![]()
The perfect emulation setup to study and develop the Linux kernel v5.9.2, kernel modules, QEMU, gem5 and x86_64, ARMv7 and ARMv8 userland and baremetal assembly, ANSI C, C++ and POSIX. EVERYTHING is built from source. GDB step debug and KGDB just work. Powered by Buildroot and crosstool-NG. Highly automated. Thoroughly documented. Automated tests. "Tested" in an Ubuntu 20.04 host.
TL;DR: Section 2.2.1, “QEMU Buildroot setup getting started” tested on Ubuntu 24.04:
git clone https://github.com/cirosantilli/linux-kernel-module-cheat cd linux-kernel-module-cheat sudo apt install docker python3 -m venv .venv . .venv/bin/activate ./setup ./run-docker create ./run-docker sh
This leaves you inside a Docker shell. Then inside Docker:
./build --download-dependencies qemu-buildroot ./run
and you are now in a Linux userland shell running on QEMU with everything built fully from source.
The source code for this page is located at: https://github.com/cirosantilli/linux-kernel-module-cheat. Due to a GitHub limitation, this README is too long and not fully rendered on github.com, so either use:


https://github.com/cirosantilli/china-dictatorship | https://cirosantilli.com/china-dictatorship/xinjiang

- 1.
--china - 2. Getting started
- 3. GDB step debug
- 3.1. GDB step debug kernel boot
- 3.2. GDB step debug kernel post-boot
- 3.3. tmux
- 3.4. GDB step debug kernel module
- 3.5. GDB step debug early boot
- 3.6. GDB step debug userland processes
- 3.7. GDB call
- 3.8. GDB view ARM system registers
- 3.9. GDB step debug multicore userland
- 3.10. Linux kernel GDB scripts
- 3.11. Debug the GDB remote protocol
- 4. KGDB
- 5. gdbserver
- 6. CPU architecture
- 7. init
- 8. initrd
- 9. Device tree
- 10. KVM
- 11. User mode simulation
- 12. Kernel module utilities
- 13. Filesystems
- 14. Graphics
- 15. Networking
- 16. Operating systems
- 17. Linux kernel
- 17.1. Linux kernel configuration
- 17.2. Kernel version
- 17.3. Kernel command line parameters
- 17.4. printk
- 17.5. Kernel module APIs
- 17.6. Kernel panic and oops
- 17.7. Pseudo filesystems
- 17.8. Pseudo files
- 17.9. kthread
- 17.10. Timers
- 17.11. IRQ
- 17.12. Kernel utility functions
- 17.13. Linux kernel tracing
- 17.14. Linux kernel hardening
- 17.15. User mode Linux
- 17.16. UIO
- 17.17. Linux kernel interactive stuff
- 17.18. DRM
- 17.19. Linux kernel testing
- 17.20. Linux kernel build system
- 17.21. Virtio
- 17.22. Kernel modules
- 18. FreeBSD
- 19. RTOS
- 20. Xen
- 21. U-Boot
- 22. Emulators
- 23. QEMU
- 23.1. Introduction to QEMU
- 23.2. Binary translation
- 23.3. Disk persistency
- 23.4. gem5 qcow2
- 23.5. Snapshot
- 23.6. Device models
- 23.7. QEMU monitor
- 23.8. Debug the emulator
- 23.9. Tracing
- 23.10. QEMU GUI is unresponsive
- 24. gem5
- 24.1. gem5 vs QEMU
- 24.2. gem5 run benchmark
- 24.3. gem5 system parameters
- 24.4. gem5 kernel command line parameters
- 24.5. gem5 GDB step debug
- 24.6. gem5 checkpoint
- 24.7. Pass extra options to gem5
- 24.8. m5ops
- 24.9. gem5 arm Linux kernel patches
- 24.10. m5out directory
- 24.11. m5term
- 24.12. gem5 Python scripts without rebuild
- 24.13. gem5 fs_bigLITTLE
- 24.14. gem5 in-tree tests
- 24.15. gem5 simulate() limit reached
- 24.16. gem5 build options
- 24.17. gem5 CPU types
- 24.18. gem5 ARM platforms
- 24.19. gem5 upstream images
- 24.20. gem5 bootloaders
- 24.21. gem5 memory system
- 24.22. gem5 internals
- 24.22.1. gem5 Eclipse configuration
- 24.22.2. gem5 Python C++ interaction
- 24.22.3. gem5 entry point
- 24.22.4. gem5 event queue
- 24.22.4.1. gem5 event queue AtomicSimpleCPU syscall emulation freestanding example analysis
- 24.22.4.2. gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis
- 24.22.4.2.1. TimingSimpleCPU analysis #0
- 24.22.4.2.2. TimingSimpleCPU analysis #1
- 24.22.4.2.3. TimingSimpleCPU analysis #2
- 24.22.4.2.4. TimingSimpleCPU analysis #3 and #4
- 24.22.4.2.5. TimingSimpleCPU analysis #5
- 24.22.4.2.6. TimingSimpleCPU analysis #6
- 24.22.4.2.7. TimingSimpleCPU analysis #7
- 24.22.4.2.8. TimingSimpleCPU analysis #8
- 24.22.4.2.9. TimingSimpleCPU analysis #9
- 24.22.4.2.10. TimingSimpleCPU analysis #10
- 24.22.4.2.11. TimingSimpleCPU analysis #11
- 24.22.4.2.12. TimingSimpleCPU analysis #12
- 24.22.4.2.13. TimingSimpleCPU analysis #13
- 24.22.4.2.14. TimingSimpleCPU analysis #14
- 24.22.4.2.15. TimingSimpleCPU analysis #15
- 24.22.4.2.16. TimingSimpleCPU analysis #16
- 24.22.4.2.17. TimingSimpleCPU analysis #17
- 24.22.4.2.18. TimingSimpleCPU analysis #18
- 24.22.4.2.19. TimingSimpleCPU analysis #19
- 24.22.4.2.20. TimingSimpleCPU analysis #20
- 24.22.4.2.21. TimingSimpleCPU analysis #21
- 24.22.4.2.22. TimingSimpleCPU analysis #22
- 24.22.4.2.23. TimingSimpleCPU analysis #23
- 24.22.4.2.24. TimingSimpleCPU analysis #24
- 24.22.4.2.25. TimingSimpleCPU analysis #25
- 24.22.4.2.26. TimingSimpleCPU analysis #26
- 24.22.4.2.27. TimingSimpleCPU analysis #27
- 24.22.4.2.28. TimingSimpleCPU analysis #28
- 24.22.4.2.29. TimingSimpleCPU analysis #29
- 24.22.4.2.30. TimingSimpleCPU analysis: LDR stall
- 24.22.4.3. gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis with caches
- 24.22.4.4. gem5 event queue AtomicSimpleCPU syscall emulation freestanding example analysis with caches and multiple CPUs
- 24.22.4.5. gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis with caches and multiple CPUs
- 24.22.4.6. gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis with caches and multiple CPUs and Ruby
- 24.22.4.7. gem5 event queue MinorCPU syscall emulation freestanding example analysis
- 24.22.4.8. gem5 event queue DerivO3CPU syscall emulation freestanding example analysis
- 24.22.4.8.1. gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: hazardless
- 24.22.4.8.2. gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: hazard
- 24.22.4.8.3. gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: hazard4
- 24.22.4.8.4. gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: stall
- 24.22.4.8.5. gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: stall_gain
- 24.22.4.8.6. gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: stall_hazard4
- 24.22.4.8.7. gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: speculative
- 24.22.5. gem5 instruction definitions
- 24.22.6. gem5
ThreadContextvsThreadStatevsExecContextvsProcess - 24.22.7. gem5 functional units
- 24.22.8. gem5 code generation
- 24.22.9. gem5 build system
- 25. Gensim
- 26. Buildroot
- 26.1. Introduction to Buildroot
- 26.2. Custom Buildroot configs
- 26.3. Find Buildroot options with make menuconfig
- 26.4. Change user
- 26.5. Add new files to the Buildroot image
- 26.6. Remove Buildroot packages
- 26.7. BR2_TARGET_ROOTFS_EXT2_SIZE
- 26.8. Buildroot rebuild is slow when the root filesystem is large
- 26.9. Report upstream bugs
- 26.10. libc choice
- 26.11. Buildroot hello world
- 26.12. Update the Buildroot toolchain
- 26.13. Buildroot vanilla kernel
- 27. Userland content
- 27.1. build-userland
- 27.2. C
- 27.3. C++
- 27.4. POSIX
- 27.5. Userland multithreading
- 27.6. C debugging
- 27.7. Interpreted languages
- 27.8. Algorithms
- 27.9. Benchmarks
- 27.10. userland/libs directory
- 27.11. Userland content filename conventions
- 27.12. Userland content bibliography
- 28. Userland assembly
- 29. x86 userland assembly
- 29.1. x86 registers
- 29.2. x86 addressing modes
- 29.3. x86 data transfer instructions
- 29.4. x86 binary arithmetic instructions
- 29.5. x86 logical instructions
- 29.6. x86 shift and rotate instructions
- 29.7. x86 bit and byte instructions
- 29.8. x86 control transfer instructions
- 29.9. x86 miscellaneous instructions
- 29.10. x86 random number generator instructions
- 29.11. x86 x87 FPU instructions
- 29.12. x86 SIMD
- 29.13. x86 system instructions
- 29.14. x86 thread synchronization primitives
- 29.15. x86 assembly bibliography
- 29.15.1. x86 official bibliography
- 29.15.1.1. Intel 64 and IA-32 Architectures Software Developer’s Manuals
- 29.15.1.1.1. Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 1
- 29.15.1.1.2. Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 2
- 29.15.1.1.3. Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 3
- 29.15.1.1.4. Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 4
- 29.15.1.1. Intel 64 and IA-32 Architectures Software Developer’s Manuals
- 29.15.1. x86 official bibliography
- 30. ARM userland assembly
- 30.1. Introduction to the ARM architecture
- 30.2. ARM branch instructions
- 30.3. ARM load and store instructions
- 30.4. ARM data processing instructions
- 30.5. ARM miscellaneous instructions
- 30.6. ARM SIMD
- 30.7. ARM thread synchronization primitives
- 30.8. ARMv8 architecture extensions
- 30.9. ARM PMU
- 30.10. ARM assembly bibliography
- 30.10.1. ARM non-official bibliography
- 30.10.2. ARM official bibliography
- 30.10.2.1. ARMv7 architecture reference manual
- 30.10.2.2. ARMv8 architecture reference manual
- 30.10.2.3. ARMv8 architecture reference manual db
- 30.10.2.4. ARMv8 architecture reference manual db
- 30.10.2.5. Programmer’s Guide for ARMv8-A
- 30.10.2.6. Arm A64 Instruction Set Architecture: Future Architecture Technologies in the A architecture profile Documentation
- 30.10.2.7. ARM processor documentation
- 30.10.2.8. Arm Cortex‑A77 Technical Reference Manual r1p1
- 30.10.2.9. Arm Cortex‑A77 Software Optimization Guide r1p1
- 31. ELF
- 32. IEEE 754
- 33. Baremetal
- 33.1. Baremetal GDB step debug
- 33.2. Baremetal bootloaders
- 33.3. Baremetal linker script
- 33.4. Baremetal command line arguments
- 33.5. Semihosting
- 33.6. gem5 baremetal carriage return
- 33.7. Baremetal host packaged toolchain
- 33.8. Baremetal C++
- 33.9. GDB builtin CPU simulator
- 33.10. ARM baremetal
- 33.10.1. ARM exception levels
- 33.10.2. ARM SVC instruction
- 33.10.3. ARM baremetal multicore
- 33.10.4. ARM timer
- 33.10.5. ARM GIC
- 33.10.6. ARM paging
- 33.10.7. ARM baremetal bibliography
- 33.11. How we got some baremetal stuff to work
- 33.12. Baremetal tests
- 34. Android
- 35. Benchmark this repo
- 35.1. Continuous integration
- 35.2. Benchmark this repo benchmarks
- 35.3. Benchmark machines
- 35.4. Benchmark Internets
- 35.5. Benchmark this repo bibliography
- 36. Compilers
- 37. Computer architecture
- 37.1. Instruction pipelining
- 37.2. Superscalar processor
- 37.3. Out-of-order execution
- 37.4. Instruction level parallelism
- 37.5. Hardware threads
- 37.6. Caches
- 37.6.1. Cache coherence
- 38. About this repo
- 38.1. Supported hosts
- 38.2. Common build issues
- 38.3. Run command after boot
- 38.4. Default command line arguments
- 38.5. Documentation
- 38.6. asciidoctor/link-target-up.rb
- 38.7. Clean the build
- 38.8. Custom build directory
- 38.9. ccache
- 38.10. getvar
- 38.11. Rebuild Buildroot while running
- 38.12. Simultaneous runs
- 38.13. Build variants
- 38.14. Optimization level of a build
- 38.15. Directory structure
- 38.16. Test this repo
- 38.17. Bisection
- 38.18. Update a forked submodule
- 38.19. Release
- 38.20. Design rationale
- 38.21. Soft topics
- 38.22. Bibliography
1. --china
The most important functionality of this repository is the --china option, sample usage:
python3 -m venv .venv . .venv/bin/activate ./setup ./run --china > index.html firefox index.html
The secondary systems programming functionality is described on the sections below starting from Getting started.

2. Getting started
Each child section describes a possible different setup for this repo.
If you don’t know which one to go for, start with QEMU Buildroot setup getting started.
Design goals of this project are documented at: Section 38.20.1, “Design goals”.
2.1. Should you waste your life with systems programming?
Being the hardcore person who fully understands an important complex system such as a computer, it does have a nice ring to it doesn’t it?
But before you dedicate your life to this nonsense, do consider the following points:
-
almost all contributions to the kernel are done by large companies, and if you are not an employee in one of them, you are likely not going to be able to do much.
This can be inferred by the fact that the
devices/directory is by far the largest in the kernel.The kernel is of course just an interface to hardware, and the hardware developers start developing their kernel stuff even before specs are publicly released, both to help with hardware development and to have things working when the announcement is made.
Furthermore, I believe that there are in-tree devices which have never been properly publicly documented. Linus is of course fine with this, since code == documentation for him, but it is not as easy for mere mortals.
There are some less hardware bound higher level layers in the kernel which might not require being in a hardware company, and a few people must be living off it.
But of course, those are heavily motivated by the underlying hardware characteristics, and it is very likely that most of the people working there were previously at a hardware company.
In that sense, therefore, the kernel is not as open as one might want to believe.
Of course, if there is some super useful and undocumented hardware that is just waiting there to be reverse engineered, then that’s a much juicier target :-)
-
it is impossible to become rich with this knowledge.
This is partly implied by the fact that you need to be in a big company to make useful low level things, and therefore you will only be a tiny cog in the engine.
The key problem is that the entry cost of hardware design is just too insanely high for startups in general.
-
Is learning this the most useful thing that you think can do for society?
Or are you just learning it for job security and having a nice sounding title?
I’m not a huge fan of the person, but I think Jobs said it right: https://www.youtube.com/watch?v=FF-tKLISfPE
First determine the useful goal, and then backtrack down to the most efficient thing you can do to reach it.
-
there are two things that sadden me compared to physics-based engineering:
-
you will never become eternally famous. All tech disappears sooner or later, while laws of nature, at least as useful approximations, stay unchanged.
-
every problem that you face is caused by imperfections introduced by other humans.
It is much easier to accept limitations of physics, and even natural selection in biology, which are not produced by a sentient being (?).
Physics-based engineering, just like low level hardware, is of course completely closed source however, since wrestling against the laws of physics is about the most expensive thing humans can do, so there’s also a downside to it.
-
Are you fine with those points, and ready to continue wasting your life with this crap?
Good. In that case, read on, and let’s have some fun together ;-)
Related: Soft topics.
2.2. QEMU Buildroot setup
2.2.1. QEMU Buildroot setup getting started
This setup has been tested on Ubuntu 20.04.
The Buildroot build is already broken on Ubuntu 21.04 onwards: https://github.com/cirosantilli/linux-kernel-module-cheat/issues/155, so just do this from inside a 20.04 Docker instead as shown in the Docker host setup setup. We could fix the build on Ubuntu 21.04, but it will break again inevitably later on.
For other host operating systems see: Section 38.1, “Supported hosts”.
Reserve 12Gb of disk and run:
git clone https://github.com/cirosantilli/linux-kernel-module-cheat cd linux-kernel-module-cheat python3 -m venv .venv . .venv/bin/activate ./setup ./build --download-dependencies qemu-buildroot ./run
You don’t need to clone recursively even though we have .git submodules: download-dependencies fetches just the submodules that you need for this build to save time.
If something goes wrong, see: Section 38.2, “Common build issues” and use our issue tracker: https://github.com/cirosantilli/linux-kernel-module-cheat/issues
The initial build will take a while (30 minutes to 2 hours) to clone and build, see Benchmark builds for more details.
If you don’t want to wait, you could also try the following faster but much more limited methods:
but you will soon find that they are simply not enough if you anywhere near serious about systems programming.
After ./run, QEMU opens up leaving you in the /lkmc/ directory, and you can start playing with the kernel modules inside the simulated system:
insmod hello.ko insmod hello2.ko rmmod hello rmmod hello2
This should print to the screen:
hello init hello2 init hello cleanup hello2 cleanup
which are printk messages from init and cleanup methods of those modules.
Sources:
Quit QEMU with:
Ctrl-A X
See also: Section 14.1.1, “Quit QEMU from text mode”.
All available modules can be found in the kernel_modules directory.
It is super easy to build for different CPU architectures, just use the --arch option:
python3 -m venv .venv . .venv/bin/activate ./setup ./build --arch aarch64 --download-dependencies qemu-buildroot ./run --arch aarch64
To avoid typing --arch aarch64 many times, you can set the default arch as explained at: Section 38.4, “Default command line arguments”
I now urge you to read the following sections which contain widely applicable information:
-
Linux kernel
Once you use GDB step debug and tmux, your terminal will look a bit like this:
[ 1.451857] input: AT Translated Set 2 keyboard as /devices/platform/i8042/s1│loading @0xffffffffc0000000: ../kernel_modules-1.0//timer.ko
[ 1.454310] ledtrig-cpu: registered to indicate activity on CPUs │(gdb) b lkmc_timer_callback
[ 1.455621] usbcore: registered new interface driver usbhid │Breakpoint 1 at 0xffffffffc0000000: file /home/ciro/bak/git/linux-kernel-module
[ 1.455811] usbhid: USB HID core driver │-cheat/out/x86_64/buildroot/build/kernel_modules-1.0/./timer.c, line 28.
[ 1.462044] NET: Registered protocol family 10 │(gdb) c
[ 1.467911] Segment Routing with IPv6 │Continuing.
[ 1.468407] sit: IPv6, IPv4 and MPLS over IPv4 tunneling driver │
[ 1.470859] NET: Registered protocol family 17 │Breakpoint 1, lkmc_timer_callback (data=0xffffffffc0002000 <mytimer>)
[ 1.472017] 9pnet: Installing 9P2000 support │ at /linux-kernel-module-cheat//out/x86_64/buildroot/build/
[ 1.475461] sched_clock: Marking stable (1473574872, 0)->(1554017593, -80442)│kernel_modules-1.0/./timer.c:28
[ 1.479419] ALSA device list: │28 {
[ 1.479567] No soundcards found. │(gdb) c
[ 1.619187] ata2.00: ATAPI: QEMU DVD-ROM, 2.5+, max UDMA/100 │Continuing.
[ 1.622954] ata2.00: configured for MWDMA2 │
[ 1.644048] scsi 1:0:0:0: CD-ROM QEMU QEMU DVD-ROM 2.5+ P5│Breakpoint 1, lkmc_timer_callback (data=0xffffffffc0002000 <mytimer>)
[ 1.741966] tsc: Refined TSC clocksource calibration: 2904.010 MHz │ at /linux-kernel-module-cheat//out/x86_64/buildroot/build/
[ 1.742796] clocksource: tsc: mask: 0xffffffffffffffff max_cycles: 0x29dc0f4s│kernel_modules-1.0/./timer.c:28
[ 1.743648] clocksource: Switched to clocksource tsc │28 {
[ 2.072945] input: ImExPS/2 Generic Explorer Mouse as /devices/platform/i8043│(gdb) bt
[ 2.078641] EXT4-fs (vda): couldn't mount as ext3 due to feature incompatibis│#0 lkmc_timer_callback (data=0xffffffffc0002000 <mytimer>)
[ 2.080350] EXT4-fs (vda): mounting ext2 file system using the ext4 subsystem│ at /linux-kernel-module-cheat//out/x86_64/buildroot/build/
[ 2.088978] EXT4-fs (vda): mounted filesystem without journal. Opts: (null) │kernel_modules-1.0/./timer.c:28
[ 2.089872] VFS: Mounted root (ext2 filesystem) readonly on device 254:0. │#1 0xffffffff810ab494 in call_timer_fn (timer=0xffffffffc0002000 <mytimer>,
[ 2.097168] devtmpfs: mounted │ fn=0xffffffffc0000000 <lkmc_timer_callback>) at kernel/time/timer.c:1326
[ 2.126472] Freeing unused kernel memory: 1264K │#2 0xffffffff810ab71f in expire_timers (head=<optimized out>,
[ 2.126706] Write protecting the kernel read-only data: 16384k │ base=<optimized out>) at kernel/time/timer.c:1363
[ 2.129388] Freeing unused kernel memory: 2024K │#3 __run_timers (base=<optimized out>) at kernel/time/timer.c:1666
[ 2.139370] Freeing unused kernel memory: 1284K │#4 run_timer_softirq (h=<optimized out>) at kernel/time/timer.c:1692
[ 2.246231] EXT4-fs (vda): warning: mounting unchecked fs, running e2fsck isd│#5 0xffffffff81a000cc in __do_softirq () at kernel/softirq.c:285
[ 2.259574] EXT4-fs (vda): re-mounted. Opts: block_validity,barrier,user_xatr│#6 0xffffffff810577cc in invoke_softirq () at kernel/softirq.c:365
hello S98 │#7 irq_exit () at kernel/softirq.c:405
│#8 0xffffffff818021ba in exiting_irq () at ./arch/x86/include/asm/apic.h:541
Apr 15 23:59:23 login[49]: root login on 'console' │#9 smp_apic_timer_interrupt (regs=<optimized out>)
hello /root/.profile │ at arch/x86/kernel/apic/apic.c:1052
# insmod /timer.ko │#10 0xffffffff8180190f in apic_timer_interrupt ()
[ 6.791945] timer: loading out-of-tree module taints kernel. │ at arch/x86/entry/entry_64.S:857
# [ 7.821621] 4294894248 │#11 0xffffffff82003df8 in init_thread_union ()
[ 8.851385] 4294894504 │#12 0x0000000000000000 in ?? ()
│(gdb)
2.2.2. How to hack stuff
Besides a seamless initial build, this project also aims to make it effortless to modify and rebuild several major components of the system, to serve as an awesome development setup.
2.2.2.1. Your first Linux kernel hack
Let’s hack up the Linux kernel entry point, which is an easy place to start.
Open the file:
vim submodules/linux/init/main.c
and find the start_kernel function, then add there a:
pr_info("I'VE HACKED THE LINUX KERNEL!!!");
Then rebuild the Linux kernel, quit QEMU and reboot the modified kernel:
./build-linux ./run
and, surely enough, your message has appeared at the beginning of the boot:
<6>[ 0.000000] I'VE HACKED THE LINUX KERNEL!!!
So you are now officially a Linux kernel hacker, way to go!
We could have used just build to rebuild the kernel as in the initial build instead of build-linux, but building just the required individual components is preferred during development:
-
saves a few seconds from parsing Make scripts and reading timestamps
-
makes it easier to understand what is being done in more detail
-
allows passing more specific options to customize the build
The build script is just a lightweight wrapper that calls the smaller build scripts, and you can see what ./build does with:
./build --dry-run
see also: Dry run to get commands for your project.
When you reach difficulties, QEMU makes it possible to easily GDB step debug the Linux kernel source code, see: Section 3, “GDB step debug”.
2.2.2.2. Your first kernel module hack
Edit kernel_modules/hello.c to contain:
pr_info("hello init hacked\n");
and rebuild with:
./build-modules
Now there are two ways to test it out: the fast way, and the safe way.
The fast way is, without quitting or rebooting QEMU, just directly re-insert the module with:
insmod /mnt/9p/out_rootfs_overlay/lkmc/hello.ko
and the new pr_info message should now show on the terminal at the end of the boot.
If you are simultaneously developing the test script and the kernel module, some smart test scripts should take the kernel module as first argument so you can directly run:
/mnt/9p/rootfs_overlay/lkmc/scull.sh /mnt/9p/out_rootfs_overlay/lkmc/scull.ko
and it will pick up both the test script and the kernel module from host.
This works because we have a 9P mount there setup by default, which mounts the host directory that contains the build outputs on the guest:
ls "$(./getvar out_rootfs_overlay_dir)"
The fast method is slightly risky because your previously insmodded buggy kernel module attempt might have corrupted the kernel memory, which could affect future runs.
Such failures are however unlikely, and you should be fine if you don’t see anything weird happening.
The safe way is to fist quit QEMU, rebuild the modules put them somewhere QEMU can see and then reboot. So you could either place it in the root filesystem:
./build-modules ./build-buildroot ./run --eval-after 'insmod hello.ko'
where ./build-buildroot is required after ./build-modules because it re-generates the root filesystem with the modules that we compiled at ./build-modules.
Alternatively, for a slightly faster turnaround just leave it on 9p and use it from there:
./build-modules ./run --eval-after 'insmod /mnt/9p/out_rootfs_overlay/lkmc/hello.ko'
You can see that ./build does that as well, by running:
./build --dry-run
See also: Dry run to get commands for your project.
--eval-after is optional: you could just type insmod hello.ko in the terminal, but this makes it run automatically at the end of boot, and then drops you into a shell.
If the guest and host are the same arch, typically x86_64, you can speed up boot further with KVM:
./run --kvm
All of this put together makes the safe procedure acceptably fast for regular development as well.
It is also easy to GDB step debug kernel modules with our setup, see: Section 3.4, “GDB step debug kernel module”.
2.2.2.3. Your first glibc hack
We use glibc as our default libc now, and it is tracked as an unmodified submodule at submodules/glibc, at the exact same version that Buildroot has it, which can be found at: package/glibc/glibc.mk. Buildroot 2018.05 applies no patches.
Let’s hack up the puts function:
./build-buildroot -- glibc-reconfigure
with the patch:
diff --git a/libio/ioputs.c b/libio/ioputs.c
index 706b20b492..23185948f3 100644
--- a/libio/ioputs.c
+++ b/libio/ioputs.c
@@ -38,8 +38,9 @@ _IO_puts (const char *str)
if ((_IO_vtable_offset (_IO_stdout) != 0
|| _IO_fwide (_IO_stdout, -1) == -1)
&& _IO_sputn (_IO_stdout, str, len) == len
+ && _IO_sputn (_IO_stdout, " hacked", 7) == 7
&& _IO_putc_unlocked ('\n', _IO_stdout) != EOF)
- result = MIN (INT_MAX, len + 1);
+ result = MIN (INT_MAX, len + 1 + 7);
_IO_release_lock (_IO_stdout);
return result;
And then:
./run --eval-after './c/hello.out'
outputs:
hello hacked
Lol!
We can also test our hacked glibc on User mode simulation with:
./run --userland userland/c/hello.c
I just noticed that this is actually a good way to develop glibc for other archs.
In this example, we got away without recompiling the userland program because we made a change that did not affect the glibc ABI, see this answer for an introduction to ABI stability: https://stackoverflow.com/questions/2171177/what-is-an-application-binary-interface-abi/54967743#54967743
Note that for arch agnostic features that don’t rely on bleeding kernel changes that you host doesn’t yet have, you can develop glibc natively as explained at:
-
https://stackoverflow.com/questions/2856438/how-can-i-link-to-a-specific-glibc-version/52550158#52550158 more focus on symbol versioning, but no one knows how to do it, so I answered
Tested on a30ed0f047523ff2368d421ee2cce0800682c44e + 1.
2.2.2.4. Your first Binutils hack
Have you ever felt that a single inc instruction was not enough? Really? Me too!
So let’s hack the GNU GAS assembler, which is part of GNU Binutils, to add a new shiny version of inc called… myinc!
GCC uses GNU GAS as its backend, so we will test out new mnemonic with an GCC inline assembly test program: userland/arch/x86_64/binutils_hack.c, which is just a copy of userland/arch/x86_64/binutils_nohack.c but with myinc instead of inc.
The inline assembly is disabled with an #ifdef, so first modify the source to enable that.
Then, try to build userland:
./build-userland
and watch it fail with:
binutils_hack.c:8: Error: no such instruction: `myinc %rax'
Now, edit the file
vim submodules/binutils-gdb/opcodes/i386-tbl.h
and add a copy of the "inc" instruction just next to it, but with the new name "myinc":
diff --git a/opcodes/i386-tbl.h b/opcodes/i386-tbl.h
index af583ce578..3cc341f303 100644
--- a/opcodes/i386-tbl.h
+++ b/opcodes/i386-tbl.h
@@ -1502,6 +1502,19 @@ const insn_template i386_optab[] =
{ { { 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0,
1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0 } } } },
+ { "myinc", 1, 0xfe, 0x0, 1,
+ { { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 } },
+ { 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0 },
+ { { { 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0,
+ 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0 } } } },
{ "sub", 2, 0x28, None, 1,
{ { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
Finally, rebuild Binutils, userland and test our program with User mode simulation:
./build-buildroot -- host-binutils-rebuild ./build-userland --static ./run --static --userland userland/arch/x86_64/binutils_hack.c
and we se that myinc worked since the assert did not fail!
Tested on b60784d59bee993bf0de5cde6c6380dd69420dda + 1.
2.2.2.5. Your first GCC hack
OK, now time to hack GCC.
For convenience, let’s use the User mode simulation.
If we run the program userland/c/gcc_hack.c:
./build-userland --static ./run --static --userland userland/c/gcc_hack.c
it produces the normal boring output:
i = 2 j = 0
So how about we swap ++ and -- to make things more fun?
Open the file:
vim submodules/gcc/gcc/c/c-parser.c
and find the function c_parser_postfix_expression_after_primary.
In that function, swap case CPP_PLUS_PLUS and case CPP_MINUS_MINUS:
diff --git a/gcc/c/c-parser.c b/gcc/c/c-parser.c index 101afb8e35f..89535d1759a 100644 --- a/gcc/c/c-parser.c +++ b/gcc/c/c-parser.c @@ -8529,7 +8529,7 @@ c_parser_postfix_expression_after_primary (c_parser *parser, expr.original_type = DECL_BIT_FIELD_TYPE (field); } break; - case CPP_PLUS_PLUS: + case CPP_MINUS_MINUS: /* Postincrement. */ start = expr.get_start (); finish = c_parser_peek_token (parser)->get_finish (); @@ -8548,7 +8548,7 @@ c_parser_postfix_expression_after_primary (c_parser *parser, expr.original_code = ERROR_MARK; expr.original_type = NULL; break; - case CPP_MINUS_MINUS: + case CPP_PLUS_PLUS: /* Postdecrement. */ start = expr.get_start (); finish = c_parser_peek_token (parser)->get_finish ();
Now rebuild GCC, the program and re-run it:
./build-buildroot -- host-gcc-final-rebuild ./build-userland --static ./run --static --userland userland/c/gcc_hack.c
and the new ouptut is now:
i = 2 j = 0
We need to use the ugly -final thing because GCC has to packages in Buildroot, -initial and -final: https://stackoverflow.com/questions/54992977/how-to-select-an-override-srcdir-source-for-gcc-when-building-buildroot No one is able to example precisely with a minimal example why this is required:
2.2.3. About the QEMU Buildroot setup
What QEMU and Buildroot are:
This is our reference setup, and the best supported one, use it unless you have good reason not to.
It was historically the first one we did, and all sections have been tested with this setup unless explicitly noted.
Read the following sections for further introductory material:
2.3. Dry run to get commands for your project
One of the major features of this repository is that we try to support the --dry-run option really well for all scripts.
This option, as the name suggests, outputs the external commands that would be run (or more precisely: equivalent commands), without actually running them.
This allows you to just clone this repository and get full working commands to integrate into your project, without having to build or use this setup further!
For example, we can obtain a QEMU run for the file userland/c/hello.c in User mode simulation by adding --dry-run to the normal command:
./run --dry-run --userland userland/c/hello.c
which as of LKMC a18f28e263c91362519ef550150b5c9d75fa3679 + 1 outputs:
+ /path/to/linux-kernel-module-cheat/out/qemu/default/opt/x86_64-linux-user/qemu-x86_64 \ -L /path/to/linux-kernel-module-cheat/out/buildroot/build/default/x86_64/target \ -r 5.2.1 \ -seed 0 \ -trace enable=load_file,file=/path/to/linux-kernel-module-cheat/out/run/qemu/x86_64/0/trace.bin \ -cpu max \ /path/to/linux-kernel-module-cheat/out/userland/default/x86_64/c/hello.out \ ;
So observe that the command contains:
-
+: sign to differentiate it from program stdout, much like bash-xoutput. This is not a valid part of the generated Bash command however. -
the actual command nicely, indented and with arguments broken one per line, but with continuing backslashes so you can just copy paste into a terminal
For setups that don’t support the newline e.g. Eclipse debugging, you can turn them off with
--print-cmd-oneline -
;: both a valid part of the Bash command, and a visual mark the end of the command
For the specific case of running emulators such as QEMU, the last command is also automatically placed in a file for your convenience and later inspection:
cat "$(./getvar run_dir)/run.sh"
Since we need this so often, the last run command is also stored for convenience at:
cat out/run.sh
although this won’t of course work well for Simultaneous runs.
Furthermore, --dry-run also automatically specifies, in valid Bash shell syntax:
-
environment variables used to run the command with syntax
+ ENV_VAR_1=abc ENV_VAR_2=def ./some/command -
change in working directory with
+ cd /some/new/path && ./some/command
2.4. gem5 Buildroot setup
2.4.1. About the gem5 Buildroot setup
This setup is like the QEMU Buildroot setup, but it uses gem5 instead of QEMU as a system simulator.
QEMU tries to run as fast as possible and give correct results at the end, but it does not tell us how many CPU cycles it takes to do something, just the number of instructions it ran. This kind of simulation is known as functional simulation.
The number of instructions executed is a very poor estimator of performance because in modern computers, a lot of time is spent waiting for memory requests rather than the instructions themselves.
gem5 on the other hand, can simulate the system in more detail than QEMU, including:
-
simplified CPU pipeline
-
caches
-
DRAM timing
and can therefore be used to estimate system performance, see: Section 24.2, “gem5 run benchmark” for an example.
The downside of gem5 much slower than QEMU because of the greater simulation detail.
See gem5 vs QEMU for a more thorough comparison.
2.4.2. gem5 Buildroot setup getting started
For the most part, if you just add the --emulator gem5 option or *-gem5 suffix to all commands and everything should magically work.
If you haven’t built Buildroot yet for QEMU Buildroot setup, you can build from the beginning with:
python3 -m venv .venv . .venv/bin/activate ./setup ./build --download-dependencies gem5-buildroot ./run --emulator gem5
If you have already built previously, don’t be afraid: gem5 and QEMU use almost the same root filesystem and kernel, so ./build will be fast.
Remember that the gem5 boot is considerably slower than QEMU since the simulation is more detailed.
If you have a relatively new GCC version and the gem5 build fails on your machine, see: gem5 build broken on recent compiler version.
To get a terminal, either open a new shell and run:
./gem5-shell
You can quit the shell without killing gem5 by typing tilde followed by a period:
~.
If you are inside tmux, which I highly recommend, you can both run gem5 stdout and open the guest terminal on a split window with:
./run --emulator gem5 --tmux
See also: Section 3.3.1, “tmux gem5”.
At the end of boot, it might not be very clear that you have the shell since some printk messages may appear in front of the prompt like this:
# <6>[ 1.215329] clocksource: tsc: mask: 0xffffffffffffffff max_cycles: 0x1cd486fa865, max_idle_ns: 440795259574 ns <6>[ 1.215351] clocksource: Switched to clocksource tsc
but if you look closely, the PS1 prompt marker # is there already, just hit enter and a clear prompt line will appear.
If you forgot to open the shell and gem5 exit, you can inspect the terminal output post-mortem at:
less "$(./getvar --emulator gem5 m5out_dir)/system.pc.com_1.device"
More gem5 information is present at: Section 24, “gem5”
Good next steps are:
-
gem5 run benchmark: how to run a benchmark in gem5 full system, including how to boot Linux, checkpoint and restore to skip the boot on a fast CPU
-
m5out directory: understand the output files that gem5 produces, which contain information about your run
-
m5ops: magic guest instructions used to control gem5
-
Add new files to the Buildroot image: how to add your own files to the image if you have a benchmark that we don’t already support out of the box (also send a pull request!)
2.5. Docker host setup
This repository has been tested inside clean Docker containers.
This is a good option if you are on a Linux host, but the native setup failed due to your weird host distribution, and you have better things to do with your life than to debug it. See also: Section 38.1, “Supported hosts”.
For example, to do a QEMU Buildroot setup inside Docker, run:
sudo apt-get install docker python3 -m venv .venv . .venv/bin/activate ./setup ./run-docker create && \ ./run-docker sh -- ./build --download-dependencies qemu-buildroot ./run-docker
You are now left inside a shell in the Docker! From there, just run as usual:
./run
The host git top level directory is mounted inside the guest with a Docker volume, which means for example that you can use your host’s GUI text editor directly on the files. Just don’t forget that if you nuke that directory on the guest, then it gets nuked on the host as well!
Command breakdown:
-
./run-docker create: create the image and container.Needed only the very first time you use Docker, or if you run
./run-docker DESTROYto restart for scratch, or save some disk space.The image and container name is
lkmc. The container shows under:docker ps -a
and the image shows under:
docker images
-
./run-docker: open a shell on the container.If it has not been started previously, start it. This can also be done explicitly with:
./run-docker start
Quit the shell as usual with
Ctrl-DThis can be called multiple times from different host terminals to open multiple shells.
-
./run-docker stop: stop the container.This might save a bit of CPU and RAM once you stop working on this project, but it should not be a lot.
-
./run-docker DESTROY: delete the container and image.This doesn’t really clean the build, since we mount the guest’s working directory on the host git top-level, so you basically just got rid of the
apt-getinstalls.To actually delete the Docker build, run on host:
# sudo rm -rf out.docker
To use GDB step debug from inside Docker, you need a second shell inside the container. You can either do that from another shell with:
./run-docker
or even better, by starting a tmux session inside the container. We install tmux by default in the container.
You can also start a second shell and run a command in it at the same time with:
./run-docker sh -- ./run-gdb start_kernel
To use QEMU graphic mode from Docker, run:
./run --graphic --vnc
and then on host:
sudo apt-get install vinagre ./vnc
TODO make files created inside Docker be owned by the current user in host instead of root:
2.6. Prebuilt setup
2.6.1. About the prebuilt setup
This setup uses prebuilt binaries that we upload to GitHub from time to time.
We don’t currently provide a full prebuilt because it would be too big to host freely, notably because of the cross toolchain.
Our prebuilts currently include:
-
QEMU Buildroot setup binaries
-
Linux kernel
-
root filesystem
-
-
Baremetal setup binaries for QEMU
For more details, see our our release procedure.
Advantage of this setup: saves time and disk space on the initial install, which is expensive in largely due to building the toolchain.
The limitations are severe however:
-
can’t GDB step debug the kernel, since the source and cross toolchain with GDB are not available. Buildroot cannot easily use a host toolchain: Section 35.2.3.1.1, “Buildroot use prebuilt host toolchain”.
Maybe we could work around this by just downloading the kernel source somehow, and using a host prebuilt GDB, but we felt that it would be too messy and unreliable.
-
you won’t get the latest version of this repository. Our Travis attempt to automate builds failed, and storing a release for every commit would likely make GitHub mad at us anyway.
-
gem5 is not currently supported. The major blocking point is how to avoid distributing the kernel images twice: once for gem5 which uses
vmlinux, and once for QEMU which usesarch/*images, see also:
This setup might be good enough for those developing simulators, as that requires less image modification. But once again, if you are serious about this, why not just let your computer build the full featured setup while you take a coffee or a nap? :-)
2.6.2. Prebuilt setup getting started
Checkout to the latest tag and use the Ubuntu packaged QEMU to boot Linux:
sudo apt-get install qemu-system-x86 git clone https://github.com/cirosantilli/linux-kernel-module-cheat cd linux-kernel-module-cheat git checkout "$(git rev-list --tags --max-count=1)" ./release-download-latest unzip lkmc-*.zip ./run --qemu-which host
You have to checkout to the latest tag to ensure that the scripts match the release format: https://stackoverflow.com/questions/1404796/how-to-get-the-latest-tag-name-in-current-branch-in-git
This is known not to work for aarch64 on an Ubuntu 16.04 host with QEMU 2.5.0, presumably because QEMU is too old, the terminal does not show any output. I haven’t investigated why.
Or to run a baremetal example instead:
./run \ --arch aarch64 \ --baremetal userland/c/hello.c \ --qemu-which host \ ;
Be saner and use our custom built QEMU instead:
python3 -m venv .venv . .venv/bin/activate ./setup ./build --download-dependencies qemu ./run
To build the kernel modules as in Your first kernel module hack do:
git submodule update --depth 1 --init --recursive "$(./getvar linux_source_dir)" ./build-linux --no-modules-install -- modules_prepare ./build-modules --gcc-which host ./run
TODO: for now the only way to test those modules out without building Buildroot is with 9p, since we currently rely on Buildroot to manipulate the root filesystem.
Command explanation:
-
modules_preparedoes the minimal build procedure required on the kernel for us to be able to compile the kernel modules, and is way faster than doing a full kernel build. A full kernel build would also work however. -
--gcc-which hostselects your host Ubuntu packaged GCC, since you don’t have the Buildroot toolchain -
--no-modules-installis required otherwise themake modules_installtarget we run by default fails, since the kernel wasn’t built
To modify the Linux kernel, build and use it as usual:
git submodule update --depth 1 --init --recursive "$(./getvar linux_source_dir)" ./build-linux ./run
2.7. Host kernel module setup
THIS IS DANGEROUS (AND FUN), YOU HAVE BEEN WARNED
This method runs the kernel modules directly on your host computer without a VM, and saves you the compilation time and disk usage of the virtual machine method.
It has however severe limitations:
-
can’t control which kernel version and build options to use. So some of the modules will likely not compile because of kernel API changes, since the Linux kernel does not have a stable kernel module API.
-
bugs can easily break you system. E.g.:
-
segfaults can trivially lead to a kernel crash, and require a reboot
-
your disk could get erased. Yes, this can also happen with
sudofrom userland. But you should not usesudowhen developing newbie programs. And for the kernel you don’t have the choice not to usesudo. -
even more subtle system corruption such as not being able to rmmod
-
-
can’t control which hardware is used, notably the CPU architecture
-
can’t step debug it with GDB easily. The alternatives are JTAG or KGDB, but those are less reliable, and require extra hardware.
Still interested?
./build-modules --host
Compilation will likely fail for some modules because of kernel or toolchain differences that we can’t control on the host.
The best workaround is to compile just your modules with:
./build-modules --host -- hello hello2
which is equivalent to:
./build-modules \ --gcc-which host \ --host \ -- \ kernel_modules/hello.c \ kernel_modules/hello2.c \ ;
Or just remove the .c extension from the failing files and try again:
cd "$(./getvar kernel_modules_source_dir)" mv broken.c broken.c~
Once you manage to compile, and have come to terms with the fact that this may blow up your host, try it out with:
cd "$(./getvar kernel_modules_build_host_subdir)" sudo insmod hello.ko # Our module is there. sudo lsmod | grep hello # Last message should be: hello init dmesg -T sudo rmmod hello # Last message should be: hello exit dmesg -T # Not present anymore sudo lsmod | grep hello
2.7.1. Hello host
Minimal host build system example:
cd hello_host_kernel_module make sudo insmod hello.ko dmesg sudo rmmod hello.ko dmesg
2.8. Userland setup
2.8.1. About the userland setup
In order to test the kernel and emulators, userland content in the form of executables and scripts is of course required, and we store it mostly under:
When we started this repository, it only contained content that interacted very closely with the kernel, or that had required performance analysis.
However, we soon started to notice that this had an increasing overlap with other userland test repositories: we were duplicating build and test infrastructure and even some examples.
Therefore, we decided to consolidate other userland tutorials that we had scattered around into this repository.
Notable userland content included / moving into this repository includes:
2.8.2. Userland setup getting started
There are several ways to run our Userland content, notably:
-
natively on the host as shown at: Section 2.8.2.1, “Userland setup getting started natively”
Can only run examples compatible with your host CPU architecture and OS, but has the fastest setup and runtimes.
-
from user mode simulation with:
-
the host prebuilt toolchain: Section 2.8.2.2, “Userland setup getting started with prebuilt toolchain and QEMU user mode”
-
the Buildroot toolchain you built yourself: Section 11.1, “QEMU user mode getting started”
This setup:
-
can run most examples, including those for other CPU architectures, with the notable exception of examples that rely on kernel modules
-
can run reproducible approximate performance experiments with gem5, see e.g. BST vs heap vs hashmap
-
-
from full system simulation as shown at: Section 2.2.1, “QEMU Buildroot setup getting started”.
This is the most reproducible and controlled environment, and all examples work there. But also the slower one to setup.
2.8.2.1. Userland setup getting started natively
With this setup, we will use the host toolchain and execute executables directly on the host.
No toolchain build is required, so you can just download your distro toolchain and jump straight into it.
Build, run and example, and clean it in-tree with:
sudo apt-get install gcc cd userland ./build c/hello ./c/hello.out ./build --clean
Source: userland/c/hello.c.
Build an entire directory and test it:
cd userland ./build c ./test c
Build the current directory and test it:
cd userland/c ./build ./test
As mentioned at userland/libs directory, tests under userland/libs require certain optional libraries to be installed, and are not built or tested by default.
You can install those libraries with:
cd linux-kernel-module-cheat python3 -m venv .venv . .venv/bin/activate ./setup ./build --download-dependencies userland-host
and then build the examples and test with:
./build --package-all ./test --package-all
Pass custom compiler options:
./build --ccflags='-foptimize-sibling-calls -foptimize-strlen' --force-rebuild
Here we used --force-rebuild to force rebuild since the sources weren’t modified since the last build.
Some CLI options have more specialized flags, e.g. -O for the Optimization level of a build:
./build --optimization-level 3 --force-rebuild
See also User mode static executables for --static.
The build scripts inside userland/ are just symlinks to build-userland-in-tree which you can also use from toplevel as:
./build-userland-in-tree ./build-userland-in-tree userland/c ./build-userland-in-tree userland/c/hello.c
build-userland-in-tree is in turn just a thin wrapper around build-userland:
./build-userland --gcc-which host --in-tree userland/c
So you can use any option supported by build-userland script freely with build-userland-in-tree and build.
The situation is analogous for userland/test, test-executables-in-tree and test-executables, which are further documented at: Section 11.2, “User mode tests”.
Do a more clean out-of-tree build instead and run the program:
./build-userland --gcc-which host --userland-build-id host ./run --emulator native --userland userland/c/hello.c --userland-build-id host
Here we:
-
put the host executables in a separate build variant to avoid conflict with Buildroot builds.
-
ran with the
--emulator nativeoption to run the program natively
In this case you can debub the program with:
./run --debug-vm --emulator native --userland userland/c/hello.c --userland-build-id host
as shown at: Section 23.8, “Debug the emulator”, although direct GDB host usage works as well of course.
2.8.2.2. Userland setup getting started with prebuilt toolchain and QEMU user mode
If you are lazy to built the Buildroot toolchain and QEMU, but want to run e.g. ARM Userland assembly in User mode simulation, you can get away on Ubuntu 18.04 with just:
sudo apt-get install gcc-aarch64-linux-gnu qemu-system-aarch64 ./build-userland \ --arch aarch64 \ --gcc-which host \ --userland-build-id host \ ; ./run \ --arch aarch64 \ --qemu-which host \ --userland-build-id host \ --userland userland/c/command_line_arguments.c \ --cli-args 'asdf "qw er"' \ ;
where:
-
--gcc-which host: use the host toolchain.We must pass this to
./runas well because QEMU must know which dynamic libraries to use. See also: Section 11.5, “User mode static executables”. -
--userland-build-id host: put the host built into a Build variants
This present the usual trade-offs of using prebuilts as mentioned at: Section 2.6, “Prebuilt setup”.
Other functionality are analogous, e.g. testing:
./test-executables \ --arch aarch64 \ --gcc-which host \ --qemu-which host \ --userland-build-id host \ ;
and User mode GDB:
./run \ --arch aarch64 \ --gdb \ --gcc-which host \ --qemu-which host \ --userland-build-id host \ --userland userland/c/command_line_arguments.c \ --cli-args 'asdf "qw er"' \ ;
2.8.2.3. Userland setup getting started full system
First ensure that QEMU Buildroot setup is working.
After doing that setup, you can already execute your userland programs from inside QEMU: the only missing step is how to rebuild executables and run them.
And the answer is exactly analogous to what is shown at: Section 2.2.2.2, “Your first kernel module hack”
For example, if we modify userland/c/hello.c to print out something different, we can just rebuild it with:
./build-userland
Source: build-userland. ./build calls that script automatically for us when doing the initial full build.
Now, run the program either without rebooting use the 9P mount:
/mnt/9p/out_rootfs_overlay/c/hello.out
or shutdown QEMU, add the executable to the root filesystem:
./build-buildroot
reboot and use the root filesystem as usual:
./hello.out
2.9. Baremetal setup
2.9.1. About the baremetal setup
This setup does not use the Linux kernel nor Buildroot at all: it just runs your very own minimal OS.
x86_64 is not currently supported, only arm and aarch64: I had made some x86 bare metal examples at: https://github.com/cirosantilli/x86-bare-metal-examples but I’m lazy to port them here now. Pull requests are welcome.
The main reason this setup is included in this project, despite the word "Linux" being on the project name, is that a lot of the emulator boilerplate can be reused for both use cases.
This setup allows you to make a tiny OS and that runs just a few instructions, use it to fully control the CPU to better understand the simulators for example, or develop your own OS if you are into that.
You can also use C and a subset of the C standard library because we enable Newlib by default. See also:
Our C bare-metal compiler is built with crosstool-NG. If you have already built Buildroot previously, you will end up with two GCCs installed. Unfortunately I don’t see a solution for this, since we need separate toolchains for Newlib on baremetal and glibc on Linux: https://stackoverflow.com/questions/38956680/difference-between-arm-none-eabi-and-arm-linux-gnueabi/38989869#38989869
2.9.2. Baremetal setup getting started
Every .c file inside baremetal/ and .S file inside baremetal/arch/<arch>/ generates a separate baremetal image.
For example, to run baremetal/arch/aarch64/dump_regs.c in QEMU do:
python3 -m venv .venv . .venv/bin/activate ./setup ./build --arch aarch64 --download-dependencies qemu-baremetal ./run --arch aarch64 --baremetal baremetal/arch/aarch64/dump_regs.c
And the terminal prints the values of certain system registers. This example prints registers that are only accessible from EL1 or higher, and thus could not be run in userland.
In addition to the examples under baremetal/, several of the userland examples can also be run in baremetal! This is largely due to the awesomeness of Newlib.
The examples that work include most C examples that don’t rely on complicated syscalls such as threads, and almost all the Userland assembly examples.
The exact list of userland programs that work in baremetal is specified in path_properties.py with the baremetal property, but you can also easily find it out with a baremetal test dry run:
./test-executables --arch aarch64 --dry-run --mode baremetal
For example, we can run the C hello world userland/c/hello.c simply as:
./run --arch aarch64 --baremetal userland/c/hello.c
and that outputs to the serial port the string:
hello
which QEMU shows on the host terminal.
To modify a baremetal program, simply edit the file, e.g.
vim userland/c/hello.c
and rebuild:
./build-baremetal --arch aarch64 ./run --arch aarch64 --baremetal userland/c/hello.c
./build qemu-baremetal that we run previously is only needed for the initial build. That script calls build-baremetal for us, in addition to building prerequisites such as QEMU and crosstool-NG.
./build-baremetal uses crosstool-NG, and so it must be preceded by build-crosstool-ng, which ./build qemu-baremetal also calls.
Now let’s run userland/arch/aarch64/add.S:
./run --arch aarch64 --baremetal userland/arch/aarch64/add.S
This time, the terminal does not print anything, which indicates success: if you look into the source, you will see that we just have an assertion there.
You can see a sample assertion fail in userland/c/assert_fail.c:
./run --arch aarch64 --baremetal userland/c/assert_fail.c
and the terminal contains:
lkmc_exit_status_134 error: simulation error detected by parsing logs
and the exit status of our script is 1:
echo $?
You can run all the baremetal examples in one go and check that all assertions passed with:
./test-executables --arch aarch64 --mode baremetal
To use gem5 instead of QEMU do:
python3 -m venv .venv . .venv/bin/activate ./setup ./build --download-dependencies gem5-baremetal ./run --arch aarch64 --baremetal userland/c/hello.c --emulator gem5
and then as usual open a shell with:
./gem5-shell
Or as usual, tmux users can do both in one go with:
./run --arch aarch64 --baremetal userland/c/hello.c --emulator gem5 --tmux
TODO: the carriage returns are a bit different than in QEMU, see: Section 33.6, “gem5 baremetal carriage return”.
Note that ./build-baremetal requires the --emulator gem5 option, and generates separate executable images for both, as can be seen from:
echo "$(./getvar --arch aarch64 --baremetal userland/c/hello.c --emulator qemu image)" echo "$(./getvar --arch aarch64 --baremetal userland/c/hello.c --emulator gem5 image)"
This is unlike the Linux kernel that has a single image for both QEMU and gem5:
echo "$(./getvar --arch aarch64 --emulator qemu image)" echo "$(./getvar --arch aarch64 --emulator gem5 image)"
The reason for that is that on baremetal we don’t parse the device tress from memory like the Linux kernel does, which tells the kernel for example the UART address, and many other system parameters.
gem5 also supports the RealViewPBX machine, which represents an older hardware compared to the default VExpress_GEM5_V1:
./build-baremetal --arch aarch64 --emulator gem5 --machine RealViewPBX ./run --arch aarch64 --baremetal userland/c/hello.c --emulator gem5 --machine RealViewPBX
see also: Section 24.18, “gem5 ARM platforms”.
This generates yet new separate images with new magic constants:
echo "$(./getvar --arch aarch64 --baremetal userland/c/hello.c --emulator gem5 --machine VExpress_GEM5_V1 image)" echo "$(./getvar --arch aarch64 --baremetal userland/c/hello.c --emulator gem5 --machine RealViewPBX image)"
But just stick to newer and better VExpress_GEM5_V1 unless you have a good reason to use RealViewPBX.
When doing baremetal programming, it is likely that you will want to learn userland assembly first, see: Section 28, “Userland assembly”.
For more information on baremetal, see the section: Section 33, “Baremetal”.
The following subjects are particularly important:
2.10. Build the documentation
You don’t need to depend on GitHub.
For a quick and dirty build, install Asciidoctor however you like and build:
asciidoctor README.adoc xdg-open README.html
For development, you will want to do a more controlled build with extra error checking as follows.
TODO: get this working seamlessly on Docker. For now some quick instructions for host building. For the initial build, first install RVM and Ruby as per https://www.rvm.io/rvm/install:
\curl -sSL https://get.rvm.io | bash rvm install 3.2.3
The TODO Docker instructions which are not yet working should look simply something like this:
./run-docker ./build --download-dependencies doc
which also downloads build dependencies.
Then the following times just to the faster:
./build-doc
Source: build-doc
The HTML output is located at:
xdg-open out/README.html
More information about our documentation internals can be found at: Section 38.5, “Documentation”
3. GDB step debug
3.1. GDB step debug kernel boot
--gdb-wait makes QEMU and gem5 wait for a GDB connection, otherwise we could accidentally go past the point we want to break at:
./run --gdb-wait
Say you want to break at start_kernel. So on another shell:
./run-gdb start_kernel
or at a given line:
./run-gdb init/main.c:1088
Now QEMU will stop there, and you can use the normal GDB commands:
list next continue
See also:
3.1.1. GDB step debug kernel boot other archs
Just don’t forget to pass --arch to ./run-gdb, e.g.:
./run --arch aarch64 --gdb-wait
and:
./run-gdb --arch aarch64 start_kernel
3.1.2. Disable kernel compiler optimizations
O=0 is an impossible dream, O=2 being the default.
So get ready for some weird jumps, and <value optimized out> fun. Why, Linux, why.
The -O level of some other userland content can be controlled as explained at: Optimization level of a build.
3.2. GDB step debug kernel post-boot
Let’s observe the kernel write system call as it reacts to some userland actions.
Start QEMU with just:
./run
and after boot inside a shell run:
./count.sh
which counts to infinity to stdout. Source: rootfs_overlay/lkmc/count.sh.
Then in another shell, run:
./run-gdb
and then hit:
Ctrl-C break __x64_sys_write continue continue continue
And you now control the counting on the first shell from GDB!
Before v4.17, the symbol name was just sys_write, the change happened at d5a00528b58cdb2c71206e18bd021e34c4eab878. As of Linux v 4.19, the function is called sys_write in arm, and __arm64_sys_write in aarch64. One good way to find it if the name changes again is to try:
rbreak .*sys_write
or just have a quick look at the sources!
When you hit Ctrl-C, if we happen to be inside kernel code at that point, which is very likely if there are no heavy background tasks waiting, and we are just waiting on a sleep type system call of the command prompt, we can already see the source for the random place inside the kernel where we stopped.
3.3. tmux
tmux just makes things even more fun by allowing us to see both the terminal for:
-
emulator stdout
at once without dragging windows around!
First start tmux with:
tmux
Now that you are inside a shell inside tmux, you can start GDB simply with:
./run --gdb
which is just a convenient shortcut for:
./run --gdb-wait --tmux --tmux-args start_kernel
This splits the terminal into two panes:
-
left: usual QEMU with terminal
-
right: GDB
and focuses on the GDB pane.
Now you can navigate with the usual tmux shortcuts:
-
switch between the two panes with:
Ctrl-B O -
close either pane by killing its terminal with
Ctrl-Das usual
See the tmux manual for further details:
man tmux
To start again, switch back to the QEMU pane with Ctrl-O, kill the emulator, and re-run:
./run --gdb
This automatically clears the GDB pane, and starts a new one.
The option --tmux-args determines which options will be passed to the program running on the second tmux pane, and is equivalent to:
This is equivalent to:
./run --gdb-wait ./run-gdb start_kernel
Due to Python’s CLI parsing quicks, if the run-gdb arguments start with a dash -, you have to use the = sign, e.g. to GDB step debug early boot:
./run --gdb --tmux-args=--no-continue
3.3.1. tmux gem5
If you are using gem5 instead of QEMU, --tmux has a different effect by default: it opens the gem5 terminal instead of the debugger:
./run --emulator gem5 --tmux
To open a new pane with GDB instead of the terminal, use:
./run --gdb
which is equivalent to:
./run --emulator gem5 --gdb-wait --tmux --tmux-args start_kernel --tmux-program gdb
--tmux-program implies --tmux, so we can just write:
./run --emulator gem5 --gdb-wait --tmux-program gdb
If you also want to see both GDB and the terminal with gem5, then you will need to open a separate shell manually as usual with ./gem5-shell.
From inside tmux, you can create new terminals on a new window with Ctrl-B C split a pane yet again vertically with Ctrl-B % or horizontally with Ctrl-B ".
3.4. GDB step debug kernel module
Loadable kernel modules are a bit trickier since the kernel can place them at different memory locations depending on load order.
So we cannot set the breakpoints before insmod.
However, the Linux kernel GDB scripts offer the lx-symbols command, which takes care of that beautifully for us.
Shell 1:
./run
Wait for the boot to end and run:
insmod timer.ko
Source: kernel_modules/timer.c.
This prints a message to dmesg every second.
Shell 2:
./run-gdb
In GDB, hit Ctrl-C, and note how it says:
scanning for modules in /root/linux-kernel-module-cheat/out/kernel_modules/x86_64/kernel_modules loading @0xffffffffc0000000: /root/linux-kernel-module-cheat/out/kernel_modules/x86_64/kernel_modules/timer.ko
That’s lx-symbols working! Now simply:
break lkmc_timer_callback continue continue continue
and we now control the callback from GDB!
Just don’t forget to remove your breakpoints after rmmod, or they will point to stale memory locations.
