:Then stdout will contain only the output of the command and nothing else.
set prompt ">>> "
log_user 0
send "What is quantum field theory?\r"
expect -re "(.+)$prompt"
puts -nonewline [join [lrange [lmap line [split $expect_out(1,string) \n] {regsub {\r$} $line ""}] 1 end] "\n"]Bibliography:
- unix.stackexchange.com/questions/239161/get-the-output-from-expect-script-in-a-variable/792645#792645
- stackoverflow.com/questions/45210358/expect-output-only-stdout-of-the-command-and-nothing-else/79517903#79517903
- stackoverflow.com/questions/57975853/how-to-read-the-send-command-output-in-expect-script title is wrong, OP wants exit status apparently not stdout
The author Ole Tange answers every question about it on Stack Exchange. What a legend!
This program makes you respect GNU make a bit more. Good old make with
-j can not only parallelize, but also take in account a dependency graph.Some examples under:
man parallel_exampesTo get the input argument explicitly job number use the magic string sample output:
{}, e.g.:printf 'a\nb\nc\n' | parallel echo '{}'a
b
cTo get the job number use sample output:
{#} as in:printf 'a\nb\nc\n' | parallel echo '{} {#}'a 1
b 2
c 3
c 3{%} contains which thread the job running in, e.g. if we limit it to 2 threads with -j2:printf 'a\nb\nc\nd\n' | parallel -j2 echo '{} {#} {%}'a 1 1
b 2 1
c 3 2
d 4 1% symbol in many programming languages such as C.To pass multiple CLI arguments per command you can use sample output:
-X e.g.:printf 'a\nb\nc\nd\n' | parallel -j2 -X echo '{} {#} {%}'a b 1 1
c d 2 2Way too few people know about this. Spread the word.

Tagged
Check which you you have:Tested on Ubuntu 23.10 I see:which means I have GNOME Display Manager.
systemctl status display-manager.service● gdm.service - GNOME Display Manager
Loaded: loaded (/lib/systemd/system/gdm.service; static)
Active: active (running) since Sun 2023-12-24 10:34:50 GMT; 23min ago
Process: 1827 ExecStartPre=/usr/share/gdm/generate-config (code=exited, status=0/SUCCESS)
Main PID: 1850 (gdm3)
Tasks: 4 (limit: 71817)
Memory: 6.8M
CPU: 119ms
CGroup: /system.slice/gdm.service
└─1850 /usr/sbin/gdm3Bibliography:
Tagged
Tagged
A software that implements some database system, e.g. PostgreSQL or MySQL are two (widely extended) SQL implementations.
Per language:
Tagged
How to decide if an ORM is decent? Just try to replicate every SQL query from nodejs/sequelize/raw/many_to_many.js on PostgreSQL and SQLite.
There is only a very finite number of possible reasonable queries on a two table many to many relationship with a join table. A decent ORM has to be able to do them all.
If it can do all those queries, then the ORM can actually do a good subset of SQL and is decent. If not, it can't, and this will make you suffer. E.g. Sequelize v5 is such an ORM that makes you suffer.
The next thing to check are transactions.
Basically, all of those come up if you try to implement a blog hello world world such as gothinkster/realworld correctly, i.e. without unnecessary inefficiencies due to your ORM on top of underlying SQL, and dealing with concurrency.
One "LevelDB" database contains multiple file in a directory. Off the bat inferior to SQLite which stores everything in a single file!
github.com/mdawsonuk/LevelDBDumper/tree/e750a27ff58443ecc410b5c16abbdc539d617387#installation worked on Ubuntu 23.10 Annoying installation, but worked: github.com/mdawsonuk/LevelDBDumper/issues/13
Initial issues off-the-bat:
List databases:
echo 'show dbs' | mongoDelete database:or:
use mydb
db.dropDatabase()echo 'db.dropDatabase()' | mongo mydbView collections within a database:
echo 'db.getCollectionNames()' | mongo mydbShow all data from one of the collections: stackoverflow.com/questions/24985684/mongodb-show-all-contents-from-all-collections
echo 'db.collectionName.find()' | mongo mydbTested as of Ubuntu 20.04, there is no Mongo package available by default due to their change to Server Side Public License, which Debian opposed. Therefore, you have to add their custom PPA as mentioned at: docs.mongodb.com/manual/tutorial/install-mongodb-on-ubuntu/
This means that e.g. if you do an
UPDATE query on multiple rows, and power goes out half way, either all update, or none update.This is different from isolation, which considers instead what can or cannot happen when multiple queries are running in parallel.
Determines what can or cannot happen when multiple queries are running in parallel.
See Section "SQL transaction isolation level" for the most common context under which this is discussed: SQL.
Tagged
Tagged
Ciro Santilli used to use file managers in the past.
But he finally converted to a shell
cd aliases that auto-ls: github.com/cirosantilli/dotfiles/blob/a51bcc324f0cff0eddd4c3bb8654ec223a0adb7b/home/.bashrc#L1058The most powerful GUI file manager ever?? Infinite configurability??
Ciro Santilli wasted some time on it before he gave up on file managers altogether and started using only the CLI with a few aliases.
Ciro Santilli considered it before he stopped using file managers altogether, it is not bad.
A library to make games.
Tagged
Ciro Santilli considered this as the basis for Ciro's 2D reinforcement learning games, but ultimately decided it was a bit too messy. Nice overall though.
The one true game engine!
Tagged
Their project lead as of 2018 was pro-CCP: github.com/cirosantilli/china-dictatorship/blob/aa1176c57fc2929465294e520b43b50d44e202ba/communities-that-censor-politics.md
Originally by Keyhole Inc., which the nbecame Google Maps, but the format seems standardized and has non-Google support, so should be OK.
Owned/developed by Google as of 2020.
Early on jumpstarted from several acquisitions, notably Keyhole Inc. and Where 2 Technologies.
Street View's go into the past mode is the dream of every archaeologist. Ciro can only dream of a magic street view that allows going back to earlier centuries and beyond... isn't it amazing to think that people in the future will have that ability to time travel back to around the year 2006? Ciro wonders how long Google will be able to keep storing data like that.
Thanks, CIA.
It is rare to find a project with such a ridiculously high importance over funding ratio.
E.g., as of 2020, their help login help.openstreetmap.org/ shows MyOpenID as an option, which was discontinued in 2014, and not Google OAuth.
They do still seem to have a bit more activity than gis.stackexchange.com/questions/tagged/openstreetmap on Stack Exchange.
Complaints:
- Transliteration is off by default!...... wiki.openstreetmap.org/wiki/Translation You just have to learn all scripts ever. Good luck with the Chinese characters. Genius.
- In order to see information about places, you have to click "Query features" on the toolbar first. Who made such a terrible UI? Direct click is a much, and so easy to implement?
- It is impossible to discern different types of paths and other walking path symbols, the symbols are too small, and just scale down to a line no matter how much you zoom in.
- Power lines are way too visible. While that is kind of cool, it is useless and distracting to most people most of the time.
- No street-level imagery...: help.openstreetmap.org/questions/1178/adding-photos
- No aerial imagery: help.openstreetmap.org/questions/6849/how-can-i-see-the-aerial-imagery-without-editing-the-map But that is kind of understandable, as that one might not be free.
- No restaurant ratings: help.openstreetmap.org/questions/64852/ratings-for-pois because it is "Subjective". OMG those people, such a huge value powerhouse wasted.Not just for restaurants, but for other things as well, e.g. sharing of good cycle circuits.
All of this is a shame, because they do have some incredible data that you cannot find easily on other maps because people just edited it up.
Kind of works! Notably, has the amazing cycling database offline for you, if you fall within the 6 area downloads. It is worth supporting these people beyond the 6 free downloads however.
Has some of the best map data available for the United Kingdom, but their data appears to be proprietary?
