 Ciro Santilli
Ciro SantilliThis section contains the a list of cool things Ciro Santilli has been up to in chronological order, including small quick ones. Many/most of those are also posted on Ciro Santilli's accounts such as:
For a more theme-oriented version of the best results see: Section "The best articles by Ciro Santilli".
For OurBigBook Project updates see: docs.ourbigbook.com/news
Imagine that it is 2011 and you are editing the linked to it back in 2011 in a Talk of the "Causes of autism" Wikipedia page. You are researching about the far fetched theory that it was Neanderthal mixture with earlier humans which led to the appearance of autism. You Google it up and list some links. One of them happens to be
autism-news.org. This is how it would have looked like at the time according to archive.org. You mark it as "non-legitimate" and move on.And imagine that, unknown to you however, this page was actually created by CIA employees as of of many to allow their agents to communicate information back to the CIA! These pages would later be discovered by the target countries such as China and Iran, leading to the imprisonment and execution of many agents!
Well, this is exactly what happened to Wikipedia user Slartibartfastibast!
After the revelations of CIA 2010 covert communication websites, security researcher Ellie intentionally registered the domain autism-news.org, and she found out that Wikipedia Slartibartfastibast had linked to it back in 2011 in a Talk of the "Causes of autism" page discussing the legitimacy of the "Neanderthal Admixture Hypothesis".
Slartibartfastibast placed the website under a list:"Non-legitimate" it was!
Non-legitimate source(s) that propose hominid admixture is behind autism
Ellie created a Accidentally found a CIA covert communications website badge for them which his exceedingly cute.
Attempts to reach Slartibartfastibast to ask how he found the website failed, x.com/Slartibartfas12 is a possible account, and there is also a known similar Gmail address from a data leak which might match.
It is almost certain that they just happened to find the website while Googling for it, since we know that the websites were Googleable because it has been reported that the Iranians used Google dorking to find some of them.[ref] This is presumably because Google had access to zone files, which are big dumps of registered domains that some registrars make available to some organizations.
Ciro Santilli subsequently searched for any more hits of the Websites on the Wikipedia dumps by grepping gives a few dozen hits, all legit. The next step would be to try and download full Wikipedia history for the period, but that would require more patience and would likely not yield anything of much interest either.
enwiki-latest-externallinks.sql which contains all live external links outgoing from Wikipedia. The only two hits were autism-news.org itself and inkfreenews.com which became a legitimate local news website for Northern Indiana as early as 2013. Inspection of:grep -Po "inkfreenews.*?'.*?'.*?'" enwiki-latest-externallinks.sqlIt is understandable why
autism-news.org is would be one of the few websites most prone to being randomly Googled: unlike most websites which are quite generic news aggregator websites, this one contains a surprising amount of text. Much like the Star Wars website starwarsweb.net, we would like to think that the contractor who made this one up actually put their hearts into it, and might have had a real personal interest in the matter. The quotes about Neanderthal Admixture Hypothesis are in the Causes subpage:The Neanderthal Theory is that autism and other psychiatric conditions evolved from interbreeding between Homo Sapiens and Neanderthals. This interbreeding is believed to have caused genetic material from the Neanderthals to enter the Homo Sapiens genome. Whether such interbreeding ever actually occurred is controversial, and this theory is extremely speculative.
The username "Slartibartfastibast" seems to be a variation of Slartibartfast, a character from The Hitchhiker's Guide to the Galaxy who according to Gemini is a:So it's probably an autistic dude from the UK. Their Wiki homepage says simply however:and as of writing their latest contribution was from 2014 and they are typical STEM nerd based on their edits.
venerable "planetary designer" from the planet Magrathea, most famously known for his award-winning work designing coastlines and his deep, personal passion for creating fjords
I live in NYC.

2011 Wayback Machine archive of autism-news.org
. Source. I've created a quick fork of ARC-DSL which defines a hand crafted Domain Specific Language (DSL) approach to help solve ARC-AGI problems.
I basically just merged outstanding pull requests on the original repo that were needed to make things run.
It would be cool to see if those rules also solve ARC-AGI-2 problems well, but lazy now.
ARC-AGI-2 is a very interesting benchmark which mixes some symbolic and other visual elements, and is readily solvable by non-expert humans, but has so far resisted transformers to a large degree.
Part of me would like to focus more on less visual aspects of AI, but it is still of interest.
It is funny how many early (semi)-retired fintech/bigtech bros that are interested in the project, I saw several of them on the forums.
I'd be tempted if I were in that position too I must confess. Maybe in 15 years time for me the way things are looking.
Kudos to these people who do something cool and open when they don't need money: www.reddit.com/r/Fire/comments/15x4w7r/comment/jx7dn16/ It is also the case of Jimmy Wales from Wikipedia for example, who used to work in finance.
Announcements:
I have been banned from Project Euler for life, and cannot login to my previous account projecteuler.net/profile/cirosantilli.pn
The ban happened within 12 hours of me publishing a solution to Project Euler problem 961 github.com/lucky-bai/projecteuler-solutions/pull/94 which was one-shot by a free GPT-5 account as MathArena had alerted me to being possible: matharena.ai/?comp=euler--euler&task=4&model=GPT-5+%28high%29&run=1
The problem leaderboard contains several people solved the problem within minutes of it being released, so almost certainly with an LLM.
I'm a huge believer in giving answers to problems, and I take the ban with pride.
It is funny to see that people waste their time policing this kind of useless stuff.
Project Euler likely has many fun problems, and can be a useful machine learning benchmark.
The "secret club" mentality is their only blemish, and incompatible with open science.
They should also make sure that LLMs don't one shot their future problems BEFORE publishing them!
Announcements:
This is a quick update to the article: Section "CIA 2010 covert communication websites"
I've downloaded and uploaded copies of the archives of the CIA websites as follows:
- all cqcounter screenshots where cqcounter was the best source to: github.com/cirosantilli/media/tree/master/cia-2010-covert-communication-websites/screenshots/cqcounter. That commercial website does not inspire much trust, e.g. now the main pages like cqcounter.com/site/internationalwhiskylounge.com.html were giving an error:so I'm glad to have saved their precious screenshots at a safer place.
[1114: The table 'access' is full] ( 1114 : The table 'access' is full ) - all Wayback Machine archives to: github.com/cirosantilli/cia-2010-websites-dump. The exports were done with github.com/StrawberryMaster/wayback-machine-downloader by Felipe x.com/opapeldetrouxa which is an up-to-date fork of github.com/hartator/wayback-machine-downloader and the tool seemed to work very well. I've also edited that better working fork at the top answer of: superuser.com/questions/828907/how-to-download-a-website-from-the-archive-org-wayback-machine/957298#957298
The cqcounter screenshots don't offer too much information, but having the wayback machine ones could actually reveal new fingerprints and other website information leaks.
We've had a very quick look, and while there was nothing mind blowing, there were some small finds.
Starting December 2004, the "Submit your favored carlson quote" of alljohnny.com was mind blowingly switched to point to https://washington.serversecured.net/~alljohnn/cgi-bin/memlog.cgi thus likely leaking the control site URL. Beauty. It previously pointed to web.archive.org/web/20040901162621/https://secure.alljohnny.com/cgi-bin/memlog.cgi
mynepalnews.com actually has several archives for a /stats path which contains HTML reports generated by Webalizer, an analytic tracker that tracks the source of incoming traffic!!! It is hard to believe that the CIA would have left that there. Particularly ridiculous is the presence of
inurl:cgi server_software at web.archive.org/web/20110204095809/http://mynepalnews.com:80/stats/usage_200805.html which is almost certainly a Google dork search, which we know is something that the Iranians used to find the websites. That search hits under /cgi-bin/check.cgi. That page is itself os some interest containing SERVER_ADMIN = mmadev@mmadev.com. web.archive.org/web/20110204095815/http://mynepalnews.com:80/stats/usage_200806.html also reveals several request IPs. Even if this is not a CIA website, there's a chance we could find the IP of the Iranian counter-intelligence in these IP list, it's mind blowing. There's lots of referrer spam too as well. Further HTML inspection however seems to show close relationship to that HTML and other confirmed hits.globaltourist.net, if is actually a hit, likely has a a 2003 archive, which would be our earliest hit archive so far.
A fun fact is that looking at the source code of: web.archive.org/web/20130828122833/http://euronewsonline.net/euro_bus.php we noticed an interesting comment:which clarifies that the CIA likely used Adobe ImageReady to cut up the images for Split header images:We also understand that the tool likely outputs the layout to HTML directly, and leaks the adobe projects filenames (.pds files) in the process.
<!-- ImageReady Slices (enewsweather.psd) -->Adobe ImageReady was a bitmap graphics editor that was shipped with Adobe Photoshop for six years. It was available for Windows, Classic Mac OS and Mac OS X from 1998 to 2007. ImageReady was designed for web development and closely interacted with Photoshop
After yet another awesome announcement by DeepMind that it had improved theoretical 4x4 matrix multiplication reducing the number of scalar multiplications with its AlphaEvolve system, I decided to have a look at the smallest open size 3x3 to understand what was going on in there.
I've dumped what I gathered at:
Announced at:
I can't believe I had missed that meme until now, and I couldn't resist the temptation to translate it
Xi Jinping saying those against raise their hands (2017)
Source. Xi Jinping saying those against raise their hands (2022)
Source. Those against raise their hands Xi Jinping remix by Ciro Santilli
. Source. I also couldn't resist a Kdenlive exercise in voice sampling. It was remarkably easy to do, not bad.Announced at:
I made not one but two quick presentation videos about my project Linux Kernel Module Cheat, an emulation setup to study and develop the Linux kernel and more:
- www.youtube.com/watch?v=HDJFyCma32U: a presentation of me talking about it, edited up from my earlier presentation at Aratu Week 2024
- www.youtube.com/watch?v=fgDhe1tN50o: a demo of me running actually the project
I had meant to do this editing for a while and kept pushing it off because editing hurts, but finally sat down did it, partly prompted by my quick recent updates made to the projects part of post OurBigBook job search round 2025. At first I was thinking of making a single video, but after I recorded the demo a bit it seemed like two separate ones would make more sense.
I also created a bug report for Kdenlive, the video editor that I used, for a freeze that happens if you try to shift + delete the last item of the timeline: bugs.kde.org/show_bug.cgi?id=504103. Kdenlive is a good editor, but unfortunately it has new freezes and crashes relatively often.
One more useless task that I get off my head, on to the next!
Announced at:
I shouldn't be doing this on funded OurBigBook time which is until the end of May, but I was getting too nervous and decided to start a casual job search to test the waters.
In particular I want to see if I can get past the HR lady step without toning down my online profiles. If nothing works out for the next round I'll be hiding anything too spicy like:Another interesting point is to see if French companies are more likely to reply given that Ciro Santilli studied at École Polytechnique which the French worship.
- prominently seeking funding for OurBigBook on my LinkedIn profile
- CIA 2010 covert communication websites references. This will be my first job hunt since I have published that article. Wish me luck.
- gay Putin profile picture on Stack Overflow