TODO: why does break work_func for insmod kthread.ko not very well? Sometimes it breaks but not others.
3.4.1. GDB step debug kernel module insmodded by init on ARM
TODO on arm 51e31cdc2933a774c2a0dc62664ad8acec1d2dbe it does not always work, and lx-symbols fails with the message:
loading vmlinux
Traceback (most recent call last):
File "/linux-kernel-module-cheat//out/arm/buildroot/build/linux-custom/scripts/gdb/linux/symbols.py", line 163, in invoke
self.load_all_symbols()
File "/linux-kernel-module-cheat//out/arm/buildroot/build/linux-custom/scripts/gdb/linux/symbols.py", line 150, in load_all_symbols
[self.load_module_symbols(module) for module in module_list]
File "/linux-kernel-module-cheat//out/arm/buildroot/build/linux-custom/scripts/gdb/linux/symbols.py", line 110, in load_module_symbols
module_name = module['name'].string()
gdb.MemoryError: Cannot access memory at address 0xbf0000cc
Error occurred in Python command: Cannot access memory at address 0xbf0000cc
Can’t reproduce on x86_64 and aarch64 are fine.
It is kind of random: if you just insmod manually and then immediately ./run-gdb --arch arm, then it usually works.
But this fails most of the time: shell 1:
./run --arch arm --eval-after 'insmod hello.ko'
shell 2:
./run-gdb --arch arm
then hit Ctrl-C on shell 2, and voila.
Then:
cat /proc/modules
says that the load address is:
0xbf000000
so it is close to the failing 0xbf0000cc.
readelf:
./run-toolchain readelf -- -s "$(./getvar kernel_modules_build_subdir)/hello.ko"
does not give any interesting hits at cc, no symbol was placed that far.
3.4.2. GDB module_init
TODO find a more convenient method. We have working methods, but they are not ideal.
This is not very easy, since by the time the module finishes loading, and lx-symbols can work properly, module_init has already finished running!
Possibly asked at:
3.4.2.1. GDB module_init step into it
This is the best method we’ve found so far.
The kernel calls module_init synchronously, therefore it is not hard to step into that call.
As of 4.16, the call happens in do_one_initcall, so we can do in shell 1:
./run
shell 2 after boot finishes (because there are other calls to do_init_module at boot, presumably for the built-in modules):
./run-gdb do_one_initcall
then step until the line:
833 ret = fn();
which does the actual call, and then step into it.
For the next time, you can also put a breakpoint there directly:
./run-gdb init/main.c:833
How we found this out: first we got GDB module_init calculate entry address working, and then we did a bt. AKA cheating :-)
3.4.2.2. GDB module_init calculate entry address
This works, but is a bit annoying.
The key observation is that the load address of kernel modules is deterministic: there is a pre allocated memory region https://www.kernel.org/doc/Documentation/x86/x86_64/mm.txt "module mapping space" filled from bottom up.
So once we find the address the first time, we can just reuse it afterwards, as long as we don’t modify the module.
Do a fresh boot and get the module:
./run --eval-after './pr_debug.sh;insmod fops.ko;./linux/poweroff.out'
The boot must be fresh, because the load address changes every time we insert, even after removing previous modules.
The base address shows on terminal:
0xffffffffc0000000 .text
Now let’s find the offset of myinit:
./run-toolchain readelf -- \ -s "$(./getvar kernel_modules_build_subdir)/fops.ko" | \ grep myinit
which gives:
30: 0000000000000240 43 FUNC LOCAL DEFAULT 2 myinit
so the offset address is 0x240 and we deduce that the function will be placed at:
0xffffffffc0000000 + 0x240 = 0xffffffffc0000240
Now we can just do a fresh boot on shell 1:
./run --eval 'insmod fops.ko;./linux/poweroff.out' --gdb-wait
and on shell 2:
./run-gdb '*0xffffffffc0000240'
GDB then breaks, and lx-symbols works.
3.4.2.3. GDB module_init break at the end of sys_init_module
TODO not working. This could be potentially very convenient.
The idea here is to break at a point late enough inside sys_init_module, at which point lx-symbols can be called and do its magic.
Beware that there are both sys_init_module and sys_finit_module syscalls, and insmod uses fmodule_init by default.
Both call do_module_init however, which is what lx-symbols hooks to.
If we try:
b sys_finit_module
then hitting:
n
does not break, and insertion happens, likely because of optimizations? Disable kernel compiler optimizations
Then we try:
b do_init_module
A naive:
fin
also fails to break!
Finally, in despair we notice that pr_debug prints the kernel load address as explained at Bypass lx-symbols.
So, if we set a breakpoint just after that message is printed by searching where that happens on the Linux source code, we must be able to get the correct load address before init_module happens.
3.4.2.4. GDB module_init add trap instruction
This is another possibility: we could modify the module source by adding a trap instruction of some kind.
This appears to be described at: https://www.linuxjournal.com/article/4525
But it refers to a gdbstart script which is not in the tree anymore and beyond my git log capabilities.
And just adding:
asm( " int $3");
directly gives an oops as I’d expect.
3.4.3. Bypass lx-symbols
Useless, but a good way to show how hardcore you are. Disable lx-symbols with:
./run-gdb --no-lxsymbols
From inside guest:
insmod timer.ko cat /proc/modules
as mentioned at:
This will give a line of form:
fops 2327 0 - Live 0xfffffffa00000000
And then tell GDB where the module was loaded with:
Ctrl-C add-symbol-file ../../../rootfs_overlay/x86_64/timer.ko 0xffffffffc0000000 0xffffffffc0000000
Alternatively, if the module panics before you can read /proc/modules, there is a pr_debug which shows the load address:
echo 8 > /proc/sys/kernel/printk echo 'file kernel/module.c +p' > /sys/kernel/debug/dynamic_debug/control ./linux/myinsmod.out hello.ko
And then search for a line of type:
[ 84.877482] 0xfffffffa00000000 .text
Tested on 4f4749148273c282e80b58c59db1b47049e190bf + 1.
3.5. GDB step debug early boot
TODO successfully debug the very first instruction that the Linux kernel runs, before start_kernel!
Break at the very first instruction executed by QEMU:
./run-gdb --no-continue
Note however that early boot parts appear to be relocated in memory somehow, and therefore:
-
you won’t see the source location in GDB, only assembly
-
you won’t be able to break by symbol in those early locations
Further discussion at: Linux kernel entry point.
In the specific case of gem5 aarch64 at least:
-
gem5 relocates the kernel in memory to a fixed location, see e.g. https://gem5.atlassian.net/browse/GEM5-787
-
--param 'system.workload.early_kernel_symbols=Trueshould in theory duplicate the symbols to the correct physical location, but it was broken at one point: https://gem5.atlassian.net/browse/GEM5-785 -
gem5 executes directly from vmlinux, so there is no decompression code involved, so you actually immediately start running the "true" first instruction from
head.Sas described at: https://stackoverflow.com/questions/18266063/does-linux-kernel-have-main-function/33422401#33422401 -
once the MMU gets turned on at kernel symbol
__primary_switched, the virtual address matches the ELF symbols, and you start seeing correct symbols without the need forearly_kernel_symbols. This can be observed clearly withfunction_trace = True: https://stackoverflow.com/questions/64049487/how-to-trace-executed-guest-function-symbol-names-with-their-timestamp-in-gem5/64049488#64049488 which produces:0: _kernel_flags_le_lo32 (12500) 12500: __crc_tcp_add_backlog (1000) 13500: __crc_crypto_alg_tested (6500) 20000: __crc_tcp_add_backlog (10000) 30000: __crc_crypto_alg_tested (500) 30500: __crc_scsi_is_host_device (5000) 35500: __crc_crypto_alg_tested (1500) 37000: __crc_scsi_is_host_device (4000) 41000: __crc_crypto_alg_tested (3000) 44000: __crc_tcp_add_backlog (263500) 307500: __crc_crypto_alg_tested (975500) 1283000: __crc_tcp_add_backlog (77191500) 78474500: __crc_crypto_alg_tested (1000) 78475500: __crc_scsi_is_host_device (19500) 78495000: __crc_crypto_alg_tested (500) 78495500: __crc_scsi_is_host_device (13500) 78509000: __primary_switched (14000) 78523000: memset (21118000) 99641000: __primary_switched (2500) 99643500: start_kernel (11000)
so we see that
primary_switchedis the first non-trash symbol (non-crc_*and non-kernel_flags*, which are just informative symbols, not actual executable code)
3.5.1. Linux kernel entry point
As mentioned at: GDB step debug early boot, the very first kernel instructions executed appear to be placed into memory at a different location than that of the kernel ELF section.
As a result, we are unable to break on early symbols such as:
./run-gdb extract_kernel ./run-gdb main
gem5 ExecAll trace format>> however does show the right symbols however! This could be because gem5 uses vmlinux to boot, which QEMU uses the compressed version, and as mentioned on the Stack Overflow answer, the entry point is actually a tiny decompresser routine.
I also tried to hack run-gdb with:
@@ -81,7 +81,7 @@ else
${gdb} \
-q \\
-ex 'add-auto-load-safe-path $(pwd)' \\
--ex 'file vmlinux' \\
+-ex 'file arch/arm/boot/compressed/vmlinux' \\
-ex 'target remote localhost:${port}' \\
${brk} \
-ex 'continue' \\
and no I do have the symbols from arch/arm/boot/compressed/vmlinux', but the breaks still don’t work.
v4.19 also added a CONFIG_HAVE_KERNEL_UNCOMPRESSED=y option for having the kernel uncompressed which could make following the startup easier, but it is only available on s390. aarch64 however is already uncompressed by default, so might be the easiest one. See also: Section 17.20.1, “vmlinux vs bzImage vs zImage vs Image”.
You then need the associated KERNEL_UNCOMPRESSED to enable it if available:
config KERNEL_UNCOMPRESSED
bool "None"
depends on HAVE_KERNEL_UNCOMPRESSED
3.5.1.1. arm64 secondary CPU entry point
In gem5 aarch64 Linux v4.18, experimentally the entry point of secondary CPUs seems to be secondary_holding_pen as shown at https://gist.github.com/cirosantilli2/34a7bc450fcb6c1c1a910369be1fdd90
What happens is that:
-
the bootloader goes in in WFE
-
the kernel writes the entry point to the secondary CPU (the address of
secondary_holding_pen) with CPU0 at the address given to the kernel in thecpu-release-addrof the DTB -
the kernel wakes up the bootloader with a SEV, and the bootloader boots to the address the kernel told it
The CPU0 action happens at: https://github.com/cirosantilli/linux/blob/v5.7/arch/arm64/kernel/smp_spin_table.c:
Here’s the code that writes the address and does SEV:
static int smp_spin_table_cpu_prepare(unsigned int cpu)
{
__le64 __iomem *release_addr;
if (!cpu_release_addr[cpu])
return -ENODEV;
/*
* The cpu-release-addr may or may not be inside the linear mapping.
* As ioremap_cache will either give us a new mapping or reuse the
* existing linear mapping, we can use it to cover both cases. In
* either case the memory will be MT_NORMAL.
*/
release_addr = ioremap_cache(cpu_release_addr[cpu],
sizeof(*release_addr));
if (!release_addr)
return -ENOMEM;
/*
* We write the release address as LE regardless of the native
* endianess of the kernel. Therefore, any boot-loaders that
* read this address need to convert this address to the
* boot-loader's endianess before jumping. This is mandated by
* the boot protocol.
*/
writeq_relaxed(__pa_symbol(secondary_holding_pen), release_addr);
__flush_dcache_area((__force void *)release_addr,
sizeof(*release_addr));
/*
* Send an event to wake up the secondary CPU.
*/
sev();
and here’s the code that reads the value from the DTB:
static int smp_spin_table_cpu_init(unsigned int cpu)
{
struct device_node *dn;
int ret;
dn = of_get_cpu_node(cpu, NULL);
if (!dn)
return -ENODEV;
/*
* Determine the address from which the CPU is polling.
*/
ret = of_property_read_u64(dn, "cpu-release-addr",
&cpu_release_addr[cpu]);
3.5.2. Linux kernel arch-agnostic entry point
start_kernel is the first C function to be executed basically: https://stackoverflow.com/questions/18266063/does-kernel-have-main-function/33422401#33422401
For the earlier arch-specific entry point, see: Linux kernel entry point.
3.5.3. Linux kernel early boot messages
When booting Linux on a slow emulator like gem5, what you observe is that:
-
first nothing shows for a while
-
then at once, a bunch of message lines show at once followed on aarch64 Linux 5.4.3 by:
[ 0.081311] printk: console [ttyAMA0] enabled
This means of course that all the previous messages had been generated earlier and stored, but were only printed to the terminal once the terminal itself was enabled.
Notably for example the very first message:
[ 0.000000] Booting Linux on physical CPU 0x0000000000 [0x410fd070]
happens very early in the boot process.
If you get a failure before that, it will be hard to see the print messages.
One possible solution is to parse the dmesg buffer, gem5 actually implements that: gem5 m5out/system.workload.dmesg file.
3.6. GDB step debug userland processes
QEMU’s -gdb GDB breakpoints are set on virtual addresses, so you can in theory debug userland processes as well.
You will generally want to use gdbserver for this as it is more reliable, but this method can overcome the following limitations of gdbserver:
-
the emulator does not support host to guest networking. This seems to be the case for gem5 as explained at: Section 15.3.1.3, “gem5 host to guest networking”
-
cannot see the start of the
initprocess easily -
gdbserveralters the working of the kernel, and makes your run less representative
Known limitations of direct userland debugging:
-
the kernel might switch context to another process or to the kernel itself e.g. on a system call, and then TODO confirm the PIC would go to weird places and source code would be missing.
Solutions to this are being researched at: Section 3.10.1, “lx-ps”.
-
TODO step into shared libraries. If I attempt to load them explicitly:
(gdb) sharedlibrary ../../staging/lib/libc.so.0 No loaded shared libraries match the pattern `../../staging/lib/libc.so.0'.
since GDB does not know that libc is loaded.
3.6.1. GDB step debug userland custom init
This is the userland debug setup most likely to work, since at init time there is only one userland executable running.
For executables from the userland/ directory such as userland/posix/count.c:
-
Shell 1:
./run --gdb-wait --kernel-cli 'init=/lkmc/posix/count.out'
-
Shell 2:
./run-gdb --userland userland/posix/count.c main
Alternatively, we could also pass the full path to the executable:
./run-gdb --userland "$(./getvar userland_build_dir)/posix/count.out" main
Path resolution is analogous to that of
./run --baremetal.
Then, as soon as boot ends, we are left inside a debug session that looks just like what gdbserver would produce.
3.6.2. GDB step debug userland BusyBox init
BusyBox custom init process:
-
Shell 1:
./run --gdb-wait --kernel-cli 'init=/bin/ls'
-
Shell 2:
./run-gdb --userland "$(./getvar buildroot_build_build_dir)"/busybox-*/busybox ls_main
This follows BusyBox' convention of calling the main for each executable as <exec>_main since the busybox executable has many "mains".
BusyBox default init process:
-
Shell 1:
./run --gdb-wait
-
Shell 2:
./run-gdb --userland "$(./getvar buildroot_build_build_dir)"/busybox-*/busybox init_main
init cannot be debugged with gdbserver without modifying the source, or else /sbin/init exits early with:
"must be run as PID 1"
3.6.3. GDB step debug userland non-init
Non-init process:
-
Shell 1:
./run --gdb-wait
-
Shell 2:
./run-gdb --userland userland/linux/rand_check.c main
-
Shell 1 after the boot finishes:
./linux/rand_check.out
This is the least reliable setup as there might be other processes that use the given virtual address.
3.6.3.1. GDB step debug userland non-init without --gdb-wait
TODO: if I try GDB step debug userland non-init without --gdb-wait and the break main that we do inside ./run-gdb says:
Cannot access memory at address 0x10604
and then GDB never breaks. Tested at ac8663a44a450c3eadafe14031186813f90c21e4 + 1.
The exact behaviour seems to depend on the architecture:
-
arm: happens always -
x86_64: appears to happen only if you try to connect GDB as fast as possible, before init has been reached. -
aarch64: could not observe the problem
We have also double checked the address with:
./run-toolchain --arch arm readelf -- \ -s "$(./getvar --arch arm userland_build_dir)/linux/myinsmod.out" | \ grep main
and from GDB:
info line main
and both give:
000105fc
which is just 8 bytes before 0x10604.
gdbserver also says 0x10604.
However, if do a Ctrl-C in GDB, and then a direct:
b *0x000105fc
it works. Why?!
On GEM5, x86 can also give the Cannot access memory at address, so maybe it is also unreliable on QEMU, and works just by coincidence.
3.7. GDB call
GDB can call functions as explained at: https://stackoverflow.com/questions/1354731/how-to-evaluate-functions-in-gdb
However this is failing for us:
-
some symbols are not visible to
calleven thoughbsees them -
for those that are,
callfails with an E14 error
E.g.: if we break on __x64_sys_write on count.sh:
>>> call printk(0, "asdf") Could not fetch register "orig_rax"; remote failure reply 'E14' >>> b printk Breakpoint 2 at 0xffffffff81091bca: file kernel/printk/printk.c, line 1824. >>> call fdget_pos(fd) No symbol "fdget_pos" in current context. >>> b fdget_pos Breakpoint 3 at 0xffffffff811615e3: fdget_pos. (9 locations) >>>
even though fdget_pos is the first thing __x64_sys_write does:
581 SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf,
582 size_t, count)
583 {
584 struct fd f = fdget_pos(fd);
I also noticed that I get the same error:
Could not fetch register "orig_rax"; remote failure reply 'E14'
when trying to use:
fin
on many (all?) functions.
3.8. GDB view ARM system registers
info all-registers shows some of them.
The implementation is described at: https://stackoverflow.com/questions/46415059/how-to-observe-aarch64-system-registers-in-qemu/53043044#53043044
3.9. GDB step debug multicore userland
For a more minimal baremetal multicore setup, see: Section 33.10.3, “ARM baremetal multicore”.
We can set and get which cores the Linux kernel allows a program to run on with sched_getaffinity and sched_setaffinity:
./run --cpus 2 --eval-after './linux/sched_getaffinity.out'
Sample output:
sched_getaffinity = 1 1 sched_getcpu = 1 sched_getaffinity = 1 0 sched_getcpu = 0
Which shows us that:
-
initially:
-
all 2 cores were enabled as shown by
sched_getaffinity = 1 1 -
the process was randomly assigned to run on core 1 (the second one) as shown by
sched_getcpu = 1. If we run this several times, it will also run on core 0 sometimes.
-
-
then we restrict the affinity to just core 0, and we see that the program was actually moved to core 0
The number of cores is modified as explained at: Section 24.3.1, “Number of cores”
taskset from the util-linux package sets the initial core affinity of a program:
./build-buildroot \ --config 'BR2_PACKAGE_UTIL_LINUX=y' \ --config 'BR2_PACKAGE_UTIL_LINUX_SCHEDUTILS=y' \ ; ./run --eval-after 'taskset -c 1,1 ./linux/sched_getaffinity.out'
output:
sched_getaffinity = 0 1 sched_getcpu = 1 sched_getaffinity = 1 0 sched_getcpu = 0
so we see that the affinity was restricted to the second core from the start.
Let’s do a QEMU observation to justify this example being in the repository with userland breakpoints.
We will run our ./linux/sched_getaffinity.out infinitely many times, on core 0 and core 1 alternatively:
./run \ --cpus 2 \ --eval-after 'i=0; while true; do taskset -c $i,$i ./linux/sched_getaffinity.out; i=$((! $i)); done' \ --gdb-wait \ ;
on another shell:
./run-gdb --userland "$(./getvar userland_build_dir)/linux/sched_getaffinity.out" main
Then, inside GDB:
(gdb) info threads Id Target Id Frame * 1 Thread 1 (CPU#0 [running]) main () at sched_getaffinity.c:30 2 Thread 2 (CPU#1 [halted ]) native_safe_halt () at ./arch/x86/include/asm/irqflags.h:55 (gdb) c (gdb) info threads Id Target Id Frame 1 Thread 1 (CPU#0 [halted ]) native_safe_halt () at ./arch/x86/include/asm/irqflags.h:55 * 2 Thread 2 (CPU#1 [running]) main () at sched_getaffinity.c:30 (gdb) c
and we observe that info threads shows the actual correct core on which the process was restricted to run by taskset!
We should also try it out with kernel modules: https://stackoverflow.com/questions/28347876/set-cpu-affinity-on-a-loadable-linux-kernel-module
TODO we then tried:
./run --cpus 2 --eval-after './linux/sched_getaffinity_threads.out'
and:
./run-gdb --userland "$(./getvar userland_build_dir)/linux/sched_getaffinity_threads.out"
to switch between two simultaneous live threads with different affinities, it just didn’t break on our threads:
b main_thread_0
Note that secondary cores in gem5 are kind of broken however: gem5 GDB step debug secondary cores.
Bibliography:
3.10. Linux kernel GDB scripts
We source the Linux kernel GDB scripts by default for lx-symbols, but they also contains some other goodies worth looking into.
Those scripts basically parse some in-kernel data structures to offer greater visibility with GDB.
All defined commands are prefixed by lx-, so to get a full list just try to tab complete that.
There aren’t as many as I’d like, and the ones that do exist are pretty self explanatory, but let’s give a few examples.
Show dmesg:
lx-dmesg
Show the Kernel command line parameters:
lx-cmdline
Dump the device tree to a fdtdump.dtb file in the current directory:
lx-fdtdump pwd
List inserted kernel modules:
lx-lsmod
Sample output:
Address Module Size Used by 0xffffff80006d0000 hello 16384 0
Bibliography:
3.10.1. lx-ps
List all processes:
lx-ps
Sample output:
0xffff88000ed08000 1 init 0xffff88000ed08ac0 2 kthreadd
The second and third fields are obviously PID and process name.
The first one is more interesting, and contains the address of the task_struct in memory.
This can be confirmed with:
p ((struct task_struct)*0xffff88000ed08000
which contains the correct PID for all threads I’ve tried:
pid = 1,
TODO get the PC of the kthreads: https://stackoverflow.com/questions/26030910/find-program-counter-of-process-in-kernel Then we would be able to see where the threads are stopped in the code!
On ARM, I tried:
task_pt_regs((struct thread_info *)((struct task_struct)*0xffffffc00e8f8000))->uregs[ARM_pc]
but task_pt_regs is a #define and GDB cannot see defines without -ggdb3: https://stackoverflow.com/questions/2934006/how-do-i-print-a-defined-constant-in-gdb which are apparently not set?
Bibliography:
3.10.1.1. CONFIG_PID_IN_CONTEXTIDR
https://stackoverflow.com/questions/54133479/accessing-logical-software-thread-id-in-gem5 on ARM the kernel can store an indication of PID in the CONTEXTIDR_EL1 register, making that much easier to observe from simulators.
In particular, gem5 prints that number out by default on ExecAll messages!
Let’s test it out with Linux kernel build variants + gem5 checkpoint restore and run a different script:
./build-linux --arch aarch64 --linux-build-id CONFIG_PID_IN_CONTEXTIDR --config 'CONFIG_PID_IN_CONTEXTIDR=y' # Checkpoint run. ./run --arch aarch64 --emulator gem5 --linux-build-id CONFIG_PID_IN_CONTEXTIDR --eval './gem5.sh' # Trace run. ./run \ --arch aarch64 \ --emulator gem5 \ --gem5-readfile 'posix/getpid.out; posix/getpid.out' \ --gem5-restore 1 \ --linux-build-id CONFIG_PID_IN_CONTEXTIDR \ --trace FmtFlag,ExecAll,-ExecSymbol \ ;
The terminal runs both programs which output their PID to stdout:
pid=44 pid=45
By quickly inspecting the trace.txt file, we immediately notice that the system.cpu: A<n> part of the logs, which used to always be system.cpu: A0, now has a few different values! Nice!
We can briefly summarize those values by removing repetitions:
cut -d' ' -f4 "$(./getvar --arch aarch64 --emulator gem5 trace_txt_file)" | uniq -c
gives:
97227 A39
147476 A38
222052 A40
1 terminal
1117724 A40
27529 A31
43868 A40
27487 A31
138349 A40
13781 A38
231246 A40
25536 A38
28337 A40
214799 A38
963561 A41
92603 A38
27511 A31
224384 A38
564949 A42
182360 A38
729009 A43
8398 A23
20200 A10
636848 A43
187995 A44
27529 A31
70071 A44
16981 A0
623806 A44
16981 A0
139319 A44
24487 A0
174986 A44
25420 A0
89611 A44
16981 A0
183184 A44
24728 A0
89608 A44
17226 A0
899075 A44
24974 A0
250608 A44
137700 A43
1497997 A45
227485 A43
138147 A38
482646 A46
I’m not smart enough to be able to deduce all of those IDs, but we can at least see that:
-
A44 and A45 are there as expected from stdout!
-
A39 must be the end of the execution of
m5 checkpoint -
so we guess that A38 is the shell as it comes next
-
the weird "terminal" line is
336969745500: system.terminal: attach terminal 0 -
which is the shell PID? I should have printed that as well :-)
-
why are there so many other PIDs? This was supposed to be a silent system without daemons!
-
A0 is presumably the kernel. However we see process switches without going into A0, so I’m not sure how, it appears to count kernel instructions as part of processes
-
A46 has to be the
m5 exitcall
Or if you want to have some real fun, try: baremetal/arch/aarch64/contextidr_el1.c:
./run --arch aarch64 --emulator gem5 --baremetal baremetal/arch/aarch64/contextidr_el1.c --trace-insts-stdout
in which we directly set the register ourselves! Output excerpt:
31500: system.cpu: A0 T0 : @main+12 : ldr x0, [sp, #12] : MemRead : D=0x0000000000000001 A=0x82fffffc flags=(IsInteger|IsMemRef|IsLoad) 32000: system.cpu: A1 T0 : @main+16 : msr contextidr_el1, x0 : IntAlu : D=0x0000000000000001 flags=(IsInteger|IsSerializeAfter|IsNonSpeculative) 32500: system.cpu: A1 T0 : @main+20 : ldr x0, [sp, #12] : MemRead : D=0x0000000000000001 A=0x82fffffc flags=(IsInteger|IsMemRef|IsLoad) 33000: system.cpu: A1 T0 : @main+24 : add w0, w0, #1 : IntAlu : D=0x0000000000000002 flags=(IsInteger) 33500: system.cpu: A1 T0 : @main+28 : str x0, [sp, #12] : MemWrite : D=0x0000000000000002 A=0x82fffffc flags=(IsInteger|IsMemRef|IsStore) 34000: system.cpu: A1 T0 : @main+32 : ldr x0, [sp, #12] : MemRead : D=0x0000000000000002 A=0x82fffffc flags=(IsInteger|IsMemRef|IsLoad) 34500: system.cpu: A1 T0 : @main+36 : subs w0, #9 : IntAlu : D=0x0000000000000000 flags=(IsInteger) 35000: system.cpu: A1 T0 : @main+40 : b.le <main+12> : IntAlu : flags=(IsControl|IsDirectControl|IsCondControl) 35500: system.cpu: A1 T0 : @main+12 : ldr x0, [sp, #12] : MemRead : D=0x0000000000000002 A=0x82fffffc flags=(IsInteger|IsMemRef|IsLoad) 36000: system.cpu: A2 T0 : @main+16 : msr contextidr_el1, x0 : IntAlu : D=0x0000000000000002 flags=(IsInteger|IsSerializeAfter|IsNonSpeculative) 36500: system.cpu: A2 T0 : @main+20 : ldr x0, [sp, #12] : MemRead : D=0x0000000000000002 A=0x82fffffc flags=(IsInteger|IsMemRef|IsLoad) 37000: system.cpu: A2 T0 : @main+24 : add w0, w0, #1 : IntAlu : D=0x0000000000000003 flags=(IsInteger) 37500: system.cpu: A2 T0 : @main+28 : str x0, [sp, #12] : MemWrite : D=0x0000000000000003 A=0x82fffffc flags=(IsInteger|IsMemRef|IsStore) 38000: system.cpu: A2 T0 : @main+32 : ldr x0, [sp, #12] : MemRead : D=0x0000000000000003 A=0x82fffffc flags=(IsInteger|IsMemRef|IsLoad) 38500: system.cpu: A2 T0 : @main+36 : subs w0, #9 : IntAlu : D=0x0000000000000000 flags=(IsInteger) 39000: system.cpu: A2 T0 : @main+40 : b.le <main+12> : IntAlu : flags=(IsControl|IsDirectControl|IsCondControl) 39500: system.cpu: A2 T0 : @main+12 : ldr x0, [sp, #12] : MemRead : D=0x0000000000000003 A=0x82fffffc flags=(IsInteger|IsMemRef|IsLoad) 40000: system.cpu: A3 T0 : @main+16 : msr contextidr_el1, x0 : IntAlu : D=0x0000000000000003 flags=(IsInteger|IsSerializeAfter|IsNonSpeculative)
ARMv8 architecture reference manual db D13.2.27 "CONTEXTIDR_EL1, Context ID Register (EL1)" documents CONTEXTIDR_EL1 as:
Identifies the current Process Identifier.
The value of the whole of this register is called the Context ID and is used by:
The debug logic, for Linked and Unlinked Context ID matching.
The trace logic, to identify the current process.
The significance of this register is for debug and trace use only.
Tested on 145769fc387dc5ee63ec82e55e6b131d9c968538 + 1.
3.11. Debug the GDB remote protocol
For when it breaks again, or you want to add a new feature!
./run --debug ./run-gdb --before '-ex "set remotetimeout 99999" -ex "set debug remote 1"' start_kernel
3.11.1. Remote 'g' packet reply is too long
This error means that the GDB server, e.g. in QEMU, sent more registers than the GDB client expected.
This can happen for the following reasons:
-
you set the architecture of the client wrong, often 32 vs 64 bit as mentioned at: https://stackoverflow.com/questions/4896316/gdb-remote-cross-debugging-fails-with-remote-g-packet-reply-is-too-long
-
there is a bug in the GDB server and the XML description does not match the number of registers actually sent
-
the GDB server does not send XML target descriptions and your GDB expects a different number of registers by default. E.g., gem5 d4b3e064adeeace3c3e7d106801f95c14637c12f does not send the XML files
The XML target description format is described a bit further at: https://stackoverflow.com/questions/46415059/how-to-observe-aarch64-system-registers-in-qemu/53043044#53043044
4. KGDB
KGDB is kernel dark magic that allows you to GDB the kernel on real hardware without any extra hardware support.
It is useless with QEMU since we already have full system visibility with -gdb. So the goal of this setup is just to prepare you for what to expect when you will be in the treches of real hardware.
KGDB is cheaper than JTAG (free) and easier to setup (all you need is serial), but with less visibility as it depends on the kernel working, so e.g.: dies on panic, does not see boot sequence.
First run the kernel with:
./run --kgdb
this passes the following options on the kernel CLI:
kgdbwait kgdboc=ttyS1,115200
kgdbwait tells the kernel to wait for KGDB to connect.
So the kernel sets things up enough for KGDB to start working, and then boot pauses waiting for connection:
<6>[ 4.866050] Serial: 8250/16550 driver, 4 ports, IRQ sharing disabled <6>[ 4.893205] 00:05: ttyS0 at I/O 0x3f8 (irq = 4, base_baud = 115200) is a 16550A <6>[ 4.916271] 00:06: ttyS1 at I/O 0x2f8 (irq = 3, base_baud = 115200) is a 16550A <6>[ 4.987771] KGDB: Registered I/O driver kgdboc <2>[ 4.996053] KGDB: Waiting for connection from remote gdb... Entering kdb (current=0x(____ptrval____), pid 1) on processor 0 due to Keyboard Entry [0]kdb>
KGDB expects the connection at ttyS1, our second serial port after ttyS0 which contains the terminal.
The last line is the KDB prompt, and is covered at: Section 4.3, “KDB”. Typing now shows nothing because that prompt is expecting input from ttyS1.
Instead, we connect to the serial port ttyS1 with GDB:
./run-gdb --kgdb --no-continue
Once GDB connects, it is left inside the function kgdb_breakpoint.
So now we can set breakpoints and continue as usual.
For example, in GDB:
continue
Then in QEMU:
./count.sh & ./kgdb.sh
rootfs_overlay/lkmc/kgdb.sh pauses the kernel for KGDB, and gives control back to GDB.
And now in GDB we do the usual:
break __x64_sys_write continue continue continue continue
And now you can count from KGDB!
If you do: break __x64_sys_write immediately after ./run-gdb --kgdb, it fails with KGDB: BP remove failed: <address>. I think this is because it would break too early on the boot sequence, and KGDB is not yet ready.
See also:
4.1. KGDB ARM
TODO: we would need a second serial for KGDB to work, but it is not currently supported on arm and aarch64 with -M virt that we use: https://unix.stackexchange.com/questions/479085/can-qemu-m-virt-on-arm-aarch64-have-multiple-serial-ttys-like-such-as-pl011-t/479340#479340
One possible workaround for this would be to use KDB ARM.
Main more generic question: https://stackoverflow.com/questions/14155577/how-to-use-kgdb-on-arm
4.2. KGDB kernel modules
Just works as you would expect:
insmod timer.ko ./kgdb.sh
In GDB:
break lkmc_timer_callback continue continue continue
and you now control the count.
4.3. KDB
KDB is a way to use KDB directly in your main console, without GDB.
Advantage over KGDB: you can do everything in one serial. This can actually be important if you only have one serial for both shell and .
Disadvantage: not as much functionality as GDB, especially when you use Python scripts. Notably, TODO confirm you can’t see the the kernel source code and line step as from GDB, since the kernel source is not available on guest (ah, if only debugging information supported full source, or if the kernel had a crazy mechanism to embed it).
Run QEMU as:
./run --kdb
This passes kgdboc=ttyS0 to the Linux CLI, therefore using our main console. Then QEMU:
[0]kdb> go
And now the kdb> prompt is responsive because it is listening to the main console.
After boot finishes, run the usual:
./count.sh & ./kgdb.sh
And you are back in KDB. Now you can count with:
[0]kdb> bp __x64_sys_write [0]kdb> go [0]kdb> go [0]kdb> go [0]kdb> go
And you will break whenever __x64_sys_write is hit.
You can get see further commands with:
[0]kdb> help
The other KDB commands allow you to step instructions, view memory, registers and some higher level kernel runtime data similar to the superior GDB Python scripts.
4.3.1. KDB graphic
You can also use KDB directly from the graphic window with:
./run --graphic --kdb
This setup could be used to debug the kernel on machines without serial, such as modern desktops.
This works because --graphics adds kbd (which stands for KeyBoarD!) to kgdboc.
4.3.2. KDB ARM
TODO neither arm and aarch64 are working as of 1cd1e58b023791606498ca509256cc48e95e4f5b + 1.
arm seems to place and hit the breakpoint correctly, but no matter how many go commands I do, the count.sh stdout simply does not show.
aarch64 seems to place the breakpoint correctly, but after the first go the kernel oopses with warning:
WARNING: CPU: 0 PID: 46 at /root/linux-kernel-module-cheat/submodules/linux/kernel/smp.c:416 smp_call_function_many+0xdc/0x358
and stack trace:
smp_call_function_many+0xdc/0x358 kick_all_cpus_sync+0x30/0x38 kgdb_flush_swbreak_addr+0x3c/0x48 dbg_deactivate_sw_breakpoints+0x7c/0xb8 kgdb_cpu_enter+0x284/0x6a8 kgdb_handle_exception+0x138/0x240 kgdb_brk_fn+0x2c/0x40 brk_handler+0x7c/0xc8 do_debug_exception+0xa4/0x1c0 el1_dbg+0x18/0x78 __arm64_sys_write+0x0/0x30 el0_svc_handler+0x74/0x90 el0_svc+0x8/0xc
My theory is that every serious ARM developer has JTAG, and no one ever tests this, and the kernel code is just broken.
5. gdbserver
Step debug userland processes to understand how they are talking to the kernel.
First build gdbserver into the root filesystem:
./build-buildroot --config 'BR2_PACKAGE_GDB=y'
Then on guest, to debug userland/linux/rand_check.c:
./gdbserver.sh ./c/command_line_arguments.out asdf qwer
Source: rootfs_overlay/lkmc/gdbserver.sh.
And on host:
./run-gdb --gdbserver --userland userland/c/command_line_arguments.c main
or alternatively with the path to the executable itself:
./run --gdbserver --userland "$(./getvar userland_build_dir)/c/command_line_arguments.out"
Bibliography: https://reverseengineering.stackexchange.com/questions/8829/cross-debugging-for-arm-mips-elf-with-qemu-toolchain/16214#16214
5.1. gdbserver BusyBox
Analogous to GDB step debug userland processes:
./gdbserver.sh ls
on host you need:
./run-gdb --gdbserver --userland "$(./getvar buildroot_build_build_dir)"/busybox-*/busybox ls_main
5.2. gdbserver libc
Our setup gives you the rare opportunity to step debug libc and other system libraries.
For example in the guest:
./gdbserver.sh ./posix/count.out
Then on host:
./run-gdb --gdbserver --userland userland/posix/count.c main
and inside GDB:
break sleep continue
And you are now left inside the sleep function of our default libc implementation uclibc libc/unistd/sleep.c!
You can also step into the sleep call:
step
This is made possible by the GDB command that we use by default:
set sysroot ${common_buildroot_build_dir}/staging
which automatically finds unstripped shared libraries on the host for us.
5.3. gdbserver dynamic loader
TODO: try to step debug the dynamic loader. Would be even easier if starti is available: https://stackoverflow.com/questions/10483544/stopping-at-the-first-machine-code-instruction-in-gdb
6. CPU architecture
The portability of the kernel and toolchains is amazing: change an option and most things magically work on completely different hardware.
To use arm instead of x86 for example:
./build-buildroot --arch arm ./run --arch arm
Debug:
./run --arch arm --gdb-wait # On another terminal. ./run-gdb --arch arm
We also have one letter shorthand names for the architectures and --arch option:
# aarch64 ./run -a A # arm ./run -a a # x86_64 ./run -a x
Known quirks of the supported architectures are documented in this section.
6.1. x86_64
6.1.1. ring0
This example illustrates how reading from the x86 control registers with mov crX, rax can only be done from kernel land on ring0.
From kernel land:
insmod ring0.ko
works and output the registers, for example:
cr0 = 0xFFFF880080050033 cr2 = 0xFFFFFFFF006A0008 cr3 = 0xFFFFF0DCDC000
However if we try to do it from userland:
./ring0.out
stdout gives:
Segmentation fault
and dmesg outputs:
traps: ring0.out[55] general protection ip:40054c sp:7fffffffec20 error:0 in ring0.out[400000+1000]
Sources:
In both cases, we attempt to run the exact same code which is shared on the ring0.h header file.
Bibliography:
6.2. arm
6.2.1. Run arm executable in aarch64
TODO Can you run arm executables in the aarch64 guest? https://stackoverflow.com/questions/22460589/armv8-running-legacy-32-bit-applications-on-64-bit-os/51466709#51466709
I’ve tried:
./run-toolchain --arch aarch64 gcc -- -static ~/test/hello_world.c -o "$(./getvar p9_dir)/a.out" ./run --arch aarch64 --eval-after '/mnt/9p/data/a.out'
but it fails with:
a.out: line 1: syntax error: unexpected word (expecting ")")
6.3. MIPS
We used to "support" it until f8c0502bb2680f2dbe7c1f3d7958f60265347005 (it booted) but dropped since one was testing it often.
If you want to revive and maintain it, send a pull request.
6.4. Other architectures
It should not be too hard to port this repository to any architecture that Buildroot supports. Pull requests are welcome.
7. init
When the Linux kernel finishes booting, it runs an executable as the first and only userland process. This executable is called the init program.
The init process is then responsible for setting up the entire userland (or destroying everything when you want to have fun).
This typically means reading some configuration files (e.g. /etc/initrc) and forking a bunch of userland executables based on those files, including the very interactive shell that we end up on.
systemd provides a "popular" init implementation for desktop distros as of 2017.
BusyBox provides its own minimalistic init implementation which Buildroot, and therefore this repo, uses by default.
The init program can be either an executable shell text file, or a compiled ELF file. It becomes easy to accept this once you see that the exec system call handles both cases equally: https://unix.stackexchange.com/questions/174062/can-the-init-process-be-a-shell-script-in-linux/395375#395375
The init executable is searched for in a list of paths in the root filesystem, including /init, /sbin/init and a few others. For more details see: Section 7.3, “Path to init”
7.1. Replace init
To have more control over the system, you can replace BusyBox’s init with your own.
The most direct way to replace init with our own is to just use the init= command line parameter directly:
./run --kernel-cli 'init=/lkmc/count.sh'
This just counts every second forever and does not give you a shell.
This method is not very flexible however, as it is hard to reliably pass multiple commands and command line arguments to the init with it, as explained at: Section 7.4, “Init environment”.
For this reason, we have created a more robust helper method with the --eval option:
./run --eval 'echo "asdf qwer";insmod hello.ko;./linux/poweroff.out'
It is basically a shortcut for:
./run --kernel-cli 'init=/lkmc/eval_base64.sh - lkmc_eval="insmod hello.ko;./linux/poweroff.out"'
Source: rootfs_overlay/lkmc/eval_base64.sh.
This allows quoting and newlines by base64 encoding on host, and decoding on guest, see: Section 17.3.1, “Kernel command line parameters escaping”.
It also automatically chooses between init= and rcinit= for you, see: Section 7.3, “Path to init”
--eval replaces BusyBox' init completely, which makes things more minimal, but also has has the following consequences:
-
/etc/fstabmounts are not done, notably/procand/sys, test it out with:./run --eval 'echo asdf;ls /proc;ls /sys;echo qwer'
-
no shell is launched at the end of boot for you to interact with the system. You could explicitly add a
shat the end of your commands however:./run --eval 'echo hello;sh'
The best way to overcome those limitations is to use: Section 7.2, “Run command at the end of BusyBox init”
If the script is large, you can add it to a gitignored file and pass that to --eval as in:
echo ' cd /lkmc insmod hello.ko ./linux/poweroff.out ' > data/gitignore.sh ./run --eval "$(cat data/gitignore.sh)"
or add it to a file to the root filesystem guest and rebuild:
echo '#!/bin/sh cd /lkmc insmod hello.ko ./linux/poweroff.out ' > rootfs_overlay/lkmc/gitignore.sh chmod +x rootfs_overlay/lkmc/gitignore.sh ./build-buildroot ./run --kernel-cli 'init=/lkmc/gitignore.sh'
Remember that if your init returns, the kernel will panic, there are just two non-panic possibilities:
-
run forever in a loop or long sleep
-
poweroffthe machine
7.1.1. poweroff.out
Just using BusyBox' poweroff at the end of the init does not work and the kernel panics:
./run --eval poweroff
because BusyBox' poweroff tries to do some fancy stuff like killing init, likely to allow userland to shutdown nicely.
But this fails when we are init itself!
BusyBox' poweroff works more brutally and effectively if you add -f:
./run --eval 'poweroff -f'
but why not just use our minimal ./linux/poweroff.out and be done with it?
./run --eval './linux/poweroff.out'
Source: userland/linux/poweroff.c
This also illustrates how to shutdown the computer from C: https://stackoverflow.com/questions/28812514/how-to-shutdown-linux-using-c-or-qt-without-call-to-system
7.1.2. sleep_forever.out
I dare you to guess what this does:
./run --eval './posix/sleep_forever.out'
Source: userland/posix/sleep_forever.c
This executable is a convenient simple init that does not panic and sleeps instead.
7.1.3. time_boot.out
Get a reasonable answer to "how long does boot take in guest time?":
./run --eval-after './linux/time_boot.c'
Source: userland/linux/time_boot.c
That executable writes to dmesg directly through /dev/kmsg a message of type:
[ 2.188242] /path/to/linux-kernel-module-cheat/userland/linux/time_boot.c
which tells us that boot took 2.188242 seconds based on the dmesg timestamp.
7.2. Run command at the end of BusyBox init
Use the --eval-after option is for you rely on something that BusyBox' init set up for you like /etc/fstab:
./run --eval-after 'echo asdf;ls /proc;ls /sys;echo qwer'
After the commands run, you are left on an interactive shell.
The above command is basically equivalent to:
./run --kernel-cli-after-dash 'lkmc_eval="insmod hello.ko;./linux/poweroff.out;"'
where the lkmc_eval option gets evaled by our default rootfs_overlay/etc/init.d/S98 startup script.
Except that --eval-after is smarter and uses base64 encoding.
Alternatively, you can also add the comamdns to run to a new init.d entry to run at the end o the BusyBox init:
cp rootfs_overlay/etc/init.d/S98 rootfs_overlay/etc/init.d/S99.gitignore vim rootfs_overlay/etc/init.d/S99.gitignore ./build-buildroot ./run
and they will be run automatically before the login prompt.
Scripts under /etc/init.d are run by /etc/init.d/rcS, which gets called by the line ::sysinit:/etc/init.d/rcS in /etc/inittab.
7.3. Path to init
The init is selected at:
-
initrd or initramfs system:
/init, a custom one can be set with therdinit=kernel command line parameter -
otherwise: default is
/sbin/init, followed by some other paths, a custom one can be set withinit=
The final init that actually got selected is shown on Linux v5.9.2 a line of type:
<6>[ 0.309984] Run /sbin/init as init processat the very end of the boot logs.
7.4. Init environment
The kernel parses parameters from the kernel command line up to "-"; if it doesn’t recognize a parameter and it doesn’t contain a '.', the parameter gets passed to init: parameters with '=' go into init’s environment, others are passed as command line arguments to init. Everything after "-" is passed as an argument to init.
And you can try it out with:
./run --kernel-cli 'init=/lkmc/linux/init_env_poweroff.out' --kernel-cli-after-dash 'asdf=qwer zxcv'
From the generated QEMU command, we see that the kernel CLI at LKMC 69f5745d3df11d5c741551009df86ea6c61a09cf now contains:
init=/lkmc/linux/init_env_poweroff.out console=ttyS0 - lkmc_home=/lkmc asdf=qwer zxcv
and the init program outputs:
args: /lkmc/linux/init_env_poweroff.out - zxcv env: HOME=/ TERM=linux lkmc_home=/lkmc asdf=qwer
Source: userland/linux/init_env_poweroff.c.
As of the Linux kernel v5.7 (possibly earlier, I’ve skipped a few releases), boot also shows the init arguments and environment very clearly, which is a great addition:
<6>[ 0.309984] Run /sbin/init as init process <7>[ 0.309991] with arguments: <7>[ 0.309997] /sbin/init <7>[ 0.310004] nokaslr <7>[ 0.310010] - <7>[ 0.310016] with environment: <7>[ 0.310022] HOME=/ <7>[ 0.310028] TERM=linux <7>[ 0.310035] earlyprintk=pl011,0x1c090000 <7>[ 0.310041] lkmc_home=/lkmc
7.4.1. init arguments
The annoying dash - gets passed as a parameter to init, which makes it impossible to use this method for most non custom executables.
Arguments with dots that come after - are still treated specially (of the form subsystem.somevalue) and disappear, from args, e.g.:
./run --kernel-cli 'init=/lkmc/linux/init_env_poweroff.out' --kernel-cli-after-dash '/lkmc/linux/poweroff.out'
outputs:
args /lkmc/linux/init_env_poweroff.out - ab
so see how a.b is gone.
The simple workaround is to just create a shell script that does it, e.g. as we’ve done at: rootfs_overlay/lkmc/gem5_exit.sh.
7.4.2. init environment env
Wait, where do HOME and TERM come from? (greps the kernel). Ah, OK, the kernel sets those by default: https://github.com/torvalds/linux/blob/94710cac0ef4ee177a63b5227664b38c95bbf703/init/main.c#L173
const char *envp_init[MAX_INIT_ENVS+2] = { "HOME=/", "TERM=linux", NULL, };
7.4.3. BusyBox shell init environment
On top of the Linux kernel, the BusyBox /bin/sh shell will also define other variables.
We can explore the shenanigans that the shell adds on top of the Linux kernel with:
./run --kernel-cli 'init=/bin/sh'
From there we observe that:
env
gives:
SHLVL=1 HOME=/ TERM=linux PWD=/
therefore adding SHLVL and PWD to the default kernel exported variables.
Furthermore, to increase confusion, if you list all non-exported shell variables https://askubuntu.com/questions/275965/how-to-list-all-variables-names-and-their-current-values with:
set
then it shows more variables, notably:
PATH='/sbin:/usr/sbin:/bin:/usr/bin'
7.4.3.1. BusyBox shell initrc files
Login shells source some default files, notably:
/etc/profile $HOME/.profile
In our case, HOME is set to / presumably by init at: https://git.busybox.net/busybox/tree/init/init.c?id=5059653882dbd86e3bbf48389f9f81b0fac8cd0a#n1114
We provide /.profile from rootfs_overlay/.profile, and use the default BusyBox /etc/profile.
The shell knows that it is a login shell if the first character of argv[0] is -, see also: https://stackoverflow.com/questions/2050961/is-argv0-name-of-executable-an-accepted-standard-or-just-a-common-conventi/42291142#42291142
When we use just init=/bin/sh, the Linux kernel sets argv[0] to /bin/sh, which does not start with -.
However, if you use ::respawn:-/bin/sh on inttab described at TTY, BusyBox' init sets argv[0][0] to -, and so does getty. This can be observed with:
cat /proc/$$/cmdline
where $$ is the PID of the shell itself: https://stackoverflow.com/questions/21063765/get-pid-in-shell-bash
8. initrd
The kernel can boot from an CPIO file, which is a directory serialization format much like tar: https://superuser.com/questions/343915/tar-vs-cpio-what-is-the-difference
The bootloader, which for us is provided by QEMU itself, is then configured to put that CPIO into memory, and tell the kernel that it is there.
This is very similar to the kernel image itself, which already gets put into memory by the QEMU -kernel option.
With this setup, you don’t even need to give a root filesystem to the kernel: it just does everything in memory in a ramfs.
To enable initrd instead of the default ext2 disk image, do:
./build-buildroot --initrd ./run --initrd
By looking at the QEMU run command generated, you can see that we didn’t give the -drive option at all:
cat "$(./getvar run_dir)/run.sh"
Instead, we used the QEMU -initrd option to point to the .cpio filesystem that Buildroot generated for us.
Try removing that -initrd option to watch the kernel panic without rootfs at the end of boot.
When using .cpio, there can be no filesystem persistency across boots, since all file operations happen in memory in a tmpfs:
date >f poweroff cat f # can't open 'f': No such file or directory
which can be good for automated tests, as it ensures that you are using a pristine unmodified system image every time.
Not however that we already disable disk persistency by default on ext2 filesystems even without --initrd: Section 23.3, “Disk persistency”.
One downside of this method is that it has to put the entire filesystem into memory, and could lead to a panic:
end Kernel panic - not syncing: Out of memory and no killable processes...
This can be solved by increasing the memory as explained at Memory size:
./run --initrd --memory 256M
The main ingredients to get initrd working are:
-
BR2_TARGET_ROOTFS_CPIO=y: make Buildroot generateimages/rootfs.cpioin addition to the other images.It is also possible to compress that image with other options.
-
qemu -initrd: make QEMU put the image into memory and tell the kernel about it. -
CONFIG_BLK_DEV_INITRD=y: Compile the kernel with initrd support, see also: https://unix.stackexchange.com/questions/67462/linux-kernel-is-not-finding-the-initrd-correctly/424496#424496Buildroot forces that option when
BR2_TARGET_ROOTFS_CPIO=yis given
TODO: how does the bootloader inform the kernel where to find initrd? https://unix.stackexchange.com/questions/89923/how-does-linux-load-the-initrd-image
8.1. initrd in desktop distros
Most modern desktop distributions have an initrd in their root disk to do early setup.
The rationale for this is described at: https://en.wikipedia.org/wiki/Initial_ramdisk
One obvious use case is having an encrypted root filesystem: you keep the initrd in an unencrypted partition, and then setup decryption from there.
I think GRUB then knows read common disk formats, and then loads that initrd to memory with a /boot/grub/grub.cfg directive of type:
initrd /initrd.img-4.4.0-108-generic
8.2. initramfs
initramfs is just like initrd, but you also glue the image directly to the kernel image itself using the kernel’s build system.
Try it out with:
./build-buildroot --initramfs ./build-linux --initramfs ./run --initramfs
Notice how we had to rebuild the Linux kernel this time around as well after Buildroot, since in that build we will be gluing the CPIO to the kernel image.
Now, once again, if we look at the QEMU run command generated, we see all that QEMU needs is the -kernel option, no -drive not even -initrd! Pretty cool:
cat "$(./getvar run_dir)/run.sh"
It is also interesting to observe how this increases the size of the kernel image if you do a:
ls -lh "$(./getvar linux_image)"
before and after using initramfs, since the .cpio is now glued to the kernel image.
Don’t forget that to stop using initramfs, you must rebuild the kernel without --initramfs to get rid of the attached CPIO image:
./build-linux ./run
Alternatively, consider using Linux kernel build variants if you need to switch between initramfs and non initramfs often:
./build-buildroot --initramfs ./build-linux --initramfs --linux-build-id initramfs ./run --initramfs --linux-build-id
Setting up initramfs is very easy: our scripts just set CONFIG_INITRAMFS_SOURCE to point to the CPIO path.
http://nairobi-embedded.org/initramfs_tutorial.html shows a full manual setup.
8.3. rootfs
This is how /proc/mounts shows the root filesystem:
-
hard disk:
/dev/root on / type ext2 (rw,relatime,block_validity,barrier,user_xattr). That file does not exist however. -
initrd:
rootfs on / type rootfs (rw) -
initramfs:
rootfs on / type rootfs (rw)
TODO: understand /dev/root better:
8.4. gem5 initrd
TODO we were not able to get it working yet: https://stackoverflow.com/questions/49261801/how-to-boot-the-linux-kernel-with-initrd-or-initramfs-with-gem5
This would require gem5 to load the CPIO into memory, just like QEMU. Grepping initrd shows some ARM hits under:
src/arch/arm/linux/atag.hh
but they are commented out.
8.5. gem5 initramfs
This could in theory be easier to make work than initrd since the emulator does not have to do anything special.
However, it didn’t: boot fails at the end because it does not see the initramfs, but rather tries to open our dummy root filesystem, which unsurprisingly does not have a format in a way that the kernel understands:
VFS: Cannot open root device "sda" or unknown-block(8,0): error -5
We think that this might be because gem5 boots directly vmlinux, and not from the final compressed images that contain the attached rootfs such as bzImage, which is what QEMU does, see also: Section 17.20.1, “vmlinux vs bzImage vs zImage vs Image”.
To do this failed test, we automatically pass a dummy disk image as of gem5 7fa4c946386e7207ad5859e8ade0bbfc14000d91 since the scripts don’t handle a missing --disk-image well, much like is currently done for Baremetal.
Interestingly, using initramfs significantly slows down the gem5 boot, even though it did not work. For example, we’ve observed a 4x slowdown of as 17062a2e8b6e7888a14c3506e9415989362c58bf for aarch64. This must be because expanding the large attached CPIO must be expensive. We can clearly see from the kernel logs that the kernel just hangs at a point after the message PCI: CLS 0 bytes, default 64 for a long time before proceeding further.
9. Device tree
The device tree is a Linux kernel defined data structure that serves to inform the kernel how the hardware is setup.
Device trees serve to reduce the need for hardware vendors to patch the kernel: they just provide a device tree file instead, which is much simpler.
x86 does not use it device trees, but many other archs to, notably ARM.
This is notably because ARM boards:
-
typically don’t have discoverable hardware extensions like PCI, but rather just put everything on an SoC with magic register addresses
-
are made by a wide variety of vendors due to ARM’s licensing business model, which increases variability
The Linux kernel itself has several device trees under ./arch/<arch>/boot/dts, see also: https://stackoverflow.com/questions/21670967/how-to-compile-dts-linux-device-tree-source-files-to-dtb/42839737#42839737
9.1. DTB files
Files that contain device trees have the .dtb extension when compiled, and .dts when in text form.
You can convert between those formats with:
"$(./getvar buildroot_host_dir)"/bin/dtc -I dtb -O dts -o a.dts a.dtb "$(./getvar buildroot_host_dir)"/bin/dtc -I dts -O dtb -o a.dtb a.dts
Buildroot builds the tool due to BR2_PACKAGE_HOST_DTC=y.
On Ubuntu 18.04, the package is named:
sudo apt-get install device-tree-compiler
Device tree files are provided to the emulator just like the root filesystem and the Linux kernel image.
In real hardware, those components are also often provided separately. For example, on the Raspberry Pi 2, the SD card must contain two partitions:
-
the first contains all magic files, including the Linux kernel and the device tree
-
the second contains the root filesystem
9.2. Device tree syntax
Good format descriptions:
Minimal example
/dts-v1/;
/ {
a;
};
Check correctness with:
dtc a.dts
Separate nodes are simply merged by node path, e.g.:
/dts-v1/;
/ {
a;
};
/ {
b;
};
then dtc a.dts gives:
/dts-v1/;
/ {
a;
b;
};
9.3. Get device tree from a running kernel
This is specially interesting because QEMU and gem5 are capable of generating DTBs that match the selected machine depending on dynamic command line parameters for some types of machines.
So observing the device tree from the guest allows to easily see what the emulator has generated.
Compile the dtc tool into the root filesystem:
./build-buildroot \ --arch aarch64 \ --config 'BR2_PACKAGE_DTC=y' \ --config 'BR2_PACKAGE_DTC_PROGRAMS=y' \ ;
-M virt for example, which we use by default for aarch64, boots just fine without the -dtb option:
./run --arch aarch64
Then, from inside the guest:
dtc -I fs -O dts /sys/firmware/devicetree/base
contains:
cpus {
#address-cells = <0x1>;
#size-cells = <0x0>;
cpu@0 {
compatible = "arm,cortex-a57";
device_type = "cpu";
reg = <0x0>;
};
};
9.4. Device tree emulator generation
Since emulators know everything about the hardware, they can automatically generate device trees for us, which is very convenient.
This is the case for both QEMU and gem5.
For example, if we increase the number of cores to 2:
./run --arch aarch64 --cpus 2
QEMU automatically adds a second CPU to the DTB!
cpu@0 {
cpu@1 {
The action seems to be happening at: hw/arm/virt.c.
You can dump the DTB QEMU generated with:
./run --arch aarch64 -- -machine dumpdtb=dtb.dtb
gem5 fs_bigLITTLE 2a9573f5942b5416fb0570cf5cb6cdecba733392 can also generate its own DTB.
gem5 can generate DTBs on ARM with --generate-dtb. The generated DTB is placed in the m5out directory named as system.dtb.
10. KVM
KVM is Linux kernel interface that greatly speeds up execution of virtual machines.
You can make QEMU or gem5 by passing enabling KVM with:
./run --kvm
KVM works by running userland instructions natively directly on the real hardware instead of running a software simulation of those instructions.
Therefore, KVM only works if you the host architecture is the same as the guest architecture. This means that this will likely only work for x86 guests since almost all development machines are x86 nowadays. Unless you are running an ARM desktop for some weird reason :-)
We don’t enable KVM by default because:
-
it limits visibility, since more things are running natively:
-
can’t use GDB
-
can’t do instruction tracing
-
on gem5, you lose cycle counts and therefor any notion of performance
-
-
QEMU kernel boots are already fast enough for most purposes without it
One important use case for KVM is to fast forward gem5 execution, often to skip boot, take a gem5 checkpoint, and then move on to a more detailed and slow simulation
10.1. KVM arm
TODO: we haven’t gotten it to work yet, but it should be doable, and this is an outline of how to do it. Just don’t expect this to tested very often for now.
We can test KVM on arm by running this repository inside an Ubuntu arm QEMU VM.
This produces no speedup of course, since the VM is already slow since it cannot use KVM on the x86 host.
First, obtain an Ubuntu arm64 virtual machine as explained at: https://askubuntu.com/questions/281763/is-there-any-prebuilt-qemu-ubuntu-image32bit-online/1081171#1081171
Then, from inside that image:
sudo apt-get install git git clone https://github.com/cirosantilli/linux-kernel-module-cheat cd linux-kernel-module-cheat python3 -m venv .venv . .venv/bin/activate ./setup -y
and then proceed exactly as in Prebuilt setup.
We don’t want to build the full Buildroot image inside the VM as that would be way too slow, thus the recommendation for the prebuilt setup.
TODO: do the right thing and cross compile QEMU and gem5. gem5’s Python parts might be a pain. QEMU should be easy: https://stackoverflow.com/questions/26514252/cross-compile-qemu-for-arm
10.2. gem5 KVM
While gem5 does have KVM, as of 2019 its support has not been very good, because debugging it is harder and people haven’t focused intensively on it.