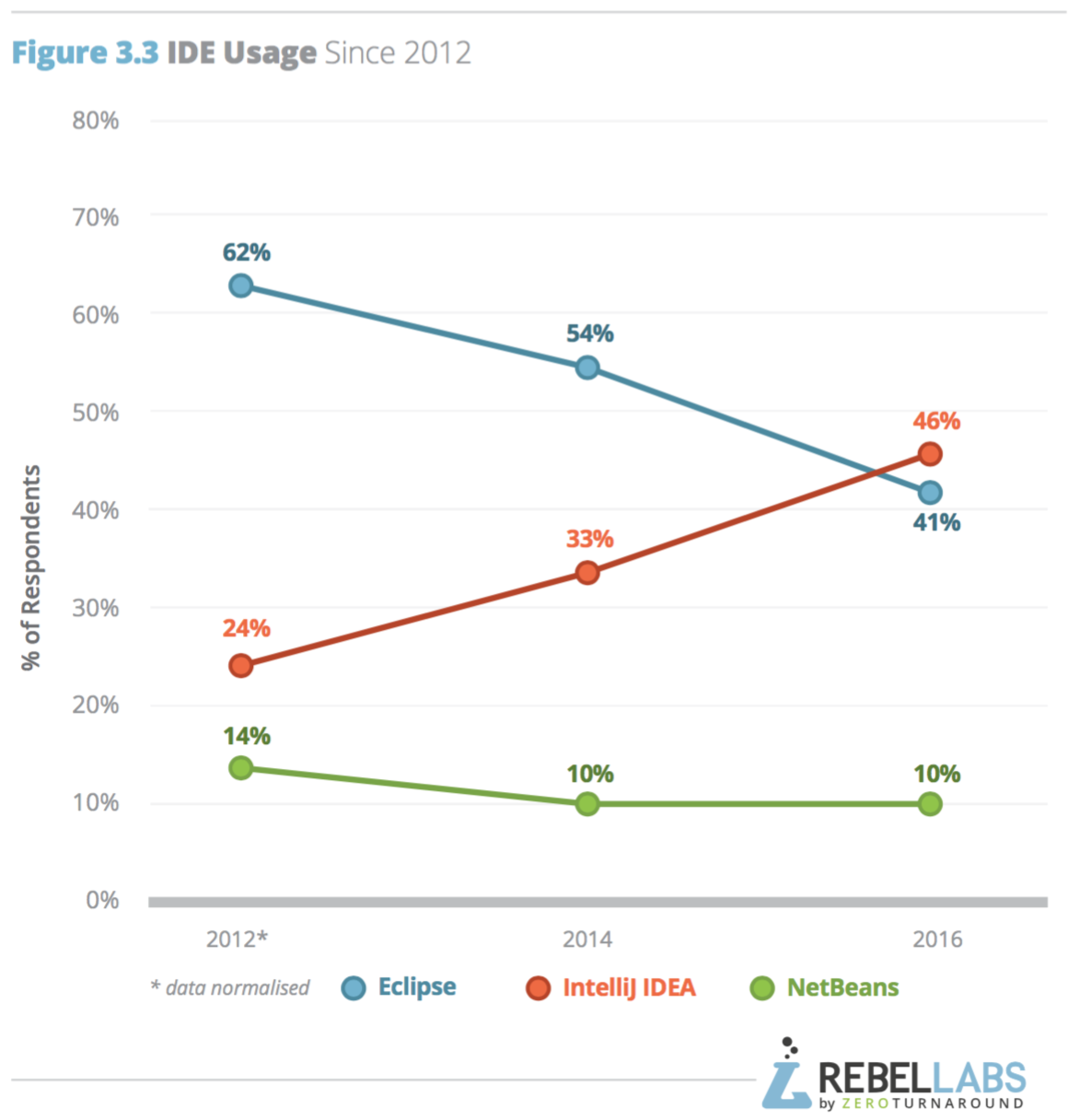
IDEs are absolutely essential for developing complex software.
The funny thing is that you don't notice this until someone shows it to you. But once you see it, there is not turning back, just like Steve Jobs customers don't know what they want quote.
Unfortunately, after the Fall of Eclipse (archive), the IDE landscape in 2019 is horrible and split between:
Programmers of the world: unite! Focus on one IDE, and make it work for all languages and all build systems. Give it all the features that Eclipse has, but none of the bugginess. Work with top project to make sure the IDE works for all top projects.
Projects of the world: support one IDE, with in-tree configuration. Complex integration is often required between the IDE and the build system, and successful projects must to that once for all developers. Either do this, or watch you complex project wither away.
Build tool maintainers: make it possible for IDEs to support your tool! E.g., implement JSON Compilation Database output so that IDEs can read the exact compiler commands from that, in order to automatically determine how files should be parsed! Or better, just use libllvm in your IDE itself as the main parser.
Ciro is evaluating some IDEs at: github.com/cirosantilli/ide-test-projects
Tagged
However also at the same time very limited integration with vscode, that makes using it for VScode compatibility almost useless, e.g.:
- you can't reuse the syntax defintions!
Before we get a decent open source integrated development environment, what else can you do?
But also perfect for small one-off files when you don't have the patience to setup said IDE.
vim's defaults are atrocious for the 21st century! Vundle is reasonable as an ad-hoc package manager, but it can't set fixed versions of packages:
Vimscript unit testing!!!
Ciro Santilli contributed a bit to this, and was even given push rights, see also: see also: Ciro Santilli's minor projects.
Since you can't escape shitty browser GUIs and live in the command line, the next best thing you can do is to bring Vim bindings to your browser :-)
There is one major annoyance: you can't use ESC to leave the address bar focus, but using Tab as a workaround works:
Once upon a time (early 2010's), Eclipse dominated the IDE landscape and all was good. NetBeans was around too. And Java was still unmarred by Google LLC v. Oracle America, Inc..
But then something happened.
For some reason, Eclipse started to decay.
And the project that had once been a vibrant community of awesomeness, started to become... a zombie of its former self.
Buggyness started increasing. And not even hard to fix bugs. One liners that affect every user immediately after startup.
Sometimes, to Eclipse's defense they weren't "bugs". Just features that it became evident with time every programmer expected from a modern IDE.
But somehow the Eclipse community had a deep problem. A cancer. It had completely lost touch with user experience.
Perhaps is was due to the increasing interest of the several corporations that had adopted Eclipse as the base IDE for the proprietary solutions?
Perhaps.
Many users stuck to the IDE.
Some heroic efforts were made as plugins that drastically improved certain defects. The Darkest Dark plugin comes to mind.
But all those efforts required configuration. A setup time that most users simply don't have. The core devteam had become dumb and dead, unable to incorporate such changes.
This greatly opened up the space for other competing IDEs to come along. The "semi feature complete but at least easy to use and not so buggy" Visual Studio Code and the proprietary JetBrains IDEs being some of the most notable ones.
Using Eclipse as of the early 2020's is such a mixed experience. If you spend enough time to configure out the key buggyness, there are moments where you can feel "OMG, this feature is amazing".
But the effort is just too great, and soon another bug or obvious missing feature hits you and brings you back to reality.
Every young person uses VS Code now. Eclipse is dead, and there is no way back, usage will just continue dropping.
RIP, Eclipse. It wasn't meant to be.
Bibliography:
snap vscode 1.100.2, Ubuntu 25.04
The issue appears to be that the file watcher goes out of control.
The reproduction is very simple:and now the editor GUI hangs and Ubuntu shows a popup:
mkdir mytest
cd mytest
seq 1000000 | xargs touch
code --disable-extensions .The window is not responding
htop reveals a bunch of processes or threads of type:
/snap/code/194/usr/share/code/codeInfinite duplicate pool:
Persistent undo history:
undois broken beyond belief: github.com/VSCodeVim/Vim/issues/1490
It is especially bad on large projects, unless you carefully whitelist only the small source directories:
Having multiple windows is generally the only sane way to manage multiple projects. So how to reopen then after you:
- restart the OS or logout?
- close all window in some other way? It can't be by closing them one by one of course, or else only the last remains. Not sure such way exists.
FFmpeg is the assembler of audio and video.
As a result, Ciro Santilli who likes "lower level stuff", has had many many hours if image manipulation fun with this software, see e.g.:
- the "Media" section of the best articles by Ciro Articles.
- Figure "Ciro knows how to convert videos to GIFs"
As older Ciro grows, the more he notices that FFmpeg can do basically any lower level audio video task. It is just an amazing piece of software, the immediate go-to for any low level operation.
FFmpeg was created by Fabrice Bellard, which Ciro deeply respects.
Resize a video: superuser.com/questions/624563/how-to-resize-a-video-to-make-it-smaller-with-ffmpeg:Unlike every other convention under the sun, the height in
ffmpeg -i input.avi -filter:v scale=720:-1 -c:a copy output.mkvscale is the first number.Filter graphs are a thing of great beauty. What an amazingly obscure domain-specific language, but which can produce striking results with very little!!!
A quick example from stackoverflow.com/questions/59551013/how-to-generate-stereo-sine-wave-using-ffmpeg-with-different-frequencies-for-eac/77730492#77730492 illustrates some of the fundamentals:
ffplay -autoexit -nodisp -f lavfi -i '
sine=frequency=500[a];
sine=frequency=1000[b];
[a][b]amerge, atrim=end=2
' +--------+
[sine=frequency=500]--->[a]-->| |
| amerge |-->[atrim]-->[output]
[sine=frequency=1000]-->[b]-->| |
+--------+So we see the following syntax patterns:
sine,amergeandatrimare filterssine=frequency=500: the first=says "araguments follow"frequency=500sets thefrequencyargument of thesinefilter- for multiple arguments the syntax is to separate arguments with colons e.g.
sine=frequency=500:duration=2
;: separates statements[a],[b]: sets the name of an edge,: creates unnamed edge between filters that have one input and one output
A list of all filters can be obtained ith:and parameters for a single filter can be obtained with:Related question: stackoverflow.com/questions/69251087/in-ffmpeg-command-line-how-to-show-all-filter-settings-and-their-parameters-bef
ffmpeg -filtersffmpeg --help filter=sineTODO dump graph to ASCII art? trac.ffmpeg.org/wiki/FilteringGuide#Visualizingfilters mentions a
-dumpgraph option, but haven't managed to use it yet.Bibliography:
- ffmpeg.org/ffmpeg-filters.html official documentation
- trac.ffmpeg.org/wiki/FilteringGuide some handy tips from the FFMpeg Wiki
Awesome tool to view quick stuff quickly without generating files. Unfortunately it doesn't support all options that the ffmpeg CLI supports, e.g. ffplay multiple input files. One day, one day.