Gay Putin, currently used in Ciro Santilli's Stack Overflow profile
. Ciro's profiles may be a bit too much for the HR ladies who reject his job applications on the spot. To be fair, perhaps not enough years of experience for certain applications and job hopping may have something to do with it too. But since they don't ever tell you anything not to get sued, we'll never know.I'm looking in particular either for:
- machine learning-adjacent jobs in companies that seem to be doing something that could further AGI, e.g. automatic code generation or robotics would be ideal
- quantum computing
- systems programming, which is what I actually have work experience with
I spent the last two weeks doing that:
- one week browsing everything of interest in London and Paris and sending applications to anything that seemed both relevant and interesting. Maintaining an application list at: Section "Job application by Ciro Santilli".
- one week on a very laborious but somewhat interesting take home exercise for Linux kernel engineer a Canonical, makers of Ubuntu.I had a week to finish 5 practical coding and packaging questions, and I tried to do everything as perfectly as possible, but I somewhat underestimated the amount of work and wait needed to do everything and didn't manage to finish question 4 and missed 5. Oops let's see how that goes.At least this had a few good outcomes for the Internet as I tried to document things as nicely as I could where they were missing from Google as usual:
- I re-tested Linux Kernel Module Cheat and made some small improvements. Things still worked from a Ubuntu 24.10 host (using Docker to Ubuntu 22.04), and I also checked that kernel 6.8 builds and GDB step debugs after adding the newly required config
CONFIG_DEBUG_INFO_DWARF_TOOLCHAIN_DEFAULT, also mentioned that at: Why are there no debug symbols in my vmlinux when using gdb with /proc/kcore? - I contributed some simple updates to github.com/martinezjavier/ldd3 getting it closer to work on Linux kernel v6.8. That repository aims to keep the venerable examples from Linux kernel module book LDD3 alive on newer kernels, and is a very good source for kernel module developers.
- How to compile a Linux kernel module?: wrote a quick Ciro-approved tutorial
- Dynamic array in Linux kernel module: I gave an educational example of a dynamic byte array (like std::string) using the kvmalloc family of allocators
- quickemu: this is a good emulator manager and I think I'll be using it for Ubuntu images when needed from now on. I wrote:
- How to run Ubuntu desktop on QEMU?: an introductory tutorial to the software as their README is not that good as is often the case. It's hard for project authors to predict what new users want or not. This is my second answer to this question, the previous one focusing on a more manual approach without third party helpers.
- How to share folder between guest/host? (Quickemu): I explained how to setup a 9p mount to share a directory between guest and host
- Error :: You must put some 'source' URIs in your sources.list: updated this answer for Ubuntu 24.04. This issue comes up when you want to do either of:which don't work by default, and my answer explains how to do it from the GUI and CLI. The CLI method is specially important for Docker images. Since Ubuntu doesn't offer a stable CLI method for this, the method breaks from time to time and we have to find the new config file to edit.
sudo apt build-dep sudo apt source - What is hardware enablement (HWE)?: I learned a bit better how Ubuntu structures its kernel releases for each Ubuntu release

Figure 3. Linux kernel version used for each Ubuntu release. Source. In particular, Ubuntu has HWE kernels which are updated kernels for older releases. E.g.- 24.04.0 and 24.04.1 had kernel 6.8
- 24.04.2 moved up to kernel 6.11, the same one used in 24.10, to support newer hardware
Some of the main issues I had were:- compiling Linux kernel for Ubuntu is extremely slow. I was used to compiling for embedded system with Buildroot, which finishes in minutes, but for Ubuntu is hours, presumably because they enable as many drivers as possible to make a single ISO work on as many different computers as possible, which makes sense, but also makes development harder
- my QEMU setup for Ubuntu was not quite as streamlined and I relearned a few things and set up quickemu. By chance I had recently come across quickemu for testing OurBigBook on MacOS, but I had to learn a bit how to set it up reasonably too
- I re-tested Linux Kernel Module Cheat and made some small improvements. Things still worked from a Ubuntu 24.10 host (using Docker to Ubuntu 22.04), and I also checked that kernel 6.8 builds and GDB step debugs after adding the newly required config
I'll make sure to add two weeks of OurBigBook work after May to make up for this.
This is an update to the article: Section "CIA 2010 covert communication websites"
While procrastinating I suddenly remembered that cqcounter.com/siteinfo/ has screenshots of many many old websites, and I decided to look at possible hits in known IP ranges for which the Wayback Machine archive was broken.
Luckily I had already maintained a clear list of known domains in IP ranges which had no or broken wayback machine archive, so I just went over those.
This led to finding 60 novel screenshots of previously examined domains that are in common CIA-style, thus confirming them as hits beyond reasonable doubt in my mind. This also publicly revealed for the first time how a few new websites looked like, and what was their content, and in particular the target language, which could sometimes not be easily determined from the domain name alone.
This novel CQ Counter screenshot interpretation, plus a few new random discoveries and a slight relaxation of fingerprint requisites described described below moves us to 473 hits up from the previous 397!
The newly found websites were all just soulless bulk or mildly cute like the vast majority of them, but I did find found a few new screenshots of CIA websites that targeted other democracies:
- affairesdumonde.com (France)
- romulusactualites.com (France)
- ordenpolicial.com (Spain)
- vejaaeuropa.com (Brazil)
- european-footballer.com (Croatia)
I've also decided to now classify garanziadellasicurezza.com (Italy) as a hit due to various forms of supporting evidence being present. The archive is very broken however unfortunately.