X86 was broken with pending patches: https://www.mail-archive.com/gem5-users@gem5.org/msg15046.html It failed immediately on:
panic: KVM: Failed to enter virtualized mode (hw reason: 0x80000021)
also mentioned at:
Bibliography:
11. User mode simulation
Both QEMU and gem5 have an user mode simulation mode in addition to full system simulation that we consider elsewhere in this project.
In QEMU, it is called just "user mode", and in gem5 it is called syscall emulation mode.
In both, the basic idea is the same.
User mode simulation takes regular userland executables of any arch as input and executes them directly, without booting a kernel.
Instead of simulating the full system, it translates normal instructions like in full system mode, but magically forwards system calls to the host OS.
Advantages over full system simulation:
-
the simulation may run faster since you don’t have to simulate the Linux kernel and several device models
-
you don’t need to build your own kernel or root filesystem, which saves time. You still need a toolchain however, but the pre-packaged ones may work fine.
Disadvantages:
-
lower guest to host portability:
-
TODO confirm: host OS == guest OS?
-
TODO confirm: the host Linux kernel should be newer than the kernel the executable was built for.
It may still work even if that is not the case, but could fail is a missing system call is reached.
The target Linux kernel of the executable is a GCC toolchain build-time configuration.
-
emulator implementers have to keep up with libc changes, some of which break even a C hello world due setup code executed before main.
-
-
cannot be used to test the Linux kernel or any devices, and results are less representative of a real system since we are faking more
11.1. QEMU user mode getting started
Let’s run userland/c/command_line_arguments.c built with the Buildroot toolchain on QEMU user mode:
./build user-mode-qemu ./run \ --userland userland/c/command_line_arguments.c \ --cli-args='asdf "qw er"' \ ;
Output:
/path/to/linux-kernel-module-cheat/out/userland/default/x86_64/c/command_line_arguments.out asdf qw er
./run --userland path resolution is analogous to that of ./run --baremetal.
./build user-mode-qemu first builds Buildroot, and then runs ./build-userland, which is further documented at: Section 2.8, “Userland setup”. It also builds QEMU. If you ahve already done a QEMU Buildroot setup previously, this will be very fast.
If you modify the userland programs, rebuild simply with:
./build-userland
To rebuild just QEMU userland if you hack it, use:
./build-qemu --mode userland
The:
--mode userland
is needed because QEMU has two separate executables:
-
qemu-x86_64for userland -
qemu-system-x86_64for full system
11.1.1. User mode GDB
It’s nice when the obvious just works, right?
./run \ --arch aarch64 \ --gdb-wait \ --userland userland/c/command_line_arguments.c \ --cli-args 'asdf "qw er"' \ ;
and on another shell:
./run-gdb \ --arch aarch64 \ --userland userland/c/command_line_arguments.c \ main \ ;
Or alternatively, if you are using tmux, do everything in one go with:
./run \ --arch aarch64 \ --gdb \ --userland userland/c/command_line_arguments.c \ --cli-args 'asdf "qw er"' \ ;
To stop at the very first instruction of a freestanding program, just use --no-continue. A good example of this is shown at: Section 28.5.1, “Freestanding programs”.
11.2. User mode tests
Automatically run all userland tests that can be run in user mode simulation, and check that they exit with status 0:
./build --all-archs test-executables-userland ./test-executables --all-archs --all-emulators
Or just for QEMU:
./build --all-archs test-executables-userland-qemu ./test-executables --all-archs --emulator qemu
Source: test-executables
This script skips a manually configured list of tests, notably:
-
tests that depend on a full running kernel and cannot be run in user mode simulation, e.g. those that rely on kernel modules
-
tests that require user interaction
-
tests that take perceptible amounts of time
-
known bugs we didn’t have time to fix ;-)
Tests under userland/libs/ are only run if --package or --package-all are given as described at userland/libs directory.
The gem5 tests require building statically with build id static, see also: Section 11.7, “gem5 syscall emulation mode”. TODO automate this better.
See: Section 38.16, “Test this repo” for more useful testing tips.
11.3. User mode Buildroot executables
If you followed QEMU Buildroot setup, you can now run the executables created by Buildroot directly as:
./run \ --userland "$(./getvar buildroot_target_dir)/bin/echo" \ --cli-args='asdf' \ ;
To easily explore the userland executable environment interactively, you can do:
./run \ --arch aarch64 \ --userland "$(./getvar --arch aarch64 buildroot_target_dir)/bin/sh" \ --terminal \ ;
or:
./run \ --arch aarch64 \ --userland "$(./getvar --arch aarch64 buildroot_target_dir)/bin/sh" \ --cli-args='-c "uname -a && pwd"' \ ;
Here is an interesting examples of this: Section 17.19.1, “Linux Test Project”
11.4. User mode simulation with glibc
At 125d14805f769104f93c510bedaa685a52ec025d we moved Buildroot from uClibc to glibc, and caused some user mode pain, which we document here.
11.4.1. FATAL: kernel too old failure in userland simulation
glibc has a check for kernel version, likely obtained from the uname syscall, and if the kernel is not new enough, it quits.
Both gem5 and QEMU however allow setting the reported uname version from the command line for User mode simulation, which we do to always match our toolchain.
QEMU by default copies the host uname value, but we always override it in our scripts.
Determining the right number to use for the kernel version is of course highly non-trivial and would require an extensive userland test suite, which most emulators don’t have.
./run --arch aarch64 --kernel-version 4.18 --userland userland/posix/uname.c
Source: userland/posix/uname.c.
The QEMU source that does this is at: https://github.com/qemu/qemu/blob/v3.1.0/linux-user/syscall.c#L8931 The default ID is just hardcoded on the source.
Bibliography:
11.4.2. stack smashing detected when using glibc
For some reason QEMU / glibc x86_64 picks up the host libc, which breaks things.
Other archs work as they different host libc is skipped. User mode static executables also work.
We have worked around this with with https://bugs.launchpad.net/qemu/+bug/1701798/comments/12 from the thread: https://bugs.launchpad.net/qemu/+bug/1701798 by creating the file: rootfs_overlay/etc/ld.so.cache which is a symlink to a file that cannot exist: /dev/null/nonexistent.
Reproduction:
rm -f "$(./getvar buildroot_target_dir)/etc/ld.so.cache" ./run --userland userland/c/hello.c ./run --userland userland/c/hello.c --qemu-which host
Outcome:
*** stack smashing detected ***: <unknown> terminated qemu: uncaught target signal 6 (Aborted) - core dumped
To get things working again, restore ld.so.cache with:
./build-buildroot
I’ve also tested on an Ubuntu 16.04 guest and the failure is different one:
qemu: uncaught target signal 4 (Illegal instruction) - core dumped
A non-QEMU-specific example of stack smashing is shown at: https://stackoverflow.com/questions/1345670/stack-smashing-detected/51897264#51897264
Tested at: 2e32389ebf1bedd89c682aa7b8fe42c3c0cf96e5 + 1.
11.5. User mode static executables
Example:
./build-userland \ --arch aarch64 \ --static \ ; ./run \ --arch aarch64 \ --static \ --userland userland/c/command_line_arguments.c \ --cli-args 'asdf "qw er"' \ ;
Running dynamically linked executables in QEMU requires pointing it to the root filesystem with the -L option so that it can find the dynamic linker and shared libraries, see also:
We pass -L by default, so everything just works.
However, in case something goes wrong, you can also try statically linked executables, since this mechanism tends to be a bit more stable, for example:
-
QEMU x86_64 guest on x86_64 host was failing with stack smashing detected when using glibc, but we found a workaround
-
gem5 user only supported static executables in the past, as mentioned at: Section 11.7, “gem5 syscall emulation mode”
Running statically linked executables sometimes makes things break:
-
TODO understand why:
./run --static --userland userland/c/file_write_read.c
fails our assertion that the data was read back correctly:
Assertion `strcmp(data, output) == 0' faile
11.5.1. User mode static executables with dynamic libraries
One limitation of static executables is that Buildroot mostly only builds dynamic versions of libraries (the libc is an exception).
So programs that rely on those libraries might not compile as GCC can’t find the .a version of the library.
For example, if we try to build BLAS statically:
./build-userland --package openblas --static -- userland/libs/openblas/hello.c
it fails with:
ld: cannot find -lopenblas
11.5.1.1. C++ static and pthreads
g++ and pthreads also causes issues:
As a consequence, the following just hangs as of LKMC ca0403849e03844a328029d70c08556155dc1cd0 + 1 the example userland/cpp/atomic/std_atomic.cpp:
./run --userland userland/cpp/atomic/std_atomic.cpp --static
And before that, it used to fail with other randomly different errors, e.g.:
qemu-x86_64: /path/to/linux-kernel-module-cheat/submodules/qemu/accel/tcg/cpu-exec.c:700: cpu_exec: Assertion `!have_mmap_lock()' failed. qemu-x86_64: /path/to/linux-kernel-module-cheat/submodules/qemu/accel/tcg/cpu-exec.c:700: cpu_exec: Assertion `!have_mmap_lock()' failed.
And a native Ubuntu 18.04 AMD64 run with static compilation segfaults.
As of LKMC f5d4998ff51a548ed3f5153aacb0411d22022058 the aarch64 error:
./run --arch aarch64 --userland userland/cpp/atomic/fail.cpp --static
is:
terminate called after throwing an instance of 'std::system_error' what(): Unknown error 16781344 qemu: uncaught target signal 6 (Aborted) - core dumped
The workaround:
-pthread -Wl,--whole-archive -lpthread -Wl,--no-whole-archive
fixes some of the problems, but not all TODO which were missing?, so we are just skipping those tests for now.
11.6. syscall emulation mode program stdin
The following work on both QEMU and gem5 as of LKMC 99d6bc6bc19d4c7f62b172643be95d9c43c26145 + 1. Interactive input:
./run --userland userland/c/getchar.c
Source: userland/c/getchar.c
A line of type should show:
enter a character:
and after pressing say a and Enter, we get:
you entered: a
Note however that due to QEMU user mode does not show stdout immediately we don’t really see the initial enter a character line.
Non-interactive input from a file by forwarding emulators stdin implicitly through our Python scripts:
printf a > f.tmp ./run --userland userland/c/getchar.c < f.tmp
Input from a file by explicitly requesting our scripts to use it via the Python API:
printf a > f.tmp ./run --emulator gem5 --userland userland/c/getchar.c --stdin-file f.tmp
This is especially useful when running tests that require stdin input.
11.7. gem5 syscall emulation mode
Less robust than QEMU’s, but still usable:
There are much more unimplemented syscalls in gem5 than in QEMU. Many of those are trivial to implement however.
So let’s just play with some static ones:
./build-userland --arch aarch64 ./run \ --arch aarch64 \ --emulator gem5 \ --userland userland/c/command_line_arguments.c \ --cli-args 'asdf "qw er"' \ ;
TODO: how to escape spaces on the command line arguments?
GDB step debug also works normally on gem5:
./run \ --arch aarch64 \ --emulator gem5 \ --gdb-wait \ --userland userland/c/command_line_arguments.c \ --cli-args 'asdf "qw er"' \ ; ./run-gdb \ --arch aarch64 \ --emulator gem5 \ --userland userland/c/command_line_arguments.c \ main \ ;
11.7.1. gem5 dynamic linked executables in syscall emulation
Support for dynamic linking was added in November 2019:
Note that as shown at Section 35.2.2, “Benchmark emulators on userland executables”, the dynamic version runs 200x more instructions, which might have an impact on smaller simulations in detailed CPUs.
11.7.2. gem5 syscall emulation exit status
As of gem5 7fa4c946386e7207ad5859e8ade0bbfc14000d91, the crappy se.py script does not forward the exit status of syscall emulation mode, you can test it with:
./run --dry-run --emulator gem5 --userland userland/c/false.c
Source: userland/c/false.c.
Then manually run the generated gem5 CLI, and do:
echo $?
and the output is always 0.
Instead, it just outputs a message to stdout just like for m5 fail:
Simulated exit code not 0! Exit code is 1
which we parse in run and then exit with the correct result ourselves…
11.7.3. gem5 syscall emulation mode syscall tracing
Since gem5 has to implement syscalls itself in syscall emulation mode, it can of course clearly see which syscalls are being made, and we can log them for debug purposes with gem5 tracing, e.g.:
./run \ --emulator gem5 \ --userland userland/arch/x86_64/freestanding/linux/hello.S \ --trace-stdout \ --trace ExecAll,SyscallBase,SyscallVerbose \ ;
the trace as of f2eeceb1cde13a5ff740727526bf916b356cee38 + 1 contains:
0: system.cpu A0 T0 : @asm_main_after_prologue : mov rdi, 0x1
0: system.cpu A0 T0 : @asm_main_after_prologue.0 : MOV_R_I : limm rax, 0x1 : IntAlu : D=0x0000000000000001 flags=(IsInteger|IsMicroop|IsLastMicroop|IsFirstMicroop)
1000: system.cpu A0 T0 : @asm_main_after_prologue+7 : mov rdi, 0x1
1000: system.cpu A0 T0 : @asm_main_after_prologue+7.0 : MOV_R_I : limm rdi, 0x1 : IntAlu : D=0x0000000000000001 flags=(IsInteger|IsMicroop|IsLastMicroop|IsFirstMicroop)
2000: system.cpu A0 T0 : @asm_main_after_prologue+14 : lea rsi, DS:[rip + 0x19]
2000: system.cpu A0 T0 : @asm_main_after_prologue+14.0 : LEA_R_P : rdip t7, %ctrl153, : IntAlu : D=0x000000000040008d flags=(IsInteger|IsMicroop|IsDelayedCommit|IsFirstMicroop)
2500: system.cpu A0 T0 : @asm_main_after_prologue+14.1 : LEA_R_P : lea rsi, DS:[t7 + 0x19] : IntAlu : D=0x00000000004000a6 flags=(IsInteger|IsMicroop|IsLastMicroop)
3500: system.cpu A0 T0 : @asm_main_after_prologue+21 : mov rdi, 0x6
3500: system.cpu A0 T0 : @asm_main_after_prologue+21.0 : MOV_R_I : limm rdx, 0x6 : IntAlu : D=0x0000000000000006 flags=(IsInteger|IsMicroop|IsLastMicroop|IsFirstMicroop)
4000: system.cpu: T0 : syscall write called w/arguments 1, 4194470, 6, 0, 0, 0
hello
4000: system.cpu: T0 : syscall write returns 6
4000: system.cpu A0 T0 : @asm_main_after_prologue+28 : syscall eax : IntAlu : flags=(IsInteger|IsSerializeAfter|IsNonSpeculative|IsSyscall)
5000: system.cpu A0 T0 : @asm_main_after_prologue+30 : mov rdi, 0x3c
5000: system.cpu A0 T0 : @asm_main_after_prologue+30.0 : MOV_R_I : limm rax, 0x3c : IntAlu : D=0x000000000000003c flags=(IsInteger|IsMicroop|IsLastMicroop|IsFirstMicroop)
6000: system.cpu A0 T0 : @asm_main_after_prologue+37 : mov rdi, 0
6000: system.cpu A0 T0 : @asm_main_after_prologue+37.0 : MOV_R_I : limm rdi, 0 : IntAlu : D=0x0000000000000000 flags=(IsInteger|IsMicroop|IsLastMicroop|IsFirstMicroop)
6500: system.cpu: T0 : syscall exit called w/arguments 0, 4194470, 6, 0, 0, 0
6500: system.cpu: T0 : syscall exit returns 0
6500: system.cpu A0 T0 : @asm_main_after_prologue+44 : syscall eax : IntAlu : flags=(IsInteger|IsSerializeAfter|IsNonSpeculative|IsSyscall)
so we see that two syscall lines were added for each syscall, showing the syscall inputs and exit status, just like a mini strace!
11.7.4. gem5 syscall emulation multithreading
gem5 user mode multithreading has been particularly flaky compared to QEMU’s, but work is being put into improving it.
In gem5 syscall simulation, the fork syscall checks if there is a free CPU, and if there is a free one, the new threads runs on that CPU.
Otherwise, the fork call, and therefore higher level interfaces to fork such as pthread_create also fail and return a failure return status in the guest.
For example, if we use just one CPU for userland/posix/pthread_self.c which spawns one thread besides main:
./run --cpus 1 --emulator gem5 --userland userland/posix/pthread_self.c --cli-args 1
fails with this error message coming from the guest stderr:
pthread_create: Resource temporarily unavailable
It works however if we add on extra CPU:
./run --cpus 2 --emulator gem5 --userland userland/posix/pthread_self.c --cli-args 1
Once threads exit, their CPU is freed and becomes available for new fork calls: For example, the following run spawns a thread, joins it, and then spawns again, and 2 CPUs are enough:
./run --cpus 2 --emulator gem5 --userland userland/posix/pthread_self.c --cli-args '1 2'
because at each point in time, only up to two threads are running.
gem5 syscall emulation does show the expected number of cores when queried, e.g.:
./run --cpus 1 --userland userland/cpp/thread_hardware_concurrency.cpp --emulator gem5 ./run --cpus 2 --userland userland/cpp/thread_hardware_concurrency.cpp --emulator gem5
outputs 1 and 2 respectively.
This can also be clearly by running sched_getcpu:
./run \ --arch aarch64 \ --cli-args 4 \ --cpus 8 \ --emulator gem5 \ --userland userland/linux/sched_getcpu.c \ ;
which necessarily produces an output containing the CPU numbers from 1 to 4 and no higher:
1 3 4 2
TODO why does the 2 come at the end here? Would be good to do a detailed assembly run analysis.
11.7.5. gem5 syscall emulation multiple executables
gem5 syscall emulation has the nice feature of allowing you to run multiple executables "at once".
Each executable starts running on the next free core much as if it had been forked right at the start of simulation: gem5 syscall emulation multithreading.
This can be useful to quickly create deterministic multi-CPU workload.
se.py --cmd takes a semicolon separated list, so we could do which LKMC exposes this by taking --userland multiple times as in:
./run \ --arch aarch64 \ --cpus 2 \ --emulator gem5 \ --userland userland/posix/getpid.c \ --userland userland/posix/getpid.c \ ;
We need at least one CPU per executable, just like when forking new processes.
The outcome of this is that we see two different pid messages printed to stdout:
pid=101 pid=100
since from gem5 Process we can see that se.py sets up one different PID per executable starting at 100:
workloads = options.cmd.split(';')
idx = 0
for wrkld in workloads:
process = Process(pid = 100 + idx)
We can also see that these processes are running concurrently with gem5 tracing by hacking:
--debug-flags ExecAll \ --debug-file cout \
which starts with:
0: system.cpu1: A0 T0 : @__end__+274873647040 : add x0, sp, #0 : IntAlu : D=0x0000007ffffefde0 flags=(IsInteger)
0: system.cpu0: A0 T0 : @__end__+274873647040 : add x0, sp, #0 : IntAlu : D=0x0000007ffffefde0 flags=(IsInteger)
500: system.cpu0: A0 T0 : @__end__+274873647044 : bl <__end__+274873649648> : IntAlu : D=0x0000004000001008 flags=(IsInteger|IsControl|IsDirectControl|IsUncondControl|IsCall)
500: system.cpu1: A0 T0 : @__end__+274873647044 : bl <__end__+274873649648> : IntAlu : D=0x0000004000001008 flags=(IsInteger|IsControl|IsDirectControl|IsUncondControl|IsCall)
and therefore shows one instruction running on each CPU for each process at the same time.
11.7.5.1. gem5 syscall emulation --smt
gem5 b1623cb2087873f64197e503ab8894b5e4d4c7b4 syscall emulation has an --smt option presumably for Hardware threads but it has been neglected forever it seems: https://github.com/cirosantilli/linux-kernel-module-cheat/issues/104
If we start from the manually hacked working command from gem5 syscall emulation multiple executables and try to add:
--cpu 1 --cpu-type Derivo3CPU --caches
We choose DerivO3CPU because of the se.py assert:
example/se.py:115: assert(options.cpu_type == "DerivO3CPU")
But then that fails with:
gem5.opt: /path/to/linux-kernel-module-cheat/out/gem5/master3/build/ARM/cpu/o3/cpu.cc:205: FullO3CPU<Impl>::FullO3CPU(DerivO3CPUParams*) [with Impl = O3CPUImpl]: Assertion `params->numPhysVecPredRegs >= numThreads * TheISA::NumVecPredRegs' failed. Program aborted at tick 0
11.8. QEMU user mode quirks
11.8.1. QEMU user mode does not show stdout immediately
At 8d8307ac0710164701f6e14c99a69ee172ccbb70 + 1, I noticed that if you run userland/posix/count.c:
./run --userland userland/posix/count_to.c --cli-args 3
it first waits for 3 seconds, then the program exits, and then it dumps all the stdout at once, instead of counting once every second as expected.
The same can be reproduced by copying the raw QEMU command and piping it through tee, so I don’t think it is a bug in our setup:
/path/to/linux-kernel-module-cheat/out/qemu/default/x86_64-linux-user/qemu-x86_64 \ -L /path/to/linux-kernel-module-cheat/out/buildroot/build/default/x86_64/target \ /path/to/linux-kernel-module-cheat/out/userland/default/x86_64/posix/count.out \ 3 \ | tee
TODO: investigate further and then possibly post on QEMU mailing list.
11.8.1.1. QEMU user mode does not show errors
Similarly to QEMU user mode does not show stdout immediately, QEMU error messages do not show at all through pipes.
In particular, it does not say anything if you pass it a non-existing executable:
qemu-x86_64 asdf | cat
So we just check ourselves manually
12. Kernel module utilities
12.2. myinsmod
If you are feeling raw, you can insert and remove modules with our own minimal module inserter and remover!
# init_module ./linux/myinsmod.out hello.ko # finit_module ./linux/myinsmod.out hello.ko "" 1 ./linux/myrmmod.out hello
which teaches you how it is done from C code.
Source:
The Linux kernel offers two system calls for module insertion:
-
init_module -
finit_module
and:
man init_module
documents that:
The finit_module() system call is like init_module(), but reads the module to be loaded from the file descriptor fd. It is useful when the authenticity of a kernel module can be determined from its location in the filesystem; in cases where that is possible, the overhead of using cryptographically signed modules to determine the authenticity of a module can be avoided. The param_values argument is as for init_module().
finit is newer and was added only in v3.8. More rationale: https://lwn.net/Articles/519010/
12.3. modprobe
Implemented as a BusyBox applet by default: https://git.busybox.net/busybox/tree/modutils/modprobe.c?h=1_29_stable
modprobe searches for modules installed under:
ls /lib/modules/<kernel_version>
and specified in the modules.order file.
This is the default install path for CONFIG_SOME_MOD=m modules built with make modules_install in the Linux kernel tree, with root path given by INSTALL_MOD_PATH, and therefore canonical in that sense.
Currently, there are only two kinds of kernel modules that you can try out with modprobe:
-
modules built with Buildroot, see: Section 38.15.2.1, “kernel_modules buildroot package”
-
modules built from the kernel tree itself, see: Section 17.11.2, “dummy-irq”
We are not installing out custom ./build-modules modules there, because:
-
we don’t know the right way. Why is there no
installorinstall_modulestarget for kernel modules?This can of course be solved by running Buildroot in verbose mode, and copying whatever it is doing, initial exploration at: https://stackoverflow.com/questions/22783793/how-to-install-kernel-modules-from-source-code-error-while-make-process/53169078#53169078
-
we would have to think how to not have to include the kernel modules twice in the root filesystem, but still have 9P working for fast development as described at: Section 2.2.2.2, “Your first kernel module hack”
12.4. kmod
The more "reference" kernel.org implementation of lsmod, insmod, rmmod, etc.: https://git.kernel.org/pub/scm/utils/kernel/kmod/kmod.git
Default implementation on desktop distros such as Ubuntu 16.04, where e.g.:
ls -l /bin/lsmod
gives:
lrwxrwxrwx 1 root root 4 Jul 25 15:35 /bin/lsmod -> kmod
and:
dpkg -l | grep -Ei
contains:
ii kmod 22-1ubuntu5 amd64 tools for managing Linux kernel modules
BusyBox also implements its own version of those executables, see e.g. modprobe. Here we will only describe features that differ from kmod to the BusyBox implementation.
12.4.1. module-init-tools
Name of a predecessor set of tools.
12.4.2. kmod modprobe
kmod’s modprobe can also load modules under different names to avoid conflicts, e.g.:
sudo modprobe vmhgfs -o vm_hgfs
13. Filesystems
13.1. OverlayFS
OverlayFS is a filesystem merged in the Linux kernel in 3.18.
As the name suggests, OverlayFS allows you to merge multiple directories into one. The following minimal runnable examples should give you an intuition on how it works:
We are very interested in this filesystem because we are looking for a way to make host cross compiled executables appear on the guest root / without reboot.
This would have several advantages:
-
makes it faster to test modified guest programs
-
not rebooting is fundamental for gem5, where the reboot is very costly.
-
no need to regenerate the root filesystem at all and reboot
-
overcomes the
check_bin_archproblem as shown at: Section 26.8, “Buildroot rebuild is slow when the root filesystem is large”
-
-
we could keep the base root filesystem very small, which implies:
-
less host disk usage, no need to copy the entire
./getvar out_rootfs_overlay_dirto the image again -
no need to worry about BR2_TARGET_ROOTFS_EXT2_SIZE
-
We can already make host files appear on the guest with 9P, but they appear on a subdirectory instead of the root.
If they would appear on the root instead, that would be even more awesome, because you would just use the exact same paths relative to the root transparently.
For example, we wouldn’t have to mess around with variables such as PATH and LD_LIBRARY_PATH.
The idea is to:
-
9P mount our overlay directory
./getvar out_rootfs_overlay_diron the guest, which we already do at/mnt/9p/out_rootfs_overlay -
then create an overlay with that directory and the root, and
chrootinto it.I was unable to mount directly to
/avoid thechroot: https://stackoverflow.com/questions/41119656/how-can-i-overlayfs-the-root-filesystem-on-linux https://unix.stackexchange.com/questions/316018/how-to-use-overlayfs-to-protect-the-root-filesystem ** https://unix.stackexchange.com/questions/420646/mount-root-as-overlayfs
We already have a prototype of this running from fstab on guest at /mnt/overlay, but it has the following shortcomings:
-
changes to underlying filesystems are not visible on the overlay unless you remount with
mount -r remount /mnt/overlay, as mentioned on the kernel docs:Changes to the underlying filesystems while part of a mounted overlay filesystem are not allowed. If the underlying filesystem is changed, the behavior of the overlay is undefined, though it will not result in a crash or deadlock.
This makes everything very inconvenient if you are inside
chrootaction. You would have to leavechroot, remount, then come back. -
the overlay does not contain sub-filesystems, e.g.
/proc. We would have to re-mount them. But should be doable with some automation.
Even more awesome than chroot would be to pivot_root, but I couldn’t get that working either:
13.2. Secondary disk
A simpler and possibly less overhead alternative to 9P would be to generate a secondary disk image with the benchmark you want to rebuild.
Then you can umount and re-mount on guest without reboot.
To build the secondary disk image run build-disk2:
./build-disk2
This will put the entire out_rootfs_overlay_dir into a squashfs filesystem.
Then, if that filesystem is present, ./run will automatically pass it as the second disk on the command line.
For example, from inside QEMU, you can mount that disk with:
mkdir /mnt/vdb mount /dev/vdb /mnt/vdb /mnt/vdb/lkmc/c/hello.out
To update the secondary disk while a simulation is running to avoid rebooting, first unmount in the guest:
umount /mnt/vdb
and then on the host:
# Edit the file. vim userland/c/hello.c ./build-userland ./build-disk2
and now you can re-run the updated version of the executable on the guest after remounting it.
gem5 fs.py support for multiple disks is discussed at: https://stackoverflow.com/questions/50862906/how-to-attach-multiple-disk-images-in-a-simulation-with-gem5-fs-py/51037661#51037661
14. Graphics
Both QEMU and gem5 are capable of outputting graphics to the screen, and taking mouse and keyboard input.
14.1. QEMU text mode
Text mode is the default mode for QEMU.
The opposite of text mode is QEMU graphic mode
In text mode, we just show the serial console directly on the current terminal, without opening a QEMU GUI window.
You cannot see any graphics from text mode, but text operations in this mode, including:
-
scrolling up: Section 14.2.1, “Scroll up in graphic mode”
-
copy paste to and from the terminal
making this a good default, unless you really need to use with graphics.
Text mode works by sending the terminal character by character to a serial device.
This is different from a display screen, where each character is a bunch of pixels, and it would be much harder to convert that into actual terminal text.
For more details, see:
Note that you can still see an image even in text mode with the VNC:
./run --vnc
and on another terminal:
./vnc
but there is not terminal on the VNC window, just the CONFIG_LOGO penguin.
14.1.1. Quit QEMU from text mode
However, our QEMU setup captures Ctrl + C and other common signals and sends them to the guest, which makes it hard to quit QEMU for the first time since there is no GUI either.
The simplest way to quit QEMU, is to do:
Ctrl-A X
Alternative methods include:
-
quitcommand on the QEMU monitor -
pkill qemu
14.2. QEMU graphic mode
Enable graphic mode with:
./run --graphic
Outcome: you see a penguin due to CONFIG_LOGO.
For a more exciting GUI experience, see: Section 14.4, “X11 Buildroot”
Text mode is the default due to the following considerable advantages:
-
copy and paste commands and stdout output to / from host
-
get full panic traces when you start making the kernel crash :-) See also: https://unix.stackexchange.com/questions/208260/how-to-scroll-up-after-a-kernel-panic
-
have a large scroll buffer, and be able to search it, e.g. by using tmux on host
-
one less window floating around to think about in addition to your shell :-)
-
graphics mode has only been properly tested on
x86_64.
Text mode has the following limitations over graphics mode:
-
you can’t see graphics such as those produced by X11 Buildroot
-
very early kernel messages such as
early console in extract_kernelonly show on the GUI, since at such early stages, not even the serial has been setup.
x86_64 has a VGA device enabled by default, as can be seen as:
./qemu-monitor info qtree
and the Linux kernel picks it up through the fbdev graphics system as can be seen from:
cat /dev/urandom > /dev/fb0
flooding the screen with colors. See also: https://superuser.com/questions/223094/how-do-i-know-if-i-have-kms-enabled
14.2.1. Scroll up in graphic mode
Scroll up in QEMU graphic mode:
Shift-PgUp
but I never managed to increase that buffer:
The superior alternative is to use text mode and GNU screen or tmux.
14.2.2. QEMU Graphic mode arm
14.2.2.1. QEMU graphic mode arm terminal
TODO: on arm, we see the penguin and some boot messages, but don’t get a shell at then end:
./run --arch aarch64 --graphic
I think it does not work because the graphic window is DRM only, i.e.:
cat /dev/urandom > /dev/fb0
fails with:
cat: write error: No space left on device
and has no effect, and the Linux kernel does not appear to have a built-in DRM console as it does for fbdev with fbcon.
There is however one out-of-tree implementation: kmscon.
14.2.2.2. QEMU graphic mode arm terminal implementation
arm and aarch64 rely on the QEMU CLI option:
-device virtio-gpu-pci
and the kernel config options:
CONFIG_DRM=y CONFIG_DRM_VIRTIO_GPU=y
Unlike x86, arm and aarch64 don’t have a display device attached by default, thus the need for virtio-gpu-pci.
See also https://wiki.qemu.org/Documentation/Platforms/ARM (recently edited and corrected by yours truly… :-)).
14.2.2.3. QEMU graphic mode arm VGA
TODO: how to use VGA on ARM? https://stackoverflow.com/questions/20811203/how-can-i-output-to-vga-through-qemu-arm Tried:
-device VGA
# We use virtio-gpu because the legacy VGA framebuffer is # very troublesome on aarch64, and virtio-gpu is the only # video device that doesn't implement it.
so maybe it is not possible?
14.3. gem5 graphic mode
gem5 does not have a "text mode", since it cannot redirect the Linux terminal to same host terminal where the executable is running: you are always forced to connect to the terminal with gem-shell.
TODO could not get it working on x86_64, only ARM.
More concretely, first build the kernel with the gem5 arm Linux kernel patches, and then run:
./build-linux \ --arch arm \ --custom-config-file-gem5 \ --linux-build-id gem5-v4.15 \ ; ./run --arch arm --emulator gem5 --linux-build-id gem5-v4.15
and then on another shell:
vinagre localhost:5900
The CONFIG_LOGO penguin only appears after several seconds, together with kernel messages of type:
[ 0.152755] [drm] found ARM HDLCD version r0p0 [ 0.152790] hdlcd 2b000000.hdlcd: bound virt-encoder (ops 0x80935f94) [ 0.152795] [drm] Supports vblank timestamp caching Rev 2 (21.10.2013). [ 0.152799] [drm] No driver support for vblank timestamp query. [ 0.215179] Console: switching to colour frame buffer device 240x67 [ 0.230389] hdlcd 2b000000.hdlcd: fb0: frame buffer device [ 0.230509] [drm] Initialized hdlcd 1.0.0 20151021 for 2b000000.hdlcd on minor 0
The port 5900 is incremented by one if you already have something running on that port, gem5 stdout tells us the right port on stdout as:
system.vncserver: Listening for connections on port 5900
and when we connect it shows a message:
info: VNC client attached
Alternatively, you can also dump each new frame to an image file with --frame-capture:
./run \ --arch arm \ --emulator gem5 \ --linux-build-id gem5-v4.15 \ -- --frame-capture \ ;
This creates on compressed PNG whenever the screen image changes inside the m5out directory with filename of type:
frames_system.vncserver/fb.<frame-index>.<timestamp>.png.gz
It is fun to see how we get one new frame whenever the white underscore cursor appears and reappears under the penguin!
The last frame is always available uncompressed at: system.framebuffer.png.
TODO kmscube failed on aarch64 with:
kmscube[706]: unhandled level 2 translation fault (11) at 0x00000000, esr 0x92000006, in libgbm.so.1.0.0[7fbf6a6000+e000]
Tested on: 38fd6153d965ba20145f53dc1bb3ba34b336bde9
14.3.1. Graphic mode gem5 aarch64
For aarch64 we also need to configure the kernel with linux_config/display:
git -C "$(./getvar linux_source_dir)" fetch https://gem5.googlesource.com/arm/linux gem5/v4.15:gem5/v4.15 git -C "$(./getvar linux_source_dir)" checkout gem5/v4.15 ./build-linux \ --arch aarch64 \ --config-fragment linux_config/display \ --custom-config-file-gem5 \ --linux-build-id gem5-v4.15 \ ; git -C "$(./getvar linux_source_dir)" checkout - ./run --arch aarch64 --emulator gem5 --linux-build-id gem5-v4.15
This is because the gem5 aarch64 defconfig does not enable HDLCD like the 32 bit one arm one for some reason.
14.3.2. gem5 graphic mode DP650
TODO get working. There is an unmerged patchset at: https://gem5-review.googlesource.com/c/public/gem5/+/11036/1
The DP650 is a newer display hardware than HDLCD. TODO is its interface publicly documented anywhere? Since it has a gem5 model and in-tree Linux kernel support, that information cannot be secret?
The key option to enable support in Linux is DRM_MALI_DISPLAY=y which we enable at linux_config/display.
Build the kernel exactly as for Graphic mode gem5 aarch64 and then run with:
./run --arch aarch64 --dp650 --emulator gem5 --linux-build-id gem5-v4.15
14.3.3. gem5 graphic mode internals
We cannot use mainline Linux because the gem5 arm Linux kernel patches are required at least to provide the CONFIG_DRM_VIRT_ENCODER option.
gem5 emulates the HDLCD ARM Holdings hardware for arm and aarch64.
The kernel uses HDLCD to implement the DRM interface, the required kernel config options are present at: linux_config/display.
TODO: minimize out the --custom-config-file. If we just remove it on arm: it does not work with a failing dmesg:
[ 0.066208] [drm] found ARM HDLCD version r0p0 [ 0.066241] hdlcd 2b000000.hdlcd: bound virt-encoder (ops drm_vencoder_ops) [ 0.066247] [drm] Supports vblank timestamp caching Rev 2 (21.10.2013). [ 0.066252] [drm] No driver support for vblank timestamp query. [ 0.066276] hdlcd 2b000000.hdlcd: Cannot do DMA to address 0x0000000000000000 [ 0.066281] swiotlb: coherent allocation failed for device 2b000000.hdlcd size=8294400 [ 0.066288] CPU: 0 PID: 1 Comm: swapper/0 Not tainted 4.15.0 #1 [ 0.066293] Hardware name: V2P-AARCH64 (DT) [ 0.066296] Call trace: [ 0.066301] dump_backtrace+0x0/0x1b0 [ 0.066306] show_stack+0x24/0x30 [ 0.066311] dump_stack+0xb8/0xf0 [ 0.066316] swiotlb_alloc_coherent+0x17c/0x190 [ 0.066321] __dma_alloc+0x68/0x160 [ 0.066325] drm_gem_cma_create+0x98/0x120 [ 0.066330] drm_fbdev_cma_create+0x74/0x2e0 [ 0.066335] __drm_fb_helper_initial_config_and_unlock+0x1d8/0x3a0 [ 0.066341] drm_fb_helper_initial_config+0x4c/0x58 [ 0.066347] drm_fbdev_cma_init_with_funcs+0x98/0x148 [ 0.066352] drm_fbdev_cma_init+0x40/0x50 [ 0.066357] hdlcd_drm_bind+0x220/0x428 [ 0.066362] try_to_bring_up_master+0x21c/0x2b8 [ 0.066367] component_master_add_with_match+0xa8/0xf0 [ 0.066372] hdlcd_probe+0x60/0x78 [ 0.066377] platform_drv_probe+0x60/0xc8 [ 0.066382] driver_probe_device+0x30c/0x478 [ 0.066388] __driver_attach+0x10c/0x128 [ 0.066393] bus_for_each_dev+0x70/0xb0 [ 0.066398] driver_attach+0x30/0x40 [ 0.066402] bus_add_driver+0x1d0/0x298 [ 0.066408] driver_register+0x68/0x100 [ 0.066413] __platform_driver_register+0x54/0x60 [ 0.066418] hdlcd_platform_driver_init+0x20/0x28 [ 0.066424] do_one_initcall+0x44/0x130 [ 0.066428] kernel_init_freeable+0x13c/0x1d8 [ 0.066433] kernel_init+0x18/0x108 [ 0.066438] ret_from_fork+0x10/0x1c [ 0.066444] hdlcd 2b000000.hdlcd: Failed to set initial hw configuration. [ 0.066470] hdlcd 2b000000.hdlcd: master bind failed: -12 [ 0.066477] hdlcd: probe of 2b000000.hdlcd failed with error -12
So what other options are missing from gem5_defconfig? It would be cool to minimize it out to better understand the options.
14.4. X11 Buildroot
Once you’ve seen the CONFIG_LOGO penguin as a sanity check, you can try to go for a cooler X11 Buildroot setup.
Build and run:
./build-buildroot --config-fragment buildroot_config/x11 ./run --graphic
Inside QEMU:
startx
And then from the GUI you can start exciting graphical programs such as:
xcalc xeyes
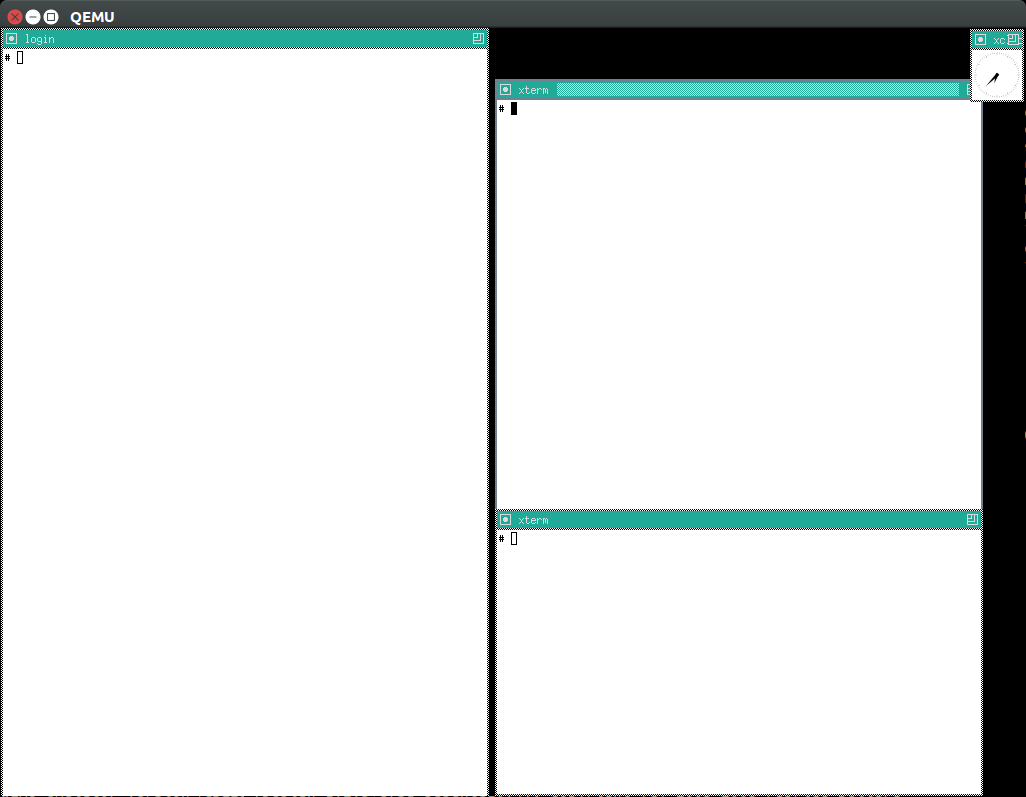
We don’t build X11 by default because it takes a considerable amount of time (about 20%), and is not expected to be used by most users: you need to pass the -x flag to enable it.
More details: https://unix.stackexchange.com/questions/70931/how-to-install-x11-on-my-own-linux-buildroot-system/306116#306116
Not sure how well that graphics stack represents real systems, but if it does it would be a good way to understand how it works.
To x11 packages have an xserver prefix as in:
./build-buildroot --config-fragment buildroot_config/x11 -- xserver_xorg-server-reconfigure
the easiest way to find them out is to just list "$(./getvar buildroot_build_build_dir)/x*.
TODO as of: c2696c978d6ca88e8b8599c92b1beeda80eb62b2 I noticed that startx leads to a BUG_ON:
[ 2.809104] WARNING: CPU: 0 PID: 51 at drivers/gpu/drm/ttm/ttm_bo_vm.c:304 ttm_bo_vm_open+0x37/0x40
14.4.1. X11 Buildroot mouse not moving
TODO 9076c1d9bcc13b6efdb8ef502274f846d8d4e6a1 I’m 100% sure that it was working before, but I didn’t run it forever, and it stopped working at some point. Needs bisection, on whatever commit last touched x11 stuff.
-show-cursor did not help, I just get to see the host cursor, but the guest cursor still does not move.
Doing:
watch -n 1 grep i8042 /proc/interrupts
shows that interrupts do happen when mouse and keyboard presses are done, so I expect that it is some wrong either with:
-
QEMU. Same behaviour if I try the host’s QEMU 2.10.1 however.
-
X11 configuration. We do have
BR2_PACKAGE_XDRIVER_XF86_INPUT_MOUSE=y.
/var/log/Xorg.0.log contains the following interesting lines:
[ 27.549] (II) LoadModule: "mouse" [ 27.549] (II) Loading /usr/lib/xorg/modules/input/mouse_drv.so [ 27.590] (EE) <default pointer>: Cannot find which device to use. [ 27.590] (EE) <default pointer>: cannot open input device [ 27.590] (EE) PreInit returned 2 for "<default pointer>" [ 27.590] (II) UnloadModule: "mouse"
The file /dev/inputs/mice does not exist.
Note that our current link:kernel_confi_fragment sets:
# CONFIG_INPUT_MOUSE is not set # CONFIG_INPUT_MOUSEDEV_PSAUX is not set
for gem5, so you might want to remove those lines to debug this.
14.4.2. X11 Buildroot ARM
On ARM, startx hangs at a message:
vgaarb: this pci device is not a vga device
and nothing shows on the screen, and:
grep EE /var/log/Xorg.0.log
says:
(EE) Failed to load module "modesetting" (module does not exist, 0)
A friend told me this but I haven’t tried it yet:
-
xf86-video-modesettingis likely the missing ingredient, but it does not seem possible to activate it from Buildroot currently without patching things. -
xf86-video-fbdevshould work as well, but we need to make sure fbdev is enabled, and maybe add some line to theXorg.conf
15. Networking
15.1. Enable networking
We disable networking by default because it starts an userland process, and we want to keep the number of userland processes to a minimum to make the system more understandable as explained at: Section 38.20.3, “Resource tradeoff guidelines”
To enable networking on Buildroot, simply run:
ifup -a
That command goes over all (-a) the interfaces in /etc/network/interfaces and brings them up.
Then test it with:
wget google.com cat index.html
Disable networking with:
ifdown -a
To enable networking by default after boot, use the methods documented at Run command at the end of BusyBox init.
15.2. ping
ping does not work within QEMU by default, e.g.:
ping google.com
hangs after printing the header:
PING google.com (216.58.204.46): 56 data bytes
Here Ciro describes how to get it working: https://unix.stackexchange.com/questions/473448/how-to-ping-from-the-qemu-guest-to-an-external-url
Further bibliography: https://superuser.com/questions/787400/qemu-user-mode-networking-doesnt-work
15.3. Guest host networking
In this section we discuss how to interact between the guest and the host through networking.
First ensure that you can access the external network since that is easier to get working, see: Section 15, “Networking”.
15.3.1. Host to guest networking
15.3.1.1. nc host to guest
With nc we can create the most minimal example possible as a sanity check.
On guest run:
nc -l -p 45455
Then on host run:
echo asdf | nc localhost 45455
asdf appears on the guest.
This uses:
-
BusyBox'
ncutility, which is enabled withCONFIG_NC=y -
ncfrom thenetcat-openbsdpackage on an Ubuntu 18.04 host
Only this specific port works by default since we have forwarded it on the QEMU command line.
We us this exact procedure to connect to gdbserver.
15.3.1.2. ssh into guest
Not enabled by default due to the build / runtime overhead. To enable, build with:
./build-buildroot --config 'BR2_PACKAGE_OPENSSH=y'
Then inside the guest turn on sshd:
./sshd.sh
Source: rootfs_overlay/lkmc/sshd.sh
And finally on host:
ssh root@localhost -p 45456
15.3.1.3. gem5 host to guest networking
Could not do port forwarding from host to guest, and therefore could not use gdbserver: https://stackoverflow.com/questions/48941494/how-to-do-port-forwarding-from-guest-to-host-in-gem5
15.3.2. Guest to host networking
First Enable networking.
Then in the host, start a server:
python -m SimpleHTTPServer 8000
And then in the guest, find the IP we need to hit with:
ip rounte
which gives:
default via 10.0.2.2 dev eth0 10.0.2.0/24 dev eth0 scope link src 10.0.2.15
so we use in the guest:
wget 10.0.2.2:8000
Bibliography:
15.4. 9P
The 9p protocol allows the guest to mount a host directory.
Both QEMU and gem5 9P support 9P.
15.4.1. 9P vs NFS
All of 9P and NFS (and sshfs) allow sharing directories between guest and host.
Advantages of 9P
-
doesn’t require
sudoon the host to mount -
we could share a guest directory to the host, but this would require running a server on the guest, which adds simulation overhead
Furthermore, this would be inconvenient, since what we usually want to do is to share host cross built files with the guest, and to do that we would have to copy the files over after the guest starts the server.
-
QEMU implements 9P natively, which makes it very stable and convenient, and must mean it is a simpler protocol than NFS as one would expect.
This is not the case for gem5 7bfb7f3a43f382eb49853f47b140bfd6caad0fb8 unfortunately, which relies on the diod host daemon, although it is not unfeasible that future versions could implement it natively as well.
Advantages of NFS:
-
way more widely used and therefore stable and available, not to mention that it also works on real hardware.
-
the name does not start with a digit, which is an invalid identifier in all programming languages known to man. Who in their right mind would call a software project as such? It does not even match the natural order of Plan 9; Plan then 9: P9!
15.4.2. 9P getting started
As usual, we have already set everything up for you. On host:
cd "$(./getvar p9_dir)" uname -a > host
Guest:
cd /mnt/9p/data cat host uname -a > guest
Host:
cat guest
The main ingredients for this are:
-
9Psettings in our kernel configs -
9pentry on our rootfs_overlay/etc/fstabAlternatively, you could also mount your own with:
mkdir /mnt/my9p mount -t 9p -o trans=virtio,version=9p2000.L host0 /mnt/my9p
where mount tag
host0is set by the emulator (mount_tagflag on QEMU CLI), and can be found in the guest with:cat /sys/bus/virtio/drivers/9pnet_virtio/virtio0/mount_tagas documented at: https://www.kernel.org/doc/Documentation/filesystems/9p.txt. -
Launch QEMU with
-virtfsas in your run scriptWhen we tried:
security_model=mapped
writes from guest failed due to user mismatch problems: https://serverfault.com/questions/342801/read-write-access-for-passthrough-9p-filesystems-with-libvirt-qemu
Bibliography:
15.4.3. gem5 9P
Is possible on aarch64 as shown at: https://gem5-review.googlesource.com/c/public/gem5/+/22831, and it is just a matter of exposing to X86 for those that want it.
Enable it by passing the --vio-9p option on the fs.py gem5 command line:
./run --arch aarch64 --emulator gem5 -- --vio-9p
Then on the guest:
mkdir -p /mnt/9p/gem5 mount -t 9p -o trans=virtio,version=9p2000.L,aname=/path/to/linux-kernel-module-cheat/out/run/gem5/aarch64/0/m5out/9p/share gem5 /mnt/9p/gem5 echo asdf > /mnt/9p/gem5/qwer
Yes, you have to pass the full path to the directory on the host. Yes, this is horrible.
The shared directory is:
out/run/gem5/aarch64/0/m5out/9p/share
so we can observe the file the guest wrote from the host with:
out/run/gem5/aarch64/0/m5out/9p/share/qwer
and vice versa:
echo zxvc > out/run/gem5/aarch64/0/m5out/9p/share/qwer
is now visible from the guest:
cat /mnt/9p/gem5/qwer
Checkpoint restore with an open mount will likely fail because gem5 uses an ugly external executable to implement diod. The protocol is not very complex, and QEMU implements it in-tree, which is what gem5 should do as well at some point.
Also checkpoint without --vio-9p and restore with --vio-9p did not work either, the mount fails.
However, this did work, on guest:
unmount /mnt/9p/gem5 m5 checkpoint
then restore with the detalied CPU of interest e.g.
./run --arch aarch64 --emulator gem5 -- --vio-9p --cpu-type DerivO3CPU --caches
Tested on gem5 b2847f43c91e27f43bd4ac08abd528efcf00f2fd, LKMC 52a5fdd7c1d6eadc5900fc76e128995d4849aada.
15.4.4. NFS
TODO: get working.
9P is better with emulation, but let’s just get this working for fun.
First make sure that this works: Section 15.3.2, “Guest to host networking”.
Then, build the kernel with NFS support:
./build-linux --config-fragment linux_config/nfs
Now on host:
sudo apt-get install nfs-kernel-server
Now edit /etc/exports to contain:
/tmp *(rw,sync,no_root_squash,no_subtree_check)
and restart the server:
sudo systemctl restart nfs-kernel-server
Now on guest:
mkdir /mnt/nfs mount -t nfs 10.0.2.2:/tmp /mnt/nfs
TODO: failing with:
mount: mounting 10.0.2.2:/tmp on /mnt/nfs failed: No such device
And now the /tmp directory from host is not mounted on guest!
If you don’t want to start the NFS server after the next boot automatically so save resources, do:
systemctl disable nfs-kernel-server
17. Linux kernel
17.1. Linux kernel configuration
17.1.1. Modify kernel config
To modify a single option on top of our default kernel configs, do:
./build-linux --config 'CONFIG_FORTIFY_SOURCE=y'
Kernel modules depend on certain kernel configs, and therefore in general you might have to clean and rebuild the kernel modules after changing the kernel config:
./build-modules --clean ./build-modules
and then proceed as in Your first kernel module hack.
You might often get way without rebuilding the kernel modules however.
To use an extra kernel config fragment file on top of our defaults, do:
printf ' CONFIG_IKCONFIG=y CONFIG_IKCONFIG_PROC=y ' > data/myconfig ./build-linux --config-fragment 'data/myconfig'
To use just your own exact .config instead of our defaults ones, use:
./build-linux --custom-config-file data/myconfig
There is also a shortcut --custom-config-file-gem5 to use the gem5 arm Linux kernel patches.
The following options can all be used together, sorted by decreasing config setting power precedence:
-
--config -
--config-fragment -
--custom-config-file
To do a clean menu config yourself and use that for the build, do:
./build-linux --clean ./build-linux --custom-config-target menuconfig
But remember that every new build re-configures the kernel by default, so to keep your configs you will need to use on further builds:
./build-linux --no-configure
So what you likely want to do instead is to save that as a new defconfig and use it later as:
./build-linux --no-configure --no-modules-install savedefconfig cp "$(./getvar linux_build_dir)/defconfig" data/myconfig ./build-linux --custom-config-file data/myconfig
You can also use other config generating targets such as defconfig with the same method as shown at: Section 17.1.3.1.1, “Linux kernel defconfig”.
17.1.2. Find the kernel config
Get the build config in guest:
zcat /proc/config.gz
or with our shortcut:
./conf.sh
or to conveniently grep for a specific option case insensitively:
./conf.sh ikconfig
Source: rootfs_overlay/lkmc/conf.sh.
This is enabled by:
CONFIG_IKCONFIG=y CONFIG_IKCONFIG_PROC=y
From host:
cat "$(./getvar linux_config)"
Just for fun https://stackoverflow.com/questions/14958192/how-to-get-the-config-from-a-linux-kernel-image/14958263#14958263:
./linux/scripts/extract-ikconfig "$(./getvar vmlinux)"
although this can be useful when someone gives you a random image.
17.1.3. About our Linux kernel configs
By default, build-linux generates a .config that is a mixture of:
-
a base config extracted from Buildroot’s minimal per machine
.config, which has the minimal options needed to boot as explained at: Section 17.1.3.1, “About Buildroot’s kernel configs”. -
small overlays put top of that
To find out which kernel configs are being used exactly, simply run:
./build-linux --dry-run
and look for the merge_config.sh call. This script from the Linux kernel tree, as the name suggests, merges multiple configuration files into one as explained at: https://unix.stackexchange.com/questions/224887/how-to-script-make-menuconfig-to-automate-linux-kernel-build-configuration/450407#450407
For each arch, the base of our configs are named as:
linux_config/buildroot-<arch>
These configs are extracted directly from a Buildroot build with update-buildroot-kernel-configs.
Note that Buildroot can sed override some of the configurations, e.g. it forces CONFIG_BLK_DEV_INITRD=y when BR2_TARGET_ROOTFS_CPIO is on. For this reason, those configs are not simply copy pasted from Buildroot files, but rather from a Buildroot kernel build, and then minimized with make savedefconfig: https://stackoverflow.com/questions/27899104/how-to-create-a-defconfig-file-from-a-config
On top of those, we add the following by default:
-
linux_config/min: see: Section 17.1.3.1.2, “Linux kernel min config”
-
linux_config/default: other optional configs that we enable by default because they increase visibility, or expose some cool feature, and don’t significantly increase build time nor add significant runtime overhead
We have since observed that the kernel size itself is very bloated compared to
defconfigas shown at: Section 17.1.3.1.1, “Linux kernel defconfig”.
17.1.3.1. About Buildroot’s kernel configs
To see Buildroot’s base configs, start from buildroot/configs/qemu_x86_64_defconfig.
That file contains BR2_LINUX_KERNEL_CUSTOM_CONFIG_FILE="board/qemu/x86_64/linux-4.15.config", which points to the base config file used: board/qemu/x86_64/linux-4.15.config.
arm, on the other hand, uses buildroot/configs/qemu_arm_vexpress_defconfig, which contains BR2_LINUX_KERNEL_DEFCONFIG="vexpress", and therefore just does a make vexpress_defconfig, and gets its config from the Linux kernel tree itself.
17.1.3.1.1. Linux kernel defconfig
To boot defconfig from disk on Linux and see a shell, all we need is these missing virtio options:
./build-linux \ --linux-build-id defconfig \ --custom-config-target defconfig \ --config CONFIG_VIRTIO_PCI=y \ --config CONFIG_VIRTIO_BLK=y \ ; ./run --linux-build-id defconfig
Oh, and check this out:
du -h \ "$(./getvar vmlinux)" \ "$(./getvar --linux-build-id defconfig vmlinux)" \ ;
Output:
360M /path/to/linux-kernel-module-cheat/out/linux/default/x86_64/vmlinux 47M /path/to/linux-kernel-module-cheat/out/linux/defconfig/x86_64/vmlinux
Brutal. Where did we go wrong?
The extra virtio options are not needed if we use initrd:
./build-linux \ --linux-build-id defconfig \ --custom-config-target defconfig \ ; ./run --initrd --linux-build-id defconfig
On aarch64, we can boot from initrd with:
./build-linux \ --arch aarch64 \ --linux-build-id defconfig \ --custom-config-target defconfig \ ; ./run \ --arch aarch64 \ --initrd \ --linux-build-id defconfig \ --memory 2G \ ;
We need the 2G of memory because the CPIO is 600MiB due to a humongous amount of loadable kernel modules!
In aarch64, the size situation is inverted from x86_64, and this can be seen on the vmlinux size as well:
118M /path/to/linux-kernel-module-cheat/out/linux/default/aarch64/vmlinux 240M /path/to/linux-kernel-module-cheat/out/linux/defconfig/aarch64/vmlinux
So it seems that the ARM devs decided rather than creating a minimal config that boots QEMU, to try and make a single config that boots every board in existence. Terrible!
Bibliography: https://unix.stackexchange.com/questions/29439/compiling-the-kernel-with-default-configurations/204512#204512
Tested on 1e2b7f1e5e9e3073863dc17e25b2455c8ebdeadd + 1.
17.1.3.1.2. Linux kernel min config
linux_config/min contains minimal tweaks required to boot gem5 or for using our slightly different QEMU command line options than Buildroot on all archs.
It is one of the default config fragments we use, as explained at: Section 17.1.3, “About our Linux kernel configs”>.
Having the same config working for both QEMU and gem5 (oh, the hours of bisection) means that you can deal with functional matters in QEMU, which runs much faster, and switch to gem5 only for performance issues.
We can build just with min on top of the base config with:
./build-linux \ --arch aarch64 \ --config-fragment linux_config/min \ --custom-config-file linux_config/buildroot-aarch64 \ --linux-build-id min \ ;
vmlinux had a very similar size to the default. It seems that linux_config/buildroot-aarch64 contains or implies most linux_config/default options already? TODO: that seems odd, really?
Tested on 649d06d6758cefd080d04dc47fd6a5a26a620874 + 1.
17.1.3.2. Notable alternate gem5 kernel configs
Other configs which we had previously tested at 4e0d9af81fcce2ce4e777cb82a1990d7c2ca7c1e are:
-
armandaarch64configs present in the official ARM gem5 Linux kernel fork as described at: Section 24.9, “gem5 arm Linux kernel patches”. Some of the configs present there are added by the patches. -
Jason’s magic
x86_64config: http://web.archive.org/web/20171229121642/http://www.lowepower.com/jason/files/config which is referenced at: http://web.archive.org/web/20171229121525/http://www.lowepower.com/jason/setting-up-gem5-full-system.html. QEMU boots with that by removing# CONFIG_VIRTIO_PCI is not set.
17.2. Kernel version
17.2.1. Find the kernel version
We try to use the latest possible kernel major release version.
In QEMU:
cat /proc/version
or in the source:
cd "$(./getvar linux_source_dir)" git log | grep -E ' Linux [0-9]+\.' | head
17.2.2. Update the Linux kernel
During update all you kernel modules may break since the kernel API is not stable.
They are usually trivial breaks of things moving around headers or to sub-structs.
The userland, however, should simply not break, as Linus enforces strict backwards compatibility of userland interfaces.
This backwards compatibility is just awesome, it makes getting and running the latest master painless.
This also makes this repo the perfect setup to develop the Linux kernel.
In case something breaks while updating the Linux kernel, you can try to bisect it to understand the root cause, see: Section 38.17, “Bisection”.