TODO possible? superuser.com/questions/559768/ffplay-how-to-play-together-separate-video-and-audio-files
For synthesized streams like but it does not seem to accept multiple fails with:
sine we can do it e.g.ffplay -autoexit -nodisp -f lavfi -i '
sine=frequency=500[a];
sine=frequency=1000[b];
[a][b]amerge, atrim=end=2
'-i for some reason. So is there a way to open a file from some filter? E.g.:ffplay -i tmp.wav -i tmp.mkv -filter_complex "[0:a]atrim=end=2[a];[1:v]trim=end=2[v]" -map '[a]' -map '[v]'Argument 'tmp.mkv' provided as input filename, but 'tmp.wav' was already specified.Simple sines and variants:
- unix.stackexchange.com/questions/82112/stereo-tone-generator-for-linux/536860#536860
- stackoverflow.com/questions/5109038/linux-sine-wave-audio-generator/57610684#57610684
- superuser.com/questions/724391/how-to-generate-a-sine-wave-with-ffmpeg
- stackoverflow.com/questions/59551013/how-to-generate-stereo-sine-wave-using-ffmpeg-with-different-frequencies-for-eac/77730492#77730492
2 second 1000 Hz:
ffmpeg -f lavfi -i "sine=f=1000:d=2" out.wavVideo with a solid color:
- 2 second white video:Also add some audio:
ffplay -autoexit -f lavfi -i 'color=white:640x480:d=3,format=rgb24,trim=end=2'TODO how to ffplay the video + audio directly?ffmpeg -lavfi "color=white:640x480:d=3,format=rgb24,trim=end=2[v];sine=f=1000:d=2[a]" -map '[a]' -map '[v]' out.mkv-mapdoes not seem to work unfortunately. - 2 second white followed by 2 second black video:
ffplay -autoexit -f lavfi -i 'color=white:640x480:d=3,format=rgb24,trim=end=2[a];color=black:640x480:d=3,format=rgb24,trim=end=2[b];[a][b]concat=n=2:v=1:a=0' - bibliography:
Display count in seconds on the video:
- black text on white background. Start from 0 and count up to 2:
ffplay -autoexit -f lavfi -i " color=white:480x480:d=3, format=rgb24, drawtext= fontcolor=black: fontsize=600: text='%{eif\:t\:d}': x=(w-text_w)/2: y=(h-text_h)/2 " - count 0 to 2 with one different sine wave per count:
ffmpeg -lavfi " color=white:480x480:d=3, format=rgb24, drawtext= fontcolor=black: fontsize=600: text='%{eif\:t\:d}': x=(w-text_w)/2: y=(h-text_h)/2[v]; sine=f=500:d=1[a1]; sine=f=1000:d=1[a2]; sine=f=2000:d=1[a3]; [a1][a2][a3]concat=n=3:v=0:a=1[a]; " -map '[v]' -map '[a]' count.mkv - bibliography:
Bibliography:
- ffmpeg.org//ffmpeg-filters.html#Video-Sources main section of the documentation listing various video generators
- stackoverflow.com/questions/11640458/how-can-i-generate-a-video-file-directly-from-an-ffmpeg-filter-with-no-actual-in generically asking how to generate the video without an input video
FFmpeg is likely the backend of YouTube through reverse engineering: streaminglearningcenter.com/blogs/youtube-uses-ffmpeg-for-encoding.html (archive)
This is a really good one to quickly browser multiple images present in a directory, and also to do some basic editing on them!
At around 2022 development by the original devs faltered a bit but some other people seem to have picked it up:
Crop
20 pixels from the bottom of the image:convert image.png -gravity East -chop 20x0 result.pngconvert -size 512x512 xc:blue blue.pngconvert -size 256x256 gradient: out.png
convert -size 256x256 gradient:white-black out.png
convert -size 256x256 gradient:red-blue out.png
convert -size 256x256 radial-gradient: out.png
convert -size 256x256 radial-gradient:white-black out.pngDigits 0 to 9, white on black background:
for i in `seq 0 9`; do convert -size 512x512 xc:black -pointsize 500 -gravity center -fill white -draw "text 0,0 \"$i\"" $i.png; doneWhat happens when the underdogs get together and try to factor out their efforts to beat some evil dominant power, sometimes victoriously.
Or when startups use the cheapest stuff available and randomly become the next big thing, and decide to keep maintaining the open stuff to get features for free from other companies, or because they are forced by the Holy GPL.
Open source frees employees. When you change jobs, a large part of the specific knowledge you acquired about closed source a project with your blood and tears goes to the trash. When companies get bought, projects get shut down, and closed source code goes to the trash. What sane non desperate person would sell their life energy into such closed source projects that could die at any moment? Working on open source is the single most important non money perk a company can have to attract the best employees.
Open source is worth more than the mere pragmatic financial value of not having to pay for software or the ability to freely add new features.
Its greatest value is perhaps the fact that it allows people study it, to appreciate the beauty of the code, and feel empowered by being able to add the features that they want.
That is why Ciro Santilli thought:
Life is too short for closed source.
But quoting Ciro's colleague S.:
Every software is open source when you read assembly code.
And "can reverse engineer the undocumented GPU hardware APIs", Ciro would add.
While software is the most developed open source technology available in the 2010's, due to the "zero cost" of copying it over the Internet, Ciro also believes that the world would benefit enormously from open source knowledge in all areas on science and engineering, for the same reasons as open source.
Tagged
Tagged
Tagged
A more precise term for those in the know: open source software that also has a liberal license, for some definition of liberal.
Ciro Santilli defines liberal as: "can be commercialized without paying anything back" (but possibly subject to other restrictions).
He therefore does not consider Creative Commons licenses with NC to be FOSS.
For the newbs, the term open source software is good enough, since most open source software is also FOSS.
But when it's not, it's crucial to know.
Tagged
This model can work well when there is a set of commonly used libraries that some developers often use together, but such that there isn't enough maintenance work for each one individually.
So what people do is to create a group that maintains all those projects, to try and get enough money to survive from the contributions done primarily for each one individually.
Examples:
Tagged
Ciro Santilli's raison d'etre, one of his attempts: OurBigBook.com.
The outcome of closed knowledge is reverse engineering.
Projects:
Not everything is perfect.
One big problem of many big open source projects is that they are contributed to by separate selfish organizations, that have private information. Then what happens is that:
- people implement the same thing twice, or one change makes the other completely unmergeable
- you get bugs but can't share your closed source test cases, and then you can't automate tests for them, or clearly demonstrate the problem
- other contributors don't see your full semi secret important motivation, and may either nitpick too much or take too long to review your stuff
Another common difficulty is that open source maintainers may simply not care enough about their own project (maybe they did in the past but lost interest) to review external patches by people they don't know.
This is understandable: a new patch, is a new risk of things breaking.
Therefore, if you ever submit patches and they get ignore, don't be too sad. It just comes down to a question of maintenance cost, and means that you will waste some extra time on the next rebase. You just have to decide your goals and be cold about it:
- are you doing the right thing and going for a specific goal backward design? Then just fork, run as fast as possible towards a minimum viable product, and if you start to feel that rebase is costing you a lot, or feel you could get some open source fame for cheap, open reviews and see what upstream says. If they ignore you, politely tell yourself in your mind silently "fuck them", and carry on with the MVP
- otherwise, e.g. you just want to randomly help out, you have to ask them before doing anything big "how can I be of help". If I propose a patch for this issue, do you promise to review it?
Writing documentation in an open source project in which you don't have immediate push rights is another major pain due to code reviews. Code code reviews tend to be much less subjective, because if you do something wrong, stuff crashes, runs slower, or you need more lines of code to reach the same goal. There are tradeoffs, but in a limited number. Documentation code reviews on the other hand, are an open invitation to infinite bike-shedding, since you can't "run" documentation through a standardized brain model. Much better is for one good documenter person to just make one cohesive Stack Overflow post, and ping others with more knowledge to review details or add any missing pieces :-)
Open source development model in which developers develop in private, and only release code to the public during releases.
Notable example project: Android Open Source Project.
This development model basically makes reporting bugs and sending patches a waste of time, because many of them will already have been solved, which is why this development model is evil.
Ciro Santilli can accept closed source on server products more easily than offline, because the servers have to be paid for somehow (by stealing your private data).
Closed source on offline products used by millions of people is evil, when you could just have those for free with open source software! Thus Ciro's hatred for Microsoft Windows and MacOS (at least userland, maybe).
Tagged
The opposite of open source software.
How the hell are you supposed to develop an open source implementation of something that has a closed standard?
Not to mention open source test suites, that would be way too much to ask for, those always end up being made by some shady small companies that go bankrupt from time to time, see e.g. .
If you are going to do closed source, at least do it like this.
Basically the opposite of need to know for software.
These people are heroes. There's nothing else to say.
Sample term usage: jax-ml.github.io/scaling-book/roofline/
Bibliography: stackoverflow.com/questions/868568/what-do-the-terms-cpu-bound-and-i-o-bound-mean/33510470#33510470
Tagged
Amazing project, that basically makes a more searchable Wayback Machine.