2011 cqcounter archive of affairesdumonde.com targeting France
. Source. 
2011 cqcounter archive of romulusactualites.com targeting France
. Source. 
2011 cqcounter archive of ordenpolicial.com targeting Spain
. Source. 
2011 cqcounter archive of vejaaeuropa.com targeting Brazil
. Source. 
2011 cqcounter archive of european-footballer.com targeting Croatia
. Source. The fingerprint of "having a visually similar CQ Counter screenshot" is definitely weaker than a Wayback Machine archive as we only have a screenshot and can't inspect the HTML to find the communication mechanism. But when the screenshot is perfectly in CIA style and in a known IP range, the evidence is too strong and we'll consider it as a hit moving forward.
I'm also going to reclassify a few previously known domains in confirmed IP ranges as hits as hits either when:This is a slight moving of goalposts, but those cases just feel overwhelmingly probably.
- they have Wayback Machine archives with matching visual style
- they have broken Wayback Machine archives but with indication of comms or known HTML elements like rss-item
I love how this project has led me to use whatever random sources come in hand! CQ Counter is the ONLY website that I know of besides the Wayback Machine that has historical screenshots of a huge number of domains. Their database is VERY complete. But they are so obscure!
They even have the old IP of the domain. But because they don't have reverse IP to domain reverse search, and are heavily CAPTCHAed preventing search engines from properly indexing them, we can't use them to fill in existing IP ranges... So the search for the most complete DNS database that doesn't cost 15k USD like DomainTools continues www.reddit.com/r/OSINT/comments/1j8uasm/does_domaintools_offer_historical_reverse_ip_ie/
Interestingly a large number of the websites with broken Wayback Machine are from regions outside of the USA, presumably being slower to load from Wayback Machine US-based servers makes he archives more likely to break.
Announced at:
I have come to realize that a few of the websites do seem to use virtual hosting, i.e. multiple domains per IP, and I put a bit more manual effort into looking at known possible IPs that had a relatively small number of domains in them.
This led either to finding a few new domains, or placing existing domains in the same IP as another domains.
From now on I'll consider any IP with more than two hits to be an "IP range".
The new finds around other pre-existing domains are:
- 199.19.110.7 (theworldnewsfeeds.com):
- 207.150.191.68 (technologypresstoday.com)
- 216.93.248.194 (esmundonoticias.com)
- 216.104.38.110 (all-sport-headlines.com)
Furthermore, I now found new hits on nearby IPs of 209.162.192.49 rastadirect.net which was given by Reuters, thus establishing a new IP range there. Apparently I had simply failed to check IPs around one of the possible reverse IPs for it. The new finds are:
- 209.162.192.44 thejewelofsouthamerica.com
- 209.162.192.51 yellow-chair-report.com
- 209.162.192.57 globalnewsreports.net
- 209.162.192.59 easytravelsite.net

2010 Wayback Machine archive of thejewelofsouthamerica.com
. Source. I also understood a bit better the Mass Deface III pastebin pastebin.com/CTXnhjeS discovered by Oleg Shakirov which contains some hits: I think that the hits are purely coincidental when some hacker broke into "Condor Hosting" systems and then defaced several websites it contained, inadvertently also taking down some CIA websites along the day which is funny.
And this seems to be a small host chosen by the CIA, so it contained a disproportionate dense concentration of CIA hits. But the original hackers likely had no idea of what they did. www.zone-h.com/mirror/id/18994983 suggests that Iranian hacker group Sejeal was behind the defacing.
I also squeezed a few of the previously known IPs without clear range a bit harder on viewdns.info, as I now understand that there do exist a few websites that share the same IPs. This led to X entirely new hits, and also me moving a few domains that were previously marked as "unknown range" to a specific IP when two or more domains were found in a given IP.
I also squeezed whoisXMLAPI harder but nothing much came out.
The vast majority of domains use domainsbyproxy.com privacy which does not seem to leak any information on their whois except dates which appear well spread out.
I did notice however that some of the sites are registered with Network Solutions, LLC and a few others in Godaddy without domainsbyproxy.com. These have names of people on them, and I did as many whoisXMLAPI searches for those names as I had the patience for.
A few had another known hit on the results, and a new hit domain came out of this: rolling-in-rapids.com which as it turns out has no Wayback machine archive, but does have a CQ Counter archive which allowed me to confirm the hit page style. That one was found by reverse searching for the registrant of
alljohnny.com, "Glaze, L." on tools.whoisxmlapi.com/reverse-whois-search and its IP matches 65.218.91.9 from welcometonyc.net.If anyone would like to donate 140 USD to dump into whoisXMLAPI I could dump all the known hit histories and have a look at them to see if anything else comes out on reverse search.

I also started to better note down the IP owner and location of each IP range from viewdns.info at Hits with nearby IP hits, as this is an important information which could offer further clues. All IPs in each range belong to the same provider, since IPs are generally bought in blocks. For example:These don't necessarily tell us directly who the CIA hosted with, since in some cases hosting providers can indirectly rent out IPs from other providers, e.g. Heroku uses AWS. But it does suggest that some nearby IP ranges were done on the same hosting provider while others weren't.
- 62.22.60.49 telecom-headlines.com was owned by the company UUNET and hosted from Spain, and the same is true for neighboring IPs such as:
- 62.22.60.48: currentcommunique.com
- 62.22.60.52: collectedmedias.com
- 63.131.229.12 cyberreportagenews.com was owned by the company ADHOST and hosted from Coeur d'Alene - United States. Interestingly US-based hosts also offer city-level information while foreign ones don't.
I'm not sure about this and it's not very useful, but the following were cute.
216.105.98.132 europeantravelcafe.com is a very likely hit that:This suggests that this was an internal site management link for the site operators which was later noticed and removed across versions, leaking the management method in the process.
- had a "Plan Your Trip" link in 2010: web.archive.org/web/20100724024623/http://www.europeantravelcafe.com/ linking to an external website: secure-cert.net/~etc/transport.html
- and had the link removed in 2011: web.archive.org/web/20110201192245/http://europeantravelcafe.com/
2010 Wayback Machine archive of www.europeantravelcafe.com
. Source. The suspicious "Plan Your Trip" link that was later removed is highlighted with an arrow made by us.199.187.208.12 webofcheer.com has an exceedingly weird HTML page title:which feels like it could be a leak of an internal identifier for this website, or perhaps even worse, for the CIA program itself.
pg1c
- affairesdumonde.com
- american-historyonline.com
- arborstribune.org
- atthemovies.biz
- aviation-navigation.com
- bookmarksthis.com
- bosniakbusinessnews.com
- cityworldnewsnow.com
- classic-rocktopia.com
- classicalmusic4arab.com
- delacorne.com
- dynamicworldnews.com
- econfutures.com
- efiinvestment.com
- etherealinspirations.net
- european-footballer.com
- focusonbokeh.com
- foodwineandsuch.com
- fuenteneta.com
- garundipost.com
- gazingvoyage.com
- global-headlines.com
- goldeportesnoticias.com
- greek-news.info
- i7diver.com
- ilat-news.com
- internationalwhiskylounge.com
- itechnewstoday.com
- kioni-sailing.com
- large-format-news.com
- luxuryfive.net
- news-unlimited.info
- newsforthetech.com
- newsidori.com
- noticiasdenuestromundo.com
- nrgconsultingandnews.com
- ordenpolicial.com
- pohandakhbar.com
- prebitinvestment.com
- premierstriker.com
- rolling-in-rapids.com
- romulusactualites.com
- russiaupdate.com
- screencentral.info
- sportsman-elite.com
- talkingpointnews.info
- teclafinance.com
- the-golden-rule.info
- the-news-zone.com
- the-tech-mind.com
- theventurenews.info
- todaysportscores.com
- topfootballnewsonline.com
- travel-passage.com
- urbestbod.com
- urouttahere.com
- vejaaeuropa.com
- waronfilmonline.com
- worldfeedstoday.com
- worldnewsandtravel.com
This is an update to the article: Section "Base58 messages".
While self Googling a bit, I found this paper Bitcoin Burn Addresses: Unveiling the Permanent Losses and Their Underlying Causes by Mohamed el Khatib and Arnaud Legout briefly cited Cool data embedded in the Bitcoin blockchain.
In that paper, they attempted to find Base58 Bitcoin addresses that looked as if they were fake and used only in order to contain Base58 data.
While we had previously explored a few Base58 messages, this was something that had been done mostly ad-hoc simply by looking at transactions with large amounts of unspent outputs. As a result, any smaller messages were missed.
By looking through the data produced by the those researchers, we managed to find many new Base58 messages, and highlighted many of the most interesting early messages at: Section "Base58 messages".
The cutest new example is tx dea183908e40e0cebfee6a0d8362b299e07cf193fbc02ffd3308b43781eca208 (2011-11-24) containing Eric Lombrozo's minimalistic wedding contract to Sandra Sandic:
1EricLombrozoXXXXXXXXXXXXXXXWACBVB
1969SandraSandicXXXXXXXXXXXXXvdEiUAnnounced at:
This is an update to the article: Section "CIA 2010 covert communication websites"
I found 44 new covert websites made by the CIA around 2010 bringing the total to 397!
Most websites were boring as usual, but one was slightly cooler: webofcheer.com is a comedy fansite featuring Johnny Carson, Charles Chaplin, Rowan Atkins (of Mr. Bean fame), The Three Stooges and some other Americans no one knows about anymore. There must have been a massive Johnny Carson amongst the contractors at that time, given that we previously also knew about
alljohnny.com, a site dedicated fully to him! Both of these sites also serve as some of the earliest examples we've got so far, dating back to 2004 and 2005.
2011 Wayback Machine archive of webofcheer.com
. Source. 
2011 Wayback Machine archive of webofcheer.com scrolled to show Johnny Carson
. Source. 
2004 Wayback Machine archive of alljohnny.com
. Source. This one was a previously known website featuring Johnny Carson.Another cool discovery is that I found the Getty Images source of the Jedi boy on their Star Wars themed site starwarsweb.net: web.archive.org/web/20101230033220/http://starwarsweb.net/ The photo can still be licensed today as of 2025: www.gettyimages.co.uk/detail/photo/little-jedi-royalty-free-image/172984439. I found it by searching for "jedi boy" on gettyimages.co.uk. The photo is credited to username
madisonwi, presumably an alias of a photographer from Madison, Wisconsin. Inspired by this I reverse image searched and found the source of many other stock images from other websites, and I pinged their authors whenever I could locate them e.g. x.com/cirosantilli/status/1899750172260806711.
Stock photo of a Jedi boy from Getty Images used on starwarsweb.net
. Source. 
2010 Wayback Machine archive of starwarsweb.net
. There were two small advances that led to the discovery of new domains:
- while looking for a way to procrastinate I decided to scrape justdropped.com/drops/ for fun. That website lists expired domain names and see if it would yield any new results.I had already scrapped other expired domain websites before and used that data, and I hoped that this one would provide some new domain hits, even though it had very large overlap with the other websites I had scraped domains from previously.Such domain name lists tend to contain all SCAM domains in existence, since those inevitably expire once the scammers are caught.
- even more importantly, I noticed by chance that I was being too strict on a small part of my fingerprinting which was excluding a few good domains, by removing any hits that had multiple archives of the Communication mechanism
With those two new developments, I then kicked off my pre-existing search pipelines searching for domain names with the word
news on them, an amazingly efficient heuristic because many of the websites were disguised as news aggregators, and after a few hours theses new hits emerged. A few of those also led to the discovery of new IPs which then led to new domains.One entirely new IP range was found around fastnews-online.com from 208.93.112.105 to 208.93.112.125. There were many domain names with very promising names in the range, but unfortunately for some reason most didn't have Wayback Machine Archives so I didn't count them as hits as per my guidelines.