17.2.2.1. Update the Linux kernel LKMC procedure
First, use use the branching procedure described at: Section 38.18, “Update a forked submodule”
Because the kernel is so central to this repository, almost all tests must be re-run, so basically just follow the full testing procedure described at: Section 38.16, “Test this repo”. The only tests that can be skipped are essentially the Baremetal tests.
Before comitting, don’t forget to update:
-
the
linux_kernel_versionconstant in common.py -
the tagline of this repository on:
-
this README
-
the GitHub project description
-
17.2.3. Downgrade the Linux kernel
The kernel is not forward compatible, however, so downgrading the Linux kernel requires downgrading the userland too to the latest Buildroot branch that supports it.
The default Linux kernel version is bumped in Buildroot with commit messages of type:
linux: bump default to version 4.9.6
So you can try:
git log --grep 'linux: bump default to version'
Those commits change BR2_LINUX_KERNEL_LATEST_VERSION in /linux/Config.in.
You should then look up if there is a branch that supports that kernel. Staying on branches is a good idea as they will get backports, in particular ones that fix the build as newer host versions come out.
Finally, after downgrading Buildroot, if something does not work, you might also have to make some changes to how this repo uses Buildroot, as the Buildroot configuration options might have changed.
We don’t expect those changes to be very difficult. A good way to approach the task is to:
-
do a dry run build to get the equivalent Bash commands used:
./build-buildroot --dry-run
-
build the Buildroot documentation for the version you are going to use, and check if all Buildroot build commands make sense there
Then, if you spot an option that is wrong, some grepping in this repo should quickly point you to the code you need to modify.
It also possible that you will need to apply some patches from newer Buildroot versions for it to build, due to incompatibilities with the host Ubuntu packages and that Buildroot version. Just read the error message, and try:
-
git log master — packages/<pkg> -
Google the error message for mailing list hits
Successful port reports:
17.3. Kernel command line parameters
Bootloaders can pass a string as input to the Linux kernel when it is booting to control its behaviour, much like the execve system call does to userland processes.
This allows us to control the behaviour of the kernel without rebuilding anything.
With QEMU, QEMU itself acts as the bootloader, and provides the -append option and we expose it through ./run --kernel-cli, e.g.:
./run --kernel-cli 'foo bar'
Then inside the host, you can check which options were given with:
cat /proc/cmdline
They are also printed at the beginning of the boot message:
dmesg | grep "Command line"
See also:
The arguments are documented in the kernel documentation: https://www.kernel.org/doc/html/v4.14/admin-guide/kernel-parameters.html
When dealing with real boards, extra command line options are provided on some magic bootloader configuration file, e.g.:
-
GRUB configuration files: https://askubuntu.com/questions/19486/how-do-i-add-a-kernel-boot-parameter
-
Raspberry pi
/boot/cmdline.txton a magic partition: https://raspberrypi.stackexchange.com/questions/14839/how-to-change-the-kernel-commandline-for-archlinuxarm-on-raspberry-pi-effectly
17.3.1. Kernel command line parameters escaping
Double quotes can be used to escape spaces as in opt="a b", but double quotes themselves cannot be escaped, e.g. opt"a\"b"
This even lead us to use base64 encoding with --eval!
17.3.2. Kernel command line parameters definition points
There are two methods:
-
__setupas in:__setup("console=", console_setup); -
core_paramas in:core_param(panic, panic_timeout, int, 0644);
core_param suggests how they are different:
/** * core_param - define a historical core kernel parameter. ... * core_param is just like module_param(), but cannot be modular and * doesn't add a prefix (such as "printk."). This is for compatibility * with __setup(), and it makes sense as truly core parameters aren't * tied to the particular file they're in. */
17.3.3. rw
By default, the Linux kernel mounts the root filesystem as readonly. TODO rationale?
This cannot be observed in the default BusyBox init, because by default our rootfs_overlay/etc/inittab does:
/bin/mount -o remount,rw /
Analogously, Ubuntu 18.04 does in its fstab something like:
UUID=/dev/sda1 / ext4 errors=remount-ro 0 1
which uses default mount rw flags.
We have however removed those setups init setups to keep things more minimal, and replaced them with the rw kernel boot parameter makes the root mounted as writable.
To observe the default readonly behaviour, hack the run script to remove replace init, and then run on a raw shell:
./run --kernel-cli 'init=/bin/sh'
Now try to do:
touch a
which fails with:
touch: a: Read-only file system
We can also observe the read-onlyness with:
mount -t proc /proc mount
which contains:
/dev/root on / type ext2 (ro,relatime,block_validity,barrier,user_xattr)
and so it is Read Only as shown by ro.
17.3.4. norandmaps
Disable userland address space randomization. Test it out by running rand_check.out twice:
./run --eval-after './linux/rand_check.out;./linux/poweroff.out' ./run --eval-after './linux/rand_check.out;./linux/poweroff.out'
If we remove it from our run script by hacking it up, the addresses shown by linux/rand_check.out vary across boots.
Equivalent to:
echo 0 > /proc/sys/kernel/randomize_va_space
17.4. printk
printk is the most simple and widely used way of getting information from the kernel, so you should familiarize yourself with its basic configuration.
We use printk a lot in our kernel modules, and it shows on the terminal by default, along with stdout and what you type.
Hide all printk messages:
dmesg -n 1
or equivalently:
echo 1 > /proc/sys/kernel/printk
See also: https://superuser.com/questions/351387/how-to-stop-kernel-messages-from-flooding-my-console
Do it with a Kernel command line parameters to affect the boot itself:
./run --kernel-cli 'loglevel=5'
and now only boot warning messages or worse show, which is useful to identify problems.
Our default printk format is:
<LEVEL>[TIMESTAMP] MESSAGE
e.g.:
<6>[ 2.979121] Freeing unused kernel memory: 2024K
where:
-
LEVEL: higher means less serious -
TIMESTAMP: seconds since boot
This format is selected by the following boot options:
-
console_msg_format=syslog: add the<LEVEL>part. Added in v4.16. -
printk.time=y: add the[TIMESTAMP]part
The debug highest level is a bit more magic, see: Section 17.4.3, “pr_debug” for more info.
17.4.1. /proc/sys/kernel/printk
The current printk level can be obtained with:
cat /proc/sys/kernel/printk
As of 87e846fc1f9c57840e143513ebd69c638bd37aa8 this prints:
7 4 1 7
which contains:
-
7: current log level, modifiable by previously mentioned methods -
4: documented as: "printk’s without a loglevel use this": TODO what does that mean, how to callprintkwithout a log level? -
1: minimum log level that still prints something (0prints nothing) -
7: default log level
We start at the boot time default after boot by default, as can be seen from:
insmod myprintk.ko
which outputs something like:
<1>[ 12.494429] pr_alert <2>[ 12.494666] pr_crit <3>[ 12.494823] pr_err <4>[ 12.494911] pr_warning <5>[ 12.495170] pr_notice <6>[ 12.495327] pr_info
Source: kernel_modules/myprintk.c
This proc entry is defined at: https://github.com/torvalds/linux/blob/v5.1/kernel/sysctl.c#L839
#if defined CONFIG_PRINTK
{
.procname = "printk",
.data = &console_loglevel,
.maxlen = 4*sizeof(int),
.mode = 0644,
.proc_handler = proc_dointvec,
},
which teaches us that printk can be completely disabled at compile time:
config PRINTK default y bool "Enable support for printk" if EXPERT select IRQ_WORK help This option enables normal printk support. Removing it eliminates most of the message strings from the kernel image and makes the kernel more or less silent. As this makes it very difficult to diagnose system problems, saying N here is strongly discouraged.
console_loglevel is defined at:
#define console_loglevel (console_printk[0])
and console_printk is an array with 4 ints:
int console_printk[4] = {
CONSOLE_LOGLEVEL_DEFAULT, /* console_loglevel */
MESSAGE_LOGLEVEL_DEFAULT, /* default_message_loglevel */
CONSOLE_LOGLEVEL_MIN, /* minimum_console_loglevel */
CONSOLE_LOGLEVEL_DEFAULT, /* default_console_loglevel */
};
and then we see that the default is configurable with CONFIG_CONSOLE_LOGLEVEL_DEFAULT:
/* * Default used to be hard-coded at 7, quiet used to be hardcoded at 4, * we're now allowing both to be set from kernel config. */ #define CONSOLE_LOGLEVEL_DEFAULT CONFIG_CONSOLE_LOGLEVEL_DEFAULT #define CONSOLE_LOGLEVEL_QUIET CONFIG_CONSOLE_LOGLEVEL_QUIET
The message loglevel default is explained at:
/* printk's without a loglevel use this.. */ #define MESSAGE_LOGLEVEL_DEFAULT CONFIG_MESSAGE_LOGLEVEL_DEFAULT
The min is just hardcoded to one as you would expect, with some amazing kernel comedy around it:
/* We show everything that is MORE important than this.. */ #define CONSOLE_LOGLEVEL_SILENT 0 /* Mum's the word */ #define CONSOLE_LOGLEVEL_MIN 1 /* Minimum loglevel we let people use */ #define CONSOLE_LOGLEVEL_DEBUG 10 /* issue debug messages */ #define CONSOLE_LOGLEVEL_MOTORMOUTH 15 /* You can't shut this one up */
We then also learn about the useless quiet and debug kernel parameters at:
config CONSOLE_LOGLEVEL_QUIET int "quiet console loglevel (1-15)" range 1 15 default "4" help loglevel to use when "quiet" is passed on the kernel commandline. When "quiet" is passed on the kernel commandline this loglevel will be used as the loglevel. IOW passing "quiet" will be the equivalent of passing "loglevel=<CONSOLE_LOGLEVEL_QUIET>"
which explains the useless reason why that number is special. This is implemented at:
static int __init debug_kernel(char *str)
{
console_loglevel = CONSOLE_LOGLEVEL_DEBUG;
return 0;
}
static int __init quiet_kernel(char *str)
{
console_loglevel = CONSOLE_LOGLEVEL_QUIET;
return 0;
}
early_param("debug", debug_kernel);
early_param("quiet", quiet_kernel);
17.4.2. ignore_loglevel
./run --kernel-cli 'ignore_loglevel'
enables all log levels, and is basically the same as:
./run --kernel-cli 'loglevel=8'
except that you don’t need to know what is the maximum level.
17.4.3. pr_debug
Debug messages are not printable by default without recompiling.
But the awesome CONFIG_DYNAMIC_DEBUG=y option which we enable by default allows us to do:
echo 8 > /proc/sys/kernel/printk echo 'file kernel/module.c +p' > /sys/kernel/debug/dynamic_debug/control ./linux/myinsmod.out hello.ko
and we have a shortcut at:
./pr_debug.sh
Source: rootfs_overlay/lkmc/pr_debug.sh.
Wildcards are also accepted, e.g. enable all messages from all files:
echo 'file * +p' > /sys/kernel/debug/dynamic_debug/control
TODO: why is this not working:
echo 'func sys_init_module +p' > /sys/kernel/debug/dynamic_debug/control
Enable messages in specific modules:
echo 8 > /proc/sys/kernel/printk echo 'module myprintk +p' > /sys/kernel/debug/dynamic_debug/control insmod myprintk.ko
Source: kernel_modules/myprintk.c
This outputs the pr_debug message:
printk debug
but TODO: it also shows debug messages even without enabling them explicitly:
echo 8 > /proc/sys/kernel/printk insmod myprintk.ko
and it shows as enabled:
# grep myprintk /sys/kernel/debug/dynamic_debug/control /root/linux-kernel-module-cheat/out/kernel_modules/x86_64/kernel_modules/panic.c:12 [myprintk]myinit =p "pr_debug\012"
Enable pr_debug for boot messages as well, before we can reach userland and write to /proc:
./run --kernel-cli 'dyndbg="file * +p" loglevel=8'
Get ready for the noisiest boot ever, I think it overflows the printk buffer and funny things happen.
17.4.3.1. pr_debug != printk(KERN_DEBUG
When CONFIG_DYNAMIC_DEBUG is set, printk(KERN_DEBUG is not the exact same as pr_debug( since printk(KERN_DEBUG messages are visible with:
./run --kernel-cli 'initcall_debug logleve=8'
which outputs lines of type:
<7>[ 1.756680] calling clk_disable_unused+0x0/0x130 @ 1 <7>[ 1.757003] initcall clk_disable_unused+0x0/0x130 returned 0 after 111 usecs
which are printk(KERN_DEBUG inside init/main.c in v4.16.
Mentioned at: https://stackoverflow.com/questions/37272109/how-to-get-details-of-all-modules-drivers-got-initialized-probed-during-kernel-b
This likely comes from the ifdef split at init/main.c:
/* If you are writing a driver, please use dev_dbg instead */
#if defined(CONFIG_DYNAMIC_DEBUG)
#include <linux/dynamic_debug.h>
/* dynamic_pr_debug() uses pr_fmt() internally so we don't need it here */
#define pr_debug(fmt, ...) \
dynamic_pr_debug(fmt, ##__VA_ARGS__)
#elif defined(DEBUG)
#define pr_debug(fmt, ...) \
printk(KERN_DEBUG pr_fmt(fmt), ##__VA_ARGS__)
#else
#define pr_debug(fmt, ...) \
no_printk(KERN_DEBUG pr_fmt(fmt), ##__VA_ARGS__)
#endif
17.5. Kernel module APIs
17.5.1. Kernel module parameters
The Linux kernel allows passing module parameters at insertion time through the init_module and finit_module system calls.
The insmod tool exposes that as:
insmod params.ko i=3 j=4
Parameters are declared in the module as:
static u32 i = 0; module_param(i, int, S_IRUSR | S_IWUSR); MODULE_PARM_DESC(i, "my favorite int");
Automated test:
./params.sh echo $?
Outcome: the test passes:
0
Sources:
As shown in the example, module parameters can also be read and modified at runtime from sysfs.
We can obtain the help text of the parameters with:
modinfo params.ko
The output contains:
parm: j:my second favorite int parm: i:my favorite int
17.5.1.1. modprobe.conf
modprobe insertion can also set default parameters via the /etc/modprobe.conf file:
modprobe params cat /sys/kernel/debug/lkmc_params
Output:
12 34
This is specially important when loading modules with Kernel module dependencies or else we would have no opportunity of passing those.
modprobe.conf doesn’t actually insmod anything for us: https://superuser.com/questions/397842/automatically-load-kernel-module-at-boot-angstrom/1267464#1267464
17.5.2. Kernel module dependencies
One module can depend on symbols of another module that are exported with EXPORT_SYMBOL:
./dep.sh echo $?
Outcome: the test passes:
0
Sources:
The kernel deduces dependencies based on the EXPORT_SYMBOL that each module uses.
Symbols exported by EXPORT_SYMBOL can be seen with:
insmod dep.ko grep lkmc_dep /proc/kallsyms
sample output:
ffffffffc0001030 r __ksymtab_lkmc_dep [dep] ffffffffc000104d r __kstrtab_lkmc_dep [dep] ffffffffc0002300 B lkmc_dep [dep]
This requires CONFIG_KALLSYMS_ALL=y.
Dependency information is stored by the kernel module build system in the .ko files' MODULE_INFO, e.g.:
modinfo dep2.ko
contains:
depends: dep
We can double check with:
strings 3 dep2.ko | grep -E 'depends'
The output contains:
depends=dep
Module dependencies are also stored at:
cd /lib/module/* grep dep modules.dep
Output:
extra/dep2.ko: extra/dep.ko extra/dep.ko:
TODO: what for, and at which point point does Buildroot / BusyBox generate that file?
17.5.2.1. Kernel module dependencies with modprobe
Unlike insmod, modprobe deals with kernel module dependencies for us.
First get kernel_modules buildroot package working.
Then, for example:
modprobe buildroot_dep2
outputs to dmesg:
42
and then:
lsmod
outputs:
Module Size Used by Tainted: G buildroot_dep2 16384 0 buildroot_dep 16384 1 buildroot_dep2
Sources:
Removal also removes required modules that have zero usage count:
modprobe -r buildroot_dep2
modprobe uses information from the modules.dep file to decide the required dependencies. That file contains:
extra/buildroot_dep2.ko: extra/buildroot_dep.ko
Bibliography:
17.5.3. MODULE_INFO
Module metadata is stored on module files at compile time. Some of the fields can be retrieved through the THIS_MODULE struct module:
insmod module_info.ko
Dmesg output:
name = module_info version = 1.0
Source: kernel_modules/module_info.c
Some of those are also present on sysfs:
cat /sys/module/module_info/version
Output:
1.0
And we can also observe them with the modinfo command line utility:
modinfo module_info.ko
sample output:
filename: module_info.ko license: GPL version: 1.0 srcversion: AF3DE8A8CFCDEB6B00E35B6 depends: vermagic: 4.17.0 SMP mod_unload modversions
Module information is stored in a special .modinfo section of the ELF file:
./run-toolchain readelf -- -SW "$(./getvar kernel_modules_build_subdir)/module_info.ko"
contains:
[ 5] .modinfo PROGBITS 0000000000000000 0000d8 000096 00 A 0 0 8
and:
./run-toolchain readelf -- -x .modinfo "$(./getvar kernel_modules_build_subdir)/module_info.ko"
gives:
0x00000000 6c696365 6e73653d 47504c00 76657273 license=GPL.vers 0x00000010 696f6e3d 312e3000 61736466 3d717765 ion=1.0.asdf=qwe 0x00000020 72000000 00000000 73726376 65727369 r.......srcversi 0x00000030 6f6e3d41 46334445 38413843 46434445 on=AF3DE8A8CFCDE 0x00000040 42364230 30453335 42360000 00000000 B6B00E35B6...... 0x00000050 64657065 6e64733d 006e616d 653d6d6f depends=.name=mo 0x00000060 64756c65 5f696e66 6f007665 726d6167 dule_info.vermag 0x00000070 69633d34 2e31372e 3020534d 50206d6f ic=4.17.0 SMP mo 0x00000080 645f756e 6c6f6164 206d6f64 76657273 d_unload modvers 0x00000090 696f6e73 2000 ions .
I think a dedicated section is used to allow the Linux kernel and command line tools to easily parse that information from the ELF file as we’ve done with readelf.
Bibliography:
17.5.4. vermagic
As of kernel v5.8, you can’t use VERMAGIC_STRING string from modules anymore as per: https://github.com/cirosantilli/linux/commit/51161bfc66a68d21f13d15a689b3ea7980457790. So instead we just showcase init_utsname.
Sample insmod output as of LKMC fa8c2ee521ea83a74a2300e7a3be9f9ab86e2cb6 + 1 aarch64:
<6>[ 25.180697] sysname = Linux <6>[ 25.180697] nodename = buildroot <6>[ 25.180697] release = 5.9.2 <6>[ 25.180697] version = #1 SMP Thu Jan 1 00:00:00 UTC 1970 <6>[ 25.180697] machine = aarch64 <6>[ 25.180697] domainname = (none)
Vermagic is a magic string present in the kernel and previously visible in MODULE_INFO on kernel modules. It is used to verify that the kernel module was compiled against a compatible kernel version and relevant configuration:
insmod vermagic.ko
Possible dmesg output:
VERMAGIC_STRING = 4.17.0 SMP mod_unload modversions
If we artificially create a mismatch with MODULE_INFO(vermagic, the insmod fails with:
insmod: can't insert 'vermagic_fail.ko': invalid module format
and dmesg says the expected and found vermagic found:
vermagic_fail: version magic 'asdfqwer' should be '4.17.0 SMP mod_unload modversions '
Source: kernel_modules/vermagic_fail.c
The kernel’s vermagic is defined based on compile time configurations at include/linux/vermagic.h:
#define VERMAGIC_STRING \
UTS_RELEASE " " \
MODULE_VERMAGIC_SMP MODULE_VERMAGIC_PREEMPT \
MODULE_VERMAGIC_MODULE_UNLOAD MODULE_VERMAGIC_MODVERSIONS \
MODULE_ARCH_VERMAGIC \
MODULE_RANDSTRUCT_PLUGIN
The SMP part of the string for example is defined on the same file based on the value of CONFIG_SMP:
#ifdef CONFIG_SMP #define MODULE_VERMAGIC_SMP "SMP " #else #define MODULE_VERMAGIC_SMP ""
TODO how to get the vermagic from running kernel from userland? https://lists.kernelnewbies.org/pipermail/kernelnewbies/2012-October/006306.html
kmod modprobe has a flag to skip the vermagic check:
--force-modversion
This option just strips modversion information from the module before loading, so it is not a kernel feature.
17.5.5. init_module
init_module and cleanup_module are an older alternative to the module_init and module_exit macros:
insmod init_module.ko rmmod init_module
Dmesg output:
init_module cleanup_module
Source: kernel_modules/init_module.c
TODO why were module_init and module_exit created? https://stackoverflow.com/questions/3218320/what-is-the-difference-between-module-init-and-init-module-in-a-linux-kernel-mod
17.5.6. Floating point in kernel modules
It is generally hard / impossible to use floating point operations in the kernel. TODO understand details.
A quick (x86-only for now because lazy) example is shown at: kernel_modules/float.c
Usage:
insmod float.ko myfloat=1 enable_fpu=1
We have to call: kernel_fpu_begin() before starting FPU operations, and kernel_fpu_end() when we are done. This particular example however did not blow up without it at lkmc 7f917af66b17373505f6c21d75af9331d624b3a9 + 1:
insmod float.ko myfloat=1 enable_fpu=0
The v5.1 documentation under arch/x86/include/asm/fpu/api.h reads:
* Use kernel_fpu_begin/end() if you intend to use FPU in kernel context. It * disables preemption so be careful if you intend to use it for long periods * of time.
The example sets in the kernel_modules/Makefile:
CFLAGS_REMOVE_float.o += -mno-sse -mno-sse2
to avoid:
error: SSE register return with SSE disabled
We found those flags with ./build-modules --verbose.
Bibliography:
17.6. Kernel panic and oops
To test out kernel panics and oops in controlled circumstances, try out the modules:
insmod panic.ko insmod oops.ko
Source:
A panic can also be generated with:
echo c > /proc/sysrq-trigger
Panic vs oops: https://unix.stackexchange.com/questions/91854/whats-the-difference-between-a-kernel-oops-and-a-kernel-panic
How to generate them:
When a panic happens, Shift-PgUp does not work as it normally does, and it is hard to get the logs if on are on QEMU graphic mode:
17.6.1. Kernel panic
On panic, the kernel dies, and so does our terminal.
The panic trace looks like:
panic: loading out-of-tree module taints kernel. panic myinit Kernel panic - not syncing: hello panic CPU: 0 PID: 53 Comm: insmod Tainted: G O 4.16.0 #6 Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS rel-1.11.0-0-g63451fca13-prebuilt.qemu-project.org 04/01/2014 Call Trace: dump_stack+0x7d/0xba ? 0xffffffffc0000000 panic+0xda/0x213 ? printk+0x43/0x4b ? 0xffffffffc0000000 myinit+0x1d/0x20 [panic] do_one_initcall+0x3e/0x170 do_init_module+0x5b/0x210 load_module+0x2035/0x29d0 ? kernel_read_file+0x7d/0x140 ? SyS_finit_module+0xa8/0xb0 SyS_finit_module+0xa8/0xb0 do_syscall_64+0x6f/0x310 ? trace_hardirqs_off_thunk+0x1a/0x32 entry_SYSCALL_64_after_hwframe+0x42/0xb7 RIP: 0033:0x7ffff7b36206 RSP: 002b:00007fffffffeb78 EFLAGS: 00000206 ORIG_RAX: 0000000000000139 RAX: ffffffffffffffda RBX: 000000000000005c RCX: 00007ffff7b36206 RDX: 0000000000000000 RSI: 000000000069e010 RDI: 0000000000000003 RBP: 000000000069e010 R08: 00007ffff7ddd320 R09: 0000000000000000 R10: 00007ffff7ddd320 R11: 0000000000000206 R12: 0000000000000003 R13: 00007fffffffef4a R14: 0000000000000000 R15: 0000000000000000 Kernel Offset: disabled ---[ end Kernel panic - not syncing: hello panic
Notice how our panic message hello panic is visible at:
Kernel panic - not syncing: hello panic
17.6.1.1. Kernel module stack trace to source line
The log shows which module each symbol belongs to if any, e.g.:
myinit+0x1d/0x20 [panic]
says that the function myinit is in the module panic.
To find the line that panicked, do:
./run-gdb
and then:
info line *(myinit+0x1d)
which gives us the correct line:
Line 7 of "/root/linux-kernel-module-cheat/out/kernel_modules/x86_64/kernel_modules/panic.c" starts at address 0xbf00001c <myinit+28> and ends at 0xbf00002c <myexit>.
as explained at: https://stackoverflow.com/questions/8545931/using-gdb-to-convert-addresses-to-lines/27576029#27576029
The exact same thing can be done post mortem with:
./run-toolchain gdb -- \ -batch \ -ex 'info line *(myinit+0x1d)' \ "$(./getvar kernel_modules_build_subdir)/panic.ko" \ ;
Related:
17.6.1.2. BUG_ON
Basically just calls panic("BUG!") for most archs.
17.6.1.3. Exit emulator on panic
For testing purposes, it is very useful to quit the emulator automatically with exit status non zero in case of kernel panic, instead of just hanging forever.
17.6.1.3.1. Exit QEMU on panic
Enabled by default with:
-
panic=-1command line option which reboots the kernel immediately on panic, see: Section 17.6.1.4, “Reboot on panic” -
QEMU
-no-reboot, which makes QEMU exit when the guest tries to reboot
Also asked at https://unix.stackexchange.com/questions/443017/can-i-make-qemu-exit-with-failure-on-kernel-panic which also mentions the x86_64 -device pvpanic, but I don’t see much advantage to it.
TODO neither method exits with exit status different from 0, so for now we are just grepping the logs for panic messages, which sucks.
One possibility that gets close would be to use GDB step debug to break at the panic function, and then send a QEMU monitor from GDB quit command if that happens, but I don’t see a way to exit with non-zero status to indicate error.
17.6.1.3.2. Exit gem5 on panic
gem5 9048ef0ffbf21bedb803b785fb68f83e95c04db8 (January 2019) can detect panics automatically if the option system.panic_on_panic is on.
It parses kernel symbols and detecting when the PC reaches the address of the panic function. gem5 then prints to stdout:
Kernel panic in simulated kernel
and exits with status -6.
At gem5 ff52563a214c71fcd1e21e9f00ad839612032e3b (July 2018) behaviour was different, and just exited 0: https://www.mail-archive.com/gem5-users@gem5.org/msg15870.html TODO find fixing commit.
We enable the system.panic_on_panic option by default on arm and aarch64, which makes gem5 exit immediately in case of panic, which is awesome!
If we don’t set system.panic_on_panic, then gem5 just hangs on an infinite guest loop.
TODO: why doesn’t gem5 x86 ff52563a214c71fcd1e21e9f00ad839612032e3b support system.panic_on_panic as well? Trying to set system.panic_on_panic there fails with:
tried to set or access non-existentobject parameter: panic_on_panic
However, at that commit panic on x86 makes gem5 crash with:
panic: i8042 "System reset" command not implemented.
which is a good side effect of an unimplemented hardware feature, since the simulation actually stops.
The implementation of panic detection happens at: https://github.com/gem5/gem5/blob/1da285dfcc31b904afc27e440544d006aae25b38/src/arch/arm/linux/system.cc#L73
kernelPanicEvent = addKernelFuncEventOrPanic<Linux::KernelPanicEvent>(
"panic", "Kernel panic in simulated kernel", dmesg_output);
Here we see that the symbol "panic" for the panic() function is the one being tracked.
17.6.1.4. Reboot on panic
Make the kernel reboot after n seconds after panic:
echo 1 > /proc/sys/kernel/panic
Can also be controlled with the panic= kernel boot parameter.
0 to disable, -1 to reboot immediately.
Bibliography:
17.6.1.5. Panic trace show addresses instead of symbols
If CONFIG_KALLSYMS=n, then addresses are shown on traces instead of symbol plus offset.
In v4.16 it does not seem possible to configure that at runtime. GDB step debugging with:
./run --eval-after 'insmod dump_stack.ko' --gdb-wait --tmux-args dump_stack
shows that traces are printed at arch/x86/kernel/dumpstack.c:
static void printk_stack_address(unsigned long address, int reliable,
char *log_lvl)
{
touch_nmi_watchdog();
printk("%s %s%pB\n", log_lvl, reliable ? "" : "? ", (void *)address);
}
and %pB is documented at Documentation/core-api/printk-formats.rst:
If KALLSYMS are disabled then the symbol address is printed instead.
I wasn’t able do disable CONFIG_KALLSYMS to test this this out however, it is being selected by some other option? But I then used make menuconfig to see which options select it, and they were all off…
17.6.2. Kernel oops
On oops, the shell still lives after.
However we:
-
leave the normal control flow, and
oops afternever gets printed: an interrupt is serviced -
cannot
rmmod oopsafterwards
It is possible to make oops lead to panics always with:
echo 1 > /proc/sys/kernel/panic_on_oops insmod oops.ko
An oops stack trace looks like:
BUG: unable to handle kernel NULL pointer dereference at 0000000000000000 IP: myinit+0x18/0x30 [oops] PGD dccf067 P4D dccf067 PUD dcc1067 PMD 0 Oops: 0002 [#1] SMP NOPTI Modules linked in: oops(O+) CPU: 0 PID: 53 Comm: insmod Tainted: G O 4.16.0 #6 Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS rel-1.11.0-0-g63451fca13-prebuilt.qemu-project.org 04/01/2014 RIP: 0010:myinit+0x18/0x30 [oops] RSP: 0018:ffffc900000d3cb0 EFLAGS: 00000282 RAX: 000000000000000b RBX: ffffffffc0000000 RCX: ffffffff81e3e3a8 RDX: 0000000000000001 RSI: 0000000000000086 RDI: ffffffffc0001033 RBP: ffffc900000d3e30 R08: 69796d2073706f6f R09: 000000000000013b R10: ffffea0000373280 R11: ffffffff822d8b2d R12: 0000000000000000 R13: ffffffffc0002050 R14: ffffffffc0002000 R15: ffff88000dc934c8 FS: 00007ffff7ff66a0(0000) GS:ffff88000fc00000(0000) knlGS:0000000000000000 CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 CR2: 0000000000000000 CR3: 000000000dcd2000 CR4: 00000000000006f0 Call Trace: do_one_initcall+0x3e/0x170 do_init_module+0x5b/0x210 load_module+0x2035/0x29d0 ? SyS_finit_module+0xa8/0xb0 SyS_finit_module+0xa8/0xb0 do_syscall_64+0x6f/0x310 ? trace_hardirqs_off_thunk+0x1a/0x32 entry_SYSCALL_64_after_hwframe+0x42/0xb7 RIP: 0033:0x7ffff7b36206 RSP: 002b:00007fffffffeb78 EFLAGS: 00000206 ORIG_RAX: 0000000000000139 RAX: ffffffffffffffda RBX: 000000000000005c RCX: 00007ffff7b36206 RDX: 0000000000000000 RSI: 000000000069e010 RDI: 0000000000000003 RBP: 000000000069e010 R08: 00007ffff7ddd320 R09: 0000000000000000 R10: 00007ffff7ddd320 R11: 0000000000000206 R12: 0000000000000003 R13: 00007fffffffef4b R14: 0000000000000000 R15: 0000000000000000 Code: <c7> 04 25 00 00 00 00 00 00 00 00 e8 b2 33 09 c1 31 c0 c3 0f 1f 44 RIP: myinit+0x18/0x30 [oops] RSP: ffffc900000d3cb0 CR2: 0000000000000000 ---[ end trace 3cdb4e9d9842b503 ]---
To find the line that oopsed, look at the RIP register:
RIP: 0010:myinit+0x18/0x30 [oops]
and then on GDB:
./run-gdb
run
info line *(myinit+0x18)
which gives us the correct line:
Line 7 of "/root/linux-kernel-module-cheat/out/kernel_modules/x86_64/kernel_modules/panic.c" starts at address 0xbf00001c <myinit+28> and ends at 0xbf00002c <myexit>.
This-did not work on arm due to GDB step debug kernel module insmodded by init on ARM so we need to either:
-
Kernel module stack trace to source line post-mortem method
17.6.3. dump_stack
The dump_stack function produces a stack trace much like panic and oops, but causes no problems and we return to the normal control flow, and can cleanly remove the module afterwards:
insmod dump_stack.ko
Source: kernel_modules/dump_stack.c
17.6.4. WARN_ON
The WARN_ON macro basically just calls dump_stack.
One extra side effect is that we can make it also panic with:
echo 1 > /proc/sys/kernel/panic_on_warn insmod warn_on.ko
Source: kernel_modules/warn_on.c
Can also be activated with the panic_on_warn boot parameter.
17.6.5. not syncing: VFS: Unable to mount root fs on unknown-block(0,0)
Let’s learn how to diagnose problems with the root filesystem not being found. TODO add a sample panic error message for each error type:
This is the diagnosis procedure.
First, if we remove the following options from the our kernel build:
CONFIG_VIRTIO_BLK=y CONFIG_VIRTIO_PCI=y
we get a message like this:
<4>[ 0.541708] VFS: Cannot open root device "vda" or unknown-block(0,0): error -6 <4>[ 0.542035] Please append a correct "root=" boot option; here are the available partitions: <0>[ 0.542562] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)
From the message, we notice that the kernel sees a disk of some sort (vda means a virtio disk), but it could not open it.
This means that the kernel cannot properly read any bytes from the disk.
And afterwards, it has an useless message here are the available partitions:, but of course we have no available partitions, the list is empty, because the kernel cannot even read bytes from the disk, so it definitely cannot understand its filesystems.
This can indicate basically two things:
-
on real hardware, it could mean that the hardware is broken. Kind of hard on emulators ;-)
-
you didn’t configure the kernel with the option that enables it to read from that kind of disk.
In our case, disks are virtio devices that QEMU exposes to the guest kernel. This is why removing the options:
CONFIG_VIRTIO_BLK=y CONFIG_VIRTIO_PCI=y
led to this error.
Now, let’s restore the previously removed virtio options, and instead remove:
CONFIG_EXT4_FS=y
This time, the kernel will be able to read bytes from the device. But it won’t be able to read files from the filesystem, because our filesystem is in ext4 format.
Therefore, this time the error message looks like this:
<4>[ 0.585296] List of all partitions: <4>[ 0.585913] fe00 524288 vda <4>[ 0.586123] driver: virtio_blk <4>[ 0.586471] No filesystem could mount root, tried: <4>[ 0.586497] squashfs <4>[ 0.586724] <0>[ 0.587360] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(254,0)
In this case, we see that the kernel did manage to read from the vda disk! It even told us how: by using the driver: virtio_blk.
However, it then went through the list of all filesystem types it knows how to read files from, in our case just squashf, and none of those worked, because our partition is an ext4 partition.
Finally, the last possible error is that we simply passed the wrong root= kernel CLI option. For example, if we hack our command to pass:
root=/dev/vda2
which does not even exist since /dev/vda is a raw non-partitioned ext4 image, then boot fails with a message:
<4>[ 0.608475] Please append a correct "root=" boot option; here are the available partitions: <4>[ 0.609563] fe00 524288 vda <4>[ 0.609723] driver: virtio_blk <0>[ 0.610433] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(254,2)
This one is easy, because the kernel tells us clearly which partitions it would have been able to understand. In our case /dev/vda.
Once all those problems are solved, in the working setup, we finally see something like:
<6>[ 0.636129] EXT4-fs (vda): mounted filesystem with ordered data mode. Opts: (null) <6>[ 0.636700] VFS: Mounted root (ext4 filesystem) on device 254:0.
Tested on LKMC 863a373a30cd3c7982e3e453c4153f85133b17a9, Linux kernel 5.4.3.
Bibliography:
17.7. Pseudo filesystems
Pseudo filesystems are filesystems that don’t represent actual files in a hard disk, but rather allow us to do special operations on filesystem-related system calls.
What each pseudo-file does for each related system call does is defined by its File operations.
Bibliography:
17.7.1. debugfs
Debugfs is the simplest pseudo filesystem to play around with:
./debugfs.sh echo $?
Outcome: the test passes:
0
Sources:
Debugfs is made specifically to help test kernel stuff. Just mount, set File operations, and we are done.
For this reason, it is the filesystem that we use whenever possible in our tests.
debugfs.sh explicitly mounts a debugfs at a custom location, but the most common mount point is /sys/kernel/debug.
This mount not done automatically by the kernel however: we, like most distros, do it from userland with our fstab.
Debugfs support requires the kernel to be compiled with CONFIG_DEBUG_FS=y.
Only the more basic file operations can be implemented in debugfs, e.g. mmap never gets called:
Bibliography: https://github.com/chadversary/debugfs-tutorial
17.7.2. procfs
Procfs is just another fops entry point:
./procfs.sh echo $?
Outcome: the test passes:
0
Procfs is a little less convenient than debugfs, but is more used in serious applications.
Procfs can run all system calls, including ones that debugfs can’t, e.g. mmap.
Sources:
Bibliography:
17.7.2.1. /proc/version
Its data is shared with uname(), which is a POSIX C function and has a Linux syscall to back it up.
Where the data comes from and how to modify it:
In this repo, leaking host information, and to make builds more reproducible, we are setting:
-
user and date to dummy values with
KBUILD_BUILD_USERandKBUILD_BUILD_TIMESTAMP -
hostname to the kernel git commit with
KBUILD_BUILD_HOSTandKBUILD_BUILD_VERSION
A sample result is:
Linux version 4.19.0-dirty (lkmc@84df9525b0c27f3ebc2ebb1864fa62a97fdedb7d) (gcc version 6.4.0 (Buildroot 2018.05-00002-gbc60382b8f)) #1 SMP Thu Jan 1 00:00:00 UTC 1970
17.7.3. sysfs
Sysfs is more restricted than procfs, as it does not take an arbitrary file_operations:
./sysfs.sh echo $?
Outcome: the test passes:
0
Sources:
Vs procfs:
You basically can only do open, close, read, write, and lseek on sysfs files.
It is similar to a seq_file file operation, except that write is also implemented.
TODO: what are those kobject structs? Make a more complex example that shows what they can do.
Bibliography:
17.7.4. Character devices
Character devices can have arbitrary File operations associated to them:
./character_device.sh echo $?
Outcome: the test passes:
0
Sources:
Unlike procfs entires, character device files are created with userland mknod or mknodat syscalls:
mknod </dev/path_to_dev> c <major> <minor>
Intuitively, for physical devices like keyboards, the major number maps to which driver, and the minor number maps to which device it is.
A single driver can drive multiple compatible devices.
The major and minor numbers can be observed with:
ls -l /dev/urandom
Output:
crw-rw-rw- 1 root root 1, 9 Jun 29 05:45 /dev/urandom
which means:
-
c(first letter): this is a character device. Would bebfor a block device. -
1, 9: the major number is1, and the minor9
To avoid device number conflicts when registering the driver we:
-
ask the kernel to allocate a free major number for us with:
register_chrdev(0 -
find ouf which number was assigned by grepping
/proc/devicesfor the kernel module name
Bibliography: https://unix.stackexchange.com/questions/37829/understanding-character-device-or-character-special-files/371758#371758
17.7.4.1. Automatically create character device file on insmod
And also destroy it on rmmod:
./character_device_create.sh echo $?
Outcome: the test passes:
0
Sources:
17.8. Pseudo files
17.8.1. File operations
File operations are the main method of userland driver communication that uses common file system calls such as read and write.
Through struct file_operations drivers tell the kernel what it should do on filesystem system calls of Pseudo filesystems.
17.8.1.1. fops.c
This example illustrates the most basic system calls: open, read, write, close and lseek.
In it we create a debugfs special file that behaves like a regular file, except that it is stored in memory for as long as the kernel module is loaded, and it has a fixed lengh of 4 bytes. Any longer write attempt gets simply truncated up at the end:
./fops.sh echo $?
Outcome: the test passes:
0
Then give this a try:
sh -x ./fops.sh
We have put printks on each fop, so this allows you to see which system calls are being made for each command.
No, there no official documentation: https://stackoverflow.com/questions/15213932/what-are-the-struct-file-operations-arguments
17.8.1.1.1. memfile.c
This example behaves the same as fops.c, except that the in-memory virtual file has unlimited size. In the kernel module we have therefore to so a bit of memory management and somehow increase the size of the buffer as needed.
TODO: this example builds but oopses with out of memory on our currently default kernel v5.9.2 when doing the big allocation at:
dd if=/dev/zero of="$f" bs=1k count=1M
It works however on kernel 6.8.12, we’re not sure why. We do have a potential krealloc vs kvrealloc on version check which is a very likely reason for the issue, but it has not been investigated.
17.8.2. seq_file
Writing trivial read File operations is repetitive and error prone. The seq_file API makes the process much easier for those trivial cases:
./seq_file.sh echo $?
Outcome: the test passes:
0
Sources:
In this example we create a debugfs file that behaves just like a file that contains:
0 1 2
However, we only store a single integer in memory and calculate the file on the fly in an iterator fashion.
seq_file does not provide write: https://stackoverflow.com/questions/30710517/how-to-implement-a-writable-proc-file-by-using-seq-file-in-a-driver-module
Bibliography:
17.8.2.1. seq_file single_open
If you have the entire read output upfront, single_open is an even more convenient version of seq_file:
./seq_file_single_open.sh echo $?
Outcome: the test passes:
0
Sources:
This example produces a debugfs file that behaves like a file that contains:
ab cd
17.8.3. poll
The poll system call allows an user process to do a non-busy wait on a kernel event.
Sources:
Example:
./poll.sh
Outcome: jiffies gets printed to stdout every second from userland, e.g.:
poll <6>[ 4.275305] poll <6>[ 4.275580] return POLLIN revents = 1 POLLIN n=10 buf=4294893337 poll <6>[ 4.276627] poll <6>[ 4.276911] return 0 <6>[ 5.271193] wake_up <6>[ 5.272326] poll <6>[ 5.273207] return POLLIN revents = 1 POLLIN n=10 buf=4294893588 poll <6>[ 5.276367] poll <6>[ 5.276618] return 0 <6>[ 6.275178] wake_up <6>[ 6.276370] poll <6>[ 6.277269] return POLLIN revents = 1 POLLIN n=10 buf=4294893839
Force the poll file_operation to return 0 to see what happens more clearly:
./poll.sh pol0=1
Sample output:
poll <6>[ 85.674801] poll <6>[ 85.675788] return 0 <6>[ 86.675182] wake_up <6>[ 86.676431] poll <6>[ 86.677373] return 0 <6>[ 87.679198] wake_up <6>[ 87.680515] poll <6>[ 87.681564] return 0 <6>[ 88.683198] wake_up
From this we see that control is not returned to userland: the kernel just keeps calling the poll file_operation again and again.
Typically, we are waiting for some hardware to make some piece of data available available to the kernel.
The hardware notifies the kernel that the data is ready with an interrupt.
To simplify this example, we just fake the hardware interrupts with a kthread that sleeps for a second in an infinite loop.
Bibliography:
17.8.4. ioctl
The ioctl system call is the best way to pass an arbitrary number of parameters to the kernel in a single go:
./ioctl.sh echo $?
Outcome: the test passes:
0
Sources:
ioctl is one of the most important methods of communication with real device drivers, which often take several fields as input.
ioctl takes as input:
-
an integer
request: it usually identifies what type of operation we want to do on this call -
an untyped pointer to memory: can be anything, but is typically a pointer to a
structThe type of the
structoften depends on therequestinputThis
structis defined on a uapi-style C header that is used both to compile the kernel module and the userland executable.The fields of this
structcan be thought of as arbitrary input parameters.
And the output is:
-
an integer return value.
man ioctldocuments:Usually, on success zero is returned. A few
ioctl()requests use the return value as an output parameter and return a nonnegative value on success. On error, -1 is returned, and errno is set appropriately. -
the input pointer data may be overwritten to contain arbitrary output
Bibliography:
17.8.5. mmap
The mmap system call allows us to share memory between user and kernel space without copying:
./mmap.sh echo $?
Outcome: the test passes:
0
Sources:
In this example, we make a tiny 4 byte kernel buffer available to user-space, and we then modify it on userspace, and check that the kernel can see the modification.
mmap, like most more complex File operations, does not work with debugfs as of 4.9, so we use a procfs file for it.
Example adapted from: https://coherentmusings.wordpress.com/2014/06/10/implementing-mmap-for-transferring-data-from-user-space-to-kernel-space/
Bibliography:
17.8.6. Anonymous inode
Anonymous inodes allow getting multiple file descriptors from a single filesystem entry, which reduces namespace pollution compared to creating multiple device files:
./anonymous_inode.sh echo $?
Outcome: the test passes:
0
Sources:
This example gets an anonymous inode via ioctl from a debugfs entry by using anon_inode_getfd.
Reads to that inode return the sequence: 1, 10, 100, … 10000000, 1, 100, …
17.8.7. netlink sockets
Netlink sockets offer a socket API for kernel / userland communication:
./netlink.sh echo $?
Outcome: the test passes:
0
Sources:
Launch multiple user requests in parallel to stress our socket:
insmod netlink.ko sleep=1 for i in `seq 16`; do ./netlink.out & done
TODO: what is the advantage over read, write and poll? https://stackoverflow.com/questions/16727212/how-netlink-socket-in-linux-kernel-is-different-from-normal-polling-done-by-appl
Bibliography:
17.9. kthread
Kernel threads are managed exactly like userland threads; they also have a backing task_struct, and are scheduled with the same mechanism:
insmod kthread.ko
Source: kernel_modules/kthread.c
Outcome: dmesg counts from 0 to 9 once every second infinitely many times:
0 1 2 ... 8 9 0 1 2 ...
The count stops when we rmmod:
rmmod kthread
The sleep is done with usleep_range, see: Section 17.9.2, “sleep”.
Bibliography:
17.9.1. kthreads
Let’s launch two threads and see if they actually run in parallel:
insmod kthreads.ko
Source: kernel_modules/kthreads.c
Outcome: two threads count to dmesg from 0 to 9 in parallel.
Each line has output of form:
<thread_id> <count>
Possible very likely outcome:
1 0 2 0 1 1 2 1 1 2 2 2 1 3 2 3
The threads almost always interleaved nicely, thus confirming that they are actually running in parallel.
17.9.2. sleep
Count to dmesg every one second from 0 up to n - 1:
insmod sleep.ko n=5
Source: kernel_modules/sleep.c
The sleep is done with a call to usleep_range directly inside module_init for simplicity.
Bibliography:
17.9.3. Workqueues
A more convenient front-end for kthread:
insmod workqueue_cheat.ko
Outcome: count from 0 to 9 infinitely many times
Stop counting:
rmmod workqueue_cheat
Source: kernel_modules/workqueue_cheat.c
The workqueue thread is killed after the worker function returns.
We can’t call the module just workqueue.c because there is already a built-in with that name: https://unix.stackexchange.com/questions/364956/how-can-insmod-fail-with-kernel-module-is-already-loaded-even-is-lsmod-does-not
17.9.3.1. Workqueue from workqueue
Count from 0 to 9 every second infinitely many times by scheduling a new work item from a work item:
insmod work_from_work.ko
Stop:
rmmod work_from_work
The sleep is done indirectly through: queue_delayed_work, which waits the specified time before scheduling the work.
Source: kernel_modules/work_from_work.c
17.9.4. schedule
Let’s block the entire kernel! Yay:
./run --eval-after 'dmesg -n 1;insmod schedule.ko schedule=0'
Outcome: the system hangs, the only way out is to kill the VM.
Source: kernel_modules/schedule.c
kthreads only allow interrupting if you call schedule(), and the schedule=0 kernel module parameter turns it off.
Sleep functions like usleep_range also end up calling schedule.
If we allow schedule() to be called, then the system becomes responsive:
./run --eval-after 'dmesg -n 1;insmod schedule.ko schedule=1'
and we can observe the counting with:
dmesg -w
The system also responds if we add another core:
./run --cpus 2 --eval-after 'dmesg -n 1;insmod schedule.ko schedule=0'
17.9.5. Wait queues
Wait queues are a way to make a thread sleep until an event happens on the queue:
insmod wait_queue.c
Dmesg output:
0 0 1 0 2 0 # Wait one second. 0 1 1 1 2 1 # Wait one second. 0 2 1 2 2 2 ...
Stop the count:
rmmod wait_queue
Source: kernel_modules/wait_queue.c
This example launches three threads:
-
one thread generates events every with
wake_up -
the other two threads wait for that with
wait_event, and print a dmesg when it happens.The
wait_eventmacro works a bit like:while (!cond) sleep_until_event
17.10. Timers
Count from 0 to 9 infinitely many times in 1 second intervals using timers:
insmod timer.ko
Stop counting:
rmmod timer
Source: kernel_modules/timer.c
Timers are callbacks that run when an interrupt happens, from the interrupt context itself.
Therefore they produce more accurate timing than thread scheduling, which is more complex, but you can’t do too much work inside of them.
Bibliography:
17.11. IRQ
17.11.1. irq.ko
Brute force monitor every shared interrupt that will accept us:
./run --eval-after 'insmod irq.ko' --graphic
Source: kernel_modules/irq.c.
Now try the following:
-
press a keyboard key and then release it after a few seconds
-
press a mouse key, and release it after a few seconds
-
move the mouse around
Outcome: dmesg shows which IRQ was fired for each action through messages of type:
handler irq = 1 dev = 250
dev is the character device for the module and never changes, as can be confirmed by:
grep lkmc_irq /proc/devices
The IRQs that we observe are:
-
1for keyboard press and release.If you hold the key down for a while, it starts firing at a constant rate. So this happens at the hardware level!
-
12mouse actions
This only works if for IRQs for which the other handlers are registered as IRQF_SHARED.
We can see which ones are those, either via dmesg messages of type:
genirq: Flags mismatch irq 0. 00000080 (myirqhandler0) vs. 00015a00 (timer) request_irq irq = 0 ret = -16 request_irq irq = 1 ret = 0
which indicate that 0 is not, but 1 is, or with:
cat /proc/interrupts
which shows:
0: 31 IO-APIC 2-edge timer 1: 9 IO-APIC 1-edge i8042, myirqhandler0
so only 1 has myirqhandler0 attached but not 0.
The QEMU monitor also has some interrupt statistics for x86_64:
./qemu-monitor info irq
TODO: properly understand how each IRQ maps to what number.
17.11.2. dummy-irq
The Linux kernel v4.16 mainline also has a dummy-irq module at drivers/misc/dummy-irq.c for monitoring a single IRQ.
We build it by default with:
CONFIG_DUMMY_IRQ=m
And then you can do
./run --graphic
and in guest:
modprobe dummy-irq irq=1
Outcome: when you click a key on the keyboard, dmesg shows:
dummy-irq: interrupt occurred on IRQ 1
However, this module is intended to fire only once as can be seen from its source:
static int count = 0;
if (count == 0) {
printk(KERN_INFO "dummy-irq: interrupt occurred on IRQ %d\n",
irq);
count++;
}
and furthermore interrupt 1 and 12 happen immediately TODO why, were they somehow pending?
17.11.3. /proc/interrupts
In the guest with QEMU graphic mode:
watch -n 1 cat /proc/interrupts
Then see how clicking the mouse and keyboard affect the interrupt counts.
This confirms that:
-
1: keyboard
-
12: mouse click and drags
The module also shows which handlers are registered for each IRQ, as we have observed at irq.ko
When in text mode, we can also observe interrupt line 4 with handler ttyS0 increase continuously as IO goes through the UART.
17.12. Kernel utility functions
17.12.1. kstrto
Convert a string to an integer:
./kstrto.sh echo $?
Outcome: the test passes:
0
Sources:
17.12.2. virt_to_phys
Convert a virtual address to physical:
insmod virt_to_phys.ko cat /sys/kernel/debug/lkmc_virt_to_phys
Source: kernel_modules/virt_to_phys.c
Sample output:
*kmalloc_ptr = 0x12345678 kmalloc_ptr = ffff88000e169ae8 virt_to_phys(kmalloc_ptr) = 0xe169ae8 static_var = 0x12345678 &static_var = ffffffffc0002308 virt_to_phys(&static_var) = 0x40002308
We can confirm that the kmalloc_ptr translation worked with:
./qemu-monitor 'xp 0xe169ae8'
which reads four bytes from a given physical address, and gives the expected:
000000000e169ae8: 0x12345678
TODO it only works for kmalloc however, for the static variable:
./qemu-monitor 'xp 0x40002308'
it gave a wrong value of 00000000.
Bibliography:
17.12.2.1. Userland physical address experiments
Only tested in x86_64.
The Linux kernel exposes physical addresses to userland through:
-
/proc/<pid>/maps -
/proc/<pid>/pagemap -
/dev/mem
In this section we will play with them.
The following files contain examples to access that data and test it out:
First get a virtual address to play with:
./posix/virt_to_phys_test.out &
Sample output:
vaddr 0x600800 pid 110
The program:
-
allocates a
volatilevariable and sets is value to0x12345678 -
prints the virtual address of the variable, and the program PID
-
runs a while loop until until the value of the variable gets mysteriously changed somehow, e.g. by nasty tinkerers like us
Then, translate the virtual address to physical using /proc/<pid>/maps and /proc/<pid>/pagemap:
./linux/virt_to_phys_user.out 110 0x600800
Sample output physical address:
0x7c7b800
Now we can verify that linux/virt_to_phys_user.out gave the correct physical address in the following ways:
Bibliography:
17.12.2.1.1. QEMU xp
The xp QEMU monitor command reads memory at a given physical address.
First launch linux/virt_to_phys_user.out as described at Userland physical address experiments.
On a second terminal, use QEMU to read the physical address:
./qemu-monitor 'xp 0x7c7b800'
Output:
0000000007c7b800: 0x12345678
Yes!!! We read the correct value from the physical address.
We could not find however to write to memory from the QEMU monitor, boring.
17.12.2.1.2. /dev/mem
/dev/mem exposes access to physical addresses, and we use it through the convenient devmem BusyBox utility.
First launch linux/virt_to_phys_user.out as described at Userland physical address experiments.
Next, read from the physical address:
devmem 0x7c7b800
Possible output:
Memory mapped at address 0x7ff7dbe01000. Value at address 0X7C7B800 (0x7ff7dbe01800): 0x12345678
which shows that the physical memory contains the expected value 0x12345678.
0x7ff7dbe01000 is a new virtual address that devmem maps to the physical address to be able to read from it.
Modify the physical memory:
devmem 0x7c7b800 w 0x9abcdef0
After one second, we see on the screen:
i 9abcdef0 [1]+ Done ./posix/virt_to_phys_test.out
so the value changed, and the while loop exited!
This example requires:
-
CONFIG_STRICT_DEVMEM=n, otherwisedevmemfails with:devmem: mmap: Operation not permitted
-
nopatkernel parameter
which we set by default.
17.12.2.1.3. pagemap_dump.out
Dump the physical address of all pages mapped to a given process using /proc/<pid>/maps and /proc/<pid>/pagemap.
First launch linux/virt_to_phys_user.out as described at Userland physical address experiments. Suppose that the output was:
# ./posix/virt_to_phys_test.out & vaddr 0x601048 pid 63 # ./linux/virt_to_phys_user.out 63 0x601048 0x1a61048
Now obtain the page map for the process:
./linux/pagemap_dump.out 63
Sample output excerpt:
vaddr pfn soft-dirty file/shared swapped present library 400000 1ede 0 1 0 1 ./posix/virt_to_phys_test.out 600000 1a6f 0 0 0 1 ./posix/virt_to_phys_test.out 601000 1a61 0 0 0 1 ./posix/virt_to_phys_test.out 602000 2208 0 0 0 1 [heap] 603000 220b 0 0 0 1 [heap] 7ffff78ec000 1fd4 0 1 0 1 /lib/libuClibc-1.0.30.so
Source:
Adapted from: https://github.com/dwks/pagemap/blob/8a25747bc79d6080c8b94eac80807a4dceeda57a/pagemap2.c
Meaning of the flags:
-
vaddr: first virtual address of a page the belongs to the process. Notably:./run-toolchain readelf -- -l "$(./getvar userland_build_dir)/posix/virt_to_phys_test.out"
contains:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flags Align ... LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000 0x000000000000075c 0x000000000000075c R E 0x200000 LOAD 0x0000000000000e98 0x0000000000600e98 0x0000000000600e98 0x00000000000001b4 0x0000000000000218 RW 0x200000 Section to Segment mapping: Segment Sections... ... 02 .interp .hash .dynsym .dynstr .rela.plt .init .plt .text .fini .rodata .eh_frame_hdr .eh_frame 03 .ctors .dtors .jcr .dynamic .got.plt .data .bssfrom which we deduce that:
-
400000is the text segment -
600000is the data segment
-
-
pfn: add three zeroes to it, and you have the physical address.Three zeroes is 12 bits which is 4kB, which is the size of a page.
For example, the virtual address
0x601000haspfnof0x1a61, which means that its physical address is0x1a61000This is consistent with what
linux/virt_to_phys_user.outtold us: the virtual address0x601048has physical address0x1a61048.048corresponds to the three last zeroes, and is the offset within the page.Also, this value falls inside
0x601000, which as previously analyzed is the data section, which is the normal location for global variables such as ours. -
soft-dirty: TODO -
file/shared: TODO.1seems to indicate that the page can be shared across processes, possibly for read-only pages? E.g. the text segment has1, but the data has0. -
swapped: TODO swapped to disk? -
present: TODO vs swapped? -
library: which executable owns that page
This program works in two steps:
-
parse the human readable lines lines from
/proc/<pid>/maps. This files contains lines of form:7ffff7b6d000-7ffff7bdd000 r-xp 00000000 fe:00 658 /lib/libuClibc-1.0.22.so
which tells us that:
-
7f8af99f8000-7f8af99ff000is a virtual address range that belong to the process, possibly containing multiple pages. -
/lib/libuClibc-1.0.22.sois the name of the library that owns that memory
-
-
loop over each page of each address range, and ask
/proc/<pid>/pagemapfor more information about that page, including the physical address
17.13. Linux kernel tracing
Good overviews:
-
http://www.brendangregg.com/blog/2015-07-08/choosing-a-linux-tracer.html by Brendan Greg, AKA the master of tracing. Also: https://github.com/brendangregg/perf-tools
I hope to have examples of all methods some day, since I’m obsessed with visibility.
17.13.1. CONFIG_PROC_EVENTS
Logs proc events such as process creation to a netlink socket.
We then have a userland program that listens to the events and prints them out:
# ./linux/proc_events.out & # set mcast listen ok # sleep 2 & sleep 1 fork: parent tid=48 pid=48 -> child tid=79 pid=79 fork: parent tid=48 pid=48 -> child tid=80 pid=80 exec: tid=80 pid=80 exec: tid=79 pid=79 # exit: tid=80 pid=80 exit_code=0 exit: tid=79 pid=79 exit_code=0 echo a a #
Source: userland/linux/proc_events.c
TODO: why exit: tid=79 shows after exit: tid=80?
Note how echo a is a Bash built-in, and therefore does not spawn a new process.
TODO: why does this produce no output?
./linux/proc_events.out >f &
TODO can you get process data such as UID and process arguments? It seems not since exec_proc_event contains so little data: https://github.com/torvalds/linux/blob/v4.16/include/uapi/linux/cn_proc.h#L80 We could try to immediately read it from /proc, but there is a risk that the process finished and another one took its PID, so it wouldn’t be reliable.
17.13.1.1. CONFIG_PROC_EVENTS aarch64
0111ca406bdfa6fd65a2605d353583b4c4051781 was failing with:
>>> kernel_modules 1.0 Building
/usr/bin/make -j8 -C '/linux-kernel-module-cheat//out/aarch64/buildroot/build/kernel_modules-1.0/user' BR2_PACKAGE_OPENBLAS="" CC="/linux-kernel-module-cheat//out/aarch64/buildroot/host/bin/aarch64-buildroot-linux-uclibc-gcc" LD="/linux-kernel-module-cheat//out/aarch64/buildroot/host/bin/aarch64-buildroot-linux-uclibc-ld"
/linux-kernel-module-cheat//out/aarch64/buildroot/host/bin/aarch64-buildroot-linux-uclibc-gcc -ggdb3 -fopenmp -O0 -std=c99 -Wall -Werror -Wextra -o 'proc_events.out' 'proc_events.c'
In file included from /linux-kernel-module-cheat//out/aarch64/buildroot/host/aarch64-buildroot-linux-uclibc/sysroot/usr/include/signal.h:329:0,
from proc_events.c:12:
/linux-kernel-module-cheat//out/aarch64/buildroot/host/aarch64-buildroot-linux-uclibc/sysroot/usr/include/sys/ucontext.h:50:16: error: field ‘uc_mcontext’ has incomplete type
mcontext_t uc_mcontext;
^~~~~~~~~~~
so we commented it out.