A bit hard to use their data though, partly due to size, but also lack of free to use querrying mechanisms, and how obtuse Amazon S3 is to use.
Notably, aws-cli with an account is the only reliable way, everything else is way too broken, e.g. trying the to check the an index index.commoncrawl.org/CC-MAIN-2023-06/ very often 500s.
But still, their projct is amazing.
The only out-of-the-box search they seem to have is: urlsearch.commoncrawl.org/ for domains/URLs. It is good, but there could be so much more... notably IPs.
Also could should document the data shape a bit better.
Sample sizes can be found at: commoncrawl.org/2023/04/mar-apr-2023-crawl-archive-now-available/
To explore the data, after login:
aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2013-20/Copy the toplevel directory only:
aws s3 cp s3://commoncrawl/crawl-data/CC-MAIN-2013-20/ . --recursive --exclude "*/*"Copy some wet/wat files:
aws s3 cp s3://commoncrawl/crawl-data/CC-MAIN-2013-20/segments/1368696381249/wat/CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.wat.gz .
aws s3 sync s3://commoncrawl/crawl-data/CC-MAIN-2013-20/segments/1368696381249/wet/CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.wet.gz .Directory structrure:
- cc-index.paths.gz (1K)
- cc-index-table.paths.gz (1K)
- segment.paths.gz (1.7K) Sample lines:
crawl-data/CC-MAIN-2013-20/segments/1368696381249/ crawl-data/CC-MAIN-2013-20/segments/1368696381630/ - index.html (2.3K)
- wat.paths.gz (98K) Sample lines:
crawl-data/CC-MAIN-2013-20/segments/1368696381249/wat/CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.wat.gz crawl-data/CC-MAIN-2013-20/segments/1368696381249/wat/CC-MAIN-20130516092621-00001-ip-10-60-113-184.ec2.internal.warc.wat.gz - wet.paths.gz (98K) Sample lines:
crawl-data/CC-MAIN-2013-20/segments/1368696381249/wet/CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.wet.gz crawl-data/CC-MAIN-2013-20/segments/1368696381249/wet/CC-MAIN-20130516092621-00001-ip-10-60-113-184.ec2.internal.warc.wet.gz - warc.paths.gz (99K)
crawl-data/CC-MAIN-2013-20/segments/1368696381249/warc/CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.gz crawl-data/CC-MAIN-2013-20/segments/1368696381249/warc/CC-MAIN-20130516092621-00001-ip-10-60-113-184.ec2.internal.warc.gz - segments: directgory with actual data
- 1368696381249: one of many segments, any meaning of name?
- CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.wet.gz (142M, 334M unzipped)A tiny bit of metadata, and then plaintext content from the website, e.g. the second one:No IP unfortunately.
WARC/1.0 WARC-Type: conversion WARC-Target-URI: http://004eeb5.netsolhost.com/stephensilver.htm WARC-Date: 2013-05-18T08:11:02Z WARC-Record-ID: <urn:uuid:773b31ba-ddc6-47a5-ae24-d08141b9944d> WARC-Refers-To: <urn:uuid:4b1bdbff-4926-4ced-86f6-072f5bb3837a> WARC-Block-Digest: sha1:LQFSCR2LIJQYMPTXRHWU7HAPQTVSYS3A Content-Type: text/plain Content-Length: 12046 Stephen Silver is a journalist and editor who specializes in the areas of politics, pop culture, film and sports. He works as an editor with the North American Publishing Co. and as a film critic with The Trend, a local newspaper in the Philadelphia area. - CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.wat.gz (329M, 1.4G unzipped)A lot of JSON metadata and no contents as desired. Contains IP! Some entries however are humongous with a ton of useless data, that's what bloats these so much:Let's beautify one of them to see it better:
WARC/1.0 WARC-Type: metadata WARC-Target-URI: CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.gz WARC-Date: 2013-11-22T14:51:12Z WARC-Record-ID: <urn:uuid:ec54e493-8965-41be-b344-07596cc30b3a> WARC-Refers-To: <urn:uuid:cfeff436-7c4c-4119-aaa4-ec2ce27ad3e1> Content-Type: application/json Content-Length: 1180 {"Envelope":{"Format":"WARC","WARC-Header-Length":"274","Block-Digest":"sha1:JCZOI4V3UOTXGIRLFMPLW4J2WPLAKGVR","Actual-Content-Length":"372","WARC-Header-Metadata":{"WARC-Type":"warcinfo","WARC-Filename":"CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.gz","WARC-Date":"2013-11-22T14:51:12Z","Content-Length":"372","WARC-Record-ID":"<urn:uuid:cfeff436-7c4c-4119-aaa4-ec2ce27ad3e1>","Content-Type":"application/warc-fields"},"Payload-Metadata":{"Trailing-Slop-Length":"0","Actual-Content-Type":"application/warc-fields","Actual-Content-Length":"372","Headers-Corrupt":true,"WARC-Info-Metadata":{"robots":"classic","software":"Nutch 1.6 (CC)/CC WarcExport 1.0","description":"Wide crawl of the web with URLs provided by Blekko for Spring 2013","hostname":"ip-10-60-113-184.ec2.internal","format":"WARC File Format 1.0","isPartOf":"CC-MAIN-2013-20","operator":"CommonCrawl Admin","publisher":"CommonCrawl"}}},"Container":{"Compressed":true,"Gzip-Metadata":{"Footer-Length":"8","Deflate-Length":"453","Header-Length":"10","Inflated-CRC":"866052549","Inflated-Length":"650"},"Offset":"0","Filename":"CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.gz"}} WARC/1.0 WARC-Type: metadata WARC-Target-URI: http://%20jwashington@ap.org/Content/Press-Release/2012/How-AP-reported-in-all-formats-from-tornado-stricken-regions WARC-Date: 2013-05-18T05:48:54Z WARC-Record-ID: <urn:uuid:d519658f-7a63-46c1-849b-4cd92332ddb8> WARC-Refers-To: <urn:uuid:cefd363b-1fec-4590-8305-4c6fab2e095f> Content-Type: application/json Content-Length: 1501 {"Envelope":{"Format":"WARC","WARC-Header-Length":"433","Block-Digest":"sha1:B2B6JDSGWCUQIIUGV54SXEE25RX4SANS","Actual-Content-Length":"302","WARC-Header-Metadata":{"WARC-Type":"request","WARC-Date":"2013-05-18T05:48:54Z","WARC-Warcinfo-ID":"<urn:uuid:cfeff436-7c4c-4119-aaa4-ec2ce27ad3e1>","Content-Length":"302","WARC-Record-ID":"<urn:uuid:cefd363b-1fec-4590-8305-4c6fab2e095f>","WARC-Target-URI":"http://%20jwashington@ap.org/Content/Press-Release/2012/How-AP-reported-in-all-formats-from-tornado-stricken-regions","WARC-IP-Address":"165.1.125.44","Content-Type":"application/http; msgtype=request"},"Payload-Metadata":{"Trailing-Slop-Length":"4","HTTP-Request-Metadata":{"Headers":{"Accept-Language":"en-us,en-gb,en;q=0.7,*;q=0.3","Host":"ap.org","Accept-Encoding":"x-gzip, gzip, deflate","User-Agent":"CCBot/2.0","Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"},"Headers-Length":"300","Entity-Length":"0","Entity-Trailing-Slop-Bytes":"0","Request-Message":{"Method":"GET","Version":"HTTP/1.0","Path":"/Content/Press-Release/2012/How-AP-reported-in-all-formats-from-tornado-stricken-regions"},"Entity-Digest":"sha1:3I42H3S6NNFQ2MSVX7XZKYAYSCX5QBYJ"},"Actual-Content-Type":"application/http; msgtype=request"}},"Container":{"Compressed":true,"Gzip-Metadata":{"Footer-Length":"8","Deflate-Length":"455","Header-Length":"10","Inflated-CRC":"453539965","Inflated-Length":"739"},"Offset":"453","Filename":"CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.gz"}}Fuck no IP addresses either. But other entries do have it, why not this one?{ "Envelope": { "Format": "WARC", "WARC-Header-Length": "274", "Block-Digest": "sha1:JCZOI4V3UOTXGIRLFMPLW4J2WPLAKGVR", "Actual-Content-Length": "372", "WARC-Header-Metadata": { "WARC-Type": "warcinfo", "WARC-Filename": "CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.gz", "WARC-Date": "2013-11-22T14:51:12Z", "Content-Length": "372", "WARC-Record-ID": "<urn:uuid:cfeff436-7c4c-4119-aaa4-ec2ce27ad3e1>", "Content-Type": "application/warc-fields" }, "Payload-Metadata": { "Trailing-Slop-Length": "0", "Actual-Content-Type": "application/warc-fields", "Actual-Content-Length": "372", "Headers-Corrupt": true, "WARC-Info-Metadata": { "robots": "classic", "software": "Nutch 1.6 (CC)/CC WarcExport 1.0", "description": "Wide crawl of the web with URLs provided by Blekko for Spring 2013", "hostname": "ip-10-60-113-184.ec2.internal", "format": "WARC File Format 1.0", "isPartOf": "CC-MAIN-2013-20", "operator": "CommonCrawl Admin", "publisher": "CommonCrawl" } } }, "Container": { "Compressed": true, "Gzip-Metadata": { "Footer-Length": "8", "Deflate-Length": "453", "Header-Length": "10", "Inflated-CRC": "866052549", "Inflated-Length": "650" }, "Offset": "0", "Filename": "CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.gz" } }The reason these can be huge is theHTML-Metadatasection which contain all outlinks! gist.github.com/Smerity/e750f0ef0ab9aa366558#file-bbc-pretty-wat-L34 CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.gz()Obtain:aws s3 cp s3://commoncrawl/crawl-data/CC-MAIN-2013-20/segments/1368696381249/warc/CC-MAIN-20130516092621-00000-ip-10-60-113-184.ec2.internal.warc.gz .