2009 Wayback Machine archive of fastnews-online.com
. Also the newly found todaysengineering.com at 208.254.38.39 appears to form an IP range with the previously known nejadnews.com at 208.254.38.56, but I couldn't find any other domains in the region with our current data sources.

2011 Wayback Machine archive of todaysengineering.com
. All other domains either slot into previously known IP ranges, or more commonly don't currently have a known IP, though they would likely just slot in existing ranges if we had better data.
Thanks to Jack Rhysider from the Darknet Diaries podcast for pointing me to the existing of the 2022 Reuters article that kickstarted my research on the subject!
One outcome of this update is that I've increased my jq level to better automate the maintenance of the hits.json file were I store all the known websites in JSON format. I love that tool so much, I managed to merge two JSONs with it removing duplicates and then sort the JSON as desired. Beauty.
The full list of newly found websites is:
- cellar-notes.com
- dailywellnessnews.com
- differentviewtoday.com
- dryterrainnews.com
- euronewsonline.net
- fastnews-online.com
- financecentraltoday.com
- globalcitizennews.net
- globalinvestmentnews.net
- inkfreenews.com
- internationalnewsworthiness.com
- intoworldnews.com
- lasthournews.com
- latinamericanewsbeat.com
- localtoglobalnews.com
- magneticfieldnews.com
- middle-east-newstoday.com
- mideasttoday.net
- mydailynewsreport.com
- mynepalnews.com
- nbanewsroundup.com
- nejadnews.com
- networkconnectionsite.com
- news-and-sports.com
- newsdelivered.net
- pondernews.net
- profile-news.com
- purlicue-news.com
- sandstormnews.com
- segomonews.com
- shadesofnews.com
- technologypresstoday.com/
- the-news-scene.com
- thefootball-life.com
- thefreshnews.com
- thenewsofpakistan.com
- totallynewsnow.com
- travelxtreme.net
- webofcheer.com
- wiredworldnews.com
- world-news-online.net
- worldaroundyunnan.com
- worldofonlinenews.com
Announced at:
- mastodon.social/@cirosantilli/114156495883418926
- x.com/cirosantilli/status/1900249928653271334
- www.facebook.com/cirosantilli/posts/pfbid02LbrfezGmFik582d6H7ZEoCf9bwpU73vyivdGLVbbzWjejWLS5Rv9EjGNXBPQppUBl
- www.linkedin.com/posts/cirosantilli_httpslnkdineyu8qwc-i-found-44-new-covert-activity-7306015949374058496-X5zl/
This is a summary of the status of the OurBigBook Project, focusing notably on the past 9 months that I've been able to devote fully to it starting June 2024 notably due to the anonymous 1000 Monero donation and other supporters.
I have 3 months left and after unless some crazy person gives more money, I'll go back to some generic programming job that could be done by many other people so that my wife won't kill me. Hopefully I'll find something in quantum computing or AGI research this time that is not too boring, but we'll see.
I should also note that I have raised my requirement for a second year full time from 100k USD to 200k USD, such that there are about only 144k USD missing as of writing, a bargain. See also Section "Sponsor Ciro Santilli's work on OurBigBook.com". I have also set a 2M USD retirement goal in case someone wants to free me to lurk after university students for the rest of my life. Creepy.
The reason for this increase is partly because I'm jealous watching my university peers getting relatively richer and richer than me. More seriously though, as I'm likely going to be looking for a job soon, I don't want to scare employers off too much thinking that it is likely that I'll be leaving in a few months too easily. Plus inflation and the natural lack of security that such endeavour brings.
OurBigBook Project 2025 one year funded work debrief by Ciro Santilli
. Source. This video debriefs the end of the 1-year-funded 1000 Monero donation work in 2025, in addition to some personal remarks and what might come next.Long story short, the project is so far a complete failure on the most important metric: number of regular users, which current sits at exactly one: myself.
There were notable users who found the project online and who actually tried to use the website for some content and provided extremely valuable feedback:Unfortunately after the period of a few weeks they stopped using it to follow their other priorities instead. Which is of course totally fine, however sad.
I still believe that the OurBigBook Web feature is a significant tech innovation that could make the website go big.
I also believe that the project gets many fundamentals of braindumping right, notably the infinitely deep table of contents without forced scoping, e.g.:does not make Calculus have an ID orr URL of
- Mathematics
- Calculusmathematics/calculus, rather it's just calculus.Internal cross file internal link uses only the leaf ID
hilbert-space.But there is a fundamental difficulty in reaching critical mass to that self-sustaining point, as people don't seem to be convinced by these logical "my system is better" argument alone, as opposed to having them Google into stuff they need now and then understand that the project is awesome.
A closely related critical mass issue is that existing big multiuser knowledge base websites such as Stack Overflow and Wikipedia have a tremendous advantage on PageRank. No matter how useless a Wikipedia article about something is, it will always be on top of Google within a week of creation for title hits. And since the main goal of publishing your stuff is to get it seen, it makes much more sense for writers to publish on such existing websites whenever possible, because anywhere else it is way way less likely to be seen by anybody.
Even I end up writing way more on Stack Overflow than on OurBigBook as a programmer. But I still believe that there is a value to OurBigBook, for the usual reasons of:
- it allows you to organize a more global view of a subject, i.e. a book. Even I write answers on Stack Overflow, I also tend to organize links to these answers in a structured ways here, see e.g. big topics such as SQL
- deletionism and overly narrowness of allowed topics/style
Perhaps what saddens me the most is that even on GitHub stars/Twitter/Hacker news terms there is almost no interest in the project despite the fact that I consider that it has innovations, while many other note taking apps as well in the thousands of stars. Maybe I'm just delusional and all the tech that I'm doing is completely useless?
Part of the issue is probably linked to the fact that most other note taking apps focus on "help me organize my ideas so I can make more money" and often completely ignore "I want to publish my knowledge", and stuff that helps you make money is always easier to sell and promote.
OurBigBook on the other hand a huge focus on "I want to publish me knowledge". It aims almost single mindedly in being the best tool ever for that. However this doesn't make money for people, and therefore there are going to be way less potential users.
I do believe strongly that all it takes is a few users for the project to snowball. For some people, once you start braindumping, it is very addictive, and you never want to stop basically. So with only a few of those we can open large parts of undergrad knowledge to the world. But these people are few, and so far I haven't been able to find even a single one like me, and on top of that convince them that I have created the ultimate system for their knowledge publishing desires.
Another general lesson is that I should perhaps aimed for greater compatibility with existing systems such as Obsidian. Taking something that many people already know and use can have a huge impact on acceptance. E.g. anything that touches Obsidian can reach thousands of stars: github.com/KosmosisDire/obsidian-webpage-export. Note taking apps that aim for "markdown" compatibility also tend to fare better, even if in the end you inevitably have to extend the Markdown for some of your features. And WYSIWYG, which I want but don't have, is perhaps the ultimate familiarity.
Another issue compared to other platforms is that OurBigBook just came out late. Obsidian launched in 2020. Roam Research and Trillium Notes also came earlier. And it is hard to fight the advantage already gained by those on the "I'm going to take some personal notes" area. I do believe however that there a strong separation between "these are my personal notes" and "I want to publish these". Once you decide to publish your knowledge, you immediately start to write in a different way, and it is very hard to convert pre-existing "private" notes into ones suitable for public consumption.
At first I had intended to create a lot more content for the world class university located where I lived, but I ended up not doing that and just improving the project tech instead.
There are a few reasons for this, good or bad:
- as a tech nerd, my natural tendency is to first sit down by myself and code to solve big general problems rather than go out and try to solve specific people's specific problems to obtain money and users
- at one point I got the feeling that helping students with a bunch of small courses might be useful, and that instead I might get more impact by instead by focusing on creating content for a next big thing area such as: because many of the courses are fundamentally useless by design due to misalignment between university and reality.I'm still not sure what to do about that, but I do think I'll try to do a bit of course solving at least and see how it goes.One thing I've learned first hand through Ciro Santilli's Stack Overflow contributions and Linux Kernel Module Cheat is that the barrier to make money from a useful open source learning project that benefits a large number of people a little bit is huge, perhaps infinite, and that it might be better to instead focus more intensely on fewer users. This insight pushes me more towards going for solving local courses.Another consideration that supports going for courses is that being close to students is perhaps my only unfair advantage. There is likely no one else in the world in the same position that I'm at, with some "free time" to chill with undergrads and help them with 100% of my undivided attention and passion.A point that pulls me towards the big tutorials however is that my time is almost up, and focusing on them would increase the chances that I will be work in those fields afterwards. This feeling may go against the best interests of the project, but it is perhaps an inevitable self preservation consideration unless someone decides to free me from that forever with the 2M :-)
- the entry barrier to help students of a top university is rather high. The students are already extremely busy and pressured (this is pe), and if it is in the slightest hard to explain their problems to you because you are not fluent enough in their subject, they will find a faster way to obtain the knowledge and never come to you.
- I also did a bit of procrastinating with a few quick few exploration into cute programming projects. Nothing too crazy long however, just the usual. It's in my nature to have broad interests, and perhaps only such a person can make a OurBigBook.com. I'm not a fast worker. But I never stop. Once something is in my "this must be done or learnt list", I just keep coming back to it again and again until it happens.
The downsides of going for tech first are severe:There are however counterpoints to these as for anything else:
- you risk being misaligned with what users want and spend enormous amounts of time on useless features
- it is also rather demotivating that you are working hard on a really cool feature but you know that there are no users yet so no one will benefit from it, and that this feature alone is not enough to attract the users anyways
- I'm a user and I'm always improving it for myself. If there are other people like me out there, they will love it. If there aren't, perhaps I'll never be able to do anything that caters for them well enough anyways.
- as the two users made me understand, once someone touches your thing, they expect it to be perfect, and their standards are extremely high. This is understandable in part given the large number of note taking apps in existence, and notably WYSIWYG ones. As such, there is some rationale for improving tech.
In any case, the outcome of that is that the tech has improved. And I have done a relatively good job of clearly publishing any "more user visible" improvements to docs.ourbigbook.com/news and social media such as though it is important to note that there have been more than one "fix a hard bug" weeks that were not published because they would just bore readers.
During this period the main focus has been on improving OurBigBook Web, i.e. the dynamic website that powers OurBigBook.com. There are two reasons for that:As a result, Web is now way less buggy and much more usable.
- Web is what has the OurBigBook topics feature for mind-melding, which is the killer feature of OurBigBook compared to other note taking apps and therefore deserves the highest levels of priorityStatic website generation is an indispensable escape valve that ensures that your content can be published forever even if OurBigBook.com goes down one day, which it won't as long as I live. But the innovation is Web.
- static website generation was closer to good enough, but web was much further and is fundamentally harder.I'm extremely satisfied with OurBigBook static website generation and haven't touched it as much. It wasn't easy to reach this state, but I'm there.But Web is a different and much more complex beast.Making CLI software that will run on a person's local computer under full trust and building a bunch of HTML from lightweight markup in bulk is one thing.But making a public dynamic website that has to continuously maintain a coherent database state on granular updates, while giving users some trust but not enough for them to blow everything up is on a totally different level. See e.g. the recent SPAM attack we've had to fend off.

Figure 20. Screenshot showing voting manipulated SPAM as the most highly upvoted article on OurBigBook.com. Source.And then there's also the issue of front-end being mega-hard to get right.
If you look through the list of Web updates, there is nothing specifically mind blowing. The core ideas have largely crystallized, and we are just trying to making them click. I have a few more punches up my sleeve, but the core is decided.
OurBigBook Web search
. Source. This is one of the many basic quality of life improvements that have been done on OurBigBook Web.
OurBigBook Web article announcement
. Source. Another cute new feature, you can send an email to your followers about a new amazing article you created.Web process has been somewhat slower than what I'd like. Of course, it is the case of any project that things are easily said than done. But there are two other main structural factors that have played into it:
- I have my first baby now, and we're learning how to deal with that on the fly.For example, we could have put him on childcare a bit earlier, but due to inexperience we've kept him a bit longer than we maybe should have.Things are well sorted out now, but not matter how good your support system is, at the end of the day, and more often night, it is you the parents that have to deal with a lot of inevitable baby issues. Unless you want them to turn into psychopaths and drug addicts that is, which I don't. I've reached the point of semi failure middle age that the baby feels like my best moonshot.All of this sets a fundamental limit on how many hours you can work per week.But at least with the donations I was able to work on OurBigBook at all. Because if it weren't for that, I would have to focus entirely on the generic job instead and OurBigBook would have been put on hold.
- the choice of Web stack. I was allured by Next.js. I can see the beauty and usefulness of a Node.js render front-end that also runs on backend and hydration. That is awesome.But:
- React is insanely hard to learn and understand. Furthermore, it is also hard to understand the performance problem that it solves, and actually have a benchmark where this problem is solved faster than just delivering some HTML files with ad-hoc Js on top.
- the lack (or perhaps excess of shitty) actual web framework like Ruby on Rails and Django means that I have to rediscover the wheel many times over for all the essential support activities like testing, login and so one
At this point a rewrite is out of the question. I've managed to master things well enough to get a decent result, and given up on the few things that I couldn't for the life of me achieve, after documenting them very well for posterity of course.
Aside from Web, there was only one thing that received a significant improvement, and that was the OurBigBook VS Code extension. The extension is not perfect, and it is not the "final UI", which has to be some WYSIWYG implementation, and there are some fundamental limitations that cannot be overcome without patching VS Code itself. However, the extension is already extremely usable, and I'm writing this on it right now. Basics like syntax highlighting, jump to definition and autocomplete are very useful and usable.