Related threads:
If we try to naively update uclibc to 1.0.29 with buildroot_override, which contains the above mentioned patch, clean aarch64 test build fails with:
../utils/ldd.c: In function 'elf_find_dynamic':
../utils/ldd.c:238:12: warning: cast to pointer from integer of different size [-Wint-to-pointer-cast]
return (void *)byteswap_to_host(dynp->d_un.d_val);
^
/tmp/user/20321/cciGScKB.o: In function `process_line_callback':
msgmerge.c:(.text+0x22): undefined reference to `escape'
/tmp/user/20321/cciGScKB.o: In function `process':
msgmerge.c:(.text+0xf6): undefined reference to `poparser_init'
msgmerge.c:(.text+0x11e): undefined reference to `poparser_feed_line'
msgmerge.c:(.text+0x128): undefined reference to `poparser_finish'
collect2: error: ld returned 1 exit status
Makefile.in:120: recipe for target '../utils/msgmerge.host' failed
make[2]: *** [../utils/msgmerge.host] Error 1
make[2]: *** Waiting for unfinished jobs....
/tmp/user/20321/ccF8V8jF.o: In function `process':
msgfmt.c:(.text+0xbf3): undefined reference to `poparser_init'
msgfmt.c:(.text+0xc1f): undefined reference to `poparser_feed_line'
msgfmt.c:(.text+0xc2b): undefined reference to `poparser_finish'
collect2: error: ld returned 1 exit status
Makefile.in:120: recipe for target '../utils/msgfmt.host' failed
make[2]: *** [../utils/msgfmt.host] Error 1
package/pkg-generic.mk:227: recipe for target '/data/git/linux-kernel-module-cheat/out/aarch64/buildroot/build/uclibc-custom/.stamp_built' failed
make[1]: *** [/data/git/linux-kernel-module-cheat/out/aarch64/buildroot/build/uclibc-custom/.stamp_built] Error 2
Makefile:79: recipe for target '_all' failed
make: *** [_all] Error 2
Buildroot master has already moved to uclibc 1.0.29 at f8546e836784c17aa26970f6345db9d515411700, but it is not yet in any tag… so I’m not tempted to update it yet just for this.
17.13.2. ftrace
Trace a single function:
cd /sys/kernel/debug/tracing/ # Stop tracing. echo 0 > tracing_on # Clear previous trace. echo > trace # List the available tracers, and pick one. cat available_tracers echo function > current_tracer # List all functions that can be traced # cat available_filter_functions # Choose one. echo __kmalloc > set_ftrace_filter # Confirm that only __kmalloc is enabled. cat enabled_functions echo 1 > tracing_on # Latest events. head trace # Observe trace continuously, and drain seen events out. cat trace_pipe &
Sample output:
# tracer: function
#
# entries-in-buffer/entries-written: 97/97 #P:1
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
head-228 [000] .... 825.534637: __kmalloc <-load_elf_phdrs
head-228 [000] .... 825.534692: __kmalloc <-load_elf_binary
head-228 [000] .... 825.534815: __kmalloc <-load_elf_phdrs
head-228 [000] .... 825.550917: __kmalloc <-__seq_open_private
head-228 [000] .... 825.550953: __kmalloc <-tracing_open
head-229 [000] .... 826.756585: __kmalloc <-load_elf_phdrs
head-229 [000] .... 826.756627: __kmalloc <-load_elf_binary
head-229 [000] .... 826.756719: __kmalloc <-load_elf_phdrs
head-229 [000] .... 826.773796: __kmalloc <-__seq_open_private
head-229 [000] .... 826.773835: __kmalloc <-tracing_open
head-230 [000] .... 827.174988: __kmalloc <-load_elf_phdrs
head-230 [000] .... 827.175046: __kmalloc <-load_elf_binary
head-230 [000] .... 827.175171: __kmalloc <-load_elf_phdrs
Trace all possible functions, and draw a call graph:
echo 1 > max_graph_depth echo 1 > events/enable echo function_graph > current_tracer
Sample output:
# CPU DURATION FUNCTION CALLS
# | | | | | | |
0) 2.173 us | } /* ntp_tick_length */
0) | timekeeping_update() {
0) 4.176 us | ntp_get_next_leap();
0) 5.016 us | update_vsyscall();
0) | raw_notifier_call_chain() {
0) 2.241 us | notifier_call_chain();
0) + 19.879 us | }
0) 3.144 us | update_fast_timekeeper();
0) 2.738 us | update_fast_timekeeper();
0) ! 117.147 us | }
0) | _raw_spin_unlock_irqrestore() {
0) 4.045 us | _raw_write_unlock_irqrestore();
0) + 22.066 us | }
0) ! 265.278 us | } /* update_wall_time */
TODO: what do + and ! mean?
Each enable under the events/ tree enables a certain set of functions, the higher the enable more functions are enabled.
TODO: can you get function arguments? https://stackoverflow.com/questions/27608752/does-ftrace-allow-capture-of-system-call-arguments-to-the-linux-kernel-or-only
17.13.3. Kprobes
kprobes is an instrumentation mechanism that injects arbitrary code at a given address in a trap instruction, much like GDB. Oh, the good old kernel. :-)
./build-linux --config 'CONFIG_KPROBES=y'
Then on guest:
insmod kprobe_example.ko sleep 4 & sleep 4 &'
Outcome: dmesg outputs on every fork:
<_do_fork> pre_handler: p->addr = 0x00000000e1360063, ip = ffffffff810531d1, flags = 0x246 <_do_fork> post_handler: p->addr = 0x00000000e1360063, flags = 0x246 <_do_fork> pre_handler: p->addr = 0x00000000e1360063, ip = ffffffff810531d1, flags = 0x246 <_do_fork> post_handler: p->addr = 0x00000000e1360063, flags = 0x246
Source: kernel_modules/kprobe_example.c
TODO: it does not work if I try to immediately launch sleep, why?
insmod kprobe_example.ko sleep 4 & sleep 4 &
I don’t think your code can refer to the surrounding kernel code however: the only visible thing is the value of the registers.
You can then hack it up to read the stack and read argument values, but do you really want to?
There is also a kprobes + ftrace based mechanism with CONFIG_KPROBE_EVENTS=y which does read the memory for us based on format strings that indicate type… https://github.com/torvalds/linux/blob/v4.16/Documentation/trace/kprobetrace.txt Horrendous. Used by: https://github.com/brendangregg/perf-tools/blob/98d42a2a1493d2d1c651a5c396e015d4f082eb20/execsnoop
Bibliography:
17.13.4. Count boot instructions
TODO: didn’t port during refactor after 3b0a343647bed577586989fb702b760bd280844a. Reimplementing should not be hard.
Results (boot not excluded) are shown at: Table 1, “Boot instruction counts for various setups”
| Commit | Arch | Simulator | Instruction count |
|---|---|---|---|
7228f75ac74c896417fb8c5ba3d375a14ed4d36b |
arm |
QEMU |
680k |
7228f75ac74c896417fb8c5ba3d375a14ed4d36b |
arm |
gem5 AtomicSimpleCPU |
160M |
7228f75ac74c896417fb8c5ba3d375a14ed4d36b |
arm |
gem5 HPI |
155M |
7228f75ac74c896417fb8c5ba3d375a14ed4d36b |
x86_64 |
QEMU |
3M |
7228f75ac74c896417fb8c5ba3d375a14ed4d36b |
x86_64 |
gem5 AtomicSimpleCPU |
528M |
QEMU:
./trace-boot --arch x86_64
sample output:
instructions 1833863 entry_address 0x1000000 instructions_firmware 20708
gem5:
./run --arch aarch64 --emulator gem5 --eval 'm5 exit' # Or: # ./run --arch aarch64 --emulator gem5 --eval 'm5 exit' -- --cpu-type=HPI --caches ./gem5-stat --arch aarch64 sim_insts
Notes:
-
0x1000000is the address where QEMU puts the Linux kernel at with-kernelin x86.It can be found from:
./run-toolchain readelf -- -e "$(./getvar vmlinux)" | grep Entry
TODO confirm further. If I try to break there with:
./run-gdb *0x1000000
but I have no corresponding source line. Also note that this line is not actually the first line, since the kernel messages such as
early console in extract_kernelhave already shown on screen at that point. This does not break at all:./run-gdb extract_kernel
It only appears once on every log I’ve seen so far, checked with
grep 0x1000000 trace.txtThen when we count the instructions that run before the kernel entry point, there is only about 100k instructions, which is insignificant compared to the kernel boot itself.
TODO
--arch armand--arch aarch64does not count firmware instructions properly because the entry point address of the ELF file (ffffff8008080000foraarch64) does not show up on the trace at all. Tested on f8c0502bb2680f2dbe7c1f3d7958f60265347005. -
We can also discount the instructions after
initruns by usingreadelfto get the initial address ofinit. One easy way to do that now is to just run:./run-gdb --userland "$(./getvar userland_build_dir)/linux/poweroff.out" main
And get that from the traces, e.g. if the address is
4003a0, then we search:grep -n 4003a0 trace.txt
I have observed a single match for that instruction, so it must be the init, and there were only 20k instructions after it, so the impact is negligible.
-
to disable networking. Is replacing
initenough?CONFIG_NET=ndid not significantly reduce instruction counts, so maybe replacinginitis enough. -
gem5 simulates memory latencies. So I think that the CPU loops idle while waiting for memory, and counts will be higher.
17.14. Linux kernel hardening
Make it harder to get hacked and easier to notice that you were, at the cost of some (small?) runtime overhead.
17.14.1. CONFIG_FORTIFY_SOURCE
Detects buffer overflows for us:
./build-linux --config 'CONFIG_FORTIFY_SOURCE=y' --linux-build-id fortify ./build-modules --clean ./build-modules ./build-buildroot ./run --eval-after 'insmod strlen_overflow.ko' --linux-build-id fortify
Possible dmesg output:
strlen_overflow: loading out-of-tree module taints kernel. detected buffer overflow in strlen ------------[ cut here ]------------
followed by a trace.
You may not get this error because this depends on strlen overflowing at least until the next page: if a random \0 appears soon enough, it won’t blow up as desired.
TODO not always reproducible. Find a more reproducible failure. I could not observe it on:
insmod memcpy_overflow.ko
Source: kernel_modules/strlen_overflow.c
17.14.2. Linux security modules
17.14.2.1. SELinux
TODO get a hello world permission control working:
./build-linux \ --config-fragment linux_config/selinux \ --linux-build-id selinux \ ; ./build-buildroot --config 'BR2_PACKAGE_REFPOLICY=y' ./run --enable-kvm --linux-build-id selinux
Source: linux_config/selinux
This builds:
-
BR2_PACKAGE_REFPOLICY, which includes a reference/etc/selinux/configpolicy: https://github.com/SELinuxProject/refpolicyrefpolicy in turn depends on:
-
BR2_PACKAGE_SETOOLS, which contains tools such asgetenforced: https://github.com/SELinuxProject/setoolssetools depends on:
-
BR2_PACKAGE_LIBSELINUX, which is the backing userland library
After boot finishes, we see:
Starting auditd: mkdir: invalid option -- 'Z'
which comes from /etc/init.d/S01auditd, because BusyBox' mkdir does not have the crazy -Z option like Ubuntu. That’s amazing!
The kernel logs contain:
SELinux: Initializing.
Inside the guest we now have:
getenforce
which initially says:
Disabled
TODO: if we try to enforce:
setenforce 1
it does not work and outputs:
setenforce: SELinux is disabled
SELinux requires glibc as mentioned at: Section 26.10, “libc choice”.
17.15. User mode Linux
I once got UML running on a minimal Buildroot setup at: https://unix.stackexchange.com/questions/73203/how-to-create-rootfs-for-user-mode-linux-on-fedora-18/372207#372207
But in part because it is dying, I didn’t spend much effort to integrate it into this repo, although it would be a good fit in principle, since it is essentially a virtualization method.
Maybe some brave soul will send a pull request one day.
17.16. UIO
UIO is a kernel subsystem that allows to do certain types of driver operations from userland.
This would be awesome to improve debuggability and safety of kernel modules.
VFIO looks like a newer and better UIO replacement, but there do not exist any examples of how to use it: https://stackoverflow.com/questions/49309162/interfacing-with-qemu-edu-device-via-userspace-i-o-uio-linux-driver
TODO get something interesting working. I currently don’t understand the behaviour very well.
TODO how to ACK interrupts? How to ensure that every interrupt gets handled separately?
TODO how to write to registers. Currently using /dev/mem and lspci.
This example should handle interrupts from userland and print a message to stdout:
./uio_read.sh
TODO: what is the expected behaviour? I should have documented this when I wrote this stuff, and I’m that lazy right now that I’m in the middle of a refactor :-)
UIO interface in a nutshell:
-
blocking read / poll: waits until interrupts
-
write: callirqcontrolcallback. Default: 0 or 1 to enable / disable interrupts. -
mmap: access device memory
Sources:
Bibliography:
-
https://stackoverflow.com/questions/15286772/userspace-vs-kernel-space-driver
-
https://01.org/linuxgraphics/gfx-docs/drm/driver-api/uio-howto.html
-
https://stackoverflow.com/questions/7986260/linux-interrupt-handling-in-user-space
-
https://yurovsky.github.io/2014/10/10/linux-uio-gpio-interrupt/
-
https://github.com/bmartini/zynq-axis/blob/65a3a448fda1f0ea4977adfba899eb487201853d/dev/axis.c
-
https://yurovsky.github.io/2014/10/10/linux-uio-gpio-interrupt/
-
http://nairobi-embedded.org/uio_example.html that website has QEMU examples for everything as usual. The example has a kernel-side which creates the memory mappings and is used by the user.
-
userland driver stability questions:
17.17. Linux kernel interactive stuff
17.17.1. Linux kernel console fun
Requires Graphics.
You can also try those on the Ctrl-Alt-F3 of your Ubuntu host, but it is much more fun inside a VM!
Stop the cursor from blinking:
echo 0 > /sys/class/graphics/fbcon/cursor_blink
Rotate the console 90 degrees! https://askubuntu.com/questions/237963/how-do-i-rotate-my-display-when-not-using-an-x-server
echo 1 > /sys/class/graphics/fbcon/rotate
Relies on: CONFIG_FRAMEBUFFER_CONSOLE_ROTATION=y.
Documented under: Documentation/fb/.
TODO: font and keymap. Mentioned at: https://cmcenroe.me/2017/05/05/linux-console.html and I think can be done with BusyBox loadkmap and loadfont, we just have to understand their formats, related:
17.17.2. Linux kernel magic keys
Requires Graphics.
Let’s have some fun.
I think most are implemented under:
drivers/tty
TODO find all.
Scroll up / down the terminal:
Shift-PgDown Shift-PgUp
Or inside ./qemu-monitor:
sendkey shift-pgup sendkey shift-pgdown
17.17.2.1. Ctrl Alt Del
If you run in QEMU graphic mode:
./run --graphic
and then from the graphic window you enter the keys:
Ctrl-Alt-Del
then this runs the following command on the guest:
/sbin/reboot
This is enabled from our rootfs_overlay/etc/inittab:
::ctrlaltdel:/sbin/reboot
This leads Linux to try to reboot, and QEMU shutdowns due to the -no-reboot option which we set by default for, see: Section 17.6.1.3, “Exit emulator on panic”.
Here is a minimal example of Ctrl Alt Del:
./run --kernel-cli 'init=/lkmc/linux/ctrl_alt_del.out' --graphic
Source: userland/linux/ctrl_alt_del.c
When you hit Ctrl-Alt-Del in the guest, our tiny init handles a SIGINT sent by the kernel and outputs to stdout:
cad
To map between man 2 reboot and the uClibc RB_* magic constants see:
less "$(./getvar buildroot_build_build_dir)"/uclibc-*/include/sys/reboot.h"
The procfs mechanism is documented at:
less linux/Documentation/sysctl/kernel.txt
which says:
When the value in this file is 0, ctrl-alt-del is trapped and sent to the init(1) program to handle a graceful restart. When, however, the value is > 0, Linux's reaction to a Vulcan Nerve Pinch (tm) will be an immediate reboot, without even syncing its dirty buffers. Note: when a program (like dosemu) has the keyboard in 'raw' mode, the ctrl-alt-del is intercepted by the program before it ever reaches the kernel tty layer, and it's up to the program to decide what to do with it.
Under the hood, behaviour is controlled by the reboot syscall:
man 2 reboot
reboot system calls can set either of the these behaviours for Ctrl-Alt-Del:
-
do a hard shutdown syscall. Set in uClibc C code with:
reboot(RB_ENABLE_CAD)
or from procfs with:
echo 1 > /proc/sys/kernel/ctrl-alt-del
Done by BusyBox'
reboot -f. -
send a SIGINT to the init process. This is what BusyBox' init does, and it then execs the string set in
inittab.Set in uclibc C code with:
reboot(RB_DISABLE_CAD)
or from procfs with:
echo 0 > /proc/sys/kernel/ctrl-alt-del
Done by BusyBox'
reboot.
When a BusyBox init is with the signal, it prints the following lines:
The system is going down NOW! Sent SIGTERM to all processes Sent SIGKILL to all processes Requesting system reboot
On busybox-1.29.2’s init at init/init.c we see how the kill signals are sent:
static void run_shutdown_and_kill_processes(void)
{
/* Run everything to be run at "shutdown". This is done _prior_
* to killing everything, in case people wish to use scripts to
* shut things down gracefully... */
run_actions(SHUTDOWN);
message(L_CONSOLE | L_LOG, "The system is going down NOW!");
/* Send signals to every process _except_ pid 1 */
kill(-1, SIGTERM);
message(L_CONSOLE, "Sent SIG%s to all processes", "TERM");
sync();
sleep(1);
kill(-1, SIGKILL);
message(L_CONSOLE, "Sent SIG%s to all processes", "KILL");
sync();
/*sleep(1); - callers take care about making a pause */
}
and run_shutdown_and_kill_processes is called from:
/* The SIGPWR/SIGUSR[12]/SIGTERM handler */ static void halt_reboot_pwoff(int sig) NORETURN; static void halt_reboot_pwoff(int sig)
which also prints the final line:
message(L_CONSOLE, "Requesting system %s", m);
which is set as the signal handler via TODO.
Bibliography:
17.17.2.2. SysRq
We cannot test these actual shortcuts on QEMU since the host captures them at a lower level, but from:
./qemu-monitor
we can for example crash the system with:
sendkey alt-sysrq-c
Same but boring because no magic key:
echo c > /proc/sysrq-trigger
Implemented in:
drivers/tty/sysrq.c
On your host, on modern systems that don’t have the SysRq key you can do:
Alt-PrtSc-space
which prints a message to dmesg of type:
sysrq: SysRq : HELP : loglevel(0-9) reboot(b) crash(c) terminate-all-tasks(e) memory-full-oom-kill(f) kill-all-tasks(i) thaw-filesystems(j) sak(k) show-backtrace-all-active-cpus(l) show-memory-usage(m) nice-all-RT-tasks(n) poweroff(o) show-registers(p) show-all-timers(q) unraw(r) sync(s) show-task-states(t) unmount(u) show-blocked-tasks(w) dump-ftrace-buffer(z)
Individual SysRq can be enabled or disabled with the bitmask:
/proc/sys/kernel/sysrq
The bitmask is documented at:
less linux/Documentation/admin-guide/sysrq.rst
Bibliography: https://en.wikipedia.org/wiki/Magic_SysRq_key
17.17.3. TTY
In order to play with TTYs, do this:
printf ' tty2::respawn:/sbin/getty -n -L -l /lkmc/loginroot.sh tty2 0 vt100 tty3::respawn:-/bin/sh tty4::respawn:/sbin/getty 0 tty4 tty63::respawn:-/bin/sh ::respawn:/sbin/getty -L ttyS0 0 vt100 ::respawn:/sbin/getty -L ttyS1 0 vt100 ::respawn:/sbin/getty -L ttyS2 0 vt100 # Leave one serial empty. #::respawn:/sbin/getty -L ttyS3 0 vt100 ' >> rootfs_overlay/etc/inittab ./build-buildroot ./run --graphic -- \ -serial telnet::1235,server,nowait \ -serial vc:800x600 \ -serial telnet::1236,server,nowait \ ;
and on a second shell:
telnet localhost 1235
We don’t add more TTYs by default because it would spawn more processes, even if we use askfirst instead of respawn.
On the GUI, switch TTYs with:
-
Alt-LeftorAlt-Right:go to previous / next populated/dev/ttyNTTY. Skips over empty TTYs. -
Alt-Fn: go to the nth TTY. If it is not populated, don’t go there. -
chvt <n>: go to the n-th virtual TTY, even if it is empty: https://superuser.com/questions/33065/console-commands-to-change-virtual-ttys-in-linux-and-openbsd
You can also test this on most hosts such as Ubuntu 18.04, except that when in the GUI, you must use Ctrl-Alt-Fx to switch to another terminal.
Next, we also have the following shells running on the serial ports, hit enter to activate them:
-
/dev/ttyS0: first shell that was used to run QEMU, corresponds to QEMU’s-serial mon:stdio.It would also work if we used
-serial stdio, but:-
Ctrl-Cwould kill QEMU instead of going to the guest -
Ctrl-A Cwouldn’t open the QEMU console there
-
-
/dev/ttyS1: second shell runningtelnet -
/dev/ttyS2: go on the GUI and enterCtrl-Alt-2, corresponds to QEMU’s-serial vc. Go back to the main console withCtrl-Alt-1.
although we cannot change between terminals from there.
Each populated TTY contains a "shell":
-
-/bin/sh: goes directly into anshwithout a login prompt.The trailing dash
-can be used on any command. It makes the command that follows take over the TTY, which is what we typically want for interactive shells: https://askubuntu.com/questions/902998/how-to-check-which-tty-am-i-usingThe
gettyexecutable however also does this operation and therefore dispenses the-. -
/sbin/gettyasks for password, and then gives you anshWe can overcome the password prompt with the
-l /lkmc/loginroot.shtechnique explained at: https://askubuntu.com/questions/902998/how-to-check-which-tty-am-i-using but I don’t see any advantage over-/bin/shcurrently.
Identify the current TTY with the command:
tty
Bibliography:
-
https://unix.stackexchange.com/questions/270272/how-to-get-the-tty-in-which-bash-is-running/270372
-
https://unix.stackexchange.com/questions/187319/how-to-get-the-real-name-of-the-controlling-terminal
-
https://unix.stackexchange.com/questions/77796/how-to-get-the-current-terminal-name
-
https://askubuntu.com/questions/902998/how-to-check-which-tty-am-i-using
This outputs:
-
/dev/consolefor the initial GUI terminal. But I think it is the same as/dev/tty1, because if I try to dotty1::respawn:-/bin/sh
it makes the terminal go crazy, as if multiple processes are randomly eating up the characters.
-
/dev/ttyNfor the other graphic TTYs. Note that there are only 63 available ones, from/dev/tty1to/dev/tty63(/dev/tty0is the current one): https://superuser.com/questions/449781/why-is-there-so-many-linux-dev-tty. I think this is determined by:#define MAX_NR_CONSOLES 63
in
linux/include/uapi/linux/vt.h. -
/dev/ttySNfor the text shells.These are Serial ports, see this to understand what those represent physically: https://unix.stackexchange.com/questions/307390/what-is-the-difference-between-ttys0-ttyusb0-and-ttyama0-in-linux/367882#367882
There are only 4 serial ports, I think this is determined by QEMU. TODO check.
Get the TTY in bulk for all processes:
./psa.sh
Source: rootfs_overlay/lkmc/psa.sh.
The TTY appears under the TT section, which is enabled by -o tty. This shows the TTY device number, e.g.:
4,1
and we can then confirm it with:
ls -l /dev/tty1
Next try:
insmod kthread.ko
and switch between virtual terminals, to understand that the dmesg goes to whatever current virtual terminal you are on, but not the others, and not to the serial terminals.
Bibliography:
17.17.3.1. Start a getty from outside of init
TODO: how to place an sh directly on a TTY as well without getty?
If I try the exact same command that the inittab is doing from a regular shell after boot:
/sbin/getty 0 tty1
it fails with:
getty: setsid: Operation not permitted
The following however works:
./run --eval 'getty 0 tty1 & getty 0 tty2 & getty 0 tty3 & sleep 99999999' --graphic
presumably because it is being called from init directly?
Outcome: Alt-Right cycles between three TTYs, tty1 being the default one that appears under the boot messages.
man 2 setsid says that there is only one failure possibility:
EPERM The process group ID of any process equals the PID of the calling process. Thus, in particular, setsid() fails if the calling process is already a process group leader.
We can get some visibility into it to try and solve the problem with:
./psa.sh
17.17.3.2. console kernel boot parameter
Take the command described at TTY and try adding the following:
-
-e 'console=tty7': boot messages still show on/dev/tty1(TODO how to change that?), but we don’t get a shell at the end of boot there.Instead, the shell appears on
/dev/tty7. -
-e 'console=tty2'like/dev/tty7, but/dev/tty2is broken, because we have two shells there:-
one due to the
::respawn:-/bin/shentry which uses whateverconsolepoints to -
another one due to the
tty2::respawn:/sbin/gettyentry we added
-
-
-e 'console=ttyS0'much liketty2, but messages show only on serial, and the terminal is broken due to having multiple shells on it -
-e 'console=tty1 console=ttyS0': boot messages show on bothtty1andttyS0, but onlyS0gets a shell because it came last
17.17.4. CONFIG_LOGO
If you run in Graphics, then you get a Penguin image for every core above the console! https://askubuntu.com/questions/80938/is-it-possible-to-get-the-tux-logo-on-the-text-based-boot
This is due to the CONFIG_LOGO=y option which we enable by default.
reset on the terminal then kills the poor penguins.
When CONFIG_LOGO=y is set, the logo can be disabled at boot with:
./run --kernel-cli 'logo.nologo'
Looks like a recompile is needed to modify the image…
17.18. DRM
DRM / DRI is the new interface that supersedes fbdev:
./build-buildroot --config 'BR2_PACKAGE_LIBDRM=y' ./build-userland --package libdrm -- userland/libs/libdrm/modeset.c ./run --eval-after './libs/libdrm/modeset.out' --graphic
Source: userland/libs/libdrm/modeset.c
Outcome: for a few seconds, the screen that contains the terminal gets taken over by changing colors of the rainbow.
TODO not working for aarch64, it takes over the screen for a few seconds and the kernel messages disappear, but the screen stays black all the time.
./build-buildroot --config 'BR2_PACKAGE_LIBDRM=y' ./build-userland --package libdrm ./build-buildroot ./run --eval-after './libs/libdrm/modeset.out' --graphic
kmscube however worked, which means that it must be a bug with this demo?
We set CONFIG_DRM=y on our default kernel configuration, and it creates one device file for each display:
# ls -l /dev/dri total 0 crw------- 1 root root 226, 0 May 28 09:41 card0 # grep 226 /proc/devices 226 drm # ls /sys/module/drm /sys/module/drm_kms_helper/
Try creating new displays:
./run --arch aarch64 --graphic -- -device virtio-gpu-pci
to see multiple /dev/dri/cardN, and then use a different display with:
./run --eval-after './libs/libdrm/modeset.out' --graphic
Bibliography:
Tested on: 93e383902ebcc03d8a7ac0d65961c0e62af9612b
17.18.1. kmscube
./build-buildroot --config-fragment buildroot_config/kmscube
Outcome: a colored spinning cube coded in OpenGL + EGL takes over your display and spins forever: https://www.youtube.com/watch?v=CqgJMgfxjsk
It is a bit amusing to see OpenGL running outside of a window manager window like that: https://stackoverflow.com/questions/3804065/using-opengl-without-a-window-manager-in-linux/50669152#50669152
TODO: it is very slow, about 1FPS. I tried Buildroot master ad684c20d146b220dd04a85dbf2533c69ec8ee52 with:
make qemu_x86_64_defconfig printf " BR2_CCACHE=y BR2_PACKAGE_HOST_QEMU=y BR2_PACKAGE_HOST_QEMU_LINUX_USER_MODE=n BR2_PACKAGE_HOST_QEMU_SYSTEM_MODE=y BR2_PACKAGE_HOST_QEMU_VDE2=y BR2_PACKAGE_KMSCUBE=y BR2_PACKAGE_MESA3D=y BR2_PACKAGE_MESA3D_DRI_DRIVER_SWRAST=y BR2_PACKAGE_MESA3D_OPENGL_EGL=y BR2_PACKAGE_MESA3D_OPENGL_ES=y BR2_TOOLCHAIN_BUILDROOT_CXX=y " >> .config
and the FPS was much better, I estimate something like 15FPS.
On Ubuntu 18.04 with NVIDIA proprietary drivers:
sudo apt-get instll kmscube kmscube
fails with:
drmModeGetResources failed: Invalid argument failed to initialize legacy DRM
See also:
Tested on: 2903771275372ccfecc2b025edbb0d04c4016930
17.18.2. kmscon
TODO get working.
Implements a console for DRM.
The Linux kernel has a built-in fbdev console called Linux kernel console fun but not for DRM it seems.
The upstream project seems dead with last commit in 2014: https://www.freedesktop.org/wiki/Software/kmscon/
Build failed in Ubuntu 18.04 with: https://github.com/dvdhrm/kmscon/issues/131 but this fork compiled but didn’t run on host: https://github.com/Aetf/kmscon/issues/2#issuecomment-392484043
Haven’t tested the fork on QEMU too much insanity.
17.18.3. libdri2
TODO get working.
Looks like a more raw alternative to libdrm:
./build-buildroot --config 'BR2_PACKABE_LIBDRI2=y' wget \ -O "$(./getvar userland_source_dir)/dri2test.c" \ https://raw.githubusercontent.com/robclark/libdri2/master/test/dri2test.c \ ; ./build-userland
but then I noticed that that example requires multiple files, and I don’t feel like integrating it into our build.
When I build it on Ubuntu 18.04 host, it does not generate any executable, so I’m confused.
17.19. Linux kernel testing
17.19.1. Linux Test Project
Tests a lot of Linux and POSIX userland visible interfaces.
Buildroot already has a package, so it is trivial to build it:
./build-buildroot --config 'BR2_PACKAGE_LTP_TESTSUITE=y'
So now let’s try and see if the exit system call is working:
/usr/lib/ltp-testsuite/testcases/bin/exit01
which gives successful output:
exit01 1 TPASS : exit() test PASSED
and has source code at: https://github.com/linux-test-project/ltp/blob/20190115/testcases/kernel/syscalls/exit/exit01.c
Besides testing any kernel modifications you make, LTP can also be used to the system call implementation of User mode simulation as shown at User mode Buildroot executables:
./run --userland "$(./getvar buildroot_target_dir)/usr/lib/ltp-testsuite/testcases/bin/exit01"
Tested at: 287c83f3f99db8c1ff9bbc85a79576da6a78e986 + 1.
17.19.2. stress
POSIX userland stress. Two versions:
./build-buildroot \ --config 'BR2_PACKAGE_STRESS=y' \ --config 'BR2_PACKAGE_STRESS_NG=y' \ ;
STRESS_NG is likely the best, but it requires glibc, see: Section 26.10, “libc choice”.
Websites:
stress usage:
stress --help stress -c 16 & ps
and notice how 16 threads were created in addition to a parent worker thread.
It just runs forever, so kill it when you get tired:
kill %1
stress -c 1 -t 1 makes gem5 irresponsive for a very long time.
17.20. Linux kernel build system
17.20.1. vmlinux vs bzImage vs zImage vs Image
Between all archs on QEMU and gem5 we touch all of those kernel built output files.
We are trying to maintain a description of each at: https://unix.stackexchange.com/questions/5518/what-is-the-difference-between-the-following-kernel-makefile-terms-vmlinux-vml/482978#482978
QEMU does not seem able to boot ELF files like vmlinux: https://superuser.com/questions/1376944/can-qemu-boot-linux-from-vmlinux-instead-of-bzimage
Converting arch/* images to vmlinux is possible in theory x86 with extract-vmlinux but we didn’t get any gem5 boots working from images generated like that for some reason, see: https://github.com/cirosantilli/linux-kernel-module-cheat/issues/79
17.21. Virtio
Virtio is an interface that guest machines can use to efficiently use resources from host machines.
The types of resources it supports are for disks and networking hardware.
This interface is not like the real interface used by the host to read from real disks and network devices.
Rather, it is a simplified interface, that makes those operations simpler and faster since guest and host work together knowing that this is an emulation use case.
17.22. Kernel modules
17.22.1. dump_regs
The following kernel modules and Baremetal executables dump and disassemble various registers which cannot be observed from userland (usually "system registers", "control registers"):
Some of those programs are using:
Alternatively, you can also get their value from inside GDB step debug with:
info registers all
or the short version:
i r a
or to get just specific registers, e.g. just ARMv8’s SCTLR:
i r SCTLR
but it is sometimes just more convenient to run an executable to get the registers at the point of interest.
See also:
17.22.2. scull
This kernel module is a port of scull example from LDD3. It was tested on LKMC e1834763088b8a7532b5fae800039de880471f2d + 1 with Linux kernel 6.8.12.
"Scull" is an acronym for "Simple Character Utility for Loading Localities". This expansion is mostly meaningless however, but there you are.
Source code:
Create the devices and test them:
scull.sh
scull creates several character devices.
The most "basic" one is /dev/scull0, which acts a bit as an in-memory file, except that it has weird quantizations applied to it so that you can’t append as normal and it doesn’t really look like a regular file. What it actually is more like is an object pool.
The original scull interface is very weird and would erase all data on write-only O_WRONLY, but not on read/write O_RDWR, which doesn’t make much sense:
int scull_open(struct inode *inode, struct file *filp) {
if ( (filp->f_flags & O_ACCMODE) == O_WRONLY)
scull_trim(dev); /* ignore errors */
We have modified that to the much more reasonable:
if ((filp->f_flags & O_TRUNC)) {
The old weird truncation condition makes the code hard to test as there is no way to write to two different blocks like it and keep them both in memory, unless you are able to find a CLI tool that supports O_RDWR or you write a C program to test things.
With our new inferface, we can differentiate clear all vs don’t clear all in the usual manner, e.g. this clears:
echo asdf > /dev/scull0
but this doesn’t:
echo asdf >> /dev/scull0
The examples from our test should make its weird behavior clearer e.g.:
# Append starts writing from the start of the 4k block, not like the usual semantic.
printf asdf > "$f"
printf qw >> "$f"
[ "$(cat "$f")" = qwdf ]
# Overwrite first clears everything, then writes to start of 4k block.
printf asdf > /dev/${module}0
printf qw > /dev/${module}0
[ "$(cat "$f")" = qw ]
# Read from the middle
printf asdf > /dev/${module}0
[ "$(dd if="$f" bs=1 count=2 skip=2 status=none)" = df ]
# Write to the middle
printf asdf > /dev/${module}0
printf we | dd of="$f" bs=1 seek=1 conv=notrunc status=none
[ "$(cat "$f")" = aqwf ]
It is also worth noting that the implementation of scull is meant to be "readable" but not optimal:
kmalloc is not the most efficient way to allocate large areas of memory (see Chapter 8), so the implementation chosen for scull is not a particularly smart one. The source code for a smart implementation would be more difficult to read, and the aim of this section is to show read and write, not memory management. That’s why the code just uses kmalloc and kfree without resorting to allocation of whole pages, although that approach would be more efficient.
Another shortcoming of the example is that it uses mutexes, where rwsem would be the clearly superior choice.
This module was derived from https://github.com/martinezjavier/ldd3/tree/30f801cd0157e8dfb41193f471dc00d8ca10239f/scull which had already ported it to much more recent kernel versions for us. Ideally we should just use that repo as a submodule, but we were lazy to setup the buildroot properly for now, and decided to dump it all into a single file to start with.
18. FreeBSD
Prebuilt on Ubuntu 20.04 worked: https://stackoverflow.com/questions/49656395/how-to-boot-freebsd-image-under-qemu/64027161#64027161
TODO minimal build + boot on QEMU example anywhere???
19. RTOS
19.1. Zephyr
Zephyr is an RTOS that has POSIX support. I think it works much like our Baremetal setup which uses Newlib and generates individual ELF files that contain both our C program’s code, and the Zephyr libraries.
TODO get a hello world working, and then consider further integration in this repo, e.g. being able to run all C userland content on it.
TODO: Cortex-A CPUs are not currently supported, there are some qemu_cortex_m0 boards, but can’t find a QEMU Cortex-A. There is an x86_64 qemu board, but we don’t currently have an x86 baremetal toolchain. For this reason, we won’t touch this further for now.
However, unlike Newlib, Zephyr must be setting up a simple pre-main runtime to be able to handle threads.
Failed attempt:
# https://askubuntu.com/questions/952429/is-there-a-good-ppa-for-cmake-backports wget -O - https://apt.kitware.com/keys/kitware-archive-latest.asc 2>/dev/null | sudo apt-key add - sudo apt-add-repository 'deb https://apt.kitware.com/ubuntu/ bionic-rc main' sudo apt-get update sudo apt-get install cmake git clone https://github.com/zephyrproject-rtos/zephyr pip3 install --user -U west packaging cd zephyr git checkout v1.14.1 west init zephyrproject west update export ZEPHYR_TOOLCHAIN_VARIANT=xtools export XTOOLS_TOOLCHAIN_PATH="$(pwd)/out/crosstool-ng/build/default/install/aarch64/bin/" source zephyr-env.sh west build -b qemu_aarch64 samples/hello_world
The build system of that project is a bit excessive / wonky. You need an edge CMake not present in Ubuntu 18.04, which I don’t want to install right now, and it uses the weird custom west build tool frontend.
20. Xen
TODO: get prototype working and then properly integrate:
./build-xen
Source: build-xen
This script attempts to build Xen for aarch64 and feed it into QEMU through submodules/boot-wrapper-aarch64
TODO: other archs not yet attempted.
The current bad behaviour is that it prints just:
Boot-wrapper v0.2
and nothing else.
We will also need CONFIG_XEN=y on the Linux kernel, but first Xen should print some Xen messages before the kernel is ever reached.
If we pass to QEMU the xen image directly instead of the boot wrapper one:
-kernel ../xen/xen/xen
then Xen messages do show up! So it seems that the configuration failure lies in the boot wrapper itself rather than Xen.
Maybe it is also possible to run Xen directly like this: QEMU can already load multiple images at different memory locations with the generic loader: https://github.com/qemu/qemu/blob/master/docs/generic-loader.txt which looks something along:
-kernel file1.elf -device loader,file=file2.elf
so as long as we craft the correct DTB and feed it into Xen so that it can see the kernel, it should work. TODO does QEMU support patching the auto-generated DTB with pre-generated options? In the worst case we can just dump it hand hack it up though with -machine dumpdtb, see: Section 9.4, “Device tree emulator generation”.
Bibliography:
-
this attempt was based on: https://wiki.xenproject.org/wiki/Xen_ARM_with_Virtualization_Extensions/FastModels which is the documentation for the ARM Fast Models closed source simulators.
-
https://wiki.xenproject.org/wiki/Xen_ARM_with_Virtualization_Extensions/qemu-system-aarch64 this is the only QEMU aarch64 Xen page on the web. It uses the Ubuntu aarc64 image, which has EDK2.
I however see no joy on blobs. Buildroot does not seem to support EDK 2.
21. U-Boot
U-Boot is a popular bootloader.
It can read disk filesystems, and Buildroot supports it, so we could in theory put it into memory, and let it find a kernel image from the root filesystem and boot that, but I didn’t manage to get it working yet: https://stackoverflow.com/questions/58028789/how-to-boot-linux-aarch64-with-u-boot-with-buildroot-on-qemu
23. QEMU
23.1. Introduction to QEMU
QEMU is a system simulator: it simulates a CPU and devices such as interrupt handlers, timers, UART, screen, keyboard, etc.
If you are familiar with VirtualBox, then QEMU then basically does the same thing: it opens a "window" inside your desktop that can run an operating system inside your operating system.
Also both can use very similar techniques: either Binary translation or KVM. VirtualBox' binary translator is / was based on QEMU’s it seems: https://en.wikipedia.org/wiki/VirtualBox#Software-based_virtualization
The huge advantage of QEMU over VirtualBox is that is supports cross arch simulation, e.g. simulate an ARM guest on an x86 host.
QEMU is likely the leading cross arch system simulator as of 2018. It is even the default Android simulator that developers get with Android Studio 3 to develop apps without real hardware.
Another advantage of QEMU over virtual box is that it doesn’t have Oracle' hands all all over it, more like RedHat + ARM.
Another advantage of QEMU is that is has no nice configuration GUI. Because who needs GUIs when you have 50 million semi-documented CLI options? Android Studio adds a custom GUI configuration tool on top of it.
QEMU is also supported by Buildroot in-tree, see e.g.: https://github.com/buildroot/buildroot/blob/2018.05/configs/qemu_aarch64_virt_defconfig We however just build our own manually with build-qemu, as it gives more flexibility, and building QEMU is very easy!
All of this makes QEMU the natural choice of reference system simulator for this repo.
23.3. Disk persistency
We disable disk persistency for both QEMU and gem5 by default, to prevent the emulator from putting the image in an unknown state.
For QEMU, this is done by passing the snapshot option to -drive, and for gem5 it is the default behaviour.
If you hack up our run script to remove that option, then:
./run --eval-after 'date >f;poweroff'
followed by:
./run --eval-after 'cat f'
gives the date, because poweroff without -n syncs before shutdown.
The sync command also saves the disk:
sync
When you do:
./build-buildroot
the disk image gets overwritten by a fresh filesystem and you lose all changes.
Remember that if you forcibly turn QEMU off without sync or poweroff from inside the VM, e.g. by closing the QEMU window, disk changes may not be saved.
Persistency is also turned off when booting from initrd with a CPIO instead of with a disk.
Disk persistency is useful to re-run shell commands from the history of a previous session with Ctrl-R, but we felt that the loss of determinism was not worth it.
23.3.1. gem5 disk persistency
TODO how to make gem5 disk writes persistent?
As of cadb92f2df916dbb47f428fd1ec4932a2e1f0f48 there are some read_only entries in the gem5 config.ini under cow sections, but hacking them to true did not work:
diff --git a/configs/common/FSConfig.py b/configs/common/FSConfig.py
index 17498c42b..76b8b351d 100644
--- a/configs/common/FSConfig.py
+++ b/configs/common/FSConfig.py
@@ -60,7 +60,7 @@ os_types = { 'alpha' : [ 'linux' ],
}
class CowIdeDisk(IdeDisk):
- image = CowDiskImage(child=RawDiskImage(read_only=True),
+ image = CowDiskImage(child=RawDiskImage(read_only=False),
read_only=False)
def childImage(self, ci):
The directory of interest is src/dev/storage.
23.4. gem5 qcow2
qcow2 does not appear supported, there are not hits in the source tree, and there is a mention on Nate’s 2009 wishlist: http://gem5.org/Nate%27s_Wish_List
This would be good to allow storing smaller sparse ext2 images locally on disk.
23.5. Snapshot
QEMU allows us to take snapshots at any time through the monitor.
You can then restore CPU, memory and disk state back at any time.
qcow2 filesystems must be used for that to work.
To test it out, login into the VM with and run:
./run --eval-after 'umount /mnt/9p/*;./count.sh'
On another shell, take a snapshot:
./qemu-monitor savevm my_snap_id
The counting continues.
Restore the snapshot:
./qemu-monitor loadvm my_snap_id
and the counting goes back to where we saved. This shows that CPU and memory states were reverted.
The umount is needed because snapshotting conflicts with 9P, which we felt is a more valuable default. If you forget to unmount, the following error appears on the QEMU monitor:
Migration is disabled when VirtFS export path '/linux-kernel-module-cheat/out/x86_64/buildroot/build' is mounted in the guest using mount_tag 'host_out'
We can also verify that the disk state is also reversed. Guest:
echo 0 >f
Monitor:
./qemu-monitor savevm my_snap_id
Guest:
echo 1 >f
Monitor:
./qemu-monitor loadvm my_snap_id
Guest:
cat f
And the output is 0.
Our setup does not allow for snapshotting while using initrd.
Bibliography: https://stackoverflow.com/questions/40227651/does-qemu-emulator-have-checkpoint-function/48724371#48724371
23.5.1. Snapshot internals
Snapshots are stored inside the .qcow2 images themselves.
They can be observed with:
"$(./getvar buildroot_host_dir)/bin/qemu-img" info "$(./getvar qcow2_file)"
which after savevm my_snap_id and savevm asdf contains an output of type:
image: out/x86_64/buildroot/images/rootfs.ext2.qcow2
file format: qcow2
virtual size: 512M (536870912 bytes)
disk size: 180M
cluster_size: 65536
Snapshot list:
ID TAG VM SIZE DATE VM CLOCK
1 my_snap_id 47M 2018-04-27 21:17:50 00:00:15.251
2 asdf 47M 2018-04-27 21:20:39 00:00:18.583
Format specific information:
compat: 1.1
lazy refcounts: false
refcount bits: 16
corrupt: false
As a consequence:
-
it is possible to restore snapshots across boots, since they stay on the same image the entire time
-
it is not possible to use snapshots with initrd in our setup, since we don’t pass
-driveat all when initrd is enabled
23.6. Device models
This section documents:
-
how to interact with peripheral hardware device models through device drivers
-
how to write your own hardware device models for our emulators, see also: https://stackoverflow.com/questions/28315265/how-to-add-a-new-device-in-qemu-source-code
For the more complex interfaces, we focus on simplified educational devices, either:
-
present in the QEMU upstream:
23.6.1. PCI
Only tested in x86.
23.6.1.1. QEMU edu PCI device
Small upstream educational PCI device:
./qemu_edu.sh
This tests a lot of features of the edu device, to understand the results, compare the inputs with the documentation of the hardware: https://github.com/qemu/qemu/blob/v2.12.0/docs/specs/edu.txt
Sources:
-
kernel module: kernel_modules/qemu_edu.c
-
QEMU device: https://github.com/qemu/qemu/blob/v2.12.0/hw/misc/edu.c
-
test script: rootfs_overlay/lkmc/qemu_edu.sh
Works because we add to our default QEMU CLI:
-device edu
This example uses:
-
the QEMU
edueducational device, which is a minimal educational in-tree PCI example -
the
pci.kokernel module, which exercises theeduhardware.I’ve contacted the awesome original author author of
eduJiri Slaby, and he told there is no official kernel module example because this was created for a kernel module university course that he gives, and he didn’t want to give away answers. I don’t agree with that philosophy, so students, cheat away with this repo and go make startups instead.
TODO exercise DMA on the kernel module. The edu hardware model has that feature:
-
https://stackoverflow.com/questions/17913679/how-to-instantiate-and-use-a-dma-driver-linux-module
-
https://stackoverflow.com/questions/62831327/add-memory-device-to-qemu
-
https://stackoverflow.com/questions/64539528/qemu-pci-dma-read-and-pci-dma-write-does-not-work
-
https://stackoverflow.com/questions/64842929/general-protection-error-while-tring-to-perform-ioctl
23.6.1.2. Manipulate PCI registers directly
In this section we will try to interact with PCI devices directly from userland without kernel modules.
First identify the PCI device with:
lspci
In our case for example, we see:
00:06.0 Unclassified device [00ff]: Device 1234:11e8 (rev 10) 00:07.0 Unclassified device [00ff]: Device 1234:11e9
which we identify as being QEMU edu PCI device by the magic number: 1234:11e8.
Alternatively, we can also do use the QEMU monitor:
./qemu-monitor info qtree
which gives:
dev: edu, id ""
addr = 06.0
romfile = ""
rombar = 1 (0x1)
multifunction = false
command_serr_enable = true
x-pcie-lnksta-dllla = true
x-pcie-extcap-init = true
class Class 00ff, addr 00:06.0, pci id 1234:11e8 (sub 1af4:1100)
bar 0: mem at 0xfea00000 [0xfeafffff]
Read the configuration registers as binary:
hexdump /sys/bus/pci/devices/0000:00:06.0/config
Get nice human readable names and offsets of the registers and some enums:
setpci --dumpregs
Get the values of a given config register from its human readable name, either with either bus or device id:
setpci -s 0000:00:06.0 BASE_ADDRESS_0 setpci -d 1234:11e8 BASE_ADDRESS_0
Note however that BASE_ADDRESS_0 also appears when you do:
lspci -v
as:
Memory at feb54000
Then you can try messing with that address with /dev/mem:
devmem 0xfeb54000 w 0x12345678
which writes to the first register of the edu device.
The device then fires an interrupt at irq 11, which is unhandled, which leads the kernel to say you are a bad person:
<3>[ 1065.567742] irq 11: nobody cared (try booting with the "irqpoll" option)
followed by a trace.
Next, also try using our irq.ko IRQ monitoring module before triggering the interrupt:
insmod irq.ko devmem 0xfeb54000 w 0x12345678
Our kernel module handles the interrupt, but does not acknowledge it like our proper edu kernel module, and so it keeps firing, which leads to infinitely many messages being printed:
handler irq = 11 dev = 251
23.6.1.3. pciutils
There are two versions of setpci and lspci:
-
a simple one from BusyBox
-
a more complete one from pciutils which Buildroot has a package for, and is the default on Ubuntu 18.04 host. This is the one we enable by default.
23.6.1.4. Introduction to PCI
The PCI standard is non-free, obviously like everything in low level: https://pcisig.com/specifications but Google gives several illegal PDF hits :-)
And of course, the best documentation available is: http://wiki.osdev.org/PCI
Like every other hardware, we could interact with PCI on x86 using only IO instructions and memory operations.
But PCI is a complex communication protocol that the Linux kernel implements beautifully for us, so let’s use the kernel API.
Bibliography:
-
edu device source and spec in QEMU tree:
-
http://www.zarb.org/~trem/kernel/pci/pci-driver.c inb outb runnable example (no device)
-
LDD3 PCI chapter
-
another QEMU device + module, but using a custom QEMU device:
-
https://is.muni.cz/el/1433/podzim2016/PB173/um/65218991/ course given by the creator of the edu device. In Czech, and only describes API
23.6.1.5. PCI BFD
lspci -k shows something like:
00:04.0 Class 00ff: 1234:11e8 lkmc_pci
Meaning of the first numbers:
<8:bus>:<5:device>.<3:function>
Often abbreviated to BDF.
-
bus: groups PCI slots
-
device: maps to one slot
-
function: https://stackoverflow.com/questions/19223394/what-is-the-function-number-in-pci/44735372#44735372
Sometimes a fourth number is also added, e.g.:
0000:00:04.0
TODO is that the domain?
Class: pure magic: https://www-s.acm.illinois.edu/sigops/2007/roll_your_own/7.c.1.html TODO: does it have any side effects? Set in the edu device at:
k->class_id = PCI_CLASS_OTHERS
23.6.1.6. PCI BAR
Each PCI device has 6 BAR IOs (base address register) as per the PCI spec.
Each BAR corresponds to an address range that can be used to communicate with the PCI.
Each BAR is of one of the two types:
-
IORESOURCE_IO: must be accessed withinXandoutX -
IORESOURCE_MEM: must be accessed withioreadXandiowriteX. This is the saner method apparently, and what the edu device uses.
The length of each region is defined by the hardware, and communicated to software via the configuration registers.
The Linux kernel automatically parses the 64 bytes of standardized configuration registers for us.
QEMU devices register those regions with:
memory_region_init_io(&edu->mmio, OBJECT(edu), &edu_mmio_ops, edu,
"edu-mmio", 1 << 20);
pci_register_bar(pdev, 0, PCI_BASE_ADDRESS_SPACE_MEMORY, &edu->mmio);
23.6.2. GPIO
TODO: broken. Was working before we moved arm from -M versatilepb to -M virt around af210a76711b7fa4554dcc2abd0ddacfc810dfd4. Either make it work on -M virt if that is possible, or document precisely how to make it work with versatilepb, or hopefully vexpress which is newer.
QEMU does not have a very nice mechanism to observe GPIO activity: https://raspberrypi.stackexchange.com/questions/56373/is-it-possible-to-get-the-state-of-the-leds-and-gpios-in-a-qemu-emulation-like-t/69267#69267
The best you can do is to hack our build script to add:
HOST_QEMU_OPTS='--extra-cflags=-DDEBUG_PL061=1'
where PL061 is the dominating ARM Holdings hardware that handles GPIO.
Then compile with:
./build-buildroot --arch arm --config-fragment buildroot_config/gpio ./build-linux --config-fragment linux_config/gpio
then test it out with:
./gpio.sh
Source: rootfs_overlay/lkmc/gpio.sh
Buildroot’s Linux tools package provides some GPIO CLI tools: lsgpio, gpio-event-mon, gpio-hammer, TODO document them here.
23.6.3. LEDs
TODO: broken when arm moved to -M virt, same as GPIO.
Hack QEMU’s hw/misc/arm_sysctl.c with a printf:
static void arm_sysctl_write(void *opaque, hwaddr offset,
uint64_t val, unsigned size)
{
arm_sysctl_state *s = (arm_sysctl_state *)opaque;
switch (offset) {
case 0x08: /* LED */
printf("LED val = %llx\n", (unsigned long long)val);
and then rebuild with:
./build-qemu --arch arm ./build-linux --arch arm --config-fragment linux_config/leds
But beware that one of the LEDs has a heartbeat trigger by default (specified on dts), so it will produce a lot of output.
And then activate it with:
cd /sys/class/leds/versatile:0 cat max_brightness echo 255 >brightness
Relevant QEMU files:
-
hw/arm/versatilepb.c -
hw/misc/arm_sysctl.c
Relevant kernel files:
-
arch/arm/boot/dts/versatile-pb.dts -
drivers/leds/led-class.c -
drivers/leds/leds-sysctl.c
23.7. QEMU monitor
The QEMU monitor is a magic terminal that allows you to send text commands to the QEMU VM itself: https://en.wikibooks.org/wiki/QEMU/Monitor
While QEMU is running, on another terminal, run:
./qemu-monitor
or send one command such as info qtree and quit the monitor:
./qemu-monitor info qtree
or equivalently:
echo 'info qtree' | ./qemu-monitor
Source: qemu-monitor
qemu-monitor uses the -monitor QEMU command line option, which makes the monitor listen from a socket.
Alternatively, we can also enter the QEMU monitor from inside -nographics QEMU text mode with:
Ctrl-A C
and go back to the terminal with:
Ctrl-A C
When in graphic mode, we can do it from the GUI:
Ctrl-Alt ?
where ? is a digit 1, or 2, or, 3, etc. depending on what else is available on the GUI: serial, parallel and frame buffer.
Finally, we can also access QEMU monitor commands directly from GDB step debug with the monitor command:
./run-gdb
then inside that shell:
monitor info qtree
This way you can use both QEMU monitor and GDB commands to inspect the guest from inside a single shell! Pretty awesome.
In general, ./qemu-monitor is the best option, as it:
-
works on both modes
-
allows to use the host Bash history to re-run one off commands
-
allows you to search the output of commands on your host shell even when in graphic mode
Getting everything to work required careful choice of QEMU command line options:
23.7.1. QEMU monitor from guest
Peter Maydell said potentially not possible nicely as of August 2018: https://stackoverflow.com/questions/51747744/how-to-run-a-qemu-monitor-command-from-inside-the-guest/51764110#51764110
It is also worth looking into the QEMU Guest Agent tool qemu-gq that can be enabled with:
./build-buildroot --config 'BR2_PACKAGE_QEMU=y'
23.7.2. QEMU monitor from GDB
When doing GDB step debug it is possible to send QEMU monitor commands through the GDB monitor command, which saves you the trouble of opening yet another shell.
Try for example:
monitor help monitor info qtree
23.8. Debug the emulator
When you start hacking QEMU or gem5, it is useful to see what is going on inside the emulator themselves.
This is of course trivial since they are just regular userland programs on the host, but we make it a bit easier with:
./run --debug-vm
Or for a faster development loop you can pass -ex command as a semicolon separated list:
./run --debug-vm-ex 'break qemu_add_opts;run'
which is equivalent to the more verbose:
./run --debug-vm-args '-ex "break qemu_add_opts" -ex "run"'
if you ever want need anything besides -ex.
Or if things get really involved and you want a debug script:
printf 'break qemu_add_opts run ' > data/vm.gdb ./run --debug-vm-file data/vm.gdb
Our default emulator builds are optimized with gcc -O2 -g. To use -O0 instead, build and run with:
./build-qemu --qemu-build-type debug --verbose ./run --debug-vm ./build-gem5 --gem5-build-type debug --verbose ./run --debug-vm --emulator-gem5
The --verbose is optional, but shows clearly each GCC build command so that you can confirm what --*-build-type is doing.
The build outputs are automatically stored in a different directories for optimized and debug builds, which prevents debug files from overwriting opt ones. Therefore, --gem5-build-id is not required.
The price to pay for debuggability is high however: a Linux kernel boot was about 3x slower in QEMU and 14 times slower in gem5 debug compared to opt, see benchmarks at: Section 35.2.1, “Benchmark Linux kernel boot”.
Similar slowdowns can be observed at: Section 35.2.2, “Benchmark emulators on userland executables”.
When in QEMU text mode, using --debug-vm makes Ctrl-C not get passed to the QEMU guest anymore: it is instead captured by GDB itself, so allow breaking. So e.g. you won’t be able to easily quit from a guest program like:
sleep 10
In graphic mode, make sure that you never click inside the QEMU graphic while debugging, otherwise you mouse gets captured forever, and the only solution I can find is to go to a TTY with Ctrl-Alt-F1 and kill QEMU.
You can still send key presses to QEMU however even without the mouse capture, just either click on the title bar, or alt tab to give it focus.
23.8.1. Reverse debug the emulator
While step debugging any complex program, you always end up feeling the need to step in reverse to reach the last call to some function that was called before the failure point, in order to trace back the problem to the actual bug source.
While GDB "has" this feature, it is just too broken to be usable, and so we expose the amazing Mozilla RR tool conveniently in this repo: https://stackoverflow.com/questions/1470434/how-does-reverse-debugging-work/53063242#53063242
Before the first usage setup rr with:
echo 'kernel.perf_event_paranoid=1' | sudo tee -a /etc/sysctl.conf sudo sysctl -p
Then use it with your content of interest, for example:
./run --debug-vm-rr --userland userland/c/hello.c
This will:
-
first run the program once until completion or crash
-
then restart the program at the very first instruction at
_startand leave you in a GDB shell
From there, run the program until your point of interest, e.g.:
break qemu_add_opts continue
and you can now reliably use reverse debugging commands such as reverse-continue, reverse-finish and reverse-next!
To restart debugging again after quitting rr, simply run on your host terminal:
rr replay
The use case of rr is often to go to the final crash and then walk back from there, so you often want to automate running until the end after record with --debug-vm-args as in:
./run --debug-vm-args='-ex continue' --debug-vm-rr --userland userland/c/hello.c
Programs often tend to blow up in very low frames that use values passed in from higher frames. In those cases, remember that just like with forward debugging, you can’t just go:
up up up reverse-next
but rather, you must:
reverse-finish reverse-finish reverse-finish reverse-next
23.8.2. Debug gem5 Python scripts
Start pdb at the first instruction:
./run --emulator gem5 --gem5-exe-args='--pdb' --terminal
Requires --terminal as we must be on foreground.
Alternatively, you can add to the point of the code where you want to break the usual:
import ipdb; ipdb.set_trace()
and then run with:
./run --emulator gem5 --terminal
23.9. Tracing
The tracing described in this section requires rebuilding QEMU with:
./build-qemu --extra-config-args=--enable-trace-backends=simple
Ideally we would like to use this build option by default, but unfortunately starting on some QEMU version this started generating trace-<pid> files for every run which is far too annoying when you don’t want traces, and we don’t know how to turn it off at runtime or make the files be created in some other directory.
QEMU can log several different events.
The most interesting are events which show instructions that QEMU ran, for which we have a helper:
./trace-boot --arch x86_64
Under the hood, this uses QEMU’s -trace option.
You can then inspect the address of each instruction run:
less "$(./getvar --arch x86_64 run_dir)/trace.txt"
Sample output excerpt:
exec_tb 0.000 pid=10692 tb=0x7fb4f8000040 pc=0xfffffff0 exec_tb 35.391 pid=10692 tb=0x7fb4f8000180 pc=0xfe05b exec_tb 21.047 pid=10692 tb=0x7fb4f8000340 pc=0xfe066 exec_tb 12.197 pid=10692 tb=0x7fb4f8000480 pc=0xfe06a
Get the list of available trace events:
./run --trace help
TODO: any way to show the actualy disassembled instruction executed directly from there? Possible with QEMU -d tracing.