- 1368696381249: one of many segments, any meaning of name?
TODO no IP? Sadface?
In 2017 apparently they've started making their own Web Graphs, i.e. they parse the HTML and extract the graph of what links to what.
This is exactly what we need for an open implementation of PageRank.
Edit: actually, they already calculate PageRank for us!!! Fantastic!!! Main section: Section "Common Crawl web graph official PageRank".
The graphs are dumped in BVGraph format.
A quick exploration of the graph can be seen at: github.com/cirosantilli/cirosantilli.github.io/issues/198
Their source code is at: github.com/commoncrawl/cc-webgraph
Tagged
Best-of lists:
Became paid in 2024: www.reddit.com/r/OSINT/comments/1awkxbi/facecheckid_will_no_longer_be_free/ You can search, it and lists which social media websites it found the hits on, but does not give the full URLs.
Had one possible non-trivial LinkedIn hit for Ross Ulbricht's wife in early 2025, before her identity was publicly known, so they may have something actually going on there
Tagged
Under: gmp.
Tagged
gmp/hello.c
/* Adapted from:
* https://en.wikipedia.org/w/index.php?title=GNU_Multiple_Precision_Arithmetic_Library&oldid=1213913871
* Tested on GMP 6.3.0, Ubuntu 24.04.
*/
#include <stdio.h>
#include <gmp.h>
int main(void) {
mpz_t x, y, result;
mpz_init_set_str(x, "7612058254738945", 10);
mpz_init_set_str(y, "9263591128439081", 10);
mpz_init(result);
mpz_mul(result, x, y);
gmp_printf("%Zd * %Zd = %Zd\n", x, y, result);
/* Cleanup */
mpz_clear(x);
mpz_clear(y);
mpz_clear(result);
return 0;
}
The original gangster.
This is the dream cheating software every student should know about.
It also has serious applications obviously. www.sympy.org/scipy-2017-codegen-tutorial/ mentions code generation capabilities, which sounds super cool!
The code in this section was tested on
sympy==1.8 and Python 3.9.5.Let's start with some basics. fractions:outputs:Note that this is an exact value, it does not get converted to floating-point numbers where precision could be lost!
from sympy import *
sympify(2)/3 + sympify(1)/27/6We can also do everything with symbols:outputs:We can now evaluate that expression object at any time:outputs:
from sympy import *
x, y = symbols('x y')
expr = x/3 + y/2
print(expr)x/3 + y/2expr.subs({x: 1, y: 2})4/3How about a square root?outputs:so we understand that the value was kept without simplification. And of course:outputs outputs:gives:
x = sqrt(2)
print(x)sqrt(2)sqrt(2)**22. Also:sqrt(-1)II is the imaginary unit. We can use that symbol directly as well, e.g.:I*I-1Let's do some trigonometry:gives:and:gives:The exponential also works:gives;
cos(pi)-1cos(pi/4)sqrt(2)/2exp(I*pi)-1Now for some calculus. To find the derivative of the natural logarithm:outputs:Just read that. One over x. Beauty. And now for some integration:outputs:OK.
from sympy import *
x = symbols('x')
print(diff(ln(x), x))1/xprint(integrate(1/x, x))log(x)Let's do some more. Let's solve a simple differential equation:Doing:outputs:which means:To be fair though, it can't do anything crazy, it likely just goes over known patterns that it has solvers for, e.g. if we change it to:it just blows up:Sad.
y''(t) - 2y'(t) + y(t) = sin(t)from sympy import *
x = symbols('x')
f, g = symbols('f g', cls=Function)
diffeq = Eq(f(x).diff(x, x) - 2*f(x).diff(x) + f(x), sin(x)**4)
print(dsolve(diffeq, f(x)))Eq(f(x), (C1 + C2*x)*exp(x) + cos(x)/2)diffeq = Eq(f(x).diff(x, x)**2 + f(x), 0)NotImplementedError: solve: Cannot solve f(x) + Derivative(f(x), (x, 2))**2Let's try some polynomial equations:which outputs:which is a not amazingly nice version of the quadratic formula. Let's evaluate with some specific constants after the fact:which outputsLet's see if it handles the quartic equation:Something comes out. It takes up the entire terminal. Naughty. And now let's try to mess with it:and this time it spits out something more magic:Oh well.
from sympy import *
x, a, b, c = symbols('x a b c d e f')
eq = Eq(a*x**2 + b*x + c, 0)
sol = solveset(eq, x)
print(sol)FiniteSet(-b/(2*a) - sqrt(-4*a*c + b**2)/(2*a), -b/(2*a) + sqrt(-4*a*c + b**2)/(2*a))sol.subs({a: 1, b: 2, c: 3})FiniteSet(-1 + sqrt(2)*I, -1 - sqrt(2)*I)x, a, b, c, d, e, f = symbols('x a b c d e f')
eq = Eq(e*x**4 + d*x**3 + c*x**2 + b*x + a, 0)
solveset(eq, x)x, a, b, c, d, e, f = symbols('x a b c d e f')
eq = Eq(f*x**5 + e*x**4 + d*x**3 + c*x**2 + b*x + a, 0)
solveset(eq, x)ConditionSet(x, Eq(a + b*x + c*x**2 + d*x**3 + e*x**4 + f*x**5, 0), Complexes)Let's try some linear algebra.Let's invert it:outputs:
m = Matrix([[1, 2], [3, 4]])m**-1Matrix([
[ -2, 1],
[3/2, -1/2]])python/sympy_cheat/logarithm_integral.py
#!/usr/bin/env python3
from sympy import *
x = symbols('x')
myli = integrate(sympify(1)/ln(x), x)
# It recognizes our definition as its own li! Beauty.
assert myli.equals(li(x))
for r in range(-2, 2):
for i in range(-2, 2):
print(f'{r} {i} {li(r + i*I).evalf()}')
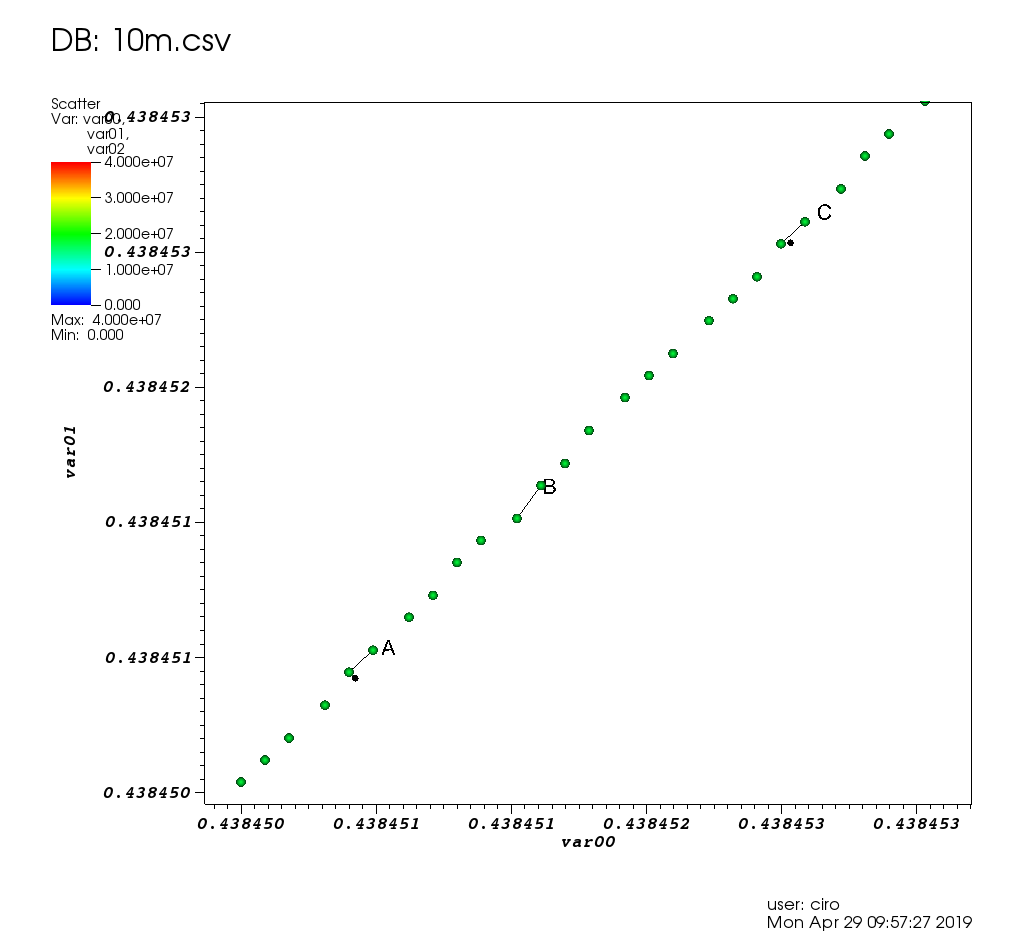
Ciro's large dataset survey: Section "Survey of open source interactive plotting software with a 10 million point scatter plot benchmark by Ciro Santilli".