Tree navigation in the OurBigBook Visual Studio Code extension
. OK, I need to do content. I know :-) At the university I'm at, the only department that is open is the mathematics one. Both:All other courses extremely closed, notably Physics, which is the other course I'd consider. There are upsides and downsides for going for Mathematics:If I were free to choose, I might go for Physics instead. But maths isn't hard, and I think I'll just go with the hand I'm dealt this time to start with.
- physically, I'm sitting next to some students right now, though they don't yet know that their saviour is just next to them.
- in terms of publishing the course materials online. Many of them even have solution
- upside:
- maths doesn't change with time
- maths doesn't require experiments
- downside: most of it is useless compared to Physics
Tech wise, the big things are the following ones to which I have given different levels of architectural consideration (i.e. read: I'm afraid they'll be fucking hard and that I'll spend a month on yet another useless feature that won't help get a single user). I don't think I'll do those before at least a little bit of content, we'll see:
- WYSIWYG: this is not a question of if, but when and how. Even I miss it when dealing with images. I was particularly impressed by Trillium Notes, and might consider forking it or reusing some of its components
- perfect two way sync from web to local: github.com/ourbigbook/ourbigbook/issues/326Currently, after much effort, publishing from local to web is extremely good.But pulling back changes that you make on web UI locally is not really possible. A basic version can be made easily, but a great version requires some thought.In particular, preventing accidental rewrite on simultaneous local + web edits require edit history to be in place.The rationale here is that users would start editing on Web with a low entry barrier. And as they become more committed to the project, they would eventually transition to having editing most of their content locally from a desktop, with the exception of a few minor edits on the go when they are on a cell phone, and which we want to very easily and automatically be pulled back to local as soon as they open an editor on their laptop.I.e. we want to add a downwards arrow to the following diagram:

Smaller cute tech that I might do before content "real quick" include:
- move more into community tagging rather than just community topic-ing:
- automatic topic rendering for plaintext! github.com/ourbigbook/ourbigbook/issues/356. In particular this could open the doors for AI generated content.
Another thing I really want to do before time is up is to create a video summarizing my philosophy of education. I want it to be as fun and funny and sad as possible, with silly moving animated images and slides, not just me talking to the camera. Although all of the points I intend to talk about have undoubtedly been covered by others, it is something that I feel so strongly about that I would like to tell others about it more personally. If I start it it will likely take a few days to get done, and I'm not sure wha the final quality would be. It is a bit sad to not do "project work", but I think I'll end up doing it regardless. Class it under "fundraising" if you will, as it may help to find other like minded but rich people.
It is a bit sad to work on a project that no one cares about. You're not sure if you're crazy or a visionary. And it is kind of lonely.
I sometimes wonder if I would be happy doing this for the rest of my life if I could. And if it would have any impact at all no matter for how long I do it. My feelings in that area go from slightly depressed to slightly excited about the potential a few times every week.
As we all know, living and making life choices means sacrificing other things that could have been. When I was in France in 2015, I started a masters course in AI/robotics with the idea of doing a PhD and AGI research later on but quit half way because I felt university was such a waste of time.
But come now the AI boom, and although I still believe Education is broken, I might have been much better off financially/reputationally if I had withstood the bullshit followed that path. Instead I sacrificed that for nerding about low level programming and open educational content.
It is hard to get such ideas off one's mind. But the fact is, for better or worse, I've started walking the path of educational reform and sacrificed others along the way, and this is the path that I'm further ahead than other people, and perhaps I should pursue it further to a possible conclusion. Also this path has the advantage that it is not fully exclusive from other academic endeavors as we will always need content about the new flashy things that keep coming up.
So yeah, it's hard, but here I am, and I'll go as far as I can without going into Charles Bukowski levels of personal sacrifice.
Announcements:
github.com/cirosantilli/cirosantilli.github.io/issues/198. Previously at: stackoverflow.com/questions/31321009/best-more-standard-graph-representation-file-format-graphson-gexf-graphml/79467334#79467334 but Stack Overflow fucking deleted the question.
I wanted to do a quick exploration of open PageRank implementation and data.
My general motivation for this is that a PageRank-like algorithm could be useful for more accurate user and article ranking on OurBigBook, see: Section "PageRank-like ranking"
But it could also be just generally cool to apply it to other graph datasets, e.g. for computing an Wikipedia internal PageRank.
A quick Google reveals only Open PageRank, but their methods are apparently closed source.
Then I had a look at the Common Crawl web graph data to see if I could easily calculate it myself, and... they already have it! See: Section "Common Crawl web graph official PageRank"
Their graph dumps are in BVGraph graph file format, which is the native format of the WebGraph framework, which implements the format and algorithms such as PageRank.
The only thing I miss is a command line interface to calculate the PageRank. That would be so awesome.
The more I look at it the more I love Common Crawl.
Announcements:
In cc-main-2024-25-dec-jan-feb-domain-ranks.txt:
cirosantilli.comwas ranked ~453kourbigbook.comwas at ~606k
I finally took a day to edit the Cool data embedded in the Bitcoin blockchain section from Aratu Week 2024 Talk by Ciro Santilli: My Best Random Projects into a proper YouTube video. The amount of effort that goes into every minute of video editing never ceases to amaze me.
My Bitcoin inscription museum by Ciro Santilli
. Source. Announcements:
- mastodon.social/@cirosantilli/113764420506911687
- x.com/cirosantilli/status/1875157694270841024
- www.linkedin.com/posts/cirosantilli_my-bitcoin-inscription-museum-images-and-activity-7280924162838126592-BVLX/
- www.facebook.com/cirosantilli/posts/pfbid02kN3sVVTViekYsgyqmN1pdcTp81ca7rJSmofk7X3DkdXYL6Rb8tEd78LoLYw7dEMSl
In 2024 I was user #25 with the most reputation gained on Stack Overflow.
This is up from #38 in 2023 is even though I have answered less questions than before.
This is likely because LLMs have killed users that just answered lots of easy new questions, and favored those like me who only answer more important questions found through Google.
I was #13 on the last quarter, so this is likely to go even higher in 2025. More details at: Section "Ciro Santilli's Stack Overflow contributions"
Announcements:
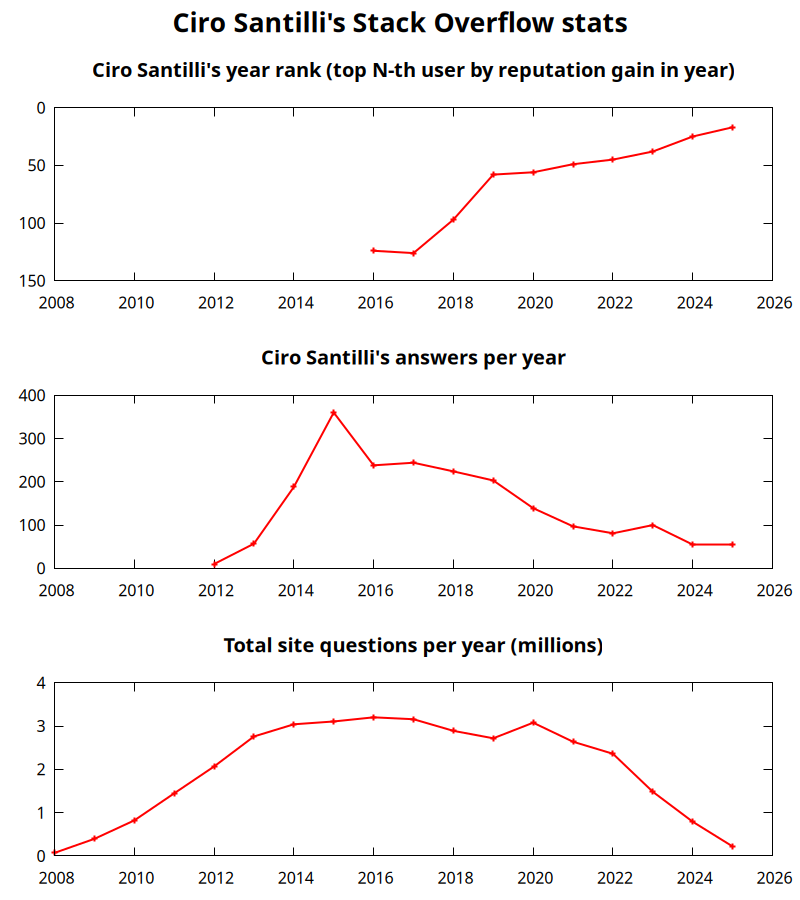
Ciro Santilli's Stack Overflow stats
. Further methodology details at: Figure 24. "Ciro Santilli's Stack Overflow stats".I've been thinking lightly about adding full text search to OurBigBook.
For example, at docs.ourbigbook.com/news/article-and-topic-id-prefix-search article search was added, but it only finds if you search something that appears right at the start of a title, e.g. for:you'd get a hit for:but not for
Fundamental theorem of calculusfundamentalcalculusTo do this efficiently, we need full text search, which PostgreSQL implements.
But finding a clean way to generate test data for testing out the speedup was not so easy and exploration into this led me to publishing a few new slightly improved methods where Googlers can now find them:
- unix.stackexchange.com/questions/97160/is-there-something-like-a-lorem-ipsum-generator/787733#787733 I propose a neat random "sentence" generator using common CLI tools like