Enable other specific trace events:
./run --trace trace1,trace2 ./qemu-trace2txt -a "$arch" less "$(./getvar -a "$arch" run_dir)/trace.txt"
This functionality relies on the following setup:
-
./configure --enable-trace-backends=simple. This logs in a binary format to the trace file.It makes 3x execution faster than the default trace backend which logs human readable data to stdout.
Logging with the default backend
loggreatly slows down the CPU, and in particular leads to this boot message:All QSes seen, last rcu_sched kthread activity 5252 (4294901421-4294896169), jiffies_till_next_fqs=1, root ->qsmask 0x0 swapper/0 R running task 0 1 0 0x00000008 ffff880007c03ef8 ffffffff8107aa5d ffff880007c16b40 ffffffff81a3b100 ffff880007c03f60 ffffffff810a41d1 0000000000000000 0000000007c03f20 fffffffffffffedc 0000000000000004 fffffffffffffedc ffffffff00000000 Call Trace: <IRQ> [<ffffffff8107aa5d>] sched_show_task+0xcd/0x130 [<ffffffff810a41d1>] rcu_check_callbacks+0x871/0x880 [<ffffffff810a799f>] update_process_times+0x2f/0x60
in which the boot appears to hang for a considerable time.
-
patch QEMU source to remove the
disablefromexec_tbin thetrace-eventsfile. See also: https://rwmj.wordpress.com/2016/03/17/tracing-qemu-guest-execution/
23.9.1. QEMU -d tracing
QEMU also has a second trace mechanism in addition to -trace, find out the events with:
./run -- -d help
Let’s pick the one that dumps executed instructions, in_asm:
./run --eval './linux/poweroff.out' -- -D out/trace.txt -d in_asm less out/trace.txt
Sample output excerpt:
---------------- IN: 0xfffffff0: ea 5b e0 00 f0 ljmpw $0xf000:$0xe05b ---------------- IN: 0x000fe05b: 2e 66 83 3e 88 61 00 cmpl $0, %cs:0x6188 0x000fe062: 0f 85 7b f0 jne 0xd0e1
TODO: after IN:, symbol names are meant to show, which is awesome, but I don’t get any. I do see them however when running a bare metal example from: https://github.com/cirosantilli/newlib-examples/tree/900a9725947b1f375323c7da54f69e8049158881
TODO: what is the point of having two mechanisms, -trace and -d? -d tracing is cool because it does not require a messy recompile, and it can also show symbols.
23.9.2. QEMU trace register values
TODO: is it possible to show the register values for each instruction?
This would include the memory values read into the registers.
Seems impossible due to optimizations that QEMU does:
PANDA can list memory addresses, so I bet it can also decode the instructions: https://github.com/panda-re/panda/blob/883c85fa35f35e84a323ed3d464ff40030f06bd6/panda/docs/LINE_Censorship.md I wonder why they don’t just upstream those things to QEMU’s tracing: https://github.com/panda-re/panda/issues/290
gem5 can do it as shown at: Section 23.9.8, “gem5 tracing”.
23.9.3. QEMU trace memory accesses
Not possible apparently, not even with the memory_region_ops_read and memory_region_ops_write trace events, Peter comments https://lists.gnu.org/archive/html/qemu-devel/2015-06/msg07482.html
No. You will miss all the fast-path memory accesses, which are done with custom generated assembly in the TCG backend. In general QEMU is not designed to support this kind of monitoring of guest operations.
23.9.4. Trace source lines
We can further use Binutils' addr2line to get the line that corresponds to each address:
./trace-boot --arch x86_64 ./trace2line --arch x86_64 less "$(./getvar --arch x86_64 run_dir)/trace-lines.txt"
The last commands takes several seconds.
The format is as follows:
39368 _static_cpu_has arch/x86/include/asm/cpufeature.h:148
Where:
-
39368: number of consecutive times that a line ran. Makes the output much shorter and more meaningful -
_static_cpu_has: name of the function that contains the line -
arch/x86/include/asm/cpufeature.h:148: file and line
This could of course all be done with GDB, but it would likely be too slow to be practical.
TODO do even more awesome offline post-mortem analysis things, such as:
-
detect if we are in userspace or kernelspace. Should be a simple matter of reading the
-
read kernel data structures, and determine the current thread. Maybe we can reuse / extend the kernel’s GDB Python scripts??
23.9.5. QEMU record and replay
QEMU runs, unlike gem5, are not deterministic by default, however it does support a record and replay mechanism that allows you to replay a previous run deterministically.
This awesome feature allows you to examine a single run as many times as you would like until you understand everything:
# Record a run. ./run --eval-after './linux/rand_check.out;./linux/poweroff.out;' --record # Replay the run. ./run --eval-after './linux/rand_check.out;./linux/poweroff.out;' --replay
A convenient shortcut to do both at once to test the feature is:
./qemu-rr --eval-after './linux/rand_check.out;./linux/poweroff.out;'
By comparing the terminal output of both runs, we can see that they are the exact same, including things which normally differ across runs:
-
timestamps of dmesg output
-
rand_check.out output
The record and replay feature was revived around QEMU v3.0.0. In v5.2.0 it is quite usable, almost all peripherals and vCPUs are supported.
Documented at: https://github.com/qemu/qemu/blob/v5.2.0/docs/replay.txt
replay may be used with with network:
./qemu-rr --eval-after 'ifup -a;wget -S google.com;./linux/poweroff.out;'
arm and aarch64 targets can also be used with rr:
./qemu-rr --arch aarch64 --eval-after './linux/rand_check.out;./linux/poweroff.out;' ./qemu-rr --arch aarch64 --eval-after 'ifup -a;wget -S google.com;./linux/poweroff.out;'
Replay also supports initrd and no disk:
./build-buildroot --arch aarch64 --initrd ./qemu-rr --arch aarch64 --eval-after './linux/rand_check.out;./linux/poweroff.out;' --initrd
23.9.5.1. QEMU reverse debugging
QEMU replays support checkpointing, and this allows for a simplistic "reverse debugging" implementation since v5.2.0:
./run --eval-after './linux/rand_check.out;./linux/poweroff.out;' --record ./run --eval-after './linux/rand_check.out;./linux/poweroff.out;' --replay --gdb-wait
On another shell:
./run-gdb start_kernel
In GDB:
n n n n reverse-continue
and we are back at start_kernel
reverse-continue proceeds to the latest of the earlier breakpoints or to the very beginning if there were no breakpoints before.
23.9.6. QEMU trace multicore
TODO: is there any way to distinguish which instruction runs on each core? Doing:
./run --arch x86_64 --cpus 2 --eval './linux/poweroff.out' --trace exec_tb ./qemu-trace2txt
just appears to output both cores intertwined without any clear differentiation.
23.9.8. gem5 tracing
gem5 provides also provides a tracing mechanism documented at: http://www.gem5.org/Trace_Based_Debugging:
./run --arch aarch64 --eval 'm5 exit' --emulator gem5 --trace ExecAll less "$(./getvar --arch aarch64 run_dir)/trace.txt"
Our wrapper just forwards the options to the --debug-flags gem5 option.
Keep in mind however that the disassembly is very broken in several places as of 2019q2, so you can’t always trust it.
Output the trace to stdout instead of a file:
./run \ --arch aarch64 \ --emulator gem5 \ --eval 'm5 exit' \ --trace ExecAll \ --trace-stdout \ ;
We also have a shortcut for --trace ExecAll -trace-stdout with --trace-insts-stdout
./run \ --arch aarch64 \ --emulator gem5 \ --eval 'm5 exit' \ --trace-insts-stdout \ ;
Be warned, the trace is humongous, at 16Gb.
This would produce a lot of output however, so you will likely not want that when tracing a Linux kernel boot instructions. But it can be very convenient for smaller traces such as Baremetal.
List all available debug flags:
./run --arch aarch64 --gem5-exe-args='--debug-help' --emulator gem5
but to understand most of them you have to look at the source code:
less "$(./getvar gem5_source_dir)/src/cpu/SConscript" less "$(./getvar gem5_source_dir)/src/cpu/exetrace.cc"
The most important trace flags to know about are:
-
Faults: CPU exceptions / interrupts, see an example at: ARM SVC instruction
Trace internals are discussed at: gem5 trace internals.
As can be seen on the Sconstruct, Exec is just an alias that enables a set of flags.
We can make the trace smaller by naming the trace file as trace.txt.gz, which enables GZIP compression, but that is not currently exposed on our scripts, since you usually just need something human readable to work on.
Enabling tracing made the runtime about 4x slower on the 2017 Lenovo ThinkPad P51, with or without .gz compression.
Trace the source lines just like for QEMU with:
./trace-boot --arch aarch64 --emulator gem5 ./trace2line --arch aarch64 --emulator gem5 less "$(./getvar --arch aarch64 run_dir)/trace-lines.txt"
TODO: 7452d399290c9c1fc6366cdad129ef442f323564 ./trace2line this is too slow and takes hours. QEMU’s processing of 170k events takes 7 seconds. gem5’s processing is analogous, but there are 140M events, so it should take 7000 seconds ~ 2 hours which seems consistent with what I observe, so maybe there is no way to speed this up… The workaround is to just use gem5’s ExecSymbol to get function granularity, and then GDB individually if line detail is needed?
23.9.8.1. gem5 trace internals
gem5 traces are generated from DPRINTF(<trace-id> calls scattered throughout the code, except for ExecAll instruction traces, which uses Debug::ExecEnable directly..
The trace IDs are themselves encoded in SConscript files, e.g.:
DebugFlag('Event'
in src/cpu/SConscript.
The build system then automatically adds the options to the --debug-flags.
For this entry, the build system then generates a file build/ARM/debug/ExecEnable.hh, which contains:
namespace Debug {
class SimpleFlag;
extern SimpleFlag ExecEnable;
}
and must be included in from callers of DPRINTF( as <debug/ExecEnable.hh>.
Tested in b4879ae5b0b6644e6836b0881e4da05c64a6550d.
23.9.8.2. gem5 ExecAll trace format
This debug flag traces all instructions.
The output format is of type:
25007000: system.cpu T0 : @start_kernel : stp 25007000: system.cpu T0 : @start_kernel.0 : addxi_uop ureg0, sp, #-112 : IntAlu : D=0xffffff8008913f90 25007500: system.cpu T0 : @start_kernel.1 : strxi_uop x29, [ureg0] : MemWrite : D=0x0000000000000000 A=0xffffff8008913f90 25008000: system.cpu T0 : @start_kernel.2 : strxi_uop x30, [ureg0, #8] : MemWrite : D=0x0000000000000000 A=0xffffff8008913f98 25008500: system.cpu T0 : @start_kernel.3 : addxi_uop sp, ureg0, #0 : IntAlu : D=0xffffff8008913f90
There are two types of lines:
-
full instructions, as the first line. Only shown if the
ExecMacroflag is given. -
micro ops that constitute the instruction, the lines that follow. Yes,
aarch64also has microops: https://superuser.com/questions/934752/do-arm-processors-like-cortex-a9-use-microcode/934755#934755. Only shown if theExecMicroflag is given.
Breakdown:
-
25007500: time count in some unit. Note how the microops execute at further timestamps. -
system.cpu: distinguishes between CPUs when there are more than one. For example, running Section 33.10.3, “ARM baremetal multicore” with two cores producessystem.cpu0andsystem.cpu1 -
T0: thread number. TODO: hyperthread? How to play with it?config.ini has--param 'system.multi_thread = True' --param 'system.cpu[0].numThreads = 2', but in ARM baremetal multicore the first one alone does not produceT1, and with the second one simulation blows up with:fatal: fatal condition interrupts.size() != numThreads occurred: CPU system.cpu has 1 interrupt controllers, but is expecting one per thread (2)
-
@start_kernel: we are in thestart_kernelfunction. Awesome feature! Implemented with libelf https://sourceforge.net/projects/elftoolchain/ copy pasted in-treeext/libelf. To get raw addresses, remove theExecSymbol, which is enabled byExec. This can be done withExec,-ExecSymbol. -
.1as in@start_kernel.1: index of the gem5 microops -
stp: instruction disassembly. Note however that the disassembly of many instructions are very broken as of 2019q2, and you can’t just trust them blindly. -
strxi_uop x29, [ureg0]: microop disassembly. -
MemWrite : D=0x0000000000000000 A=0xffffff8008913f90: a memory write microop:-
Dstands for data, and represents the value that was written to memory or to a register -
Astands for address, and represents the address to which the value was written. It only shows when data is being written to memory, but not to registers.
-
The best way to verify all of this is to write some baremetal code
23.9.8.3. gem5 Registers trace format
This flag shows a more detailed register usage than gem5 ExecAll trace format.
For example, if we run in LKMC 0323e81bff1d55b978a4b36b9701570b59b981eb:
./run --arch aarch64 --baremetal userland/arch/aarch64/add.S --emulator gem5 --trace ExecAll,Registers --trace-stdout
then the stdout contains:
31000: system.cpu A0 T0 : @main_after_prologue : movz x0, #1, #0 : IntAlu : D=0x0000000000000001 flags=(IsInteger) 31500: system.cpu.[tid:0]: Setting int reg 34 (34) to 0. 31500: system.cpu.[tid:0]: Reading int reg 0 (0) as 0x1. 31500: system.cpu.[tid:0]: Setting int reg 1 (1) to 0x3. 31500: system.cpu A0 T0 : @main_after_prologue+4 : add x1, x0, #2 : IntAlu : D=0x0000000000000003 flags=(IsInteger) 32000: system.cpu.[tid:0]: Setting int reg 34 (34) to 0. 32000: system.cpu.[tid:0]: Reading int reg 1 (1) as 0x3. 32000: system.cpu.[tid:0]: Reading int reg 31 (34) as 0. 32000: system.cpu.[tid:0]: Setting int reg 0 (0) to 0x3.
which corresponds to the two following instructions:
mov x0, 1 add x1, x0, 2
TODO that format is either buggy or is very difficult to understand:
-
what is
34? Presumably some flags register? -
what do the numbers in parenthesis mean at
31 (34)? Presumably some flags register? -
why is the first instruction setting
reg 1and the second onereg 0, given that the first setsx0and the secondx1?
23.9.8.5. gem5 tracing internals
As of gem5 16eeee5356585441a49d05c78abc328ef09f7ace the default tracer is ExeTracer. It is set at:
src/cpu/BaseCPU.py:63:default_tracer = ExeTracer()
which then gets used at:
class BaseCPU(ClockedObject):
[...]
tracer = Param.InstTracer(default_tracer, "Instruction tracer")
All tracers derive from the common InstTracer base class:
git grep ': InstTracer'
gives:
src/arch/arm/tracers/tarmac_parser.hh:218: TarmacParser(const Params *p) : InstTracer(p), startPc(p->start_pc), src/arch/arm/tracers/tarmac_tracer.cc:57: : InstTracer(p), src/cpu/exetrace.hh:67: ExeTracer(const Params *params) : InstTracer(params) src/cpu/inst_pb_trace.cc:72: : InstTracer(p), buf(nullptr), bufSize(0), curMsg(nullptr) src/cpu/inteltrace.hh:63: IntelTrace(const IntelTraceParams *p) : InstTracer(p)
As mentioned at gem5 TARMAC traces, there appears to be no way to select those currently without hacking the config scripts.
TARMAC is described at: gem5 TARMAC traces.
TODO: are IntelTrace and TarmacParser useful for anything or just relics?
Then there is also the NativeTrace class:
src/cpu/nativetrace.hh:68:class NativeTrace : public ExeTracer
which gets implemented in a few different ISAs, but not all:
src/arch/arm/nativetrace.hh:40:class ArmNativeTrace : public NativeTrace src/arch/sparc/nativetrace.hh:41:class SparcNativeTrace : public NativeTrace src/arch/x86/nativetrace.hh:41:class X86NativeTrace : public NativeTrace
TODO: I can’t find any usages of those classes from in-tree configs.
23.10. QEMU GUI is unresponsive
Sometimes in Ubuntu 14.04, after the QEMU SDL GUI starts, it does not get updated after keyboard strokes, and there are artifacts like disappearing text.
We have not managed to track this problem down yet, but the following workaround always works:
Ctrl-Shift-U Ctrl-C root
This started happening when we switched to building QEMU through Buildroot, and has not been observed on later Ubuntu.
Using text mode is another workaround if you don’t need GUI features.
24. gem5
Getting started at: Section 2.4, “gem5 Buildroot setup”.
gem5 has a bunch of crappiness, mostly described at: gem5 vs QEMU, but it does deserve some credit on the following points:
-
insanely configurable system topology from Python without recompiling, made possible in part due to a well defined memory packet structure that allows adding caches and buses transparently
-
each micro architectural model (gem5 CPU types) works with all ISAs
24.1. gem5 vs QEMU
-
advantages of gem5:
-
simulates a generic more realistic optionally pipelined and out-of-order CPU cycle by cycle, including a realistic DRAM memory access model with latencies, caches and page table manipulations. This allows us to:
-
do much more realistic performance benchmarking with it, which makes absolutely no sense in QEMU, which is purely functional
-
make certain functional observations that are not possible in QEMU, e.g.:
-
use Linux kernel APIs that flush cache memory like DMA, which are crucial for driver development. In QEMU, the driver would still work even if we forget to flush caches.
-
spectre / meltdown:
-
It is not of course truly cycle accurate, as that:
-
would require exposing proprietary information of the CPU designs: https://stackoverflow.com/questions/17454955/can-you-check-performance-of-a-program-running-with-qemu-simulator/33580850#33580850
-
would make the simulation even slower TODO confirm, by how much
but the approximation is reasonable.
It is used mostly for microarchitecture research purposes: when you are making a new chip technology, you don’t really need to specialize enormously to an existing microarchitecture, but rather develop something that will work with a wide range of future architectures.
-
-
runs are deterministic by default, unlike QEMU which has a special QEMU record and replay mode, that requires first playing the content once and then replaying
-
gem5 ARM at least appears to implement more low level CPU functionality than QEMU, e.g. QEMU only added EL2 in 2018: https://stackoverflow.com/questions/42824706/qemu-system-aarch64-entering-el1-when-emulating-a53-power-up See also: Section 33.10.1, “ARM exception levels”
-
gem5 offers more advanced logging, even for non micro architectural things which QEMU models in some way, e.g. QEMU trace memory accesses, because QEMU’s binary translation optimizations reduce visibility
-
-
disadvantages of gem5:
-
slower than QEMU, see: Section 35.2.1, “Benchmark Linux kernel boot”
This implies that the user base is much smaller, since no Android devs.
Instead, we have only chip makers, who keep everything that really works closed, and researchers, who can’t version track or document code properly >:-) And this implies that:
-
the documentation is more scarce
-
it takes longer to support new hardware features
Well, not that AOSP is that much better anyway.
-
-
not sure: gem5 has BSD license while QEMU has GPL
This suits chip makers that want to distribute forks with secret IP to their customers.
On the other hand, the chip makers tend to upstream less, and the project becomes more crappy in average :-)
-
gem5 is way more complex and harder to modify and maintain
The only hairy thing in QEMU is the binary code generation.
gem5 however has tended towards horrendous intensive code generation in order to support all its different hardware types
gem5 also has a complex Python interface which is also largely auto-generated, which greatly increases the maintenance complexity of the project: Embedding Python in another application.
This is done so that reconfiguring platforms can be done quickly without recompiling, and it is amazing when it works, but the maintenance costs are also very high. For example, pybind11 of several trivial
param_files accounted for 50% of the build time at one point: pybind11 accounts for 50% of gem5 build time.All of this also makes it hard to setup an IDE for developing gem5: gem5 Eclipse configuration
The feelings of helplessness this brings are well summarized by the following CSDN article https://blog.csdn.net/maokelong95/article/details/85333905:
Found DPRINTF based debugging unable to meet your needs?
Found GDB based debugging unfriendly to human beings?
Want to debug gem5 source with the help of modern IDEs like Eclipse?
Failed in getting help from GEM5 community?
Come on, dude! Here is the up-to-date tutorial for you!
Just be ready for THE ENDLESS NIGHTMARE gem5 will bring!
-
24.2. gem5 run benchmark
OK, this is why we used gem5 in the first place, performance measurements!
Let’s see how many cycles dhrystone, which Buildroot provides, takes for a few different input parameters.
We will do that for various input parameters on full system by taking a checkpoint after the boot finishes a fast atomic CPU boot, and then we will restore in a more detailed mode and run the benchmark:
./build-buildroot --config 'BR2_PACKAGE_DHRYSTONE=y' # Boot fast, take checkpoint, and exit. ./run --arch aarch64 --emulator gem5 --eval-after './gem5.sh' # Restore the checkpoint after boot, and benchmark with input 1000. ./run \ --arch aarch64 \ --emulator gem5 \ --eval-after './gem5.sh' \ --gem5-readfile 'm5 resetstats;dhrystone 1000;m5 dumpstats' \ --gem5-restore 1 \ -- \ --cpu-type=HPI \ --restore-with-cpu=HPI \ --caches \ --l2cache \ --l1d_size=64kB \ --l1i_size=64kB \ --l2_size=256kB \ ; # Get the value for number of cycles. # head because there are two lines: our dumpstats and the # automatic dumpstats at the end which we don't care about. ./gem5-stat --arch aarch64 | head -n 1 # Now for input 10000. ./run \ --arch aarch64 \ --emulator gem5 \ --eval-after './gem5.sh' \ --gem5-readfile 'm5 resetstats;dhrystone 10000;m5 dumpstats' \ --gem5-restore 1 \ -- \ --cpu-type=HPI \ --restore-with-cpu=HPI \ --caches \ --l2cache \ --l1d_size=64kB \ --l1i_size=64kB \ --l2_size=256kB \ ; ./gem5-stat --arch aarch64 | head -n 1
If you ever need a shell to quickly inspect the system state after boot, you can just use:
./run \ --arch aarch64 \ --emulator gem5 \ --eval-after './gem5.sh' \ --gem5-readfile 'sh' \ --gem5-restore 1 \
This procedure is further automated and DRYed up at:
./gem5-bench-dhrystone cat out/gem5-bench-dhrystone.txt
Source: gem5-bench-dhrystone
Output at 2438410c25e200d9766c8c65773ee7469b599e4a + 1:
n cycles 1000 13665219 10000 20559002 100000 85977065
so as expected, the Dhrystone run with a larger input parameter 100000 took more cycles than the ones with smaller input parameters.
The gem5-stats commands output the approximate number of CPU cycles it took Dhrystone to run.
A more naive and simpler to understand approach would be a direct:
./run --arch aarch64 --emulator gem5 --eval 'm5 checkpoint;m5 resetstats;dhrystone 10000;m5 exit'
but the problem is that this method does not allow to easily run a different script without running the boot again. The ./gem5.sh script works around that by using m5 readfile as explained further at: Section 24.6.3, “gem5 checkpoint restore and run a different script”.
Now you can play a fun little game with your friends:
-
pick a computational problem
-
make a program that solves the computation problem, and outputs output to stdout
-
write the code that runs the correct computation in the smallest number of cycles possible
Interesting algorithms and benchmarks for this game are being collected at:
To find out why your program is slow, a good first step is to have a look at the gem5 m5out/stats.txt file.
24.2.1. Skip extra benchmark instructions
A few imperfections of our benchmarking method are:
-
when we do
m5 resetstatsandm5 exit, there is some time passed before theexecsystem call returns and the actual benchmark starts and ends -
the benchmark outputs to stdout, which means so extra cycles in addition to the actual computation. But TODO: how to get the output to check that it is correct without such IO cycles?
Solutions to these problems include:
-
modify benchmark code with instrumentation directly, see m5ops instructions for an example.
-
monitor known addresses TODO possible? Create an example.
Those problems should be insignificant if the benchmark runs for long enough however.
24.3. gem5 system parameters
Besides optimizing a program for a given CPU setup, chip developers can also do the inverse, and optimize the chip for a given benchmark!
The rabbit hole is likely deep, but let’s scratch a bit of the surface.
24.3.1. Number of cores
./run --arch arm --cpus 2 --emulator gem5
Can be checked with /proc/cpuinfo or getconf in Ubuntu 18.04:
cat /proc/cpuinfo getconf _NPROCESSORS_CONF
Or from User mode simulation, we can use either of:
-
sysconf with userland/linux/sysconf.c
./run --cpus 2 --emulator gem5 --userland userland/linux/sysconf.c | grep _SC_NPROCESSORS_ONLN
-
C++ multithreading's userland/cpp/thread_hardware_concurrency.cpp:
./run --cpus 2 --emulator gem5 --userland userland/cpp/thread_hardware_concurrency.cpp
-
direct access to several special filesystem files that contain this information e.g. via userland/c/cat.c:
./run --cpus 2 --emulator gem5 --userland userland/c/cat.c --cli-args /proc/cpuinfo
24.3.1.1. QEMU user mode multithreading
User mode simulation QEMU v4.0.0 always shows the number of cores of the host, presumably because the thread switching uses host threads directly which would make that harder to implement.
It does not seem possible to make the guest see a different number of cores than what the host has. Full system does have the -smp options, which controls this.
E.g., all of of the following output the same as nproc on the host:
nproc ./run --cpus 1 --userland userland/cpp/thread_hardware_concurrency.cpp ./run --cpus 2 --userland userland/cpp/thread_hardware_concurrency.cpp
This random page suggests that QEMU splits one host thread thread per guest thread, and thus presumably delegates context switching to the host kernel: https://qemu.weilnetz.de/w64/2012/2012-12-04/qemu-tech.html#User-emulation-specific-details
We can confirm that with:
./run --userland userland/posix/pthread_count.c --cli-args 4 ps Haux | grep qemu | wc
Remember QEMU user mode does not show stdout immediately though.
At 369a47fc6e5c2f4a7f911c1c058b6088f8824463 + 1 QEMU appears to spawn 3 host threads plus one for every new guest thread created. Remember that userland/posix/pthread_count.c spawns N + 1 total threads if you count the main thread.
24.3.1.2. gem5 ARM full system with more than 8 cores
With GICv3, tested at LKMC 224fae82e1a79d9551b941b19196c7e337663f22 gem5 3ca404da175a66e0b958165ad75eb5f54cb5e772 on vanilla kernel:
./run \ --arch aarch64 \ --emulator gem5 \ --cpus 16 \ -- \ --machine-type VExpress_GEM5_V2 \ ;
boots to a shell and nproc shows 16.
For the GICv2 extension method, build the kernel with the gem5 arm Linux kernel patches, and then run:
./run \ --arch aarch64 \ --linux-build-id gem5-v4.15 \ --emulator gem5 \ --cpus 16 \ -- \ --param 'system.realview.gic.gem5_extensions = True' \ ;
Tested in LKMC 788087c6f409b84adf3cff7ac050fa37df6d4c46. It fails after boot with FATAL: kernel too old as mentioned at: gem5 arm Linux kernel patches but everything seems to work on the gem5 side of things.
24.3.2. gem5 cache size
A quick ./run --emulator gem5 -- -h leads us to the options:
--caches --l1d_size=1024 --l1i_size=1024 --l2cache --l2_size=1024 --l3_size=1024
But keep in mind that it only affects benchmark performance of the most detailed CPU types as shown at: Table 2, “gem5 cache support in function of CPU type”.
| arch | CPU type | caches used |
|---|---|---|
X86 |
|
no |
X86 |
|
?* |
ARM |
|
no |
ARM |
|
yes |
*: couldn’t test because of:
Cache sizes can in theory be checked with the methods described at: https://superuser.com/questions/55776/finding-l2-cache-size-in-linux:
lscpu cat /sys/devices/system/cpu/cpu0/cache/index2/size
and on Ubuntu 20.04 host but not Buildroot 1.31.1:
getconf -a | grep CACHE
and we also have an easy to use userland executable using sysconf at userland/linux/sysconf.c:
./run --emulator gem5 --userland userland/linux/sysconf.c
but for some reason the Linux kernel is not seeing the cache sizes:
Behaviour breakdown:
-
arm QEMU and gem5 (both
AtomicSimpleCPUorHPI), x86 gem5:/sysfiles don’t exist, andgetconfandlscpuvalue empty -
x86 QEMU:
/sysfiles exist, butgetconfandlscpuvalues still empty
The only precise option is therefore to look at gem5 config.ini as done at: gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis with caches.
Or for a quick and dirty performance measurement approach instead:
./gem5-bench-cache -- --arch aarch64 cat "$(./getvar --arch aarch64 run_dir)/bench-cache.txt"
which gives:
cmd ./run --emulator gem5 --arch aarch64 --gem5-readfile "dhrystone 1000" --gem5-restore 1 -- --caches --l2cache --l1d_size=1024 --l1i_size=1024 --l2_size=1024 --l3_size=1024 --cpu-type=HPI --restore-with-cpu=HPI time 23.82 exit_status 0 cycles 93284622 instructions 4393457 cmd ./run --emulator gem5 --arch aarch64 --gem5-readfile "dhrystone 1000" --gem5-restore 1 -- --caches --l2cache --l1d_size=1024kB --l1i_size=1024kB --l2_size=1024kB --l3_size=1024kB --cpu-type=HPI --restore-with-cpu=HPI time 14.91 exit_status 0 cycles 10128985 instructions 4211458 cmd ./run --emulator gem5 --arch aarch64 --gem5-readfile "dhrystone 10000" --gem5-restore 1 -- --caches --l2cache --l1d_size=1024 --l1i_size=1024 --l2_size=1024 --l3_size=1024 --cpu-type=HPI --restore-with-cpu=HPI time 51.87 exit_status 0 cycles 188803630 instructions 12401336 cmd ./run --emulator gem5 --arch aarch64 --gem5-readfile "dhrystone 10000" --gem5-restore 1 -- --caches --l2cache --l1d_size=1024kB --l1i_size=1024kB --l2_size=1024kB --l3_size=1024kB --cpu-type=HPI --restore-with-cpu=HPI time 35.35 exit_status 0 cycles 20715757 instructions 12192527 cmd ./run --emulator gem5 --arch aarch64 --gem5-readfile "dhrystone 100000" --gem5-restore 1 -- --caches --l2cache --l1d_size=1024 --l1i_size=1024 --l2_size=1024 --l3_size=1024 --cpu-type=HPI --restore-with-cpu=HPI time 339.07 exit_status 0 cycles 1176559936 instructions 94222791 cmd ./run --emulator gem5 --arch aarch64 --gem5-readfile "dhrystone 100000" --gem5-restore 1 -- --caches --l2cache --l1d_size=1024kB --l1i_size=1024kB --l2_size=1024kB --l3_size=1024kB --cpu-type=HPI --restore-with-cpu=HPI time 240.37 exit_status 0 cycles 125666679 instructions 91738770
We make the following conclusions:
-
the number of instructions almost does not change: the CPU is waiting for memory all the extra time. TODO: why does it change at all?
-
the wall clock execution time is not directionally proportional to the number of cycles: here we had a 10x cycle increase, but only 2x time increase. This suggests that the simulation of cycles in which the CPU is waiting for memory to come back is faster.
24.3.3. gem5 DRAM model
Some info at: TimingSimpleCPU analysis #1 but highly TODO :-)
24.3.3.1. gem5 memory latency
TODO These look promising:
--list-mem-types --mem-type=MEM_TYPE --mem-channels=MEM_CHANNELS --mem-ranks=MEM_RANKS --mem-size=MEM_SIZE
TODO: now to verify this with the Linux kernel? Besides raw performance benchmarks.
Now for a raw simplistic benchmark on TimingSimpleCPU without caches via C busy loop:
./run --arch aarch64 --cli-args 1000000 --emulator gem5 --userland userland/gcc/busy_loop.c -- --cpu-type TimingSimpleCPU
LKMC eb22fd3b6e7fff7e9ef946a88b208debf5b419d5 gem5 872cb227fdc0b4d60acc7840889d567a6936b6e1 outputs:
Exiting @ tick 897173931000 because exiting with last active thread context
and now because:
-
we have no caches, each instruction is fetched from memory
-
each loop contains 11 instructions as shown at Section 36.2, “C busy loop”
-
and supposing that the loop dominated executable pre/post
main, which we know is true since as shown in Benchmark emulators on userland executables an empty dynamically linked C program only as about 100k instructions, while our loop runs 1000000 * 11 = 12M.
we should have about 1000000 * 11 / 897173931000 ps ~ 12260722 ~ 12MB/s of random accesses. The default memory type used is DDR3_1600_8x8 as per:
common/Options.py:101: parser.add_option("--mem-type", type="choice", default="DDR3_1600_8x8
and according to https://en.wikipedia.org/wiki/DDR3_SDRAM that reaches 6400 MB/s so we are only off by a factor of 50x :-) TODO. Maybe if the minimum transaction if 64 bytes, we would be on point.
Another example we could use later on is userland/gcc/busy_loop.c, but then that mixes icache and dcache accesses, so the analysis is a bit more complex:
./run --arch aarch64 --cli-args 0x1000000 --emulator gem5 --userland userland/gcc/busy_loop.c -- --cpu-type TimingSimpleCPU
24.3.3.2. Memory size
Can be set across emulators with:
./run --memory 512M
We can verify this on the guest directly from the kernel with:
cat /proc/meminfo
as of LKMC 1e969e832f66cb5a72d12d57c53fb09e9721d589 this output contains:
MemTotal: 498472 kB
which we expand with:
printf '0x%X\n' $((498472 * 1024))
to:
0x1E6CA000
TODO: why is this value a bit smaller than 512M?
free also gives the same result:
free -b
contains:
total used free shared buffers cached Mem: 510435328 20385792 490049536 0 503808 2760704 -/+ buffers/cache: 17121280 493314048 Swap: 0 0 0
which we expand with:
printf '0x%X\n' 510435328$((498472 * 1024)
man free from Ubuntu’s procps 3.3.15 tells us that free obtains this information from /proc/meminfo as well.
From C, we can get this information with sysconf(_SC_PHYS_PAGES) or get_phys_pages():
./linux/total_memory.out
Source: userland/linux/total_memory.c
Output:
sysconf(_SC_PHYS_PAGES) * sysconf(_SC_PAGESIZE) = 0x1E6CA000 sysconf(_SC_AVPHYS_PAGES) * sysconf(_SC_PAGESIZE) = 0x1D178000 get_phys_pages() * sysconf(_SC_PAGESIZE) = 0x1E6CA000 get_avphys_pages() * sysconf(_SC_PAGESIZE) = 0x1D178000
This is mentioned at: https://stackoverflow.com/questions/22670257/getting-ram-size-in-c-linux-non-precise-result/22670407#22670407
AV means available and gives the free memory: https://stackoverflow.com/questions/14386856/c-check-available-ram/57659190#57659190
24.3.3.3. gem5 DRAM setup
This can be explored pretty well from gem5 config.ini.
se.py just has a single DDR3_1600_8x8 DRAM with size given as Memory size and physical address starting at 0.
fs.py also has that DDR3_1600_8x8 DRAM, but can have more memory types. Notably, aarch64 has as shown on RealView.py VExpress_GEM5_Base:
0x00000000-0x03ffffff: ( 0 - 64 MiB) Boot memory (CS0) 0x04000000-0x07ffffff: ( 64 MiB - 128 MiB) Reserved 0x08000000-0x0bffffff: (128 MiB - 192 MiB) NOR FLASH0 (CS0 alias) 0x0c000000-0x0fffffff: (192 MiB - 256 MiB) NOR FLASH1 (Off-chip, CS4) 0x80000000-XxXXXXXXXX: ( 2 GiB - ) DRAM
We place the entry point of our baremetal executables right at the start of DRAM with our Baremetal linker script.
This can be seen indirectly with:
./getvar --arch aarch64 --emulator gem5 entry_address
which gives 0x80000000 in decimal, or more directly with some some gem5 tracing:
./run \ --arch aarch64 \ --baremetal baremetal/arch/aarch64/no_bootloader/exit.S \ --emulator gem5 \ --trace ExecAll,-ExecSymbol \ --trace-stdout \ ;
and we see that the first instruction runs at 0x80000000:
0: system.cpu: A0 T0 : 0x80000000
TODO: what are the boot memory and NOR FLASH used for?
24.3.4. gem5 disk and network latency
TODO These look promising:
--ethernet-linkspeed --ethernet-linkdelay
and also: gem5-dist: https://publish.illinois.edu/icsl-pdgem5/
24.3.5. gem5 clock frequency
As of gem5 872cb227fdc0b4d60acc7840889d567a6936b6e1 defaults to 2GHz for fs.py:
parser.add_option("--cpu-clock", action="store", type="string",
default='2GHz',
help="Clock for blocks running at CPU speed")
We can check that very easily by looking at the timestamps of a Exec trace of an gem5 AtomicSimpleCPU without any caches:
./run \ --arch aarch64 \ --emulator gem5 \ --userland userland/arch/aarch64/freestanding/linux/hello.S \ --trace-insts-stdout \ ;
which shows:
0: system.cpu: A0 T0 : @asm_main_after_prologue : movz x0, #1, #0 : IntAlu : D=0x0000000000000001 flags=(IsInteger)
500: system.cpu: A0 T0 : @asm_main_after_prologue+4 : adr x1, #28 : IntAlu : D=0x0000000000400098 flags=(IsInteger)
1000: system.cpu: A0 T0 : @asm_main_after_prologue+8 : ldr w2, #4194464 : MemRead : D=0x0000000000000006 A=0x4000a0 flags=(IsInteger|IsMemRef|IsLoad)
1500: system.cpu: A0 T0 : @asm_main_after_prologue+12 : movz x8, #64, #0 : IntAlu : D=0x0000000000000040 flags=(IsInteger)
2000: system.cpu: A0 T0 : @asm_main_after_prologue+16 : svc #0x0 : IntAlu : flags=(IsSerializeAfter|IsNonSpeculative|IsSyscall)
hello
2500: system.cpu: A0 T0 : @asm_main_after_prologue+20 : movz x0, #0, #0 : IntAlu : D=0x0000000000000000 flags=(IsInteger)
3000: system.cpu: A0 T0 : @asm_main_after_prologue+24 : movz x8, #93, #0 : IntAlu : D=0x000000000000005d flags=(IsInteger)
3500: system.cpu: A0 T0 : @asm_main_after_prologue+28 : svc #0x0 : IntAlu : flags=(IsSerializeAfter|IsNonSpeculative|IsSyscall)
so we see that it runs one instruction every 500 ps which makes up 2GHz.
So if we change the frequency to say 1GHz and re-run it:
./run \ --arch aarch64 \ --emulator gem5 \ --userland userland/arch/aarch64/freestanding/linux/hello.S \ --trace-insts-stdout \ -- \ --cpu-clock 1GHz \ ;
we get as expected:
0: system.cpu: A0 T0 : @asm_main_after_prologue : movz x0, #1, #0 : IntAlu : D=0x0000000000000001 flags=(IsInteger) 1000: system.cpu: A0 T0 : @asm_main_after_prologue+4 : adr x1, #28 : IntAlu : D=0x0000000000400098 flags=(IsInteger) 2000: system.cpu: A0 T0 : @asm_main_after_prologue+8 : ldr w2, #4194464 : MemRead : D=0x0000000000000006 A=0x4000a0 flags=(IsInteger|IsMemRef|IsLoad) 3000: system.cpu: A0 T0 : @asm_main_after_prologue+12 : movz x8, #64, #0 : IntAlu : D=0x0000000000000040 flags=(IsInteger) 4000: system.cpu: A0 T0 : @asm_main_after_prologue+16 : svc #0x0 : IntAlu : flags=(IsSerializeAfter|IsNonSpeculative|IsSyscall) hello 5000: system.cpu: A0 T0 : @asm_main_after_prologue+20 : movz x0, #0, #0 : IntAlu : D=0x0000000000000000 flags=(IsInteger) 6000: system.cpu: A0 T0 : @asm_main_after_prologue+24 : movz x8, #93, #0 : IntAlu : D=0x000000000000005d flags=(IsInteger) 7000: system.cpu: A0 T0 : @asm_main_after_prologue+28 : svc #0x0 : IntAlu : flags=(IsSerializeAfter|IsNonSpeculative|IsSyscall)
As of gem5 872cb227fdc0b4d60acc7840889d567a6936b6e1, but like gem5 cache size, does not get propagated to the guest, and is not for example visible at:
ls /sys/devices/system/cpu/cpu0/cpufreq
24.4. gem5 kernel command line parameters
Analogous to QEMU:
./run --arch arm --kernel-cli 'init=/lkmc/linux/poweroff.out' --emulator gem5
Internals: when we give --command-line= to gem5, it overrides default command lines, including some mandatory ones which are required to boot properly.
Our run script hardcodes the require options in the default --command-line and appends extra options given by -e.
To find the default options in the first place, we removed --command-line and ran:
./run --arch arm --emulator gem5
and then looked at the line of the Linux kernel that starts with:
Kernel command line:
24.5. gem5 GDB step debug
24.5.1. gem5 GDB step debug kernel
Analogous to QEMU, on the first shell:
./run --arch arm --emulator gem5 --gdb-wait
On the second shell:
./run-gdb --arch arm --emulator gem5
On a third shell:
./gem5-shell
When you want to break, just do a Ctrl-C on GDB shell, and then continue.
And we now see the boot messages, and then get a shell. Now try the ./count.sh procedure described for QEMU at: Section 3.2, “GDB step debug kernel post-boot”.
24.5.2. gem5 GDB step debug userland process
We are unable to use gdbserver because of networking as mentioned at: Section 15.3.1.3, “gem5 host to guest networking”
The alternative is to do as in GDB step debug userland processes.
Next, follow the exact same steps explained at GDB step debug userland non-init without --gdb-wait, but passing --emulator gem5 to every command as usual.
But then TODO (I’ll still go crazy one of those days): for arm, while debugging ./linux/myinsmod.out hello.ko, after then line:
23 if (argc < 3) {
24 params = "";
I press n, it just runs the program until the end, instead of stopping on the next line of execution. The module does get inserted normally.
TODO:
./run-gdb --arch arm --emulator gem5 --userland gem5-1.0/gem5/util/m5/m5 main
breaks when m5 is run on guest, but does not show the source code.
24.5.3. gem5 GDB step debug secondary cores
gem5’s secondary core GDB setup is a hack and spawns one gdbserver for each core in separate ports, e.g. 7000, 7001, etc.
Partly because of this, it is basically unusable/very hard to use, because you can’t attach to a core that is stopped either because it hasn’t been initialized, or if you are already currently debugging another core.
This affects both full system and userland, and is described in more detail at: https://gem5.atlassian.net/browse/GEM5-626
In LKMC 0a3ce2f41f12024930bcdc74ff646b66dfc46999, we can easily test attaching to another core by passing --run-id, e.g. to connect to the second core we can use --run-id 1:
./run-gdb --arch aarch64 --emulator gem5 --userland userland/gcc/busy_loop.c --run-id 1
24.6. gem5 checkpoint
Analogous to QEMU’s Snapshot, but better since it can be started from inside the guest, so we can easily checkpoint after a specific guest event, e.g. just before init is done.
Documentation: http://gem5.org/Checkpoints
To see it in action try:
./run --arch aarch64 --emulator gem5
In the guest, wait for the boot to end and run:
m5 checkpoint
where gem5 m5 executable is a guest utility present inside the gem5 tree which we cross-compiled and installed into the guest.
To restore the checkpoint, kill the VM and run:
./run --arch arm --emulator gem5 --gem5-restore 1
The --gem5-restore option restores the checkpoint that was created most recently.
Let’s create a second checkpoint to see how it works, in guest:
date >f m5 checkpoint
Kill the VM, and try it out:
./run --arch arm --emulator gem5 --gem5-restore 1
Here we use --gem5-restore 1 again, since the second snapshot we took is now the most recent one
Now in the guest:
cat f
contains the date. The file f wouldn’t exist had we used the first checkpoint with --gem5-restore 2, which is the second most recent snapshot taken.
If you automate things with Kernel command line parameters as in:
./run --arch arm --eval 'm5 checkpoint;m5 resetstats;dhrystone 1000;m5 exit' --emulator gem5
Then there is no need to pass the kernel command line again to gem5 for replay:
./run --arch arm --emulator gem5 --gem5-restore 1
since boot has already happened, and the parameters are already in the RAM of the snapshot.
24.6.1. gem5 checkpoint userland minimal example
In order to debug checkpoint restore bugs, this minimal setup using userland/freestanding/gem5_checkpoint.S can be handy:
./build-userland --arch aarch64 --static ./run --arch aarch64 --emulator gem5 --static --userland userland/freestanding/gem5_checkpoint.S --trace-insts-stdout ./run --arch aarch64 --emulator gem5 --static --userland userland/freestanding/gem5_checkpoint.S --trace-insts-stdout --gem5-restore 1 ./run --arch aarch64 --emulator gem5 --static --userland userland/freestanding/gem5_checkpoint.S --trace-insts-stdout --gem5-restore 1 -- --cpu-type=DerivO3CPU --restore-with-cpu=DerivO3CPU --caches
On the initial run, we see that all instructions are executed and the checkpoint is taken:
0: system.cpu: A0 T0 : @asm_main_after_prologue : movz x0, #0, #0 : IntAlu : D=0x0000000000000000 flags=(IsInteger)
500: system.cpu: A0 T0 : @asm_main_after_prologue+4 : movz x1, #0, #0 : IntAlu : D=0x0000000000000000 flags=(IsInteger)
1000: system.cpu: A0 T0 : @asm_main_after_prologue+8 : m5checkpoint : IntAlu : flags=(IsInteger|IsNonSpeculative|IsUnverifiable)
Writing checkpoint
warn: Checkpoints for file descriptors currently do not work.
info: Entering event queue @ 1000. Starting simulation...
1500: system.cpu: A0 T0 : @asm_main_after_prologue+12 : movz x0, #0, #0 : IntAlu : D=0x0000000000000000 flags=(IsInteger)
2000: system.cpu: A0 T0 : @asm_main_after_prologue+16 : m5exit : No_OpClass : flags=(IsInteger|IsNonSpeculative)
Exiting @ tick 2000 because m5_exit instruction encountered
Then, on the first restore run, the checkpoint is restored, and only instructions after the checkpoint are executed:
info: Entering event queue @ 1000. Starting simulation... 1500: system.cpu: A0 T0 : @asm_main_after_prologue+12 : movz x0, #0, #0 : IntAlu : D=0x0000000000000000 flags=(IsInteger) 2000: system.cpu: A0 T0 : @asm_main_after_prologue+16 : m5exit : No_OpClass : flags=(IsInteger|IsNonSpeculative) Exiting @ tick 2000 because m5_exit instruction encountered
and a similar thing happens for the restore with a different CPU type:
info: Entering event queue @ 1000. Starting simulation... 79000: system.cpu: A0 T0 : @asm_main_after_prologue+12 : movz x0, #0, #0 : IntAlu : D=0x0000000000000000 FetchSeq=1 CPSeq=1 flags=(IsInteger) Exiting @ tick 84500 because m5_exit instruction encountered
Here we don’t see the last m5 exit instruction on the log, but it must just be something to do with the O3 logging.
24.6.2. gem5 checkpoint internals
A quick way to get a gem5 syscall emulation mode or full system checkpoint to observe is:
./run --arch aarch64 --emulator gem5 --baremetal userland/freestanding/gem5_checkpoint.S --trace-insts-stdout ./run --arch aarch64 --emulator gem5 --userland userland/freestanding/gem5_checkpoint.S --trace-insts-stdout
Checkpoints are stored inside the m5out directory at:
"$(./getvar --emulator gem5 m5out_dir)/cpt.<checkpoint-time>"
where <checkpoint-time> is the cycle number at which the checkpoint was taken.
fs.py exposes the -r N flag to restore checkpoints, which N-th checkpoint with the largest <checkpoint-time>: https://github.com/gem5/gem5/blob/e02ec0c24d56bce4a0d8636a340e15cd223d1930/configs/common/Simulation.py#L118
However, that interface is bad because if you had taken previous checkpoints, you have no idea what N to use, unless you memorize which checkpoint was taken at which cycle.
Therefore, just use our superior --gem5-restore flag, which uses directory timestamps to determine which checkpoint you created most recently.
The -r N integer value is just pure fs.py sugar, the backend at m5.instantiate just takes the actual tracepoint directory path as input.
The file m5out/cpt.1000/m5.cpt contains almost everything in the checkpoint except memory.
It is a Python configparser compatible file with a section structure that matches the SimObject tree e.g.:
[system.cpu.itb.walker.power_state] currState=0 prvEvalTick=0
When a checkpoint is taken, each SimObject calls its overridden serialize method to generate the checkpoint, and when loading, unserialize is called.
24.6.3. gem5 checkpoint restore and run a different script
You want to automate running several tests from a single pristine post-boot state.
The problem is that boot takes forever, and after the checkpoint, the memory and disk states are fixed, so you can’t for example:
-
hack up an existing rc script, since the disk is fixed
-
inject new kernel boot command line options, since those have already been put into memory by the bootloader
There is however a few loopholes, m5 readfile being the simplest, as it reads whatever is present on the host.
So we can do it like:
# Boot, checkpoint and exit. printf 'echo "setup run";m5 exit' > "$(./getvar gem5_readfile_file)" ./run --emulator gem5 --eval 'm5 checkpoint;m5 readfile > /tmp/gem5.sh && sh /tmp/gem5.sh' # Restore and run the first benchmark. printf 'echo "first benchmark";m5 exit' > "$(./getvar gem5_readfile_file)" ./run --emulator gem5 --gem5-restore 1 # Restore and run the second benchmark. printf 'echo "second benchmark";m5 exit' > "$(./getvar gem5_readfile_file)" ./run --emulator gem5 --gem5-restore 1 # If something weird happened, create an interactive shell to examine the system. printf 'sh' > "$(./getvar gem5_readfile_file)" ./run --emulator gem5 --gem5-restore 1
Since this is such a common setup, we provide the following helpers for this operation:
-
./run --gem5-readfileis a convenient way to set them5 readfilefile contents from a string in the command line, e.g.:# Boot, checkpoint and exit. ./run --emulator gem5 --eval './gem5.sh' --gem5-readfile 'echo "setup run"' # Restore and run the first benchmark. ./run --emulator gem5 --gem5-restore 1 --gem5-readfile 'echo "first benchmark"' # Restore and run the second benchmark. ./run --emulator gem5 --gem5-restore 1 --gem5-readfile 'echo "second benchmark"'
-
rootfs_overlay/lkmc/gem5.sh. This script is analogous to gem5’s in-tree hack_back_ckpt.rcS, but with less noise.
Usage:
# Boot, checkpoint and exit. ./run --emulator gem5 --eval './gem5.sh' --gem5-readfile 'echo "setup run"' # Restore and run the first benchmark. ./run --emulator gem5 --gem5-restore 1 --gem5-readfile 'echo "first benchmark"' # Restore and run the second benchmark. ./run --emulator gem5 --gem5-restore 1 --gem5-readfile 'echo "second benchmark"'
Their usage is also exemplified at gem5 run benchmark.
If you forgot to use an appropriate --eval for your boot and the simulation is already running, rootfs_overlay/lkmc/gem5.sh can be used directly from an interactive guest shell.
First we reset the readfile to something that runs quickly:
printf 'echo "first benchmark"' > "$(./getvar gem5_readfile_file)"
and then in the guest, take a checkpoint and exit with:
./gem5.sh
Now the guest is in a state where readfile will be executed automatically without interactive intervention:
./run --emulator gem5 --gem5-restore 1 --gem5-readfile 'echo "first benchmark"' ./run --emulator gem5 --gem5-restore 1 --gem5-readfile 'echo "second benchmark"'
Other loophole possibilities to execute different benchmarks non-interactively include:
-
expectas mentioned at: https://stackoverflow.com/questions/7013137/automating-telnet-session-using-bash-scripts#!/usr/bin/expect spawn telnet localhost 3456 expect "# $" send "pwd\r" send "ls /\r" send "m5 exit\r" expect eof
This is ugly however as it is not deterministic.
24.6.4. gem5 restore checkpoint with a different CPU
gem5 can switch to a different CPU model when restoring a checkpoint.
A common combo is to boot Linux with a fast CPU, make a checkpoint and then replay the benchmark of interest with a slower CPU.
This can be observed interactively in full system with:
./run --arch aarch64 --emulator gem5
Then in the guest terminal after boot ends:
sh -c 'm5 checkpoint;sh' m5 exit
And then restore the checkpoint with a different slower CPU:
./run --arch arm --emulator gem5 --gem5-restore 1 -- --caches --cpu-type=DerivO3CPU
And now you will notice that everything happens much slower in the guest terminal!
One even more direct and minimal way to observe this is with userland/freestanding/gem5_checkpoint.S which was mentioned at gem5 checkpoint userland minimal example plus some logging:
./run \ --arch aarch64 \ --emulator gem5 \ --static \ --trace ExecAll,FmtFlag,O3CPU,SimpleCPU \ --userland userland/freestanding/gem5_checkpoint.S \ ; cat "$(./getvar --arch aarch64 --emulator gem5 trace_txt_file)" ./run \ --arch aarch64 \ --emulator gem5 \ --gem5-restore 1 \ --static \ --trace ExecAll,FmtFlag,O3CPU,SimpleCPU \ --userland userland/freestanding/gem5_checkpoint.S \ -- \ --caches \ --cpu-type DerivO3CPU \ --restore-with-cpu DerivO3CPU \ ; cat "$(./getvar --arch aarch64 --emulator gem5 trace_txt_file)"
At gem5 2235168b72537535d74c645a70a85479801e0651, the first run does everything in AtomicSimpleCPU:
...
0: SimpleCPU: system.cpu.dcache_port: received snoop pkt for addr:0x1f92 WriteReq
0: SimpleCPU: system.cpu.dcache_port: received snoop pkt for addr:0x1e40 WriteReq
0: SimpleCPU: system.cpu.dcache_port: received snoop pkt for addr:0x1e30 WriteReq
0: SimpleCPU: system.cpu: Tick
0: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue : movz x0, #0, #0 : IntAlu : D=0x0000000000000000 flags=(IsInteger)
500: SimpleCPU: system.cpu: Tick
500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+4 : movz x1, #0, #0 : IntAlu : D=0x0000000000000000 flags=(IsInteger)
1000: SimpleCPU: system.cpu: Tick
1000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+8 : m5checkpoint : IntAlu : flags=(IsInteger|IsNonSpeculative|IsUnverifiable)
1000: SimpleCPU: system.cpu: Resume
1500: SimpleCPU: system.cpu: Tick
1500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+12 : movz x0, #0, #0 : IntAlu : D=0x0000000000000000 flags=(IsInteger)
2000: SimpleCPU: system.cpu: Tick
2000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+16 : m5exit : No_OpClass : flags=(IsInteger|IsNonSpeculative)
and after restore we see as expected a single ExecEnable instruction executed amidst O3CPU noise:
FullO3CPU: Ticking main, FullO3CPU. 79000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+12 : movz x0, #0, #0 : IntAlu : D=0x0000000000000000 FetchSeq=1 CPSeq=1 flags=(IsInteger) 82500: O3CPU: system.cpu: Removing committed instruction [tid:0] PC (0x400084=>0x400088).(0=>1) [sn:1] 82500: O3CPU: system.cpu: Removing instruction, [tid:0] [sn:1] PC (0x400084=>0x400088).(0=>1) 82500: O3CPU: system.cpu: Scheduling next tick! 83000: O3CPU: system.cpu:
which is the movz after the checkpoint. The final m5exit does not appear due to DerivO3CPU logging insanity.
Bibliography:
24.6.4.1. gem5 fast forward
Besides switching CPUs after a checkpoint restore, fs.py also has the --fast-forward option to automatically run the script from the start on a less detailed CPU, and switch to a more detailed CPU at a given tick.
This is generally useless compared to checkpoint restoring because:
-
checkpoint restore allows to run multiple contents after the restore, and restoring to multiple different system states, which you almost always want to do
-
we generally don’t know the exact tick at which the region of interest will start, especially as the binaries change. It is much easier to just instrument the content with a checkoint m5op
But let’s give it a try anyway with userland/freestanding/gem5_checkpoint.S which was mentioned at gem5 checkpoint userland minimal example
./run \ --arch aarch64 \ --emulator gem5 \ --static \ --trace ExecAll,FmtFlag,O3CPU,SimpleCPU \ --userland userland/freestanding/gem5_checkpoint.S \ -- \ --caches --cpu-type DerivO3CPU \ --fast-forward 1000 \ ; cat "$(./getvar --arch aarch64 --emulator gem5 trace_txt_file)"
At gem5 2235168b72537535d74c645a70a85479801e0651 we see something like:
0: O3CPU: system.switch_cpus: Creating O3CPU object.
0: O3CPU: system.switch_cpus: Workload[0] process is 0 0: SimpleCPU: system.cpu: ActivateContext 0
0: SimpleCPU: system.cpu.dcache_port: received snoop pkt for addr:0 WriteReq
0: SimpleCPU: system.cpu.dcache_port: received snoop pkt for addr:0x40 WriteReq
...
0: SimpleCPU: system.cpu.dcache_port: received snoop pkt for addr:0x1f92 WriteReq
0: SimpleCPU: system.cpu.dcache_port: received snoop pkt for addr:0x1e40 WriteReq
0: SimpleCPU: system.cpu.dcache_port: received snoop pkt for addr:0x1e30 WriteReq
0: SimpleCPU: system.cpu: Tick
0: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue : movz x0, #0, #0 : IntAlu : D=0x0000000000000000 flags=(IsInteger)
500: SimpleCPU: system.cpu: Tick
500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+4 : movz x1, #0, #0 : IntAlu : D=0x0000000000000000 flags=(IsInteger)
1000: SimpleCPU: system.cpu: Tick
1000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+8 : m5checkpoint : IntAlu : flags=(IsInteger|IsNonSpeculative|IsUnverifiable)
1000: O3CPU: system.switch_cpus: [tid:0] Calling activate thread.
1000: O3CPU: system.switch_cpus: [tid:0] Adding to active threads list
1500: O3CPU: system.switch_cpus:
FullO3CPU: Ticking main, FullO3CPU.
1500: O3CPU: system.switch_cpus: Scheduling next tick!
2000: O3CPU: system.switch_cpus:
FullO3CPU: Ticking main, FullO3CPU.
2000: O3CPU: system.switch_cpus: Scheduling next tick!
2500: O3CPU: system.switch_cpus:
...
FullO3CPU: Ticking main, FullO3CPU.
44500: ExecEnable: system.switch_cpus: A0 T0 : @asm_main_after_prologue+12 : movz x0, #0, #0 : IntAlu : D=0x00000000000
48000: O3CPU: system.switch_cpus: Removing committed instruction [tid:0] PC (0x400084=>0x400088).(0=>1) [sn:1]
48000: O3CPU: system.switch_cpus: Removing instruction, [tid:0] [sn:1] PC (0x400084=>0x400088).(0=>1)
48000: O3CPU: system.switch_cpus: Scheduling next tick!
48500: O3CPU: system.switch_cpus:
...
We can also compare that to the same log but without --fast-forward and other CPU switch options:
0: SimpleCPU: system.cpu.dcache_port: received snoop pkt for addr:0x1e40 WriteReq
0: SimpleCPU: system.cpu.dcache_port: received snoop pkt for addr:0x1e30 WriteReq
0: SimpleCPU: system.cpu: Tick
0: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue : movz x0, #0, #0 : IntAlu : D=0x0000000000000000 flags=(IsInteger)
500: SimpleCPU: system.cpu: Tick
500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+4 : movz x1, #0, #0 : IntAlu : D=0x0000000000000000 flags=(IsInteger)
1000: SimpleCPU: system.cpu: Tick
1000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+8 : m5checkpoint : IntAlu : flags=(IsInteger|IsNonSpeculative|IsUnverifiable)
1000: SimpleCPU: system.cpu: Resume
1500: SimpleCPU: system.cpu: Tick
1500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+12 : movz x0, #0, #0 : IntAlu : D=0x0000000000000000 flags=(IsInteger)
2000: SimpleCPU: system.cpu: Tick
2000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+16 : m5exit : No_OpClass : flags=(IsInteger|IsNonSpeculative)
Therefore, it is clear that what we wanted happen:
-
up until the tick 1000,
SimpleCPUwas ticking -
after tick 1000, cpu
O3CPUstarted ticking
Bibliography:
24.6.5. gem5 checkpoint upgrader
The in-tree util/cpt_upgrader.py is a tool to upgrade checkpoints taken from an older version of gem5 to be compatible with the newest version, so you can update gem5 without having to re-run the simulation that generated the checkpoints.
For example, whenever a system register is added in ARMv8, old checkpoints break unless upgraded.