Huge respect to this companies.
E.g. showing live data from a scientific instrument! TODO:
- superuser.com/questions/825588/what-is-the-easiest-way-of-visualizing-data-from-stdout-as-a-graph
- unix.stackexchange.com/questions/190337/how-can-i-make-a-graphical-plot-of-a-sequence-of-numbers-from-the-standard-input
- stackoverflow.com/questions/44470965/how-can-you-watch-gnuplot-realtime-data-plots-as-a-live-graph-with-automatic-up
- stackoverflow.com/questions/14074790/plotting-a-string-of-csv-data-in-realtime-using-linux
- stackoverflow.com/questions/11874767/how-do-i-plot-in-real-time-in-a-while-loop-using-matplotlib
By Ciro Santilli.
It does a huge percentage of what you want easily, and from the language that you want to use.
Tends to be Ciro's pick if gnuplot can't handle the use case, or if the project is really really serious.
Couldn't handle exploration of large datasets though: Survey of open source interactive plotting software with a 10 million point scatter plot benchmark by Ciro Santilli
Examples:
- matplotlib/hello.py
- matplotlib/educational2d.py
- matplotlib/axis.py
- matplotlib/label.py
- Line style
- Subplots
- matplotlib/two_lines.py
- Data from files
- Specialized
Tested on Python 3.10.4, Ubuntu 22.04.
Tends to be Ciro Santilli's first attempt for quick and dirty graphing: github.com/cirosantilli/gnuplot-cheat.
domain-specific language. When it get the jobs done, it is in 3 lines and it feels great.
When it doesn't, you Google for an hours, and then you give up in frustration, and fall back to Matplotlib.
Couldn't handle exploration of large datasets though: Survey of open source interactive plotting software with a 10 million point scatter plot benchmark by Ciro Santilli
CLI hello world:
gnuplot -p -e 'p sin(x)'Edsger W. Dijkstra's request to programmers
. Source. A glitch is more precisely a software bug that is hard to reproduce. But it has also been used to mean a software bug that is not very serious.
Debugging sucks. But there's also nothing quite that "oh fuck, that's why it doesn't work" moment, which happens after you have examined and placed everything that is relevant to the problem into your brain. You just can't see it coming. It just happens. You just learn what you generally have to look at so it happens faster.
Tagged
This is a simple hierarchical plaintext notation Ciro Santilli created to explain programs to himself.
It is usuall created by doing searches in an IDE, and then manually selecting the information of interest.
It attempts to capture intuitive information not only of the call graph itself, including callbacks, but of when things get called or not, by the addition of some context code.
For example, consider the following pseudocode:Supose that we are interested in determining what calls
f1() {
}
f2(i) {
if (i > 5) {
f1()
}
}
f3() {
f1()
f2_2()
}
f2_2() {
for (i = 0; i < 10; i++) {
f2(i)
}
}
main() {
f2_2()
f3()
}f1.Then a reasonable call hierarchy for
f1 would be:f2(i)
if (i > 5) {
f1()
f2_2()
for (i = 0; i < 10; i++) {
f2(i)
main
f3
f3()
main()Some general principles:
- start with a regular call tree
- to include context:
- remove any blank lines from the snippet of interest
- add it indented below the function
- and then follow it up with a blank line
- and then finally add any callers at the same indentation level
One of the Holiest age old debugging techniques!
Git has some helpers to help you achieve bisection Nirvana: stackoverflow.com/questions/4713088/how-to-use-git-bisect/22592593#22592593
Obviously not restricted to software engineering alone, and used in all areas of engineering, e.g. Video "Air-tight vs. Vacuum-tight by AlphaPhoenix (2020)" uses it in vacuum engineering.
The cool thing about bisection is that it is a brainless process: unlike when using a debugger, you don't have to understand anything about the system, and it incredibly narrows down the problem cause for you. Not having to think is great!
Nirvana!!!
For JavaScript: stackoverflow.com/questions/17498159/how-to-go-backwards-while-debugging-javascript-in-chrome-sources-debugging/74968631#74968631
Tagged
What it adds on top of reverse debugging: not only can you go back in time, but you can do it instantaneously.
Or in other words, you can access variables from any point in execution.
TODO implementation? Apparently Pernosco is an attempt at it, though proprietary.
Tagged
Just add GDB Dashboard, and you're good to go.
The best open source implementation as of 2020 seems to be: Mozilla rr.
- stackoverflow.com/questions/1206872/go-to-previous-line-in-gdb/46996380#46996380
- stackoverflow.com/questions/1470434/how-does-reverse-debugging-work/53063242#53063242
- stackoverflow.com/questions/3649468/setting-breakpoint-in-gdb-where-the-function-returns/46116927#46116927
- stackoverflow.com/questions/27770896/how-to-debug-a-rare-deadlock/50073993#50073993
- stackoverflow.com/questions/522619/how-to-do-bidirectional-or-reverse-debugging-of-programs/50074106#50074106 link only, marked as duplicate of go to previous line
- softwareengineering.stackexchange.com/questions/181527/why-is-reverse-debugging-rarely-used
Proprietary extension to Mozilla rr by rr lead coder Robert O'Callahan et. al, started in 2016 after he quit Mozilla.
TODO what does it add to
rr?GDB Nirvana?

The musical study of software engineering.
Ciro Santilli is obsessed by those in order to learn any new concept, not just for bug reporting.
This includes to learn more theoretical subjects like physics and mathematics.
Evil company that desecrated the beauty created by Sun Microsystems, and was trying to bury Java once and or all in the 2010's.
Their database is already matched by open source e.g. PostgreSQL, and ERP and CRM specific systems are boring.
Oracle basically grew out of selling one of the first SQL implementations in the late 70's, and notably to the United States Government and particularly the CIA. They did deliver a lot of value in those early pre-internet days, but now open source is and will supplant them entirely.
Although Ciro Santilli is a bit past their era, there's an aura of technical excellence about those people. It just seems that they sucked at business. Those open source hippies. Erm, wait.
Bibliography:
- archive.org/details/sunburstascentof00hall Sunburst: the ascent of Sun Microsystems by Mark Hall (1990)
The Dawn and Dusk of Sun Microsystems by Asianometry (2022)
Source. One of the main inspirations for the creation of their workstations were CAD applications.Video "1984 Macintosh advertisement by Apple (1984)" comes to mind.
TODO year. This was a reply to Microsoft anti-Linux propaganda it seems: www.ubuntubuzz.com/2012/03/truth-happens-redhats-legendary-reply.html
Trascript from: www.dailymotion.com/video/xw3ws
The world is flat. Earth is the centre of the universe. Fact - until proven otherwise.
Despite ignorance. Despite ridicule. Despite opposition. Truth happens.Despite ignorance.
The telephone has too many shortcomings to be seriously considered as a means of communication. /Western Union 1876/
In 1899 the US Patent Commissioner stated, everything that can be invented has been invented.Despite ridicule.
The phonograph has no commercial value at all. /Thomas Edison 1880/
The radio craze will die out in time. /Thomas Edison 1922/
The automobile has practically reached the limit of its development. /Scientific American 1909/Despite it all truth happens.
Man will not fly for fifty years. /Orville Wright 1901/
The rocket will never leave the Earth's atomosphere. /New York Times 1936/
There is a world market for maybe five computers. /IBM's Thomas Watson 1943/
640K Ought to be enough for anybody. /Bill Gates 1981/First they ignore you...
Linux is the hype du jour. /Gartner Group 1999/Then they laugh at you...
We think of linux as competitor in the student and hobbyist market. But I really don't think in the commercial market we'll see it in any significant way. /Bill Gates 2001/Then they fight you...
Linux isn't going away. Linux is a serious competitor. We will rise to this challenge. /Steve Ballmer 2003/Then you win... /Mohandas Gandhi/You are here.
Red Hat Linux. IBM.
Truth Happens advertisement by Red Hat
. Source. Tagged
Please, use AsciiDoc and one page to rule them all.
- 1.2 Check permutation: cpp/string_is_permutation.cpp
- 1.5 One away: cpp/one_away.cpp
- 4.1 Route Between Nodes: cpp/directed_graph_size.cpp
- 4.7 Build Order: cpp/topological_sort.cpp
- 16.10 Living People: cpp/max_interval_overlaps.cpp
- 16.25 LRU Cache: cpp/lru_cache.cpp
The mandatory xkcd: xkcd 927: Standards.
Of course, "Ciro Santilli" with quotes, since all of those are either taken directly from others, or had been previously formulated by others.
Some anecdotes.
Ciro Santilli never splits up functions unless there is more than one calling point. If you split early, the chances that the interface will be wrong are huge, and a much larger refactoring follows.