grepandsedand the pre-installed Ubuntu dictionary/usr/share/dict/american-english:grep -v "'" /usr/share/dict/american-english | shuf -r | paste -d ' ' $(printf "%4s" | sed 's/ /- /g') | sed -e 's/^\(.\)/\U\1/;s/$/./' | head -n10000000 \ > lorem.txt- to achieve that, I also proposed two superior "join every N lines" method for the CLI: stackoverflow.com/questions/25973140/joining-every-group-of-n-lines-into-one-with-bash/79257780#79257780, notably this awk poem:
seq 10 | awk '{ printf("%s%s", NR == 1 ? "" : NR % 3 == 1 ? "\n" : " ", $0 ) } END { printf("\n") }'
- to achieve that, I also proposed two superior "join every N lines" method for the CLI: stackoverflow.com/questions/25973140/joining-every-group-of-n-lines-into-one-with-bash/79257780#79257780, notably this awk poem:
- stackoverflow.com/questions/3371503/sql-populate-table-with-random-data/79255281#79255281 I propose:
- a clean PostgreSQL random string stored procedure that picks random characters from an allowed character list
CREATE OR REPLACE FUNCTION random_string(int) RETURNS TEXT as $$ select string_agg(substr(characters, (random() * length(characters) + 1)::integer, 1), '') as random_word from (values('ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789- ')) as symbols(characters) join generate_series(1, $1) on 1 = 1 $$ language sql; - first generating PostgreSQL data as CSV, and then importing the CSV into PostgreSQL as a more flexible method. This can also be done in a streaming fashion from stdin which is neat.
python generate_data.py 10 | psql mydb -c '\copy "mytable" FROM STDIN'
- a clean PostgreSQL random string stored procedure that picks random characters from an allowed character list
- stackoverflow.com/questions/16020164/psqlexception-error-syntax-error-in-tsquery/79437030#79437030 regarding the safe generation of prefix search
tsqueryfrom user inputs without query errors, I've learned aboutwebsearch_to_tsqueryand further highlighted a possibletsquery -> text -> tsqueryapproach that might be correct for prefix searches - stackoverflow.com/questions/67438575/fulltext-search-using-sequelize-postgres/79439253#79439253 I put everything together into a minimal Sequelize example, read for usage in OurBigBook
Finally I did a writeup summarizing PostgreSQL full text search: Section "PostgreSQL full-text search" and also dumped it at: www.reddit.com/r/PostgreSQL/comments/12yld1o/is_it_worth_using_postgres_builtin_fulltext/ for good measure.
This one was way harder than my previous fun with "find the oldest people who won a given prize" (Nobel Prize/Oscar) mastodon.social/@cirosantilli/112689376315990248 because unlike those prizes where all the decisions are centralized, countries are much more complicated beasts, with changing currencies and international recognition.
This was a good experience to see a few ways in which Wikidata is inconsistent, with the same concept being expressed in multiple different ways, e.g. "end time" property of the current vs the superior "end time" qualifier.
Particularly bad is the notion of a "deprecated rank", that should really not exist.
This is exactly the type of semi interactive data munching that I like to do, a bit in the same vein as CIA 2010 covert communication websites and Cool data embedded in the Bitcoin blockchain.
As you might imagine, the secret services use exactly this type of knowledge modelling to do their dirty business, e.g. Gaffer by the GCHQ.
If only I weren't such a rebel, I'd be a perfect fit for the intelligence agencies.
This is the best monstrosity I had the patience to come up with:It got quite close to the ISO 4217 list.
SELECT
?currency
(GROUP_CONCAT(DISTINCT ?currencyIsoCode; SEPARATOR=", ") AS ?currencyIsoCodes)
?currencyLabel
(GROUP_CONCAT(DISTINCT ?countryLabel; SEPARATOR=", ") AS ?countries)
WHERE {
?country wdt:P31/wdt:P279* wd:Q6256. # is country
?country p:P38 ?countryHasCurrency.
?countryHasCurrency ps:P38 ?currency.
?countryHasCurrency wikibase:rank ?countryHasCurrencyRank.
OPTIONAL {
?currency p:P498 ?currencyHasIsoCode.
?currencyHasIsoCode ps:P498 ?currencyIsoCode.
}
FILTER NOT EXISTS {?country wdt:P576 ?countryAbolished}
FILTER NOT EXISTS {?currency wdt:P576 ?currencyAbolished}
FILTER NOT EXISTS {?currency wdt:P582 ?currencyEndTime}
FILTER NOT EXISTS {?countryHasCurrency pq:P582 ?countryHasCurrencyEndtime}
FILTER (?countryHasCurrencyRank != wikibase:DeprecatedRank)
FILTER (!bound(?currencyHasIsoCode) || ?currencyHasIsoCode != wikibase:DeprecatedRank)
# TODO makes query take timeout? Why? Needed to exclude PLZ.
FILTER NOT EXISTS {?currencyHasIsoCode pq:P582 ?currencyHasIsoCodeEndtime}
SERVICE wikibase:label {
bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en".
?currency rdfs:label ?currencyLabel .
?country rdfs:label ?countryLabel .
}
}
GROUP BY ?currency ?currencyLabel
ORDER BY ?currencyIsoCodes ?currencyLabelI was drawn into this waste of time after I noticed that someone had managed to create the Wikipedia of PsiQuantum which I had tried earlier but got deleted: mastodon.social/@cirosantilli/113488891292906243, and then I made the mistake of having a look at the Wikidata page of PsiQuantum.

500,000 Transnistrian ruble banknote 1997 series
. This is one of the most widely used currencies which does not have an ISO 4217 code.Announcements:
I also had one more fun with: opendata.stackexchange.com/questions/15750/structured-data-for-nobel-prizes/21847#21847 getting some basic info about Nobel Prize winners, and noticed one, John Sulston, 2002 Nobel Prize in Physiology and Medicine laureate, who likely has the wrong place of birth on his Nobel Prize profile: www.nobelprize.org/prizes/medicine/2002/sulston/facts/ which is funny. I suggested the change now. Edit they fixed it after I pointed it out:
Another highlight was 1913 Nobel Prize in Chemistry laureate Alfred Werner who born either in Mulhouse in Alsace, France, or in "Yo no sé qué me pasó" ("I don't know what happened to me" in Spanish), a 1986 song by Mexican singer Juan Gabriel.
Announcements:

Also at opendata.stackexchange.com/questions/21849/how-to-get-a-list-of-all-nobel-prize-winners-who-never-had-a-doctorate-from-wiki/21850#21850 I tried to get the list of Nobel Prize laureates who don't have a PhD. I think the query was correct, but Wikidata data is just too incomplete. Related:
I edited the VOD of the talk Aratu Week 2024 Talk by Ciro Santilli: My Best Random Projects about the CIA 2010 covert communication websites a bit and published it at: www.youtube.com/watch?v=TFfuzZC5Qpc.
Announcements:
On September 2024, GitHub forbade our China Dictatorship auto-reply bot, the reason given is because they forbid comment reply bots in general. Though it was cool to see a junior support staff person giving out what obviously triggered the action:before a more senior one took over.
We've received a large volume of complaints from other users indicating that the comments and issues are unrelated to the projects they were working on.
Ciro was slightly saddened but not totally surprized by the bloodbath against him on the Reddit the threads he created:
- www.reddit.com/r/github/comments/1g7acv6/github_forbade_me_from_running_a_bot_that_would/ deleted by admins becausewhich is stupid, obviously we should be able to discuss GitHub policies in that sub.
We don't work for GitHub and we can't help you with your GitHub support problems. You'll just need to be patient.
Also good highlight to user whoShotMyCowReply:Has GitHub also forbidden you from, say, getting a job
Reply:No, a 120,000 USD donation did that: cirosantilli.com/sponsor#1000-monero-donation
Many successful people are neurodiverse comes to mind.Can't hate on the grind but I think you should also consider psychiatric help
- www.reddit.com/r/China/comments/1g7aa6k/american_programming_website_github_forbade_me/: also deleted without reason
So we observe once again the stupidity of deletionism towards anything that is considered controversial. The West is discussion fatigued, and would rather delete discussion than have it.
We also se people against you having freedom to moderate your own repositories as you like it, with bots or otherwise. Giving up freedoms for nothing, because "bot is evil".
Announcements:
academia.stackexchange.com/questions/213576/do-copyright-transfer-of-papers-to-publishers-affect-when-the-paper-enters-the-p Do copyright transfer of papers to publishers affect when the paper enters the public domain since copyright belongs to a corporation and not persons?
I'm asking a law question for a change, because I enjoy skimming through important old papers and uploading parts of them where everyone can legally enjoy them.
Announcements:
I like the Falun Mine for two reasons:
- some cool chemical discoveries have been made with a relation to the mine, notably tantalum and selenium, added a section to Wikipedia: en.wikipedia.org/w/index.php?title=Falun_Mine&oldid=1245374294#Discovery_of_new_elements I used the book discovery Of The Elements by Mary Elvira Weeks as my primary reference.
- it is the Chinese version of the Scunthorpe problem due to a naming conflict with Falun Gong, a censored new religion that was banned in China
Announcements:
Whenever a user creates an issue or comment on China Dictatorship, the bot now automatically creates a new issue with one of the latest news from Duty Machine: github.com/duty-machine/duty-machine
Sample created issue: github.com/cirosantilli/china-dictatorship/issues/1322 Script: github.com/cirosantilli/china-dictatorship/blob/ab6a46c511afaaf6c9e68ba8813c2b2cf9d9638c/action.js#L195
Duty Machine is a bot repo that automatically scrapes Chinese language news from major news outlets such as the New York Times or Radio Free Asia which ensures that China Dictatorship news will always be new.
It's the war of the anonymous bots against the little pinks, part of asymmetric information warfare: cirosantilli.com/china-dictatorship/asymmetric-information-warfare
Announcements:
Update September 2024: GitHub blocked the China Dictatorship bot
Update March 2025: duty-machine was DMCA'ed on February 2025: github.com/duty-machine/news by, surprise surprise, a Chinese copyright owner "Sanlian News" github.com/github/dmca/blob/master/2025/02/2025-02-27-sanlian-news.md I noticed because it broke my Action on another repo: github.com/orgs/community/discussions/154227 Announcements:
superuser.com/questions/420885/is-there-a-face-recognition-command-line-tool/1852394#1852394 played with the
face_recognition Python package: github.com/ageitgey/face_recognition Cute CLI API, but disappointing accuracy. Also at:Thanks Adam Geitgey for putting that repo up.

Announcements:
Under Section "Publication by Marie Curie" I did a quick overview of the papers in which Marie Curie and collaborators publish the existence of new elements polonium and radium. Both are very understandable (except the chemistry), and have some cute terminology. I also cited those papers on her Wikipedia page: en.wikipedia.org/w/index.php?title=Marie_Curie&diff=1240252528&oldid=1238097626 Another good exercise in "old paper finding" + "Wikipedia markup/rules" as I looked at the Comptes rendus de l'Académie des Sciences a bit.

{kind=link}
{kind=link}
{kind=link}
This was kickstarted by YouTube recommending me the following good video:
which led me into yet a quick nuclear physics binge. I shouldn't do this to myself. I also ended up writing some tentative answers on Quora:
Announcements:
I tried to use every single free offline text-to-speech engine that would run on Ubuntu 24.04 without too much hassle to see if any of them sounded natural. pico2wave was the overall winner so far, but it is not perfect.
I've been noticing a gap between the "AI" SOTA and what is actually packaged well enough to be usable by a general audience.
Also played a bit more with OpenAI Whisper: askubuntu.com/questions/24059/automatically-generate-subtitles-close-caption-from-a-video-using-speech-to-text/1522895#1522895 Mind blowing performance and perfect packaging as well, kudos.
Announcements:
- en.wikipedia.org/wiki/Scott_Hassan I delved into a bit of Wikipedia drama on the page of Scott Hassan, initial coder of Google Search, which I created an am the main contributor.Originally I had added some details about this messy divorce which saw coverage in major publications such as the New York Times: www.nytimes.com/2021/08/20/technology/Scott-Hassan-Allison-Huynh-divorce.html and Scott used puppets to remove those at several points in time over the years.Those removals were then reverted by other editors, not myself, indicating that editors wanted the details there.While preparing to finally decide this through moderation, I ended up finding that the divorce details should likely have been left out according to Wikipedia rules, because Scott is "relatively unknown" and a "low profile individual":and so I ended up removing them myself.This is yet once again deletionism on Wikipedia weakening the site, and making @OurBigBook stronger :-) Here is the uncensored one: Scott HassanI spent time on this partly because I'm mildly obsessed with founding myths of companies, but also partly to better understand the moderation process of Wikipedia.
- unix.stackexchange.com/questions/256138/is-there-any-decent-speech-recognition-software-for-linux/613392#613392 cool to see that the Vosk open source speech recognition software by twitter.com/alphacep now has a convenient command line interface called vosk-transcriber!It allows you to just:
vosk-transcriber -m ~/var/lib/vosk/vosk-model-en-us-0.22 -i in.ogg -o out.srt -t srtto extract a subtitle file out.srt from a .ogg audio input file.Accuracy is a bit meh, but we'll take it! - video.stackexchange.com/questions/33531/how-to-remove-background-from-video-without-green-screen-on-the-command-line/37392#37392 tested this AI video background remover github.com/nadermx/backgroundremover by @nadermx. It had a few glitches, but I had fun.
 unix.stackexchange.com/questions/233832/merge-two-video-clips-into-one-placing-them-next-to-each-other/774936#774936 I then learned how to stack videos side-by-side with ffmpeg to create this side-by-side demo. It also works for GIFs! stackoverflow.com/questions/30927367/imagemagick-making-2-gifs-into-side-by-side-gifs-using-im-convert/78361093#78361093
unix.stackexchange.com/questions/233832/merge-two-video-clips-into-one-placing-them-next-to-each-other/774936#774936 I then learned how to stack videos side-by-side with ffmpeg to create this side-by-side demo. It also works for GIFs! stackoverflow.com/questions/30927367/imagemagick-making-2-gifs-into-side-by-side-gifs-using-im-convert/78361093#78361093 Posted at:
Posted at: - Just found out that my Lenovo ThinkPad P14s has an infrared camera, and recorded a quick test video on Ubuntu 23.10 with:
fmpeg -y -f v4l2 -framerate 30 -video_size 640x360 -input_format gray -i /dev/video2 -c copy out.mkv- mastodon.social/@cirosantilli/112261675634568209
- twitter.com/cirosantilli/status/1778981935257116767
- www.facebook.com/cirosantilli/posts/pfbid027M3n2p8snE9otAWdHtJ3ig2AhrXoDGv4h68o1z8agHceQBbFHZpEoxg7KZbiWAgWl
- www.linkedin.com/feed/update/urn:li:activity:7184755892410576897/
- www.youtube.com/watch?v=o1ZeR6pmf6o
- commons.wikimedia.org/wiki/File:Infrared_video_of_Ciro_Santilli_waving_recorded_on_Lenovo_ThinkPad_P14s_with_FFmpeg_6.0_on_Ubuntu_23.10.webm

Figure 29. Ciro Santilli waving hello in infrared.