Unfortunately, since the process is not very automated (automatable?), and requires manually patching the upgrader every time a new breaking change is done, the upgrader tends to break soon if you try to move many versions of gem5 ahead as of 2020. This is evidenced in bug reports such as this one: https://gem5.atlassian.net/browse/GEM5-472
The script can be used as:
util/cpt_upgrader.py m5out/cpt.1000/m5.cpt
This updates the m5.cpt file in-place, and a m5out/cpt.1000/m5.cpt.bak is generated as a backup of the old file.
The upgrader determines which upgrades are needed by checking the version_tags entry of the checkpoint:
[Globals] version_tags=arm-ccregs arm-contextidr-el2 arm-gem5-gic-ext ...
Each of those tags corresponds to a Python file under util/cpt_upgraders/ e.g. util/cpt_upgraders/arm-ccregs.py.
24.7. Pass extra options to gem5
Remember that in the gem5 command line, we can either pass options to the script being run as in:
build/X86/gem5.opt configs/examples/fs.py --some-option
or to the gem5 executable itself:
build/X86/gem5.opt --some-option configs/examples/fs.py
Pass options to the script in our setup use:
-
get help:
./run --emulator gem5 -- -h
-
boot with the more detailed and slow
HPICPU model:./run --arch arm --emulator gem5 -- --caches --cpu-type=HPI
To pass options to the gem5 executable we expose the --gem5-exe-args option:
-
get help:
./run --gem5-exe-args='-h' --emulator gem5
24.8. m5ops
m5ops are magic instructions which lead gem5 to do magic things, like quitting or dumping stats.
Documentation: http://gem5.org/M5ops
There are two main ways to use m5ops:
m5 is convenient if you only want to take snapshots before or after the benchmark, without altering its source code. It uses the m5ops instructions as its backend.
m5 cannot should / should not be used however:
-
in bare metal setups
-
when you want to call the instructions from inside interest points of your benchmark. Otherwise you add the syscall overhead to the benchmark, which is more intrusive and might affect results.
Why not just hardcode some m5ops instructions as in our example instead, since you are going to modify the source of the benchmark anyway?
24.8.1. gem5 m5 executable
m5 is a guest command line utility that is installed and run on the guest, that serves as a CLI front-end for the m5ops
Its source is present in the gem5 tree: https://github.com/gem5/gem5/blob/6925bf55005c118dc2580ba83e0fa10b31839ef9/util/m5/m5.c
It is possible to guess what most tools do from the corresponding m5ops, but let’s at least document the less obvious ones here.
In LKMC we build m5 with:
./build-m5 --arch aarch64
The m5 executable can be run on User mode simulation as normal with:
./run --arch aarch64 --emulator gem5 --userland "$(./getvar --arch aarch64 out_rootfs_overlay_bin_dir)/m5" --cli-args dumpstats
This can be a good test m5ops since it executes very quickly.
24.8.1.1. m5 exit
End the simulation.
Sane Python scripts will exit gem5 with status 0, which is what fs.py does.
24.8.1.2. m5 dumpstats
Makes gem5 dump one more statistics entry to the gem5 m5out/stats.txt file.
24.8.1.3. m5 fail
End the simulation with a failure exit event:
m5 fail 1
Sane Python scripts would use that as the exit status of gem5, which would be useful for testing purposes, but fs.py at 200281b08ca21f0d2678e23063f088960d3c0819 just prints an error message:
Simulated exit code not 0! Exit code is 1
and exits with status 0.
We then parse that string ourselves in run and exit with the correct status…
TODO: it used to be like that, but it actually got changed to just print the message. Why? https://gem5-review.googlesource.com/c/public/gem5/+/4880
m5 fail is just a superset of m5 exit, which is just:
m5 fail 0
as can be seen from the source: https://github.com/gem5/gem5/blob/50a57c0376c02c912a978c4443dd58caebe0f173/src/sim/pseudo_inst.cc#L303
24.8.1.4. m5 writefile
Send a guest file to the host. 9P is a more advanced alternative.
Guest:
echo mycontent > myfileguest m5 writefile myfileguest myfilehost
Host:
cat "$(./getvar --arch aarch64 --emulator gem5 m5out_dir)/myfilehost"
Does not work for subdirectories, gem5 crashes:
m5 writefile myfileguest mydirhost/myfilehost
24.8.1.5. m5 readfile
Read a host file pointed to by the fs.py --script option to stdout.
Host:
date > "$(./getvar gem5_readfile_file)"
Guest:
m5 readfile
Outcome: date shows on guest.
24.8.1.6. m5 initparam
Ermm, just another m5 readfile that only takes integers and only from CLI options? Is this software so redundant?
Host:
./run --emulator gem5 --gem5-restore 1 -- --initparam 13 ./run --emulator gem5 --gem5-restore 1 -- --initparam 42
Guest:
m5 initparm
Outputs the given paramter.
24.8.1.7. m5 execfile
Trivial combination of m5 readfile + execute the script.
Host:
printf '#!/bin/sh echo asdf ' > "$(./getvar gem5_readfile_file)"
Guest:
touch /tmp/execfile chmod +x /tmp/execfile m5 execfile
Outcome:
adsf
24.8.2. m5ops instructions
There are few different possible instructions that can be used to implement identical m5ops:
-
magic instructions reserved in the encoding space
-
magic addresses: m5ops magic addresses
-
unused Semihosting addresses space on ARM platforms
All of those those methods are exposed through the gem5 m5 executable in-tree executable. You can select which method to use when calling the executable, e.g.:
m5 exit # Same as the above. m5 --inst exit # The address is mandatory if not configured at build time. m5 --addr 0x10010000 exit m5 --semi exit
To make things simpler to understand, you can play around with our own minimized educational m5 subset:
The instructions used by ./c/m5ops.out are present in lkmc/m5ops.h in a very simple to understand and reuse inline assembly form.
To use that file, first rebuild m5ops.out with the m5ops instructions enabled and install it on the root filesystem:
./build-userland \ --arch aarch64 \ --force-rebuild \ userland/c/m5ops.c \ ; ./build-buildroot --arch aarch64
We don’t enable -DLKMC_M5OPS_ENABLE=1 by default on userland executables because we try to use a single image for both gem5, QEMU and native, and those instructions would break the latter two. We enable it in the Baremetal setup by default since we already have different images for QEMU and gem5 there.
Then, from inside gem5 Buildroot setup, test it out with:
# checkpoint ./c/m5ops.out c # dumpstats ./c/m5ops.out d # exit ./c/m5ops.out e # dump resetstats ./c/m5ops.out r
In theory, the cleanest way to add m5ops to your benchmarks would be to do exactly what the m5 tool does:
-
include
include/gem5/asm/generic/m5ops.h -
link with the
.ofile underutil/m5for the correct arch, e.g.m5op_arm_A64.ofor aarch64.
However, I think it is usually not worth the trouble of hacking up the build system of the benchmark to do this, and I recommend just hardcoding in a few raw instructions here and there, and managing it with version control + sed.
Bibliography:
24.8.2.1. m5ops magic addresses
These are magic addresses that when accessed lead to an m5op.
The base address is given by system.m5ops_base, and then each m5op happens at a different address offset form that base.
If system.m5ops_base is 0, then the memory m5ops are disabled.
Note that the address is physical, and therefore when running in full system on top of the Linux kernel, you must first map a virtual to physical address with /dev/mem as mentioned at: Userland physical address experiments.
One advantage of this method is that it can work with gem5 KVM, whereas the magic instructions don’t, since the host cannot handle them and it is hard to hook into that.
A Baremetal example of that can be found at: baremetal/arch/aarch64/no_bootloader/m5_exit_addr.S.
As of gem5 0d5a80cb469f515b95e03f23ddaf70c9fd2ecbf2, fs.py --baremetal disables the memory m5ops however for some reason, therefore you should run that program as:
./run --arch aarch64 --baremetal baremetal/arch/aarch64/no_bootloader/m5_exit_addr.S --emulator gem5 --trace-insts-stdout -- --param 'system.m5ops_base=0x10010000'
TODO failing with:
info: Entering event queue @ 0. Starting simulation... fatal: Unable to find destination for [0x10012100:0x10012108] on system.iobus
24.8.2.2. m5ops instructions interface
Let’s study how the gem5 m5 executable uses them:
-
include/gem5/asm/generic/m5ops.h: defines the magic constants that represent the instructions -
util/m5/m5op_arm_A64.S: use the magic constants that represent the instructions using C preprocessor magic -
util/m5/m5.c: the actual executable. Gets linked tom5op_arm_A64.Swhich defines a function for each m5op.
We notice that there are two different implementations for each arch:
-
magic instructions, which don’t exist in the corresponding arch
-
magic memory addresses on a given page: m5ops magic addresses
Then, in aarch64 magic instructions for example, the lines:
.macro m5op_func, name, func, subfunc
.globl \name
\name:
.long 0xff000110 | (\func << 16) | (\subfunc << 12)
ret
define a simple function function for each m5op. Here we see that:
-
0xff000110is a base mask for the magic non-existing instruction -
\funcand\subfuncare OR-applied on top of the base mask, and define m5op this is.Those values will loop over the magic constants defined in
m5ops.hwith the deferred preprocessor idiom.For example,
exitis0x21due to:#define M5OP_EXIT 0x21
Finally, m5.c calls the defined functions as in:
m5_exit(ints[0]);
Therefore, the runtime "argument" that gets passed to the instruction, e.g. the delay in ticks until the exit for m5 exit, gets passed directly through the aarch64 calling convention.
Keep in mind that for all archs, m5.c does the calls with 64-bit integers:
uint64_t ints[2] = {0,0};
parse_int_args(argc, argv, ints, argc);
m5_fail(ints[1], ints[0]);
Therefore, for example:
-
aarch64 uses
x0for the first argument andx1for the second, since each is 64 bits log already -
arm uses
r0andr1for the first argument, andr2andr3for the second, since each register is only 32 bits long
That convention specifies that x0 to x7 contain the function arguments, so x0 contains the first argument, and x1 the second.
In our m5ops example, we just hardcode everything in the assembly one-liners we are producing.
We ignore the \subfunc since it is always 0 on the ops that interest us.
24.8.2.3. m5op annotations
include/gem5/asm/generic/m5ops.h also describes some annotation instructions.
24.9. gem5 arm Linux kernel patches
https://gem5.googlesource.com/arm/linux/ contains an ARM Linux kernel forks with a few gem5 specific Linux kernel patches on top of mainline created by ARM Holdings on top of a few upstream kernel releases.
Our build script automatically adds that remote for us as gem5-arm.
The patches are optional: the vanilla kernel does boot. But they add some interesting gem5-specific optimizations, instrumentations and device support.
The patches also add defconfigs that are known to work well with gem5.
E.g. for arm v4.9 there is: https://gem5.googlesource.com/arm/linux/+/917e007a4150d26a0aa95e4f5353ba72753669c7/arch/arm/configs/gem5_defconfig.
In order to use those patches and their associated configs, and, we recommend using Linux kernel build variants as:
git -C "$(./getvar linux_source_dir)" fetch gem5-arm:gem5/v4.15 git -C "$(./getvar linux_source_dir)" checkout gem5/v4.15 ./build-linux \ --arch aarch64 \ --custom-config-file-gem5 \ --linux-build-id gem5-v4.15 \ ; git -C "$(./getvar linux_source_dir)" checkout - ./run \ --arch aarch64 \ --emulator gem5 \ --linux-build-id gem5-v4.15 \ ;
QEMU also boots that kernel successfully:
./run \ --arch aarch64 \ --linux-build-id gem5-v4.15 \ ;
but glibc kernel version checks make init fail with:
FATAL: kernel too old
because glibc was built to expect a newer Linux kernel as shown at: Section 11.4.1, “FATAL: kernel too old failure in userland simulation”. Your choices to solve this are:
-
see if there is a more recent gem5 kernel available, or port your patch of interest to the newest kernel
-
modify this repo to use uClibc, which is not hard because of Buildroot
-
patch glibc to remove that check, which is easy because glibc is in a submodule of this repo
It is obviously not possible to understand what the Linux kernel fork commits actually do from their commit message, so let’s explain them one by one here as we understand them:
-
drm: Add component-aware simple encoderallows you to see images through VNC, see: Section 14.3, “gem5 graphic mode” -
gem5: Add support for gem5’s extended GIC modeadds support for more than 8 cores, see: Section 24.3.1.2, “gem5 ARM full system with more than 8 cores”
Tested on 649d06d6758cefd080d04dc47fd6a5a26a620874 + 1.
24.9.1. gem5 arm Linux kernel patches boot speedup
We have observed that with the kernel patches, boot is 2x faster, falling from 1m40s to 50s.
With ts, we see that a large part of the difference is at the message:
clocksource: Switched to clocksource arch_sys_counter
which takes 4s on the patched kernel, and 30s on the unpatched one! TODO understand why, especially if it is a config difference, or if it actually comes from a patch.
24.10. m5out directory
When you run gem5, it generates an m5out directory at:
echo $(./getvar --arch arm --emulator gem5 m5out_dir)"
The location of that directory can be set with ./gem5.opt -d, and defaults to ./m5out.
The files in that directory contains some very important information about the run, and you should become familiar with every one of them.
24.10.1. gem5 m5out/system.terminal file
Contains UART output, both from the Linux kernel or from the baremetal system.
Can also be seen live on m5term.
24.10.2. gem5 m5out/system.workload.dmesg file
This file used to be called just m5out/system.dmesg, but the name was changed after the workload refactorings of March 2020.
This file is capable of showing terminal messages that are printk before the serial is enabled as described at: Linux kernel early boot messages.
The file is dumped only on kernel panics which gem5 can detect by the PC address: Exit gem5 on panic.
This mechanism can be very useful to debug the Linux kernel boot if problems happen before the serial is enabled.
This magic mechanism works by activating an event when the PC reaches the printk address, much like gem5 can detect panic by PC and then parsing printk function arguments and buffers!
The relevant source is at src/kern/linux/printk.c.
We can test this mechanism in a controlled way by hacking a panic() into the kernel next to a printk that shows up before the serial is enabled, e.g. on Linux v5.4.3 we could do:
diff --git a/kernel/trace/ftrace.c b/kernel/trace/ftrace.c
index f296d89be757..3e79916322c2 100644
--- a/kernel/trace/ftrace.c
+++ b/kernel/trace/ftrace.c
@@ -6207,6 +6207,7 @@ void __init ftrace_init(void)
pr_info("ftrace: allocating %ld entries in %ld pages\n",
count, count / ENTRIES_PER_PAGE + 1);
+ panic("foobar");
last_ftrace_enabled = ftrace_enabled = 1;
With this, after the panic, system.workload.dmesg contains on LKMC d09a0d97b81582cc88381c4112db631da61a048d aarch64:
[0.000000] Booting Linux on physical CPU 0x0000000000 [0x410fd070] [0.000000] Linux version 5.4.3-dirty (lkmc@f7688b48ac46e9a669e279f1bc167722d5141eda) (gcc version 8.3.0 (Buildroot 2019.11-00002-g157ac499cf)) #1 SMP Thu Jan 1 00:00:00 UTC 1970 [0.000000] Machine model: V2P-CA15 [0.000000] Memory limited to 256MB [0.000000] efi: Getting EFI parameters from FDT: [0.000000] efi: UEFI not found. [0.000000] On node 0 totalpages: 65536 [0.000000] DMA32 zone: 1024 pages used for memmap [0.000000] DMA32 zone: 0 pages reserved [0.000000] DMA32 zone: 65536 pages, LIFO batch:15 [0.000000] percpu: Embedded 29 pages/cpu s79960 r8192 d30632 u118784 [0.000000] pcpu-alloc: s79960 r8192 d30632 u118784 alloc=29*4096 [0.000000] pcpu-alloc: [0] 0 [0.000000] Detected PIPT I-cache on CPU0 [0.000000] CPU features: detected: ARM erratum 832075 [0.000000] CPU features: detected: EL2 vector hardening [0.000000] ARM_SMCCC_ARCH_WORKAROUND_1 missing from firmware [0.000000] Built 1 zonelists, mobility grouping on. Total pages: 64512 [0.000000] Kernel command line: earlyprintk=pl011,0x1c090000 lpj=19988480 rw loglevel=8 mem=256MB root=/dev/sda console_msg_format=syslog nokaslr norandmaps panic=-1 printk.devkmsg=on printk.time=y rw console=ttyAMA0 - lkmc_home=/lkmc [0.000000] Dentry cache hash table entries: 32768 (order: 6, 262144 bytes, linear) [0.000000] Inode-cache hash table entries: 16384 (order: 5, 131072 bytes, linear) [0.000000] mem auto-init: stack:off, heap alloc:off, heap free:off [0.000000] Memory: 233432K/262144K available (6652K kernel code, 792K rwdata, 2176K rodata, 896K init, 659K bss, 28712K reserved, 0K cma-reserved) [0.000000] SLUB: HWalign=64, Order=0-3, MinObjects=0, CPUs=1, Nodes=1 [0.000000] ftrace: allocating 22067 entries in 87 pages
So we see that messages up to the ftrace do show up!
24.10.3. gem5 m5out/stats.txt file
This file contains important statistics about the run:
cat "$(./getvar --arch aarch64 m5out_dir)/stats.txt"
Whenever we run m5 dumpstats or when fs.py and se.py are exiting (TODO other scripts?), a section with the following format is added to that file:
---------- Begin Simulation Statistics ---------- [the stats] ---------- End Simulation Statistics ----------
That file contains several important execution metrics, e.g. number of cycles and several types of cache misses:
system.cpu.numCycles system.cpu.dtb.inst_misses system.cpu.dtb.inst_hits
For x86, it is interesting to try and correlate numCycles with:
In LKMC f42c525d7973d70f4c836d2169cc2bd2893b4197 gem5 5af26353b532d7b5988cf0f6f3d0fbc5087dd1df, the stat file for a C hello world:
./run --arch aarch64 --emulator gem5 --userland userland/c/hello.c
which has a single dump done at the exit, has size 59KB and stat lines of form:
final_tick 91432000 # Number of ticks from beginning of simulation (restored from checkpoints and never reset)
We can reduce the file size by adding the ?desc=False magic suffix to the stat flie name:
--stats-file stats.txt?desc=false
as explained in:
gem5.opt --stats-help
and this reduces the file size to 39KB by removing those excessive comments:
final_tick 91432000
although trailing spaces are still prse
We can further reduce this size by removing spaces from the dumps with this hack:
ccprintf(stream, " |%12s %10s %10s",
ValueToString(value, precision), pdfstr.str(), cdfstr.str());
} else {
- ccprintf(stream, "%-40s %12s %10s %10s", name,
- ValueToString(value, precision), pdfstr.str(), cdfstr.str());
+ ccprintf(stream, "%s %s", name, ValueToString(value, precision));
+ if (pdfstr.rdbuf()->in_avail())
+ stream << " " << pdfstr.str();
+ if (cdfstr.rdbuf()->in_avail())
+ stream << " " << cdfstr.str();
if (descriptions) {
if (!desc.empty())
and after that the file size went down to 21KB.
24.10.3.1. gem5 HDF5 statistics
We can make gem5 dump statistics in the HDF5 format by adding the magic h5:// prefix to the file name as in:
gem5.opt --stats-file h5://stats.h5
as explained in:
gem5.opt --stats-help
This is not exposed in LKMC f42c525d7973d70f4c836d2169cc2bd2893b4197 however, you just have to hack the gem5 CLI for now.
TODO what is the advantage? The generated file for --stats-file h5://stats.h5?desc=False in LKMC f42c525d7973d70f4c836d2169cc2bd2893b4197 gem5 5af26353b532d7b5988cf0f6f3d0fbc5087dd1df for a single dump was 946K, so much larger than the text version seen at gem5 m5out/stats.txt file which was only 59KB max!
We then try to see if it is any better when you have a bunch of dump events:
./run --arch aarch64 --emulator gem5 --userland userland/c/m5ops.c --cli-args 'd 1000'
and there yes, we see that the file size fell from 39MB on stats.txt to 3.2MB on stats.m5, so the increase observed previously was just due to some initial size overhead (considering the patched gem5 with no spaces in the text file).
We also note however that the stat dump made the such a simulation that just loops and dumps considerably slower, from 3s to 15s on 2017 Lenovo ThinkPad P51. Fascinating, we are definitely not disk bound there.
We enable HDF5 on the build by default with USE_HDF5=1. To disable it, you can add USE_HDF5=0 to the build as in:
./build-gem5 -- USE_HDF5=0
Library support is automatically detected, and only built if you have it installed. But there have been some compilation bugs with HDF5, which is why you might want to turn it off sometimes, e.g.: https://gem5.atlassian.net/browse/GEM5-365
24.10.3.2. gem5 only dump selected stats
To prevent the stats file from becoming humongous.
24.10.3.3. Meaning of each gem5 stat
Well, run minimal examples, and reverse engineer them up!
We can start with userland/arch/x86_64/freestanding/linux/hello.S on atomic with gem5 ExecAll trace format.
./run \ --arch aarch64 \ --emulator gem5 \ --userland userland/arch/aarch64/freestanding/linux/hello.S \ --trace ExecAll \ --trace-stdout \ ;
which gives:
0: system.cpu: A0 T0 : @_start : movz x0, #1, #0 : IntAlu : D=0x0000000000000001 flags=(IsInteger)
500: system.cpu: A0 T0 : @_start+4 : adr x1, #28 : IntAlu : D=0x0000000000400098 flags=(IsInteger)
1000: system.cpu: A0 T0 : @_start+8 : ldr w2, #4194464 : MemRead : D=0x0000000000000006 A=0x4000a0 flags=(IsInteger|IsMemRef|IsLoad)
1500: system.cpu: A0 T0 : @_start+12 : movz x8, #64, #0 : IntAlu : D=0x0000000000000040 flags=(IsInteger)
2000: system.cpu: A0 T0 : @_start+16 : svc #0x0 : IntAlu : flags=(IsSerializeAfter|IsNonSpeculative|IsSyscall)
2500: system.cpu: A0 T0 : @_start+20 : movz x0, #0, #0 : IntAlu : D=0x0000000000000000 flags=(IsInteger)
3000: system.cpu: A0 T0 : @_start+24 : movz x8, #93, #0 : IntAlu : D=0x000000000000005d flags=(IsInteger)
3500: system.cpu: A0 T0 : @_start+28 : svc #0x0 : IntAlu : flags=(IsSerializeAfter|IsNonSpeculative|IsSyscall)
The most important stat of all is usually the cycle count, which is a direct measure of performance if you modelled you system well:
sim_ticks 3500 # Number of ticks simulated
Next, sim_insts and sim_ops are often critical:
sim_insts 6 # Number of instructions simulated sim_ops 6 # Number of ops (including micro ops) simulated
sim_ops is like sim_insts but it also includes gem5 microops.
In gem5 syscall emulation mode, syscall instructions are magic, and therefore appear to not be counted, that is why we get 6 instructions instead of 8.
24.10.3.4. gem5 stats internals
This describes the internals of the gem5 m5out/stats.txt file.
GDB call stack to dumpstats:
Stats::pythonDump () at build/ARM/python/pybind11/stats.cc:58 Stats::StatEvent::process() () GlobalEvent::BarrierEvent::process (this=0x555559fa6a80) at build/ARM/sim/global_event.cc:131 EventQueue::serviceOne (this=this@entry=0x555558c36080) at build/ARM/sim/eventq.cc:228 doSimLoop (eventq=0x555558c36080) at build/ARM/sim/simulate.cc:219 simulate (num_cycles=<optimized out>) at build/ARM/sim/simulate.cc:132
Stats::pythonDump does:
void
pythonDump()
{
py::module m = py::module::import("m5.stats");
m.attr("dump")();
}
This calls src/python/m5/stats/init.py in def dump does the main dumping
That function does notably:
for output in outputList:
if output.valid():
output.begin()
for stat in stats_list:
stat.visit(output)
output.end()
begin and end are defined in C++ and output the header and tail respectively
void
Text::begin()
{
ccprintf(*stream, "\n---------- Begin Simulation Statistics ----------\n");
}
void
Text::end()
{
ccprintf(*stream, "\n---------- End Simulation Statistics ----------\n");
stream->flush();
}
stats_list contains the stats, and stat.visit prints them, outputList contains by default just the text output. I don’t see any other types of output in gem5, but likely JSON / binary formats could be envisioned.
Tested in gem5 b4879ae5b0b6644e6836b0881e4da05c64a6550d.
24.10.4. gem5 config.ini
The m5out/config.ini file, contains a very good high level description of the system:
less $(./getvar --arch arm --emulator gem5 m5out_dir)"
That file contains a tree representation of the system, sample excerpt:
[root] type=Root children=system full_system=true [system] type=ArmSystem children=cpu cpu_clk_domain auto_reset_addr_64=false semihosting=Null [system.cpu] type=AtomicSimpleCPU children=dstage2_mmu dtb interrupts isa istage2_mmu itb tracer branchPred=Null [system.cpu_clk_domain] type=SrcClockDomain clock=500
Each node has:
-
a list of child nodes, e.g.
systemis a child ofroot, and bothcpuandcpu_clk_domainare children ofsystem -
a list of parameters, e.g.
system.semihostingisNull, which means that Semihosting was turned off-
the
typeparameter shows is present on every node, and it maps to aPythonobject that inherits fromSimObject.For example,
AtomicSimpleCPUmaps is defined at src/cpu/simple/AtomicSimpleCPU.py.
-
Set custom configs with the --param option of fs.py, e.g. we can make gem5 wait for GDB to connect with:
fs.py --param 'system.cpu[0].wait_for_remote_gdb = True'
More complex settings involving new classes however require patching the config files, although it is easy to hack this up. See for example: patches/manual/gem5-semihost.patch.
Modifying the config.ini file manually does nothing since it gets overwritten every time.
24.10.4.1. gem5 config.dot
The m5out/config.dot file contains a graphviz .dot file that provides a simplified graphical view of a subset of the gem5 config.ini.
This file gets automatically converted to .svg and .pdf, which you can view after running gem5 with:
xdg-open "$(./getvar --arch arm --emulator gem5 m5out_dir)/config.dot.pdf" xdg-open "$(./getvar --arch arm --emulator gem5 m5out_dir)/config.dot.svg"
An example of such file can be seen at: config.dot.svg for a TimingSimpleCPU without caches..
On Ubuntu 20.04, you can also see the dot file "directly" with xdot:
xdot "$(./getvar --arch arm --emulator gem5 m5out_dir)/config.dot"
which is kind of really cool because it allows you to view graph arrows on hover. This can be very useful because the PDF and SVG often overlap so many arrows together that you just can’t know which one is coming from/going to where.
It is worth noting that if you are running a bunch of short simulations, dot/SVG/PDF generation could have a significant impact in simulation startup time, so it is something to watch out for. As per https://gem5-review.googlesource.com/c/public/gem5/+/29232 it can be turned off with:
gem5.opt --dot-config=''
or in LKMC:
./run --gem5-exe-args='--dot-config= --json-config= --dump-config='
The time difference can be readily observed on minimal examples by running gem5 with time.
By looking into gem5 872cb227fdc0b4d60acc7840889d567a6936b6e1 src/python/m5/util/dot_writer.py are can try to remove the SVG/PDF conversion to see if those dominate the runtime:
def do_dot(root, outdir, dotFilename):
if not pydot:
warn("No dot file generated. " +
"Please install pydot to generate the dot file and pdf.")
return
# * use ranksep > 1.0 for for vertical separation between nodes
# especially useful if you need to annotate edges using e.g. visio
# which accepts svg format
# * no need for hoizontal separation as nothing moves horizonally
callgraph = pydot.Dot(graph_type='digraph', ranksep='1.3')
dot_create_nodes(root, callgraph)
dot_create_edges(root, callgraph)
dot_filename = os.path.join(outdir, dotFilename)
callgraph.write(dot_filename)
try:
# dot crashes if the figure is extremely wide.
# So avoid terminating simulation unnecessarily
callgraph.write_svg(dot_filename + ".svg")
callgraph.write_pdf(dot_filename + ".pdf")
except:
warn("failed to generate dot output from %s", dot_filename)
but nope, they don’t, dot_create_nodes and dot_create_edges are the culprits, so the only way to gain speed is to remove .dot generation altogether. It is tempting to do this by default on LKMC and add an option to enable dot generation when desired so we can be a bit faster by default… but I’m lazy to document the option right now. When it annoys me further maybe :-)
24.11. m5term
We use the m5term in-tree executable to connect to the terminal instead of a direct telnet.
If you use telnet directly, it mostly works, but certain interactive features don’t, e.g.:
-
up and down arrows for history navigation
-
tab to complete paths
-
Ctrl-Cto kill processes
TODO understand in detail what m5term does differently than telnet.
24.12. gem5 Python scripts without rebuild
We have made a crazy setup that allows you to just cd into submodules/gem5, and edit Python scripts directly there.
This is not normally possible with Buildroot, since normal Buildroot packages first copy files to the output directory ($(./getvar -a <arch> buildroot_build_build_dir)/<pkg>), and then build there.
So if you modified the Python scripts with this setup, you would still need to ./build to copy the modified files over.
For gem5 specifically however, we have hacked up the build so that we cd into the submodules/gem5 tree, and then do an out of tree build to out/common/gem5.
Another advantage of this method is the we factor out the arm and aarch64 gem5 builds which are identical and large, as well as the smaller arch generic pieces.
Using Buildroot for gem5 is still convenient because we use it to:
-
to cross build
m5for us -
check timestamps and skip the gem5 build when it is not requested
The out of build tree is required, because otherwise Buildroot would copy the output build of all archs to each arch directory, resulting in arch^2 build copies, which is significant.
24.13. gem5 fs_bigLITTLE
By default, we use configs/example/fs.py script.
The --gem5-script biglittle option enables the alternative configs/example/arm/fs_bigLITTLE.py script instead:
./run --arch aarch64 --emulator gem5 --gem5-script biglittle
Advantages over fs.py:
-
more representative of mobile ARM SoCs, which almost always have big little cluster
-
simpler than
fs.py, and therefore easier to understand and modify
Disadvantages over fs.py:
-
only works for ARM, not other archs
-
not as many configuration options as
fs.py, many things are hardcoded
We setup 2 big and 2 small CPUs, but cat /proc/cpuinfo shows 4 identical CPUs instead of 2 of two different types, likely because gem5 does not expose some informational register much like the caches: https://www.mail-archive.com/gem5-users@gem5.org/msg15426.html gem5 config.ini does show that the two big ones are DerivO3CPU and the small ones are MinorCPU.
TODO: why is the --dtb required despite fs_bigLITTLE.py having a DTB generation capability? Without it, nothing shows on terminal, and the simulation terminates with simulate() limit reached @ 18446744073709551615. The magic vmlinux.vexpress_gem5_v1.20170616 works however without a DTB.
Tested on: 18c1c823feda65f8b54cd38e261c282eee01ed9f
24.14. gem5 in-tree tests
All those tests could in theory be added to this repo instead of to gem5, and this is actually the superior setup as it is cross emulator.
But can the people from the project be convinced of that?
24.14.1. gem5 unit tests
These are just very small GTest tests that test a single class in isolation, they don’t run any executables.
Build the unit tests and run them:
./build-gem5 --unit-tests
Running individual unit tests is not yet exposed, but it is easy to do: while running the full tests, GTest prints each test command being run, e.g.:
/path/to/build/ARM/base/circlebuf.test.opt --gtest_output=xml:/path/to/build/ARM/unittests.opt/base/circlebuf.test.xml [==========] Running 4 tests from 1 test case. [----------] Global test environment set-up. [----------] 4 tests from CircleBufTest [ RUN ] CircleBufTest.BasicReadWriteNoOverflow [ OK ] CircleBufTest.BasicReadWriteNoOverflow (0 ms) [ RUN ] CircleBufTest.SingleWriteOverflow [ OK ] CircleBufTest.SingleWriteOverflow (0 ms) [ RUN ] CircleBufTest.MultiWriteOverflow [ OK ] CircleBufTest.MultiWriteOverflow (0 ms) [ RUN ] CircleBufTest.PointerWrapAround [ OK ] CircleBufTest.PointerWrapAround (0 ms) [----------] 4 tests from CircleBufTest (0 ms total) [----------] Global test environment tear-down [==========] 4 tests from 1 test case ran. (0 ms total) [ PASSED ] 4 tests.
so you can just copy paste the command.
Building individual tests is possible with --unit-test (singular, no 's'):
./build-gem5 --unit-test base/circlebuf.test
This does not run the test however.
Note that the command and it’s corresponding results don’t need to show consecutively on stdout because tests are run in parallel. You just have to match them based on the class name CircleBufTest to the file circlebuf.test.cpp.
24.14.2. gem5 regression tests
This section is about running the gem5 in-tree tests.
Running the larger 2019 regression tests is exposed for example with:
./build-gem5 --arch aarch64 ./gem5-regression --arch aarch64 -- --length quick --length long
Sample run time: 87 minutes on 2017 Lenovo ThinkPad P51 Ubuntu 20.04 gem5 872cb227fdc0b4d60acc7840889d567a6936b6e1.
After the first run has downloaded the test binaries for you, you can speed up the process a little bit by skipping an useless SCons call:
./gem5-regression --arch aarch64 -- --length quick --length long --skip-build
Note however that running without --skip-build is required at least once to download the test binaries, because the test interface is bad.
List available instead of running them:
./gem5-regression --arch aarch64 --cmd list -- --length quick --length long
You can then pick one suite (has to be a suite, not an "individual test") from the list and run just it e.g. with:
./gem5-regression --arch aarch64 -- --uid SuiteUID:tests/gem5/cpu_tests/test.py:cpu_test_AtomicSimpleCPU_Bubblesort-ARM-opt
24.15. gem5 simulate() limit reached
This error happens when the following instruction limits are reached:
system.cpu[0].max_insts_all_threads system.cpu[0].max_insts_any_thread
If the parameter is not set, it defaults to 0, which is magic and means the huge maximum value of uint64_t: 0xFFFFFFFFFFFFFFFF, which in practice would require a very long simulation if at least one CPU were live.
So this usually means all CPUs are in a sleep state, and no events are scheduled in the future, which usually indicates a bug in either gem5 or guest code, leading gem5 to blow up.
Still, fs.py at gem5 08c79a194d1a3430801c04f37d13216cc9ec1da3 does not exit with non-zero status due to this… and so we just parse it out just as for m5 fail…
A trivial and very direct way to see message would be:
./run \ --emulator gem5 \ --userland userland/arch/x86_64/freestanding/linux/hello.S \ --trace-insts-stdout \ -- \ --param 'system.cpu[0].max_insts_all_threads = 3' \ ;
which as of lkmc 402059ed22432bb351d42eb10900e5a8e06aa623 runs only the first three instructions and quits!
info: Entering event queue @ 0. Starting simulation...
0: system.cpu A0 T0 : @asm_main_after_prologue : mov rdi, 0x1
0: system.cpu A0 T0 : @asm_main_after_prologue.0 : MOV_R_I : limm rax, 0x1 : IntAlu : D=0x0000000000000001 flags=(IsInteger|IsMicroop|IsLastMicroop|IsFirstMicroop)
1000: system.cpu A0 T0 : @asm_main_after_prologue+7 : mov rdi, 0x1
1000: system.cpu A0 T0 : @asm_main_after_prologue+7.0 : MOV_R_I : limm rdi, 0x1 : IntAlu : D=0x0000000000000001 flags=(IsInteger|IsMicroop|IsLastMicroop|IsFirstMicroop)
2000: system.cpu A0 T0 : @asm_main_after_prologue+14 : lea rsi, DS:[rip + 0x19]
2000: system.cpu A0 T0 : @asm_main_after_prologue+14.0 : LEA_R_P : rdip t7, %ctrl153, : IntAlu : D=0x000000000040008d flags=(IsInteger|IsMicroop|IsDelayedCommit|IsFirstMicroop)
2500: system.cpu A0 T0 : @asm_main_after_prologue+14.1 : LEA_R_P : lea rsi, DS:[t7 + 0x19] : IntAlu : D=0x00000000004000a6 flags=(IsInteger|IsMicroop|IsLastMicroop)
Exiting @ tick 3000 because all threads reached the max instruction count
The exact same can be achieved with the older hardcoded --maxinsts mechanism present in se.py and fs.py:
./run \ --emulator gem5 \ --userland \userland/arch/x86_64/freestanding/linux/hello.S \ --trace-insts-stdout \ -- \ --maxinsts 3 ;
Other related fs.py options are:
-
--abs-max-tick: set the maximum guest simulation time. The same scale as the ExecAll trace is used. E.g., for the above example with 3 instructions, the same trace would be achieved with a value of 3000.
The message also shows on User mode simulation deadlocks, for example in userland/posix/pthread_deadlock.c:
./run \ --emulator gem5 \ --userland userland/posix/pthread_deadlock.c \ --cli-args 1 \ ;
ends in:
Exiting @ tick 18446744073709551615 because simulate() limit reached
where 18446744073709551615 is 0xFFFFFFFFFFFFFFFF in decimal.
And there is a Baremetal example at baremetal/arch/aarch64/no_bootloader/wfe_loop.S that dies on WFE:
./run \ --arch aarch64 \ --baremetal baremetal/arch/aarch64/no_bootloader/wfe_loop.S \ --emulator gem5 \ --trace-insts-stdout \ ;
which gives:
info: Entering event queue @ 0. Starting simulation...
0: system.cpu A0 T0 : @lkmc_start : wfe : IntAlu : D=0x0000000000000000 flags=(IsSerializeAfter|IsNonSpeculative|IsQuiesce|IsUnverifiable)
1000: system.cpu A0 T0 : @lkmc_start+4 : b <lkmc_start> : IntAlu : flags=(IsControl|IsDirectControl|IsUncondControl)
1500: system.cpu A0 T0 : @lkmc_start : wfe : IntAlu : D=0x0000000000000000 flags=(IsSerializeAfter|IsNonSpeculative|IsQuiesce|IsUnverifiable)
Exiting @ tick 18446744073709551615 because simulate() limit reached
Other examples of the message:
-
ARM baremetal multicore with a single CPU stays stopped at an WFE sleep instruction
-
this sample bug on se.py multithreading: https://github.com/cirosantilli/linux-kernel-module-cheat/issues/81
24.16. gem5 build options
In order to use different build options, you might also want to use gem5 build variants to keep the build outputs separate from one another.
24.16.1. gem5 debug build
How to use it in LKMC: Section 23.8, “Debug the emulator”.
If you build gem5 with scons build/ARM/gem5.debug, then that is a .debug build.
It relates to the more common .opt build just as explained at Section 23.8, “Debug the emulator”: both .opt and .debug have -g, but .opt uses -O2 while .debug uses -O0.
24.16.2. gem5 fast build
./build-gem5 --gem5-build-type fast
How it goes faster is explained at: https://stackoverflow.com/questions/59860091/how-to-increase-the-simulation-speed-of-a-gem5-run/59861375#59861375
Disables debug symbols (no -g) for some reason.
Benchmarks present at:
24.16.3. gem5 prof and perf builds
Profiling builds as of 3cea7d9ce49bda49c50e756339ff1287fd55df77 both use: -g -O3 and disable asserts and logging like the gem5 fast build and:
-
profuses-pgfor gprof -
perfuses-lprofilefor google-pprof
Profiling techniques are discussed in more detail at: Profiling userland programs.
For the prof build, you can get the gmon.out file with:
./run --arch aarch64 --emulator gem5 --userland userland/c/hello.c --gem5-build-type prof gprof "$(./getvar --arch aarch64 gem5_executable)" > tmp.gprof
24.16.4. gem5 clang build
TODO test properly, benchmark vs GCC.
sudo apt-get install clang ./build-gem5 --gem5-clang ./run --emulator gem5 --gem5-clang
24.16.5. gem5 sanitation build
If there gem5 appears to have a C++ undefined behaviour bug, which is often very difficult to track down, you can try to build it with the following extra SCons options:
./build-gem5 --gem5-build-id san --verbose -- --with-ubsan --without-tcmalloc
This will make GCC do a lot of extra sanitation checks at compile and run time.
As a result, the build and runtime will be way slower than normal, but that still might be the fastest way to solve undefined behaviour problems.
Ideally, we should also be able to run it with asan with --with-asan, but if we try then the build fails at gem5 16eeee5356585441a49d05c78abc328ef09f7ace (with two ubsan trivial fixes I’ll push soon):
=================================================================
==9621==ERROR: LeakSanitizer: detected memory leaks
Direct leak of 371712 byte(s) in 107 object(s) allocated from:
#0 0x7ff039804448 in malloc (/usr/lib/x86_64-linux-gnu/libasan.so.5+0x10c448)
#1 0x7ff03950d065 in dictresize ../Objects/dictobject.c:643
Direct leak of 23728 byte(s) in 26 object(s) allocated from:
#0 0x7ff039804448 in malloc (/usr/lib/x86_64-linux-gnu/libasan.so.5+0x10c448)
#1 0x7ff03945e40d in _PyObject_GC_Malloc ../Modules/gcmodule.c:1499
#2 0x7ff03945e40d in _PyObject_GC_Malloc ../Modules/gcmodule.c:1493
Direct leak of 2928 byte(s) in 43 object(s) allocated from:
#0 0x7ff03980487e in __interceptor_realloc (/usr/lib/x86_64-linux-gnu/libasan.so.5+0x10c87e)
#1 0x7ff03951d763 in list_resize ../Objects/listobject.c:62
#2 0x7ff03951d763 in app1 ../Objects/listobject.c:277
#3 0x7ff03951d763 in PyList_Append ../Objects/listobject.c:289
Direct leak of 2002 byte(s) in 3 object(s) allocated from:
#0 0x7ff039804448 in malloc (/usr/lib/x86_64-linux-gnu/libasan.so.5+0x10c448)
#1 0x7ff0394fd813 in PyString_FromStringAndSize ../Objects/stringobject.c:88
#2 0x7ff0394fd813 in PyString_FromStringAndSize ../Objects/stringobject.c:
Direct leak of 40 byte(s) in 2 object(s) allocated from
#0 0x7ff039804448 in malloc (/usr/lib/x86_64-linux-gnu/libasan.so.5+0x10c448)
#1 0x7ff03951ea4b in PyList_New ../Objects/listobject.c:152
Indirect leak of 10384 byte(s) in 11 object(s) allocated from
#0 0x7ff039804448 in malloc (/usr/lib/x86_64-linux-gnu/libasan.so.5+0x10c448
#1 0x7ff03945e40d in _PyObject_GC_Malloc ../Modules/gcmodule.c:
#2 0x7ff03945e40d in _PyObject_GC_Malloc ../Modules/gcmodule.c:1493
Indirect leak of 4089 byte(s) in 6 object(s) allocated from:
#0 0x7ff039804448 in malloc (/usr/lib/x86_64-linux-gnu/libasan.so.5+0x10c448)
#1 0x7ff0394fd648 in PyString_FromString ../Objects/stringobject.c:143
Indirect leak of 2090 byte(s) in 3 object(s) allocated from:
#0 0x7ff039804448 in malloc (/usr/lib/x86_64-linux-gnu/libasan.so.5+0x10c448
#1 0x7ff0394eb36f in type_new ../Objects/typeobject.c:
#2 0x7ff0394eb36f in type_new ../Objects/typeobject.c:2094
Indirect leak of 1346 byte(s) in 2 object(s) allocated from:
#0 0x7ff039804448 in malloc (/usr/lib/x86_64-linux-gnu/libasan.so.5+0x10c448)
#1 0x7ff0394fd813 in PyString_FromStringAndSize ../Objects/stringobject.c:
#2 0x7ff0394fd813 in PyString_FromStringAndSize ../Objects/stringobject.c:
SUMMARY: AddressSanitizer: 418319 byte(s) leaked in 203 allocation(s).
From the message, this appears however to be a Python / pyenv11 bug however and not in gem5 specifically. I think it worked when I tried it in the past in an older gem5 / Ubuntu.
--without-tcmalloc is needed / a good idea when using --with-asan: https://stackoverflow.com/questions/42712555/address-sanitizer-fsanitize-address-works-with-tcmalloc since both do more or less similar jobs, see also Memory leaks.
24.16.6. gem5 Ruby build
gem5 has two types of memory system:
-
the classic memory system, which is used by default, its caches are covered at: gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis with caches
-
the Ruby memory system
The Ruby memory system includes the SLICC domain specific language to describe memory systems: http://gem5.org/Ruby SLICC transpiles to C++ auto-generated files under build/<isa>/mem/ruby/protocol/.
Ruby seems to have usage outside of gem5, but the naming overload with the Ruby programming language, which also has domain specific languages as a concept, makes it impossible to google anything about it!
Since it is not the default, Ruby is generally less stable that the classic memory model. However, because it allows describing a wide variety of important cache coherence protocols, while the classic system only describes a single protocol, Ruby is very importanonly describes a single protocol, Ruby is a very important feature of gem5.
Ruby support must be enabled at compile time with the scons PROTOCOL= flag, which compiles support for the desired memory system type.
Note however that most ISAs already implicitly set PROTOCOL via the build_opts/ directory, e.g. build_opts/ARM contains:
PROTOCOL = 'MOESI_CMP_directory'
and therefore ARM already compiles MOESI_CMP_directory by default.
Then, with fs.py and se.py, you can choose to use either the classic or the ruby system type selected at build time with PROTOCOL= at runtime by passing the --ruby option:
-
if
--rubyis given, use the ruby memory system that was compiled into gem5. Caches are always present when Ruby is used, since the main goal of Ruby is to specify the cache coherence protocol, and it therefore hardcodes cache hierarchies. -
otherwise, use the classic memory system. Caches may be optional for certain CPU types and are enabled with
--caches.
Note that the --ruby option has some crazy side effects besides enabling Ruby, e.g. it sets the default --cpu-type to TimingSimpleCPU instead of the otherwise default AtomicSimpleCPU. TODO: I have been told that this is because sends the packet atomically,atomic requests do not work with Ruby, only timing.
It is not possible to build more than one Ruby system into a single build, and this is a major pain point for testing Ruby: https://gem5.atlassian.net/browse/GEM5-467
For example, to use a two level MESI cache coherence protocol we can do:
./build-gem5 --arch aarch64 --gem5-build-id ruby -- PROTOCOL=MESI_Two_Level ./run --arch aarch64 --emulator -gem5 --gem5-build-id ruby -- --ruby
and during build we see a humongous line of type:
[ SLICC] src/mem/protocol/MESI_Two_Level.slicc -> ARM/mem/protocol/AccessPermission.cc, ARM/mem/protocol/AccessPermission.hh, ...
which shows that dozens of C++ files are being generated from Ruby SLICC.
The relevant Ruby source files live in the source tree under:
src/mem/protocol/MESI_Two_Level*
We already pass the SLICC_HTML flag by default to the build, which generates an HTML summary of each memory protocol under (TODO broken: https://gem5.atlassian.net/browse/GEM5-357):
xdg-open "$(./getvar --arch aarch64 --gem5-build-id ruby gem5_build_build_dir)/ARM/mem/protocol/html/index.html"
A minimized ruby config which was not merged upstream can be found for study at: https://gem5-review.googlesource.com/c/public/gem5/+/13599/1
One easy way to see that Ruby is being used without understanding it in detail is to enable some logging:
./run \ --arch aarch64 \ --emulator gem5 \ --gem5-worktree master \ --userland userland/arch/aarch64/freestanding/linux/hello.S \ --static \ --trace ExecAll,FmtFlag,Ruby,XBar \ -- \ --ruby \ ; cat "$(./getvar --arch aarch64 --emulator gem5 trace_txt_file)"
Then:
-
when the
--rubyflag is given, we see a gazillion Ruby related messages prefixed e.g. byRubyPort:.We also observe from
ExecEnablelines that instruction timing is not simple anymore, so the memory system must have latencies -
without
--ruby, we instead seeXBar(Coherent Crossbar) related messages such asCoherentXBar:, which I believe is the more precise name for the memory model that the classic memory system uses: gem5 crossbar interconnect.
Certain features may not work in Ruby. For example, gem5 checkpoint creation is only possible in Ruby protocols that support flush, which is the case for PROTOCOL=MOESI_hammer but not PROTOCOL=MESI_Three_Level: https://www.mail-archive.com/gem5-users@gem5.org/msg17418.html
Tested in gem5 d7d9bc240615625141cd6feddbadd392457e49eb.
24.16.6.1. gem5 Ruby MI_example protocol
This is the simplest of all protocols, and therefore the first one you should study to learn how Ruby works.
To study it, we can take an approach similar to what was done at: gem5 event queue AtomicSimpleCPU syscall emulation freestanding example analysis with caches and multiple CPUs.
Our full command line will be something like
./build-gem5 --arch aarch64 --gem5-build-id MI_example ./run \ --arch aarch64 \ --cli-args '2 100' \ --cpus 3 \ --emulator gem5 \ --userland userland/cpp/atomic/aarch64_add.cpp \ --gem5-build-id MI_example \ -- \ --ruby \ ;
which produces a config.dot.svg like the following by with 3 CPUs instead of 2:

config.dot.svg for a system with three TimingSimpleCPU CPUs with the Ruby MI_example protocol.24.16.6.2. gem5 crossbar interconnect
Crossbar or XBar in the code, is the default CPU interconnect that gets used by fs.py if --ruby is not given.
It presumably implements a crossbar switch along the lines of: https://en.wikipedia.org/wiki/Crossbar_switch
This is the best introductory example analysis we have so far: gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis with caches and multiple CPUs. It contains more or less the most minimal example in which something interesting can be observed: multiple cores fighting over a single data memory variable.
Long story short: the interconnect contains the snoop mechanism, and it forwards packets coming form caches of a CPU to the caches of other CPUs in which the block is present.
It is therefore the heart of the Cache coherence mechanism, as it informs other caches of bus transactions they need to know about.
TODO: describe it in more detail. It appears to be a very simple mechanism.
Under src/mem/ we see that there is both a coherent and a non-coherent XBar.
In se.py it is set at:
if options.ruby:
...
else:
MemClass = Simulation.setMemClass(options)
system.membus = SystemXBar()
and SystemXBar is defined at src/mem/XBar.py with a nice comment:
# One of the key coherent crossbar instances is the system # interconnect, tying together the CPU clusters, GPUs, and any I/O # coherent masters, and DRAM controllers. class SystemXBar(CoherentXBar):
Tested in gem5 12c917de54145d2d50260035ba7fa614e25317a3.
24.16.7. gem5 Python 3 build
Python 3 support was mostly added in 2019 Q3 at arounda347a1a68b8a6e370334be3a1d2d66675891e0f1 but remained buggy for some time afterwards.
In an Ubuntu 18.04 host where python is python2 by default, build with Python 3 instead with:
./build-gem5 --gem5-build-id python3 -- PYTHON_CONFIG=python3-config
Python 3 is then automatically used when running if you use that build.
24.17. gem5 CPU types
gem5 has a few in tree CPU models for different purposes.
In fs.py and se.py, those are selectable with the --cpu-type option.
The information to make highly accurate models isn’t generally public for non-free CPUs, so either you must either rely vendor provided models or on experiments/reverse engineering.
There is no simple answer for "what is the best CPU", in theory you have to understand each model and decide which one is closer your target system.
Whenever possible, stick to:
-
vendor provide ones obviously, e.g. ARM Holdings models of ARM cores, unless there is good reason not to, as they are the most likely to be accurate
-
newer models instead of older models
Both of those can be checked with git log and git blame.
All CPU types inherit from the BaseCPU class, and looking at the class hierarchy in Eclipse gives a good overview of what we have:
-
BaseCPU-
BaseKvmCPU -
BaseSimpleCPU: gem5BaseSimpleCPU-
AtomicSimpleCPU -
TimingSimpleCPU
-
-
MinorO3CPU: gem5 MinorCPU -
BaseO3CPU-
FullO3CPU-
DerivO3CPU : public FullO3CPU<O3CPUImpl>: gem5DerivO3CPU
-
-
-
From this we see that there are basically only 4 C++ CPU models in gem5: Atomic, Timing, Minor and O3. All others are basically parametrizations of those base types.
24.17.1. List of gem5 CPU types
24.17.1.1. gem5 BaseSimpleCPU
Simple abstract CPU without a pipeline.
They are therefore completely unrealistic. But they also run much faster. KVM CPUs are an alternative way of fast forwarding boot when they work.
Implementations:
24.17.1.1.1. gem5 AtomicSimpleCPU
AtomicSimpleCPU: the default one. Memory accesses happen instantaneously. The fastest simulation except for KVM, but not realistic at all.
24.17.1.1.2. gem5 TimingSimpleCPU
TimingSimpleCPU: memory accesses are realistic, but the CPU has no pipeline. The simulation is faster than detailed models, but slower than AtomicSimpleCPU.
To fully understand TimingSimpleCPU, see: gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis.
Without caches, the CPU just stalls all the time waiting for memory requests for every advance of the PC or memory read from a instruction!
Caches do make a difference here of course, and lead to much faster memory return times.
24.17.1.2. gem5 MinorCPU
Generic in-order superscalar core.
Its C++ implementation that can be parametrized to more closely match real cores.
Note that since gem5 is highly parametrizable, the parametrization could even change which instructions a CPU can execute by altering its available functional units, which are used to model performance.
For example, MinorCPU allows all implemented instructions, including ARM SVE instructions, but a derived class modelling, say, an ARM Cortex A7 core, might not, since SVE is a newer feature and the A7 core does not have SVE.
The weird name "Minor" stands for "M (TODO what is M) IN ONder".
Its 4 stage pipeline is described at the "MinorCPU" section of gem5 ARM RSK.
A commented execution example can be seen at: gem5 event queue MinorCPU syscall emulation freestanding example analysis.
There is also an in-tree doxygen at: src/doc/inside-minor.doxygen and rendered at: http://pages.cs.wisc.edu/~swilson/gem5-docs/minor.html
As of 2019, in-order cores are mostly present in low power/cost contexts, for example little cores of ARM bigLITTLE.
The following models extend the MinorCPU class by parametrization to make it match existing CPUs more closely:
-
HPI: derived fromMinorCPU.Created by Ashkan Tousi in 2017 while working at ARM.
According to gem5 ARM RSK:
The HPI CPU timing model is tuned to be representative of a modern in-order Armv8-A implementation.
-
ex5_LITTLE: derived fromMinorCPU. Description reads:ex5 LITTLE core (based on the ARM Cortex-A7)
Implemented by Pierre-Yves Péneau from LIRMM, which is a research lab in Montpellier, France, in 2017.
24.17.1.3. gem5 DerivO3CPU
Generic out-of-order core. "O3" Stands for "Out Of Order"!
Basic documentation on the old gem5 wiki: http://www.m5sim.org/O3CPU
Analogous to MinorCPU, but modelling an out of order core instead of in order.
A commented execution example can be seen at: gem5 event queue DerivO3CPU syscall emulation freestanding example analysis.
The default functional units are described at: gem5 DerivO3CPU default functional units. All default widths are set to 8 instructions, from the config.ini:
[system.cpu] type=DerivO3CPU commitWidth=8 decodeWidth=8 dispatchWidth=8 fetchWidth=8 issueWidth=8 renameWidth=8 squashWidth=8 wbWidth=8
This can be observed for example at: gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: hazardless.
Existing parametrizations:
-
ex5_big: big corresponding toex5_LITTLE, by same author at same time. It description reads:ex5 big core (based on the ARM Cortex-A15)
-
O3_ARM_v7a: implemented by Ronald Dreslinski from the University of Michigan in 2012Not sure why it has v7a in the name, since I believe the CPUs are just the microarchitectural implementation of any ISA, and the v8 hello world did run.
The CLI option is named slightly differently as:
--cpu-type O3_ARM_v7a_3.
24.17.1.3.1. gem5 DerivO3CPU pipeline stages
-
fetch: besides obviously fetching the instruction, this is also where branch prediction runs. Presumably because you need to branch predict before deciding what to fetch next.
-
retire: the instruction is completely and totally done with.
Mispeculated instructions never reach this stage as can be seen at: gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: speculative.
The
ExecAllhappens at this time as well. And thereforeExecAlldoes not happen for mispeculated instructions.
24.17.1.3.2. gem5 util/o3-pipeview.py O3 pipeline viewer
Mentioned at: http://www.m5sim.org/Visualization
./run \ --arch aarch64 \ --emulator gem5 \ --userland userland/arch/aarch64/freestanding/linux/hello.S \ --trace O3PipeView \ --trace-stdout \ -- \ --cpu-type DerivO3CPU \ --caches \ ; "$(./getvar gem5_source_dir)/util/o3-pipeview.py" -c 500 -o o3pipeview.tmp.log --color "$(./getvar --arch aarch64 trace_txt_file)" less -R o3pipeview.tmp.log
Or without color:
"$(./getvar gem5_source_dir)/util/o3-pipeview.py" -c 500 -o o3pipeview.tmp.log "$(./getvar --arch aarch64 trace_txt_file)" less o3pipeview.tmp.log
A sample output for this can be seen at: [hazardless-o3-pipeline].
24.17.1.3.3. gem5 Konata O3 pipeline viewer
Appears to be browser based, so you can zoom in and out, rather than the forced wrapping as for gem5 util/o3-pipeview.py O3 pipeline viewer.
Uses the same data source as util/o3-pipeview.py.
gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: stall_gain shows how the text-based visualization can get problematic due to stalls requiring wraparounds.
24.17.2. gem5 ARM RSK
Dated 2017, it contains a good overview of gem5 CPUs.
24.18. gem5 ARM platforms
The gem5 platform is selectable with the --machine option, which is named after the analogous QEMU -machine option, and which sets the --machine-type.
Each platform represents a different system with different devices, memory and interrupt setup.
TODO: describe the main characteristics of each platform, as of gem5 5e83d703522a71ec4f3eb61a01acd8c53f6f3860:
-
VExpress_GEM5_V1: good sane base platform -
VExpress_GEM5_V1_DPU:VExpress_GEM5_V1with DP650 instead of HDLCD, selected automatically by./run --dp650, see also: gem5 graphic mode DP650 -
VExpress_GEM5_V2: VExpress_GEM5_V1 with GICv3, uses a different bootloaderarm/aarch64_bootloader/boot_emm_v2.arm64TODO is it because of GICv3? -
anything that does not start with:
VExpress_GEM5_: old and bad, don’t use them
24.19. gem5 upstream images
Present at:
Depending on which archive you download from there, you can find some of:
-
Ubuntu based images
-
precompiled Linux kernels, with the gem5 arm Linux kernel patches for arm
-
precompiled gem5 bootloaders for ISAs that have them, e.g. ARM
-
precompiled DTBs if you don’t want to use autogeneration for some crazy reason
Some of those images are also used on the gem5 unit tests continuous integration.
Could be used as an alternative to this repository. But why would you do that? :-)
E.g. to use a precompiled ARM kernel:
mkdir aarch-system-201901106 cd aarch-system-201901106 wget http://dist.gem5.org/dist/current/arm/aarch-system-201901106.tar.bz2 tar xvf aarch-system-201901106.tar.bz2 cd .. ./run --arch aarch64 --emulator gem5 --linux-exec aarch-system-201901106/binaries/vmlinux.arm64
24.20. gem5 bootloaders
Certain ISAs like ARM have bootloaders that are automatically run before the main image to setup basic system state.
We cross compile those bootloaders from source automatically during ./build-gem5.
As of gem5 bcf041f257623e5c9e77d35b7531bae59edc0423, the source code of the bootloaderes can be found under:
system/arm/
and their selection can be seen under: src/dev/arm/RealView.py, e.g.:
def setupBootLoader(self, cur_sys, loc):
if not cur_sys.boot_loader:
cur_sys.boot_loader = [ loc('boot_emm.arm64'), loc('boot_emm.arm') ]
The bootloader basically just sets up a bit of CPU state and jumps to the kernel entry point.
In aarch64 at least, CPUs other than CPU0 are also started up briefly, run some initialization, and are made wait on a WFE. This can be seen easily by booting a multicore Linux kernel run with gem5 ExecAll trace format.
24.21. gem5 memory system
Parent section: gem5 internals.
24.21.1. gem5 port system
The gem5 memory system is connected in a very flexible way through the port system.
This system exists to allow seamlessly connecting any combination of CPU, caches, interconnects, DRAM and peripherals.
A Packet is the basic information unit that gets sent across ports.
24.21.1.1. gem5 functional vs atomic vs timing memory requests
gem5 memory requests can be classified in the following broad categories:
-
functional: get the value magically, do not update caches, see also: gem5 functional requests
-
atomic: get the value now without making a separate event, but do not update caches. Cannot work in Ruby due to fundamental limitations, mentioned in passing at: https://gem5.atlassian.net/browse/GEM5-676
-
timing: get the value simulating delays and updating caches
This trichotomy can be notably seen in the definition of the MasterPort class:
class MasterPort : public Port, public AtomicRequestProtocol,
public TimingRequestProtocol, public FunctionalRequestProtocol
and the base classes are defined under src/mem/protocol/.