If you just want to separate variables, just use a scope e.g.:
int cross_block_var;
// First step.
{
int myvar;
}
// Second step.
{
int myvar;
}Ciro has seen and had to deal with in his lifetime with two projects that had like 3 to 10 git separate Git repositories, all created and maintained by the same small group of developers of the same organization, even though one could not build without the other. Keeping everything in sync was Hell! Why not just have three directories inside a single repository with a single source of truth?
Another important case: Linux should have at least a C standard library, init system, and shell in-tree, like BSD Operating Systems, as mentioned at: Section "Linux".
A slow development test cycle will kill your software.
New developers won't want to learn your project, because they would rather shoot themselves.
This means that build time, and the time to run tests, must be short.
5 seconds to rebuild is the maximum upper limit.
Of course, at some point software gets large enough that things won't fit anymore in 5 seconds. But then you must have either some kind of build caching, or options to do partial builds/tests that will bring things down to that 5 second mark.
You also have to spend some time profiling execution and build from scratch times.
A slow build from scratch will mean that your continuous integration costs a lot, money that could be invested in a new developer!
It also means that people won't bother to reproduce bugs on given commits, or bisect stuff.
One anecdote comes to mind. Ciro Santilli was trying to debug something, and more experience colleague came over.
To reproduce a problem, ciro was running one command, wait 5 seconds, run a second command, wait 5 seconds, run a third command:
cmd1
# wait 5 seconds
cmd2
# wait 5 seconds
cmd3The first thing the colleague said: join those three commands into one:And so, Ciro was enlightened.
cmd1;cmd2;cmd3
xkcd 303: Compiling
. Source. They should be benchmarking and fixing their shitty build system instead.Whenever someone asks:you don't need to read anymore, just point them to this page immediately. Virtualization for the win.
I can only see this one thing different our setups, do you think it could be the cause of our different behaviour?
Sometimes you are really certain that something is a required substep for another thing that is coming right afterwards.
When things are this concrete, fine, just do the substep.
But you have to always beware of cases where "I'm sure this will be needed at some unspecified point in the future", because such points tends to never happen.
YAGNI is so fundamental, there are several closely related concepts to it:

Tagged
The software engineer phrasing of simplicity is the ultimate sophistication.
Like all other principles, it is not absolute.
But it is something that you should always have on the back of your mind.
You aren't gonna need it is closely related, as generally the extra unnecessary complications are set in place to accommodate useless features that will never be needed.
The trivial takes a few hours.
The easy takes a week.
And what seemed hard takes a few hours.
As "deadlines" approach, feature sets get cut down, then there are delays, and finally a feasible feature set is delivered some time after the deadline.
The only deadlines that can be met are those of tasks which have already been done but not announced.
This is of course Hofstadter's law.
On the other hand, as a colleague of Ciro once mentioned, it is also known that the time it takes for a task to be done expands without limits to match the deadline. And therefore, without deadlines, tasks will take forever and never get done.
And so, in a moment, perceiving this paradox, Ciro was enlightened.
The Misty Mountains Cold Scene from The Hobbit: An Unexpected Journey (2012)
Source. I will take each and every one of these dwarves over an army from the Iron Hills. For when I called upon them they answered. Loayalty. Honour. And willing heart. I can ask no more than that.
Once upon a time, when Ciro Santilli had a job, he had a programming problem.
A senior developer came over, and rather than trying to run and modify the code like an idiot, which is what Ciro Santilli usually does (see also experimentalism remarks at Section "Ciro Santilli's bad old event memory"), he just stared at the code for about 10 minutes.
We knew that the problem was likely in a particular function, but it was really hard to see why things were going wrong.
After the 10 minutes of examining every line in minute detail, he said:and truly, that was the cause.
I think this function call has such or such weird edge case
And so, Ciro was enlightened.
Working remotely is hard if you don't already highly master the software and enterprise systems used.
Also you don't feel people's love as strongly, and usefulness is built on love, see also Steve Jobs's Pixar office space design philosophy.
But please, give workers a small silent office so that we can concentrate instead of a silly open space, and create an internal social network so people can see what others are doing.
Remote working is much better if the majority of the team also does it, otherwise you will get excluded. Maybe after VR...
When debugging complex software, make sure to keep notes of every interesting find you make in a note file, as you extract it from the integrated development environment or debugger.
Especially if your memory sucks like Ciro's.
This is incredibly helpful in fully understanding and then solving complex bugs.
The most important program ever written!!!
Other programs that can be considered "hello worlds" in different contexts:
- web development
- video game
- Doom is the hello world shooter game
This is the hello world program of microcontrollers: blinking and LED! Many boards have an on-board LED, making this a convenient hello world that does not require any external components.
Tagged
Poet warriors monkeys? Or Code peasants (码农) according to the Chinese.
Ciro Santilli claims to be one of them.
Much like a pianist plays his piano, a software engineer plays his computer.
Tagged
www.quora.com/Why-do-successful-geeky-white-men-have-Asian-wives-This-seems-to-be-the-norm-in-Silicon-Valley suggests it is just an statistical inevitability.
Ciro Santilli believes that there is a positive correlation between being a software engineer and liking Buddhist-like things.
Maybe it is linked to minimalism and DRY, which software engineers value so greatly.
Even Ciro had to try an unoriginal Buddhist joke intro in one of this Stack Overflow answers.
Ciro also feels that his "minimal reproducible example" scientific language/concept learning method obsession of breaking things into tiny sub-problems has a strong link with Koans.
Some notable Buddhism/programmer examples:
- www.catb.org/~esr/writings/unix-koans/ "The Unix Koans of Master Foo - Rootless Root (无根的根)" by the legendary Eric Steven Raymond is notable
- thecodelesscode.com/ "The Codeless Code" by anonymous Qi.
- canonical.org/~kragen/tao-of-programming.html
- wiki.c2.com/?MysticalProgrammingKoans
- rubykoans.com/ even evil programming languages adopt them!
- The Zen of Python
Another thing that points the correlation out is the existence of wattsalan.github.io/ on a
github.io about Alan Watts.Ciro Santilli's joke version of the Chinese Four Treasures of the Study!In the past, Ciro used to use file managers, which would be the fourth tresure. But he stopped doing so for years due to his cd alias... so it became three. He actually had exactly three windows open when he was checking if there was anything else he could not open hand of.
- web browser
- Text editor
- terminal. Though to be honest, circa 2022, Ciro learned of the ctrl + click to open file (including with file.c:123 line syntax) ability of Visual Studio Code (likely present in other IDEs), and he was starting considering dumping the terminal altogether if some implementation gets it really really right. The main thing is that it can't be a tinny little bar at the bottom, it has to be full window and super easily toggleable!

The three Treasures of the Programmer
. Featuring: Gvim, tmux running in GNOME terminal, and Chromium browser on Ubuntu 22.04. The minimized windows are for demonstration purposes, Cirism mandates that all windows shall be maximized at all times. Splits withing a single program are permitted however.Aaron, Ciro Santilli will complete your quest to make eduction free. Just legally this time, with the and with the Creative Commons license you helped to create.
Ciro likes how The Internet's Own Boy (2014) explains how Aaron felt like high school was bullshit, and that he could learn whatever he wanted from books, which is one of Ciro's key feelings.
It also mentions how he was a natural teacher from a very early age.
Hmmm, he does not know how to spell guerilla? sic? www.quora.com/What-is-the-correct-spelling-guerilla-or-guerrilla
Note to self: if you are going to commit a crime, don't publish your plans online.
Ross Ulbricht's diaries come to mind.
That's how Russian shadow library maintainers do it, they know how to crime good old Russians. Maybe there is a good thing about having dictatorships in the world that give zero fucks about American copyright laws. There will always be some random Russian academic who will implement this and not go to jail. Maybe it's even state sponsored.
Huge interest overlap with Ciro Santilli, e.g. he's into
- molecular biology in general: I should have loved biology by James Somers
- JCVI-syn3.0: www.newyorker.com/magazine/2022/03/07/a-journey-to-the-center-of-our-cells
- cryo-EM: www.newyorker.com/magazine/2022/03/07/a-journey-to-the-center-of-our-cells
- David Goodsell: www.newyorker.com/magazine/2022/03/07/a-journey-to-the-center-of-our-cells
- History of Google: www.newyorker.com/magazine/2018/12/10/the-friendship-that-made-google-huge
This resonates a lot with Ciro Santilli's ideas!
- physics and the illusion of life
- physics education needs more focus on understanding experiments and their history:
- Education is broken
- molecular biology feels like systems programming
I've never come across a subject so fractal in its complexity. It reminds me of computing that way.
Lots of similar ideologies to Ciro Santilli, love it:
- sandymaguire.me/about/:
- he's an idealist
I might best be described somewhere between independent researcher and voluntarily-unemployed bum. At the ripe old age of 27 I decided to quit my highly-lucrative engineering job and decide to focus more on living than on grinding for the man. It's what you might call a work in progress.
- sandymaguire.me/blog/reaching-climbing/: don't be a pussyOne is also reminded of Gwern Branwen. Sandy is also into self-improvement stuff, so even more like Gwern. This is a point Ciro diverges on. Ciro works actively on self-worsening.
Last Friday was my final day at work. According to my facebook profile, I am now "happily retired." As of today, I don't plan to do another day of "traditional work" in my life. That's not to say that I'll be sitting idle playing tiddly winks. I want to build things, to dedicate my life to independent study, and to get really, really good with building communities. I don't have time for any of this "work" stuff that somehow pervades our entire culture, choking our inspiration and sapping our energy away from the things we'd rather be doing.
- he thinks university is useless:
- sandymaguire.me/blog/where-uni-fails/ Where University Fails (2018), mostly talking about backward design
- sandymaguire.me/blog/gatekept/ rejected from Imperial College PhD program due to grade being slightly too low for their stupid requirements, even though he had a referral already, and an amazing CV
- he likes jazz: sandymaguire.me/blog/too-smart/
Other interesting points:
- sandymaguire.me/blog/sandy-runback/ he changed his own name to Sandy because he didn't like it, he was born Alexander
- algebradriven.design/ closed source books though, ouch. At least they seem to have been made with leanpub though, could be worse.
He's a Haskell person.
His website is down as of 2020, shame: wiki.dandascalescu.com/essays/english-universal-language
This dude is interesting. Quite crazy type. It is hard to differentiate genius from mad.
Ciro Santilli bumps on his Stack Overflow from time to time: stackoverflow.com/users/1269037/dan-dascalescu.
One of the dudes from the AtomSea & EMBII Bitcoin-based file upload system.
- github.com/embiimob
- Real name: likely "Eric Bobby" according to:According to Figure "
Loraine.jpg" however, his mother's name was "Loraine Elizabeth White", so there's some chance his real family name is Mr. White.However according to bitfossil.org/root/937f70bf641ccabaf623772367df64bd867ad44c53fd227d01f2662e74aeacbf/ his daughter is Maddy Bobby, so maybe he is actually Bobby. - twitter.com/EMBII4U
- twitter.com/TheAtomSea/status/990318090738196481 sample link
- x.com/EMBII4U/status/1901769408453718146 possibly retired in 2021 after working as a barista
- he seems to have been quite interested in natural science at around high school before he decided to waste his life as a crypto artist
- x.com/EMBII4U/status/1936278732760666236:
I was science student of the year 1992 all because of molecular biology for real
It's not hard to be Science student of the year in Aberdeen SD
- x.com/EMBII4U/status/1727331097447428199 a love declaration to Marie Curie
- x.com/EMBII4U/status/1936278732760666236:

Author of gwern.net.
Accounts:He posts insanely much on these websites. It's a bit like Ciro Santilli on Stack Overflow.
- news.ycombinator.com/user?id=gwern
- www.lesswrong.com/users/gwern LessWrong
- twitter.com/gwern locked 2021: www.reddit.com/r/slatestarcodex/comments/kp2fek/does_anybody_know_what_happened_to_gwern/
- www.reddit.com/user/gwern/
- en.wikipedia.org/wiki/User:Gwern on Wikipedia. Self summary: gwern.net/wikipedia-resume. Also he is a critic of deletionism on Wikipedia like Ciro Santilli
Ciro Santilli envies this guy a bit. He dumps his brain more or less full time on his highly customized static website partly due to early Bitcoin investments gwern.net/me says:
Also unsurprisingly he likes Haskell:
I mostly contribute to projects in Haskell, my favorite language
Ciro Santilli considers Gwern Ciro Santilli's e-soulmates due to his interest in "dark web things" like Bitcoin and Silk Road, his immense writing output in encyclopedic book-sized articles on a static website, and his desire to live frugally and just research and write all day. Ah, if only Ciro had some old coins!!!
This is likely a pseudonym, his real name not being publicly unknown, e.g. at news.ycombinator.com/item?id=5659278:
Why do you choose relative anonymity?For the reasons I've said in the past. To which I can add personal safety: my Silk Road page is a bit questionable legally, and we all know that there are ways to exploit knowledge of one's True Name and address (even if, as far as I know, I have no enemies willing to resort to, say, 'swatting' me) - one group of stalkers called up a college they thought I worked at to see if they could get me fired or otherwise ruin my day.
Gwern Branwen's website.
One thing that annoys Ciro Santilli about that website are the footnote overload. Ciro likes linear things.
TODO find the best source for the amazing "I have done your mother" quote.

Richard Stallman saying "I've never installed gnu/linux"
. Source. 
{kind=link}
{kind=link}
Programming is hard. To Ciro Santilli, it's almost masochistic.
What makes Ciro especially mad when programming is not the hard things.
It is the things that should be easy, but aren't, and which take up a lot of your programming time.
Especially when you are already a few levels of "simple problems" down from your original goal, and another one of them shows up.
This is basically the cause of Hofstadter's law.
But of course, it is because it is hard that it feels amazing when you achieve your goal.
Putting a complex and useful program together is like composing a symphony, or reaching the summit of a hard rock climbing proble.
Programming can be an art form. There can be great beauty in code and what it does. It is a shame that this is hard to see from within the walls of most companies, where you are stuck doing a small specific task as fast as possible.
This script tests all executables under a selected directory.
Ciro Santilli has been writing scripts of that type for a long time in order to test his programming self-learning setups with asserts.
The most advanced of those being the test system of Linux Kernel Module Cheat.
But had too much stuff that would be specific to that project, so Ciro decided to start this new one in Node.js, hopefully it will also be the last he ever writes.
A sample usage of the test library can be seen at: nodejs/sequelize/test.
test_executables.js was not rendered because it is too large (> 2000 bytes)
Tagged
This is a good approach. The downside is that while you are developing the implementation and testing interactively you might notice that the requirements are wrong, and then the tests have to change.
One intermediate approach Ciro Santilli likes is to do the implementation and be happy with interactive usage, then create the test, make it pass, then remove the code that would make it pass, and see it fail. This does have a risk that you will forget to test something, but Ciro finds it is a worth it generally. Unless it really is one of those features that you are unable to develop without an automated test, generally more "logical/mathematical" stuff. This is a sort of laziness Driven Development.
Some blogs:
- blog.codinghorror.com/the-best-code-is-no-code-at-all/ The Best Code is No Code At All (2007)
- www.skrenta.com/2007/05/code_is_our_enemy.html Code is our enemy (2007)
Also resonates with backward design.
Once upon a time young Ciro Santilli spent lots of time evaluating the features of different terimnals. The many windows of Terminator. The pop-uppiness of Guake/Yakuake.
But then one day he met tmux, and he was enlightened
Terminal choice doesn't matter. Just use tmux.
If we didn't have GUIs, terminal multiplexers would be our desktop environments. E.g. they handle stuff like:It is a thing of beauty.
- window switching
- copy pasting across windows
- screen locking
- clock on the status bar (same one that holds tabs)
Most important things to know:
- kill window: Ctrl + A K
If session autosave was finally mainlined, this would be Nirvana.
It is said, that once upon a time, programmers used CSV and collaborated on SourceForge, and that everyone was happy.
These days, are however, long gone in the mists of time as of 2020, and beyond Ciro Santilli's programming birth.
Except for hardware developers of course. The are still happily using Perforce and Tcl, and shall never lose their innocence. Blessed be their souls. Amen.
The fundamental insight of Git design is: a SHA represents not only current state, but also the full history due to the Merkle tree implementation, see notably:
This makes it so that you will always notice if you are overwriting history on the remote, even if you are developing from two separate local computers (or more commonly, two people in two different local computers) and therefore will never lose any work accidentally.
It is very hard to achieve that without the Merkle tree.
Consider for example the most naive approach possible of marking versions with consecutive numbers:
- Local 1:
- 0: root commit
- 1: commit 1
- 2: commit 2 by local 1
- Local 2:
- 0: root commit
- 1: commit 1
- 2: commit 2 by local 2
- 3: commit 3 by local 2
- Remote
- 0: root commit
- 1: commit 1
If Local 1 were to push to Remote first, how could Local 2 notice that when it tries to push itself? The navie method of just checking: "does Remote have commit "2"" does not work, because Local 2 has a different version of commit 2 than local 1.
- stackoverflow.com/questions/600079/how-do-i-clone-a-subdirectory-only-of-a-git-repository/52269934#52269934
- summaries:
- dupes:
- file or directory
- file
- only small files:
Perfect Git integration belongs in integrated development environments :-)
gitk 2.34.1 running on Ubuntu 22.04 with a simple repository.
This is good. But it misses some key operations, so much so that makes Ciro not want to learn/use it daily.
This is where Ciro Santilli stored his code since he started coding nonstop in 2013.
He does not like the closed source aspect of it, but hey, there are more important things to worry about, the network effect is just too strong.
Some amazing people have put book source codes on GitHub. This is a list of such repos.
The cheapest and most resilient way to publish text content humanity has achieved so far.
Some tests:
- github.com/cirosantilli/jekyll-cheat: cirosantilli.com/jekyll-cheat
- Test with a
.nojekyllfile. - github.com/cirosantilli/test-gh-pages-min: cirosantilli.com/test-gh-pages-min. Minimal version of the above.
The heart/main innovation of GitHub!
GitLab was very important to Ciro because he wanted to base Booktree on it.
See also: Ciro Santilli's minor projects.