Then, by reading the rest of the class, we see that the send methods are all boring, and just forward to some polymorphic receiver that does the actual interesting activity:
Tick
sendAtomicSnoop(PacketPtr pkt)
{
return AtomicResponseProtocol::sendSnoop(_masterPort, pkt);
}
Tick
AtomicResponseProtocol::sendSnoop(AtomicRequestProtocol *peer, PacketPtr pkt)
{
assert(pkt->isRequest());
return peer->recvAtomicSnoop(pkt);
}
The receive methods are therefore the interesting ones, and must be overridden on derived classes if they ever expect to receive such requests:
Tick
recvAtomicSnoop(PacketPtr pkt) override
{
panic("%s was not expecting an atomic snoop request\n", name());
return 0;
}
void
recvFunctionalSnoop(PacketPtr pkt) override
{
panic("%s was not expecting a functional snoop request\n", name());
}
void
recvTimingSnoopReq(PacketPtr pkt) override
{
panic("%s was not expecting a timing snoop request.\n", name());
}
One question that comes up now is: but why do CPUs need to care about snoop requests?
And one big answer is: to be able to implement LLSC atomicity as mentioned at: ARM LDXR and STXR instructions, since when other cores update memory, they could invalidate the lock of the current core.
Then, as you might expect, we can see that for example AtomicSimpleCPU does not override recvTimingSnoopReq.
Now let see which requests are generated by ordinary ARM LDR instruction. We run:
./run \ --arch aarch64 \ --debug-vm \ --emulator gem5 \ --gem5-build-type debug \ --useland userland/arch/aarch64/freestanding/linux/hello.S \
and then break at the methods of the LDR class LDRXL64_LIT: gem5 execute vs initiateAcc vs completeAcc.
Before starting, we of course guess that:
-
AtomicSimpleCPUwill be making atomic accesses fromexecute -
TimingSimpleCPUwill be making timing accesses frominitiateAcc, which must generate the event which leads tocompleteAcc
so let’s confirm it.
We break on ArmISAInst::LDRXL64_LIT::execute which is what AtomicSimpleCPU uses, and that leads as expected to:
MasterPort::sendAtomic AtomicSimpleCPU::sendPacket AtomicSimpleCPU::readMem SimpleExecContext::readMem readMemAtomic<(ByteOrder)1, ExecContext, unsigned long> readMemAtomicLE<ExecContext, unsigned long> ArmISAInst::LDRXL64_LIT::execute AtomicSimpleCPU::tick
Notably, AtomicSimpleCPU::readMem immediately translates the address, creates a packet, sends the atomic request, and gets the response back without any events.
And now if we do the same with --cpu-type TimingSimpleCPU and break at ArmISAInst::LDRXL64_LIT::initiateAcc, and then add another break for the next event schedule b EventManager::schedule (which we imagine is the memory read) we reach:
EventManager::schedule DRAMCtrl::addToReadQueue DRAMCtrl::recvTimingReq DRAMCtrl::MemoryPort::recvTimingReq TimingRequestProtocol::sendReq MasterPort::sendTimingReq CoherentXBar::recvTimingReq CoherentXBar::CoherentXBarSlavePort::recvTimingReq TimingRequestProtocol::sendReq MasterPort::sendTimingReq TimingSimpleCPU::handleReadPacket TimingSimpleCPU::sendData TimingSimpleCPU::finishTranslation DataTranslation<TimingSimpleCPU*>::finish ArmISA::TLB::translateComplete ArmISA::TLB::translateTiming ArmISA::TLB::translateTiming TimingSimpleCPU::initiateMemRead SimpleExecContext::initiateMemRead initiateMemRead<ExecContext, unsigned long> ArmISAInst::LDRXL64_LIT::initiateAcc TimingSimpleCPU::completeIfetch TimingSimpleCPU::IcachePort::ITickEvent::process EventQueue::serviceOne
so as expected we have TimingRequestProtocol::sendReq.
Remember however that timing requests are a bit more complicated due to paging, since the page table walk can itself lead to further memory requests.
In this particular instance, the address being read with ldr x2, =len ARM LDR pseudo-instruction is likely placed just after the text section, and therefore the pagewalk is already in the TLB due to previous instruction fetches, and this is because the translation just finished immediately going through TimingSimpleCPU::finishTranslation, some key snippets are:
TLB::translateComplete(const RequestPtr &req, ThreadContext *tc,
Translation *translation, Mode mode, TLB::ArmTranslationType tranType,
bool callFromS2)
{
bool delay = false;
Fault fault;
if (FullSystem)
fault = translateFs(req, tc, mode, translation, delay, true, tranType);
else
fault = translateSe(req, tc, mode, translation, delay, true);
if (!delay)
translation->finish(fault, req, tc, mode);
else
translation->markDelayed();
and then translateSe does not use delay at all, so we learn that in syscall emulation, delay is always false and things progress immediately there. And then further down TimingSimpleCPU::finishTranslation does some more fault checking:
void
TimingSimpleCPU::finishTranslation(WholeTranslationState *state)
{
if (state->getFault() != NoFault) {
translationFault(state->getFault());
} else {
if (!state->isSplit) {
sendData(state->mainReq, state->data, state->res,
state->mode == BaseTLB::Read);
Tested in gem5 b1623cb2087873f64197e503ab8894b5e4d4c7b4.
24.21.1.1.1. gem5 functional requests
As seen at gem5 functional vs atomic vs timing memory requests, functional requests are not used in common simulation, since the core must always go through caches.
Functional access are therefore only used for more magic simulation functionalities.
One such functionality, is the gem5 syscall emulation mode implementation of the futex system call which is done at futexFunc in src/sim/sycall_emul.hh.
As seen from man futex, the Linux kernel reads the value from an address that is given as the first argument of the call.
Therefore, here it makes sense for gem5 syscall implementation, which does not actually have a real kernel running, to just make a functional request and be done with it, since the impact of cache changes done by this read would be insignificant to the cost of an actual full context switch that would happen on a real syscall.
It is generally hard to implement functional requests for Ruby runs, because packets are flying through the memory system in a transient state, and there is no simple way of finding exactly which ones might have the latest version of the memory. See for example:
The typical error message in that case is:
fatal: Ruby functional read failed for address
24.21.2. gem5 Packet vs Request
24.21.2.1. gem5 Packet
Packet is what goes through ports: a single packet is sent out to the memory system, gets modified when it hits valid data, and then returns with the reply.
Packet is what CPUs create and send to get memory values. E.g. on gem5 AtomicSimpleCPU:
void
AtomicSimpleCPU::tick()
{
...
Packet ifetch_pkt = Packet(ifetch_req, MemCmd::ReadReq);
ifetch_pkt.dataStatic(&inst);
icache_latency = sendPacket(icachePort, &ifetch_pkt);
Tick
AtomicSimpleCPU::sendPacket(MasterPort &port, const PacketPtr &pkt)
{
return port.sendAtomic(pkt);
}
On TimingSimpleCPU, we note that the packet is dynamically created unlike for the AtomicSimpleCPU, since it must exist across multiple events which happen on separate function calls, unlike atomic memory which is done immediately in a single call:
void
TimingSimpleCPU::sendFetch(const Fault &fault, const RequestPtr &req,
ThreadContext *tc)
{
if (fault == NoFault) {
DPRINTF(SimpleCPU, "Sending fetch for addr %#x(pa: %#x)\n",
req->getVaddr(), req->getPaddr());
ifetch_pkt = new Packet(req, MemCmd::ReadReq);
ifetch_pkt->dataStatic(&inst);
DPRINTF(SimpleCPU, " -- pkt addr: %#x\n", ifetch_pkt->getAddr());
if (!icachePort.sendTimingReq(ifetch_pkt)) {
It must later delete the return packet that it gets later on, e.g. for the ifetch:
TimingSimpleCPU::completeIfetch(PacketPtr pkt)
{
if (pkt) {
delete pkt;
}
The most important properties of a Packet are:
-
PacketDataPtr data;: the data coming back from a reply packet or being sent via it -
Addr addr;: the physical address of the data. TODO comment says could be virtual too, when?/// The address of the request. This address could be virtual or /// physical, depending on the system configuration. Addr addr;
-
Flags flags;: flags describing properties of thePacket -
MemCmd cmd;: see gem5MemCmd
24.21.2.1.1. gem5 MemCmd
Each gem5 Packet contains a MemCmd
The MemCmd is basically an enumeration of possible commands, stuff like:
enum Command
{
InvalidCmd,
ReadReq,
ReadResp,
Each command has a fixed number of attributes defined in the static array:
static const CommandInfo commandInfo[];
which gets initialized in the .cc file in the same order as the Command enum.
const MemCmd::CommandInfo
MemCmd::commandInfo[] =
{
/* InvalidCmd */
{ 0, InvalidCmd, "InvalidCmd" },
/* ReadReq - Read issued by a non-caching agent such as a CPU or
* device, with no restrictions on alignment. */
{ SET3(IsRead, IsRequest, NeedsResponse), ReadResp, "ReadReq" },
/* ReadResp */
{ SET3(IsRead, IsResponse, HasData), InvalidCmd, "ReadResp" },
From this we see for example that both ReadReq and ReadResp are marked with the IsRead attribute.
The second field of this array also specifies the corresponding reply of each request. E.g. the reply of a ReadReq is a ReadResp. InvalidCmd is just a placeholders for requests that are already replies.
struct CommandInfo
{
/// Set of attribute flags.
const std::bitset<NUM_COMMAND_ATTRIBUTES> attributes;
/// Corresponding response for requests; InvalidCmd if no
/// response is applicable.
const Command response;
/// String representation (for printing)
const std::string str;
};
Some important commands include:
-
ReadReq: what the CPU sends out to its cache, see also: gem5 event queue AtomicSimpleCPU syscall emulation freestanding example analysis with caches and multiple CPUs -
ReadSharedReq: what dcache of the CPU sends forward to the gem5 crossbar interconnect after aReadReq, see also: see also: gem5 event queue AtomicSimpleCPU syscall emulation freestanding example analysis with caches and multiple CPUs -
ReadResp: response to aReadReq. Can come from either DRAM or another cache that has the data. On gem5 event queue AtomicSimpleCPU syscall emulation freestanding example analysis with caches and multiple CPUs we see that a new packet is created. -
WriteReq: what the CPU sends out to its cache, see also: gem5 event queue AtomicSimpleCPU syscall emulation freestanding example analysis with caches and multiple CPUs -
UpgradeReq: what dcache of CPU sends forward after aWriteReq
24.21.2.2. gem5 Request
One good way to think about Request vs Packet could be "it is what the instruction definitions see", a bit like ExecContext vs ThreadContext.
Request is passed to the constructor of Packet, and Packet keeps a reference to it:
Packet(const RequestPtr &_req, MemCmd _cmd)
: cmd(_cmd), id((PacketId)_req.get()), req(_req),
data(nullptr), addr(0), _isSecure(false), size(0),
_qosValue(0), headerDelay(0), snoopDelay(0),
payloadDelay(0), senderState(NULL)
{
if (req->hasPaddr()) {
addr = req->getPaddr();
flags.set(VALID_ADDR);
_isSecure = req->isSecure();
}
if (req->hasSize()) {
size = req->getSize();
flags.set(VALID_SIZE);
}
}
where RequestPtr is defined as:
typedef std::shared_ptr<Request> RequestPtr;
so we see that shared pointers to requests are basically passed around.
Some key fields include:
-
_paddr:/** * The physical address of the request. Valid only if validPaddr * is set. */ Addr _paddr = 0; -
_vaddr:/** The virtual address of the request. */ Addr _vaddr = MaxAddr;
24.21.2.2.1. gem5 Request in AtomicSimpleCPU
In AtomicSimpleCPU, a single packet of each type is kept for the entire CPU, e.g.:
RequestPtr ifetch_req;
and it gets created at construction time:
AtomicSimpleCPU::AtomicSimpleCPU(AtomicSimpleCPUParams *p)
{
ifetch_req = std::make_shared<Request>();
and then it gets modified for each request:
setupFetchRequest(ifetch_req);
which does:
req->setVirt(fetchPC, sizeof(MachInst), Request::INST_FETCH,
instMasterId(), instAddr);
Virtual to physical address translation done by the CPU stores the physical address:
fault = thread->dtb->translateAtomic(req, thread->getTC(),
BaseTLB::Read);
which eventually calls e.g. on fs with MMU enabled:
Fault
TLB::translateMmuOn(ThreadContext* tc, const RequestPtr &req, Mode mode,
Translation *translation, bool &delay, bool timing,
bool functional, Addr vaddr,
ArmFault::TranMethod tranMethod)
{
req->setPaddr(pa);
24.21.2.2.2. gem5 Request in TimingSimpleCPU
In TimingSimpleCPU, the request gets created per memory read:
Fault
TimingSimpleCPU::initiateMemRead(Addr addr, unsigned size,
Request::Flags flags,
const std::vector<bool>& byte_enable)
{
...
RequestPtr req = std::make_shared<Request>(
addr, size, flags, dataMasterId(), pc, thread->contextId());
and from gem5 functional vs atomic vs timing memory requests and gem5 functional vs atomic vs timing memory requests we remember that initiateMemRead is actually started from the initiateAcc instruction definitions for timing:
Fault LDRWL64_LIT::initiateAcc(ExecContext *xc,
Trace::InstRecord *traceData) const
{
...
fault = initiateMemRead(xc, traceData, EA, Mem, memAccessFlags);
From this we see that initiateAcc memory instructions are basically extracting the required information for the request, notably the address EA and flags.
24.21.3. gem5 MSHR
Each cache object owns a MSHRQueue:
class BaseCache : public ClockedObject
{
/** Miss status registers */
MSHRQueue mshrQueue;
BaseCache is the base class of Cache and NoncoherentCache.
MSHRQueue is a Queue of MSHR:
class MSHRQueue : public Queue<MSHR>
and Queue is also a gem5 class under src/mem/cache/queue.hh.
The MSHR basically keeps track of all information the cache receives, and helps it take appropriate action. I’m not sure why it is separate form the cache at all, as it is basically performing essential cache bookkeeping.
A clear example of MSHR in action can be seen at: gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis with caches and multiple CPUs. In that example what happened was:
-
CPU1 writes to an address and it completes
-
CPU2 sends read
-
CPU1 writes to the address again
-
CPU2 snoops the write, and notes it down in its MSHR
-
CPU2 receives a snoop reply for its read, also from CPU1 which has the data and the line becomes valid
-
CPU2 gets its data. But the MSHR remembers that it had also received a write snoop, so it also immediately invalidates that line
From this we understand that MSHR is the part of the cache that synchronizes stuff pending snoops and ensures that things get invalidated.
24.21.4. gem5 CommMonitor
You can place this SimObject in between two ports to get extra statistics about the packets that are going through.
It only works on timing requests, and does not seem to dump any memory values, only add extra statistics.
For example, the patch patches/manual/gem5-commmonitor-se.patch hack a CommMonitor between the CPU and the L1 cache on top of gem5 1c3662c9557c85f0d25490dc4fbde3f8ab0cb350:
patch -d "$(./getvar gem5_source_dir)" -p 1 < patches/manual/gem5-commmonitor-se.patch
That patch was done largely by copying what fs.py --memcheck does with a MemChecker object.
You can then run with:
./run \ --arch aarch64 \ --emulator gem5 \ --userland userland/arch/aarch64/freestanding/linux/hello.S \ -- \ --caches \ --cpu-type TimingSimpleCPU \ ;
and now we have some new extra histogram statistics such as:
system.cpu.dcache_mon.readBurstLengthHist::samples 1
One neat thing about this is that it is agnostic to the memory object type, so you don’t have to recode those statistics for every new type of object that operates on memory packets.
24.21.5. gem5 SimpleMemory
SimpleMemory is a highly simplified memory system. It can replace a more complex DRAM model if you use it e.g. as:
./run --emulator gem5 -- --mem-type SimpleMemory
and it also gets used in certain system-y memories present in ARM systems by default e.g. Flash memory:
[system.realview.flash0] type=SimpleMemory
As of gem5 3ca404da175a66e0b958165ad75eb5f54cb5e772 LKMC 059a7ef9d9c378a6d1d327ae97d90b78183680b2 it did not provide any speedup to the Linux kernel boot according to a quick test.
24.22. gem5 internals
Internals under other sections:
24.22.1. gem5 Eclipse configuration
In order to develop complex C++ software such as gem5, a good IDE setup is fundamental.
The best setup I’ve reached is with Eclipse. It is not perfect, and there is a learning curve, but is worth it.
Notably, it is very hard to get perfect due to: Why are all C++ symlinked into the gem5 build dir?.
I recommend the following settings, tested in Eclipse 2019.09, Ubuntu 18.04:
-
fix all missing stdlib headers: https://stackoverflow.com/questions/10373788/how-to-solve-unresolved-inclusion-iostream-in-a-c-file-in-eclipse-cdt/51099533#51099533
-
use spaces instead of tabs: Window, Preferences, Code Style, C/C++, Formatter, New, Edit, Tab Policy, Spaces Only
-
either
-
create the project in the gem5 build directory! Files are moved around there and symlinked, and this gives the best chances of success
-
add to the include search path:
-
./src/ in the source tree
-
the ISA specific build directory which contains some self-generated stuff, e.g.: out/gem5/default/build/ARM
-
-
To run and GDB step debug the executable, just copy the full command line without newlines from your run command (Eclipse does not like newlines for the arguments), e.g.:
./run --emulator gem5 --print-cmd-oneline
and configure it into Eclipse as usual.
One downside of this setup is that if you want to nuke your build directory to get a clean build, then the Eclipse configuration files present in it might get deleted. Maybe it is possible to store configuration files outside of the directory, but we are now mitigating that by making a backup copy of those configuration files before removing the directory, and restoring it when you do ./build-gem --clean.
24.22.2. gem5 Python C++ interaction
The interaction uses the Python C extension interface https://docs.python.org/2/extending/extending.html interface through the pybind11 helper library: https://github.com/pybind/pybind11
The C++ executable both:
-
starts running the Python executable
-
provides Python classes written in C++ for that Python code to use
An example of this can be found at:
then gem5 magic SimObject class adds some crazy stuff on top of it further, is is a mess. In particular, it auto generates params/ headers. TODO: why is this mess needed at all? pybind11 seems to handle constructor arguments just fine:
Let’s study BadDevice for example:
src/dev/BadDevice.py defines devicename:
class BadDevice(BasicPioDevice):
type = 'BadDevice'
cxx_header = "dev/baddev.hh"
devicename = Param.String("Name of device to error on")
The object is created in Python for example from src/dev/alpha/Tsunami.py as:
fb = BadDevice(pio_addr=0x801fc0003d0, devicename='FrameBuffer')
Since BadDevice has no __init__ method, and neither BasicPioDevice, it all just falls through until the SimObject.__init__ constructor.
This constructor will loop through the inheritance chain and give the Python parameters to the C++ BadDeviceParams class as follows.
The auto-generated build/ARM/params/BadDevice.hh file defines BadDeviceParams in C++:
#ifndef __PARAMS__BadDevice__
#define __PARAMS__BadDevice__
class BadDevice;
#include <cstddef>
#include <string>
#include "params/BasicPioDevice.hh"
struct BadDeviceParams
: public BasicPioDeviceParams
{
BadDevice * create();
std::string devicename;
};
#endif // __PARAMS__BadDevice__
and ./python/_m5/param_BadDevice.cc defines the param Python from C++ with pybind11:
namespace py = pybind11;
static void
module_init(py::module &m_internal)
{
py::module m = m_internal.def_submodule("param_BadDevice");
py::class_<BadDeviceParams, BasicPioDeviceParams, std::unique_ptr<BadDeviceParams, py::nodelete>>(m, "BadDeviceParams")
.def(py::init<>())
.def("create", &BadDeviceParams::create)
.def_readwrite("devicename", &BadDeviceParams::devicename)
;
py::class_<BadDevice, BasicPioDevice, std::unique_ptr<BadDevice, py::nodelete>>(m, "BadDevice")
;
}
static EmbeddedPyBind embed_obj("BadDevice", module_init, "BasicPioDevice");
src/dev/baddev.hh then uses the parameters on the constructor:
class BadDevice : public BasicPioDevice
{
private:
std::string devname;
public:
typedef BadDeviceParams Params;
protected:
const Params *
params() const
{
return dynamic_cast<const Params *>(_params);
}
public:
/**
* Constructor for the Baddev Class.
* @param p object parameters
* @param a base address of the write
*/
BadDevice(Params *p);
src/dev/baddev.cc then uses the parameter:
BadDevice::BadDevice(Params *p)
: BasicPioDevice(p, 0x10), devname(p->devicename)
{
}
It has been found that this usage of pybind11 across hundreds of SimObject files accounted for 50% of the gem5 build time at one point: pybind11 accounts for 50% of gem5 build time.
To get a feeling of how SimObject objects are run, see: gem5 event queue AtomicSimpleCPU syscall emulation freestanding example analysis.
Bibliography:
Tested on gem5 08c79a194d1a3430801c04f37d13216cc9ec1da3.
24.22.3. gem5 entry point
The main is at: src/sim/main.cc. It calls:
ret = initM5Python();
src/sim/init.cc:
230 int
231 initM5Python()
232 {
233 EmbeddedPyBind::initAll();
234 return EmbeddedPython::initAll();
235 }
initAll basically just initializes the _m5 Python object, which is used across multiple .py.
Back on main:
ret = m5Main(argc, argv);
which goes to:
result = PyRun_String(*command, Py_file_input, dict, dict);
with commands looping over:
import m5 m5.main()
which leads into:
src/python/m5/main.py#main
which finally calls your config file like fs.py with:
filename = sys.argv[0] filedata = file(filename, 'r').read() filecode = compile(filedata, filename, 'exec') [...] exec filecode in scope
TODO: the file path name appears to be passed as a command line argument to the Python script, but I didn’t have the patience to fully understand the details.
The Python config files then set the entire system up in Python, and finally call m5.simulate() to run the actual simulation. This function has a C++ native implementation at:
src/sim/simulate.cc
and that is where the main event loop, doSimLoop, gets called and starts kicking off the gem5 event queue.
Tested at gem5 b4879ae5b0b6644e6836b0881e4da05c64a6550d.
24.22.3.1. gem5 m5.objects module
All SimObjects seem to be automatically added to the m5.objects namespace, and this is done in a very convoluted way, let’s try to understand a bit:
src/python/m5/objects/__init__.py
contains:
modules = __loader__.modules
for module in modules.keys():
if module.startswith('m5.objects.'):
exec("from %s import *" % module)
And from IPDB we see that this appears to loop over every object string of type m5.objects.modulename.
This __init__ gets called from src/python/importer.py at the exec:
class CodeImporter(object):
def load_module(self, fullname):
override = os.environ.get('M5_OVERRIDE_PY_SOURCE', 'false').lower()
if override in ('true', 'yes') and os.path.exists(abspath):
src = open(abspath, 'r').read()
code = compile(src, abspath, 'exec')
if os.path.basename(srcfile) == '__init__.py':
mod.__path__ = fullname.split('.')
mod.__package__ = fullname
else:
mod.__package__ = fullname.rpartition('.')[0]
mod.__file__ = srcfile
exec(code, mod.__dict__)
import sys
importer = CodeImporter()
add_module = importer.add_module
sys.meta_path.append(importer)
Here as a bonus here we also see how M5_OVERRIDE_PY_SOURCE works.
In src/SConscript we see that SimObject is just a PySource with module equals to m5.objects:
class SimObject(PySource):
def __init__(self, source, tags=None, add_tags=None):
'''Specify the source file and any tags (automatically in
the m5.objects package)'''
super(SimObject, self).__init__('m5.objects', source, tags, add_tags)
The add_module method seems to be doing the magic and is called from src/sim/init.cc:
bool
EmbeddedPython::addModule() const
{
PyObject *code = getCode();
PyObject *result = PyObject_CallMethod(importerModule, PyCC("add_module"),
which is called from:
int
EmbeddedPython::initAll()
{
// Load the importer module
PyObject *code = importer->getCode();
importerModule = PyImport_ExecCodeModule(PyCC("importer"), code);
if (!importerModule) {
PyErr_Print();
return 1;
}
// Load the rest of the embedded python files into the embedded
// python importer
list<EmbeddedPython *>::iterator i = getList().begin();
list<EmbeddedPython *>::iterator end = getList().end();
for (; i != end; ++i)
if (!(*i)->addModule())
and getList comes from:
EmbeddedPython::EmbeddedPython(const char *filename, const char *abspath,
const char *modpath, const unsigned char *code, int zlen, int len)
: filename(filename), abspath(abspath), modpath(modpath), code(code),
zlen(zlen), len(len)
{
// if we've added the importer keep track of it because we need it
// to bootstrap.
if (string(modpath) == string("importer"))
importer = this;
else
getList().push_back(this);
}
list<EmbeddedPython *> &
EmbeddedPython::getList()
{
static list<EmbeddedPython *> the_list;
return the_list;
}
and the constructor in turn gets called from per SimObject autogenerated files such as e.g. dev/storage/Ide.py.cc for src/dev/storage/Ide.py:
EmbeddedPython embedded_m5_objects_Ide(
"m5/objects/Ide.py",
"/home/ciro/bak/git/linux-kernel-module-cheat/data/gem5/master4/src/dev/storage/Ide.py",
"m5.objects.Ide",
data_m5_objects_Ide,
947,
2099);
} // anonymous namespace
which get autogenerated at src/SConscript:
def embedPyFile(target, source, env):
for source in PySource.all:
base_py_env.Command(source.cpp, [ py_marshal, source.tnode ],
MakeAction(embedPyFile, Transform("EMBED PY")))
where the PySource.all thing as you might expect is a static list of all PySource source files as they get updated in the constructor.
Tested in gem5 d9cb548d83fa81858599807f54b52e5be35a6b03.
24.22.4. gem5 event queue
gem5 is an event based simulator, and as such the event queue is of of the crucial elements in the system.
Every single action that takes time (e.g. notably reading from memory) models that time delay by scheduling an event in the future.
The gem5 event queue stores one callback event for each future point in time.
The event queue is implemented in the class EventQueue in the file src/sim/eventq.hh.
Not all times need to have an associated event: if a given time has no events, gem5 just skips it and jumps to the next event: the queue is basically a linked list of events.
Important examples of events include:
-
CPU ticks
-
peripherals and memory
At gem5 event queue AtomicSimpleCPU syscall emulation freestanding example analysis we see for example that at the beginning of an AtomicCPU simulation, gem5 sets up exactly two events:
-
the first CPU cycle
-
one exit event at the end of time which triggers gem5 simulate() limit reached
Then, at the end of the callback of one tick event, another tick is scheduled.
And so the simulation progresses tick by tick, until an exit event happens.
The EventQueue class has one awesome dump() function that prints a human friendly representation of the queue, and can be easily called from GDB. TODO example.
We can also observe what is going on in the event queue with the Event debug flag.
Event execution is done at EventQueue::serviceOne():
Event *exit_event = eventq->serviceOne();
This calls the Event::process method of the event.
Another important technique is to use GDB and break at interesting points such as:
b Trace::OstreamLogger::logMessage b EventManager::schedule b EventFunctionWrapper::process
although stepping into EventFunctionWrapper::process which does std::function is a bit of a pain: https://stackoverflow.com/questions/59429401/how-to-step-into-stdfunction-user-code-from-c-functional-with-gdb
Another potentially useful technique is to use:
--trace Event,ExecAll,FmtFlag,FmtStackTrace --trace-stdout
which automates the logging of Trace::OstreamLogger::logMessage() backtraces.
But alas, it misses which function callback is being scheduled, which is the awesome thing we actually want:
Then, once we had that, the most perfect thing ever would be to make the full event graph containing which events schedule which events!
24.22.4.1. gem5 event queue AtomicSimpleCPU syscall emulation freestanding example analysis
Let’s now analyze every single event on a minimal gem5 syscall emulation mode in the simplest CPU that we have:
./run \ --arch aarch64 \ --emulator gem5 \ --userland userland/arch/aarch64/freestanding/linux/hello.S \ --trace Event,ExecAll,FmtFlag \ --trace-stdout \ ;
which gives:
0: Event: AtomicSimpleCPU tick.wrapped_function_event: EventFunctionWrapped 39 scheduled @ 0
**** REAL SIMULATION ****
0: Event: Event_70: generic 70 scheduled @ 0
info: Entering event queue @ 0. Starting simulation...
0: Event: Event_70: generic 70 rescheduled @ 18446744073709551615
0: Event: AtomicSimpleCPU tick.wrapped_function_event: EventFunctionWrapped 39 executed @ 0
0: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue : movz x0, #1, #0 : IntAlu : D=0x0000000000000001 flags=(IsInteger)
0: Event: AtomicSimpleCPU tick.wrapped_function_event: EventFunctionWrapped 39 rescheduled @ 500
500: Event: AtomicSimpleCPU tick.wrapped_function_event: EventFunctionWrapped 39 executed @ 500
500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+4 : adr x1, #28 : IntAlu : D=0x0000000000400098 flags=(IsInteger)
500: Event: AtomicSimpleCPU tick.wrapped_function_event: EventFunctionWrapped 39 rescheduled @ 1000
1000: Event: AtomicSimpleCPU tick.wrapped_function_event: EventFunctionWrapped 39 executed @ 1000
1000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+8 : ldr w2, #4194464 : MemRead : D=0x0000000000000006 A=0x4000a0 flags=(IsInteger|IsMemRef|IsLoad)
1000: Event: AtomicSimpleCPU tick.wrapped_function_event: EventFunctionWrapped 39 rescheduled @ 1500
1500: Event: AtomicSimpleCPU tick.wrapped_function_event: EventFunctionWrapped 39 executed @ 1500
1500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+12 : movz x8, #64, #0 : IntAlu : D=0x0000000000000040 flags=(IsInteger)
1500: Event: AtomicSimpleCPU tick.wrapped_function_event: EventFunctionWrapped 39 rescheduled @ 2000
2000: Event: AtomicSimpleCPU tick.wrapped_function_event: EventFunctionWrapped 39 executed @ 2000
2000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+16 : svc #0x0 : IntAlu : flags=(IsSerializeAfter|IsNonSpeculative|IsSyscall)
hello
2000: Event: AtomicSimpleCPU tick.wrapped_function_event: EventFunctionWrapped 39 rescheduled @ 2500
2500: Event: AtomicSimpleCPU tick.wrapped_function_event: EventFunctionWrapped 39 executed @ 2500
2500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+20 : movz x0, #0, #0 : IntAlu : D=0x0000000000000000 flags=(IsInteger)
2500: Event: AtomicSimpleCPU tick.wrapped_function_event: EventFunctionWrapped 39 rescheduled @ 3000
3000: Event: AtomicSimpleCPU tick.wrapped_function_event: EventFunctionWrapped 39 executed @ 3000
3000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+24 : movz x8, #93, #0 : IntAlu : D=0x000000000000005d flags=(IsInteger)
3000: Event: AtomicSimpleCPU tick.wrapped_function_event: EventFunctionWrapped 39 rescheduled @ 3500
3500: Event: AtomicSimpleCPU tick.wrapped_function_event: EventFunctionWrapped 39 executed @ 3500
3500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+28 : svc #0x0 : IntAlu : flags=(IsSerializeAfter|IsNonSpeculative|IsSyscall)
3500: Event: Event_71: generic 71 scheduled @ 3500
3500: Event: Event_71: generic 71 executed @ 3500
On the event trace, we can first see:
0: Event: AtomicSimpleCPU tick.wrapped_function_event: EventFunctionWrapped 39 scheduled @ 0
This schedules a tick event for time 0, and leads to the first clock tick.
Then:
0: Event: Event_70: generic 70 scheduled @ 0 0: Event: Event_70: generic 70 rescheduled @ 18446744073709551615
schedules the end of time event for time 0, which is later rescheduled to the actual end of time.
At:
0: Event: AtomicSimpleCPU tick.wrapped_function_event: EventFunctionWrapped 39 executed @ 0 0: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue : movz x0, #1, #0 : IntAlu : D=0x0000000000000001 flags=(IsInteger) 0: Event: AtomicSimpleCPU tick.wrapped_function_event: EventFunctionWrapped 39 rescheduled @ 500
the tick event happens, the instruction runs, and then the instruction is rescheduled in 500 time units. This is done at the end of AtomicSimpleCPU::tick():
if (_status != Idle)
reschedule(tickEvent, curTick() + latency, true);
At:
3500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+28 : svc #0x0 : IntAlu : flags=(IsSerializeAfter|IsNonSpeculative|IsSyscall) 3500: Event: Event_71: generic 71 scheduled @ 3500 3500: Event: Event_71: generic 71 executed @ 3500
the exit system call is called, and then it schedules an exit evit, which gets executed and the simulation ends.
We guess then that Event_71 comes from the SE implementation of the exit syscall, so let’s just confirm, the trace contains:
exitSimLoop() at sim_events.cc:97 0x5555594746e0 exitImpl() at syscall_emul.cc:215 0x55555948c046 exitFunc() at syscall_emul.cc:225 0x55555948c147 SyscallDesc::doSyscall() at syscall_desc.cc:72 0x5555594949b6 Process::syscall() at process.cc:401 0x555559484717 SimpleThread::syscall() at 0x555559558059 ArmISA::SupervisorCall::invoke() at faults.cc:856 0x5555572950d7 BaseSimpleCPU::advancePC() at base.cc:681 0x555559083133 AtomicSimpleCPU::tick() at atomic.cc:757 0x55555907834c
and exitSimLoop() does:
new GlobalSimLoopExitEvent(when + simQuantum, message, exit_code, repeat);
Tested in gem5 12c917de54145d2d50260035ba7fa614e25317a3.
24.22.4.1.1. AtomicSimpleCPU initial events
Let’s have a closer look at the initial magically scheduled events of the simulation.
Most events come from other events, but at least one initial event must be scheduled somehow from elsewhere to kick things off.
The initial tick event:
0: Event: AtomicSimpleCPU tick.wrapped_function_event: EventFunctionWrapped 39 scheduled @ 0
we’ll study by breaking at at the point that prints messages: b Trace::OstreamLogger::logMessage() to see where events are being scheduled from:
Trace::OstreamLogger::logMessage() at trace.cc:149 0x5555593b3b1e void Trace::Logger::dprintf_flag<char const*, char const*, unsigned long>() at 0x55555949e603 void Trace::Logger::dprintf<char const*, char const*, unsigned long>() at 0x55555949de58 Event::trace() at eventq.cc:395 0x55555946d109 EventQueue::schedule() at eventq_impl.hh:65 0x555557195441 EventManager::schedule() at eventq.hh:746 0x555557194aa2 AtomicSimpleCPU::activateContext() at atomic.cc:239 0x555559075531 SimpleThread::activate() at simple_thread.cc:177 0x555559545a63 Process::initState() at process.cc:283 0x555559484011 ArmProcess64::initState() at process.cc:126 0x55555730827a ArmLinuxProcess64::initState() at process.cc:1,777 0x5555572d5e5e
The interesting call is at AtomicSimpleCPU::activateContext:
schedule(tickEvent, clockEdge(Cycles(0)));
which calls EventManager::schedule.
AtomicSimpleCPU is an EventManager because SimObject inherits from it.
tickEvent is an EventFunctionWrapper which contains a std::function<void(void)> callback;, and is initialized in the constructor as:
tickEvent([this]{ tick(); }, "AtomicSimpleCPU tick",
false, Event::CPU_Tick_Pri),
The call stack above ArmLinuxProcess64::initState is pybind11 fuzziness, but if we grep a bit we find the Python call point:
src/python/m5/simulate.py
def instantiate(ckpt_dir=None):
...
# Create the C++ sim objects and connect ports
for obj in root.descendants(): obj.createCCObject()
for obj in root.descendants(): obj.connectPorts()
# Do a second pass to finish initializing the sim objects
for obj in root.descendants(): obj.init()
...
# Restore checkpoint (if any)
if ckpt_dir:
...
else:
for obj in root.descendants(): obj.initState()
and this gets called from the toplevel Python scripts e.g. se.py configs/common/Simulation.py does:
m5.instantiate(checkpoint_dir)
As we can see, initState is just one stage of generic SimObject initialization. root.descendants() goes over the entire SimObject tree calling initState().
Finally, we see that initState is part of the SimObject C++ API:
src/sim/sim_object.hh
class SimObject : public EventManager, public Serializable, public Drainable,
public Stats::Group
{
...
/**
* initState() is called on each SimObject when *not* restoring
* from a checkpoint. This provides a hook for state
* initializations that are only required for a "cold start".
*/
virtual void initState();
Finally, we see that initState is exposed to the Python API at:
build/ARM/python/_m5/param_SimObject.cc
module_init(py::module &m_internal)
{
py::module m = m_internal.def_submodule("param_SimObject");
py::class_<SimObjectParams, std::unique_ptr<SimObjectParams, py::nodelete>>(m, "SimObjectParams")
.def_readwrite("name", &SimObjectParams::name)
.def_readwrite("eventq_index", &SimObjectParams::eventq_index)
;
py::class_<SimObject, Drainable, Serializable, Stats::Group, std::unique_ptr<SimObject, py::nodelete>>(m, "SimObject")
.def("init", &SimObject::init)
.def("initState", &SimObject::initState)
.def("memInvalidate", &SimObject::memInvalidate)
.def("memWriteback", &SimObject::memWriteback)
.def("regProbePoints", &SimObject::regProbePoints)
.def("regProbeListeners", &SimObject::regProbeListeners)
.def("startup", &SimObject::startup)
.def("loadState", &SimObject::loadState, py::arg("cp"))
.def("getPort", &SimObject::getPort, pybind11::return_value_policy::reference, py::arg("if_name"), py::arg("idx"))
;
}
which is more magical than the other param classes since py::class_<SimObject has non-trivial methods, those are auto-generated by the cxx_exports code generation mechanism:
class SimObject(object):
...
cxx_exports = [
PyBindMethod("init"),
PyBindMethod("initState"),
PyBindMethod("memInvalidate"),
PyBindMethod("memWriteback"),
PyBindMethod("regProbePoints"),
PyBindMethod("regProbeListeners"),
PyBindMethod("startup"),
]
And the second magically scheduled event is the exit event:
0: Event: Event_70: generic 70 scheduled @ 0 0: Event: Event_70: generic 70 rescheduled @ 18446744073709551615
which is scheduled with backtrace:
Trace::OstreamLogger::logMessage() at trace.cc:149 0x5555593b3b1e void Trace::Logger::dprintf_flag<char const*, char const*, unsigned long>() at 0x55555949e603 void Trace::Logger::dprintf<char const*, char const*, unsigned long>() at 0x55555949de58 Event::trace() at eventq.cc:395 0x55555946d109 EventQueue::schedule() at eventq_impl.hh:65 0x555557195441 BaseGlobalEvent::schedule() at global_event.cc:78 0x55555946d6f1 GlobalEvent::GlobalEvent() at 0x55555949d177 GlobalSimLoopExitEvent::GlobalSimLoopExitEvent() at sim_events.cc:61 0x555559474470 simulate() at simulate.cc:104 0x555559476d6f
which comes at object creation inside simulate() through the GlobalEvent() constructor:
simulate_limit_event =
new GlobalSimLoopExitEvent(mainEventQueue[0]->getCurTick(),
"simulate() limit reached", 0);
This event indicates that the simulation should finish by overriding bool isExitEvent() which gets checked in the main simulation at EventQueue::serviceOne:
if (event->isExitEvent()) {
assert(!event->flags.isSet(Event::Managed) ||
!event->flags.isSet(Event::IsMainQueue)); // would be silly
return event;
Tested in gem5 12c917de54145d2d50260035ba7fa614e25317a3.
24.22.4.1.2. AtomicSimpleCPU tick reschedule timing
Inside AtomicSimpleCPU::tick() we saw previously that the reschedule happens at:
if (latency < clockPeriod())
latency = clockPeriod();
if (_status != Idle)
reschedule(tickEvent, curTick() + latency, true);
so it is interesting to learn where that latency comes from.
From our logs, we see that all events happened with a 500 time unit interval between them, so that must be the value for all instructions of our simple example.
By GDBing it a bit, we see that none of our instructions incremented latency, and so it got set to clockPeriod(), which comes from ClockDomain::clockPeriod() which then likely comes from:
parser.add_option("--cpu-clock", action="store", type="string",
default='2GHz',
because the time unit is picoseconds. This then shows on the config.ini as:
[system.cpu_clk_domain] type=SrcClockDomain clock=500
24.22.4.1.3. AtomicSimpleCPU memory access
It will be interesting to see how AtomicSimpleCPU makes memory access on GDB and to compare that with TimingSimpleCPU.
We assume that the memory access still goes through the CoherentXBar, but instead of generating an event to model delayed response, it must be doing the access directly.
Inside AtomicSimpleCPU::tick, we track ifetch_req and see:
fault = thread->itb->translateAtomic(ifetch_req, thread->getTC(),
BaseTLB::Execute);
and later on after translation the memory is obtained at:
icache_latency = sendPacket(icachePort, &ifetch_pkt);
which sends the packet atomically through the port:
AtomicSimpleCPU::sendPacket(MasterPort &port, const PacketPtr &pkt) {
return port.sendAtomic(pkt);
}
We can compare that with what happen sin TimingSimpleCPU:
thread->itb->translateTiming(ifetch_req, thread->getTC(),
&fetchTranslation, BaseTLB::Execute);
and so there it is: the ITB classes are the same, but there are a separate Atomic and Timing methods!
The timing request is shown further at: sends the packet atomically.
Tested in gem5 b4879ae5b0b6644e6836b0881e4da05c64a6550d.
24.22.4.1.4. gem5 se.py page translation
Happens on EmulationPageTable, and seems to happen atomically without making any extra memory requests.
TODO confirm from code, notably by seeing where the translation table is set.
But we can confirm with logging with:
--trace DRAM,ExecAll,FmtFlag
which gives
0: DRAM: system.mem_ctrls: recvAtomic: ReadReq 0x78
0: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue : movz x0, #1, #0 : IntAlu : D=0x0000000000000001 flags=(IsInteger)
500: DRAM: system.mem_ctrls: recvAtomic: ReadReq 0x7c
500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+4 : adr x1, #28 : IntAlu : D=0x0000000000400098 flags=(IsInteger)
1000: DRAM: system.mem_ctrls: recvAtomic: ReadReq 0x80
1000: DRAM: system.mem_ctrls: recvAtomic: ReadReq 0xa0
1000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+8 : ldr w2, #4194464 : MemRead : D=0x0000000000000006 A=0x4000a0 flags=(IsInteger|IsMemRef|IsLoad)
1500: DRAM: system.mem_ctrls: recvAtomic: ReadReq 0x84
1500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+12 : movz x8, #64, #0 : IntAlu : D=0x0000000000000040 flags=(IsInteger)
2000: DRAM: system.mem_ctrls: recvAtomic: ReadReq 0x88
2000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+16 : svc #0x0 : IntAlu : flags=(IsSerializeAfter|IsNonSpeculative|IsSyscall)
hello
2500: DRAM: system.mem_ctrls: recvAtomic: ReadReq 0x8c
2500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+20 : movz x0, #0, #0 : IntAlu : D=0x0000000000000000 flags=(IsInteger)
3000: DRAM: system.mem_ctrls: recvAtomic: ReadReq 0x90
3000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+24 : movz x8, #93, #0 : IntAlu : D=0x000000000000005d flags=(IsInteger)
3500: DRAM: system.mem_ctrls: recvAtomic: ReadReq 0x94
3500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+28 : svc #0x0 : IntAlu : flags=(IsSerializeAfter|IsNonSpeculative|IsSyscall)
Exiting @ tick 3500 because exiting with last active thread context
3500: DRAM: system.mem_ctrls_0: Computing stats due to a dump callback
3500: DRAM: system.mem_ctrls_1: Computing stats due to a dump callback
So we see that before every instruction execution there was a DRAM event! Also, each read happens 4 bytes after the previous one, which is consistent with instruction fetches.
The DRAM addresses are very close to zero e.g. 0x78 for the first instruction, and therefore we guess that they are physical since the ELF entry point is much higher:
./run-toolchain --arch aarch64 readelf -- -h "$(./getvar --arch aarch64 userland_build_dir)/arch/aarch64/freestanding/linux/hello.out
at:
Entry point address: 0x400078
For LDR, we see that there was an extra DRAM read as well after the fetch read, as expected.
Tested in gem5 b4879ae5b0b6644e6836b0881e4da05c64a6550d.
24.22.4.2. gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis
Now, let’s move on to TimingSimpleCPU, which is just like AtomicSimpleCPU internally, but now the memory requests don’t actually finish immediately: gem5 CPU types!
This means that simulation will be much more accurate, and the DRAM memory will be modelled.
TODO: analyze better what each of the memory event mean. For now, we have just collected a bunch of data there, but needs interpreting. The CPU specifics in this section are already insightful however.
TimingSimpleCPU should be the second simplest CPU to analyze, so let’s give it a try:
./run \ --arch aarch64 \ --emulator gem5 \ --userland userland/arch/aarch64/freestanding/linux/hello.S \ --trace Event,ExecAll,FmtFlag \ --trace-stdout \ -- \ --cpu-type TimingSimpleCPU \ ;
As of LKMC 78ce2dabe18ef1d87dc435e5bc9369ce82e8d6d2 gem5 12c917de54145d2d50260035ba7fa614e25317a3 the log is now much more complex.
Here is an abridged version with:
-
the beginning up to the second instruction
-
end ending
because all that happens in between is exactly the same as the first two instructions and therefore boring.
We have also manually added:
-
double newlines before each event execution
-
line IDs to be able to refer to specific events more easily (
#0,#1, etc.)
#0 0: Event: system.cpu.wrapped_function_event: EventFunctionWrapped 43 scheduled @ 0
**** REAL SIMULATION ****
#1 0: Event: system.mem_ctrls_0.wrapped_function_event: EventFunctionWrapped 14 scheduled @ 7786250
#2 0: Event: system.mem_ctrls_1.wrapped_function_event: EventFunctionWrapped 20 scheduled @ 7786250
#3 0: Event: Event_74: generic 74 scheduled @ 0
info: Entering event queue @ 0. Starting simulation...
#4 0: Event: Event_74: generic 74 rescheduled @ 18446744073709551615
#5 0: Event: system.cpu.wrapped_function_event: EventFunctionWrapped 43 executed @ 0
#6 0: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 9 scheduled @ 0
#7 0: Event: system.membus.reqLayer0.wrapped_function_event: EventFunctionWrapped 60 scheduled @ 1000
#8 0: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 9 executed @ 0
#9 0: Event: system.mem_ctrls_0.wrapped_function_event: EventFunctionWrapped 12 scheduled @ 0
#10 0: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 10 scheduled @ 46250
#11 0: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 9 scheduled @ 5000
#12 0: Event: system.mem_ctrls_0.wrapped_function_event: EventFunctionWrapped 12 executed @ 0
#13 0: Event: system.mem_ctrls_0.wrapped_function_event: EventFunctionWrapped 15 scheduled @ 0
#14 0: Event: system.mem_ctrls_0.wrapped_function_event: EventFunctionWrapped 15 executed @ 0
#15 1000: Event: system.membus.reqLayer0.wrapped_function_event: EventFunctionWrapped 60 executed @ 1000
#16 5000: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 9 executed @ 5000
#17 46250: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 10 executed @ 46250
#18 46250: Event: system.mem_ctrls.port-RespPacketQueue.wrapped_function_event: EventFunctionWrapped 8 scheduled @ 74250
#19 74250: Event: system.mem_ctrls.port-RespPacketQueue.wrapped_function_event: EventFunctionWrapped 8 executed @ 74250
#20 74250: Event: system.membus.slave[1]-RespPacketQueue.wrapped_function_event: EventFunctionWrapped 64 scheduled @ 77000
#21 74250: Event: system.membus.respLayer1.wrapped_function_event: EventFunctionWrapped 65 scheduled @ 77000
#22 77000: Event: system.membus.respLayer1.wrapped_function_event: EventFunctionWrapped 65 executed @ 77000
#23 77000: Event: system.membus.slave[1]-RespPacketQueue.wrapped_function_event: EventFunctionWrapped 64 executed @ 77000
#24 77000: Event: Event_40: Timing CPU icache tick 40 scheduled @ 77000
#25 77000: Event: Event_40: Timing CPU icache tick 40 executed @ 77000
77000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue : movz x0, #1, #0 : IntAlu : D=0x0000000000000001 flags=(IsInteger)
#26 77000: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 9 scheduled @ 77000
#27 77000: Event: system.membus.reqLayer0.wrapped_function_event: EventFunctionWrapped 60 scheduled @ 78000
#28 77000: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 9 executed @ 77000
#29 77000: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 10 scheduled @ 95750
#30 77000: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 9 scheduled @ 77000
#31 77000: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 9 executed @ 77000
#32 78000: Event: system.membus.reqLayer0.wrapped_function_event: EventFunctionWrapped 60 executed @ 78000
#33 95750: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 10 executed @ 95750
#34 95750: Event: system.mem_ctrls.port-RespPacketQueue.wrapped_function_event: EventFunctionWrapped 8 scheduled @ 123750
#35 123750: Event: system.mem_ctrls.port-RespPacketQueue.wrapped_function_event: EventFunctionWrapped 8 executed @ 123750
#36 123750: Event: system.membus.slave[1]-RespPacketQueue.wrapped_function_event: EventFunctionWrapped 64 scheduled @ 126000
#37 123750: Event: system.membus.respLayer1.wrapped_function_event: EventFunctionWrapped 65 scheduled @ 126000
#38 126000: Event: system.membus.respLayer1.wrapped_function_event: EventFunctionWrapped 65 executed @ 126000
#39 126000: Event: system.membus.slave[1]-RespPacketQueue.wrapped_function_event: EventFunctionWrapped 64 executed @ 126000
#40 126000: Event: Event_40: Timing CPU icache tick 40 scheduled @ 126000
#41 126000: Event: Event_40: Timing CPU icache tick 40 executed @ 126000
126000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+4 : adr x1, #28 : IntAlu : D=0x0000000000400098 flags=(IsInteger)
#42 126000: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 9 scheduled @ 126000
#43 126000: Event: system.membus.reqLayer0.wrapped_function_event: EventFunctionWrapped 60 scheduled @ 127000
[...]
469000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+28 : svc #0x0 : IntAlu : flags=(IsSerializeAfter|IsNonSpeculative|IsSyscall)
469000: Event: Event_75: generic 75 scheduled @ 469000
469000: Event: Event_75: generic 75 executed @ 469000
Looking into the generated config.dot.svg can give a better intuition on the shape of the memory system: Figure 3, “config.dot.svg for a TimingSimpleCPU without caches.”, so it is good to keep that in mind.

config.dot.svg for a TimingSimpleCPU without caches.It is also helpful to see this as a tree of events where one execute event schedules other events:
| | | | |
0 1 2 3 4 0 TimingSimpleCPU::fetch
5
|
+---+
| |
6 7 6 DRAMCtrl::processNextReqEvent (0)
8 15 7 BaseXBar::Layer::releaseLayer
|
+---+---+
| | |
9 10 11 9 DRAMCtrl::Rank::processActivateEvent
12 17 16 10 DRAMCtrl::processRespondEvent (46.25)
| | 11 DRAMCtrl::processNextReqEvent (5)
| |
13 18 13 DRAMCtrl::Rank::processPowerEvent
14 19 18 PacketQueue::processSendEvent (28)
|
+---+
| |
20 21 20 PacketQueue::processSendEvent (2.75)
23 22 21 BaseXBar::Layer<SrcType, DstType>::releaseLayer
|
24 24 TimingSimpleCPU::IcachePort::ITickEvent::process (0)
25
|
+---+
| |
26 27 26 DRAMCtrl::processNextReqEvent
28 32 27 BaseXBar::Layer<SrcType, DstType>::releaseLayer
|
+---+
| |
29 30 29 DRAMCtrl::processRespondEvent
33 31 30 DRAMCtrl::processNextReqEvent
|
34 34 PacketQueue::processSendEvent
35
|
+---+
| |
36 37 36 PacketQueue::processSendEvent
39 38 37 BaseXBar::Layer<SrcType, DstType>::releaseLayer
|
40 40 TimingSimpleCPU::IcachePort::ITickEvent::process
41
|
+---+
| |
42 43 42 DRAMCtrl::processNextReqEvent
43 BaseXBar::Layer<SrcType, DstType>::releaseLayer
Note that every schedule is followed by an execution, so we put them together, for example:
| |
6 7 6 DRAMCtrl::processNextReqEvent (0)
8 15 7 BaseXBar::Layer::releaseLayer (0)
|
means:
-
6: scheduleDRAMCtrl::processNextReqEventto run in0ns after the execution that scheduled it -
8: executeDRAMCtrl::processNextReqEvent -
7: scheduleBaseXBar::Layer::releaseLayerto run in0ns after the execution that scheduled it -
15: executeBaseXBar::Layer::releaseLayer
With this, we can focus on going up the event tree from an event of interest until we see what originally caused it!
Notably, the above tree contains the execution of the first two instructions.
Observe how the events leading up to the second instruction are basically a copy of those of the first one, this is the basic TimingSimpleCPU event loop in action.
One line summary of events:
-
#5: adds the request to the DRAM queue, and schedules a
DRAMCtrl::processNextReqEventwhich later sees that request immediately -
#8: picks up the only request from the DRAM read queue (
readQueue) and services that.If there were multiple requests, priority arbitration under
DRAMCtrl::chooseNextcould chose a different one than the first based on packet prioritiesThis puts the request on the response queue
respQueueand schedules anotherDRAMCtrl::processNextReqEventbut the request queue is empty, and that does nos schedule further events -
#17: picks up the only request from the DRAM response queue and services that by placing it in yet another queue, and scheduling the
PacketQueue::processSendEventwhich will later pick up that packet -
#19: picks up the request from the previous queue, and forwards it to another queue, and schedules yet another
PacketQueue::processSendEventThe current one is the DRAM passing the message to the XBar, and the next
processSendEventis the XBar finally sending it back to the CPU -
#23: the XBar port is actually sending the reply back.
If knows to which CPU core to send the request to because ports keep a map of request to source:
const auto route_lookup = routeTo.find(pkt->req);
24.22.4.2.1. TimingSimpleCPU analysis #0
Schedules TimingSimpleCPU::fetch through:
EventManager::schedule TimingSimpleCPU::activateContext SimpleThread::activate Process::initState ArmProcess64::initState ArmLinuxProcess64::initState
This schedules the initial tick, much like for for AtomicSimpleCPU.
This time however, it is not a tick as in AtomicSimpleCPU, but rather a fetch event that gets scheduled for later on, since reading DRAM memory now takes time:
TimingSimpleCPU::activateContext(ThreadID thread_num)
{
DPRINTF(SimpleCPU, "ActivateContext %d\n", thread_num);
assert(thread_num < numThreads);
threadInfo[thread_num]->notIdleFraction = 1;
if (_status == BaseSimpleCPU::Idle)
_status = BaseSimpleCPU::Running;
// kick things off by initiating the fetch of the next instruction
if (!fetchEvent.scheduled())
schedule(fetchEvent, clockEdge(Cycles(0)));
By looking at the source, we see that fetchEvent runs TimingSimpleCPU::fetch.
Just like for AtomicSimpleCPU, this call comes from the initState call, which is exposed on SimObject and ultimately comes from Python.
24.22.4.2.2. TimingSimpleCPU analysis #1
Backtrace:
EventManager::schedule DRAMCtrl::Rank::startup DRAMCtrl::startup
Snippets:
void
DRAMCtrl::startup()
{
// remember the memory system mode of operation
isTimingMode = system()->isTimingMode();
if (isTimingMode) {
// timestamp offset should be in clock cycles for DRAMPower
timeStampOffset = divCeil(curTick(), tCK);
// update the start tick for the precharge accounting to the
// current tick
for (auto r : ranks) {
r->startup(curTick() + tREFI - tRP);
}
// shift the bus busy time sufficiently far ahead that we never
// have to worry about negative values when computing the time for
// the next request, this will add an insignificant bubble at the
// start of simulation
nextBurstAt = curTick() + tRP + tRCD;
}
}
which then calls:
void
DRAMCtrl::Rank::startup(Tick ref_tick)
{
assert(ref_tick > curTick());
pwrStateTick = curTick();
// kick off the refresh, and give ourselves enough time to
// precharge
schedule(refreshEvent, ref_tick);
}
DRAMCtrl::startup is itself a SimObject method exposed to Python and called from simulate in src/python/m5/simulate.py:
def simulate(*args, **kwargs):
global need_startup
if need_startup:
root = objects.Root.getInstance()
for obj in root.descendants(): obj.startup()
where simulate happens after m5.instantiate, and both are called directly from the toplevel scripts, e.g. for se.py in configs/common/Simulation.py:
def run(options, root, testsys, cpu_class):
...
exit_event = m5.simulate()
By looking up some variable definitions in the source, we now we see some memory parameters clearly:
-
ranks:
std::vector<DRAMCtrl::Rank*>with 2 elements. TODO why do we have 2? What does it represent? Likely linked toconfig.iniatsystem.mem_ctrls.ranks_per_channel=2: https://en.wikipedia.org/wiki/Memory_rank -
tCK=1250,tREFI=7800000,tRP=13750,tRCD=13750: all defined in a single code location with a comment:/** * Basic memory timing parameters initialized based on parameter * values. */Their values can be seen under
config.iniand they are documented insrc/mem/DRAMCtrl.pye.g.:# the base clock period of the DRAM tCK = Param.Latency("Clock period") # minimum time between a precharge and subsequent activate tRP = Param.Latency("Row precharge time") # the amount of time in nanoseconds from issuing an activate command # to the data being available in the row buffer for a read/write tRCD = Param.Latency("RAS to CAS delay") # refresh command interval, how often a "ref" command needs # to be sent. It is 7.8 us for a 64ms refresh requirement tREFI = Param.Latency("Refresh command interval")
So we realize that we are going into deep DRAM modelling, more detail that a mere mortal should ever need to know.
curTick() + tREFI - tRP = 0 + 7800000 - 13750 = 7786250 which is when that refreshEvent was scheduled. Our simulation ends way before that point however, so we will never know what it did thank God.
24.22.4.2.3. TimingSimpleCPU analysis #2
This is just the startup of the second rank, see: TimingSimpleCPU analysis #1.
se.py allocates the memory controller at configs/common/MemConfig.py:
def config_mem(options, system):
...
opt_mem_channels = options.mem_channels
...
nbr_mem_ctrls = opt_mem_channels
...
for r in system.mem_ranges:
for i in range(nbr_mem_ctrls):
mem_ctrl = create_mem_ctrl(cls, r, i, nbr_mem_ctrls, intlv_bits,
intlv_size)
...
mem_ctrls.append(mem_ctrl)
24.22.4.2.4. TimingSimpleCPU analysis #3 and #4
From the timing we know what that one is: the end of time exit event, like for AtomicSimpleCPU.
24.22.4.2.5. TimingSimpleCPU analysis #5
Executes TimingSimpleCPU::fetch().
The log shows that event ID 43 is now executing: we had previously seen event 43 get scheduled and had analyzed it to be the initial fetch.
We can step into TimingSimpleCPU::fetch() to confirm that the expected ELF entry point is being fetched. We can inspect the ELF with:
./run-toolchain --arch aarch64 readelf -- \ -h "$(./getvar --arch aarch64 userland_build_dir)/arch/aarch64/freestanding/linux/hello.out"
which contains:
Entry point address: 0x400078
and by the time we go past:
TimingSimpleCPU::fetch()
{
...
if (needToFetch) {
...
setupFetchRequest(ifetch_req);
DPRINTF(SimpleCPU, "Translating address %#x\n", ifetch_req->getVaddr());
thread->itb->translateTiming(ifetch_req, thread->getTC(),
&fetchTranslation, BaseTLB::Execute);
BaseSimpleCPU::setupFetchRequest sets up the fetch of the expected entry point by reading the PC:
p/x ifetch_req->getVaddr()
Still during the execution of the fetch, execution then moves into the address translation ArmISA::TLB::translateTiming, and after a call to:
TLB::translateSe
the packet now contains the physical address:
_paddr = 0x78
so we deduce that the virtual address 0x400078 maps to the physical address 0x78. But of course, let me log that for you by adding --trace MMU:
0: MMU: system.cpu.workload: Translating: 0x400078->0x78
If we try --trace DRAM we can see:
0: DRAM: system.mem_ctrls: recvTimingReq: request ReadReq addr 120 size 4
where 120 == 0x78 (it logs addresses in decimal? Really??) and the size 4 which is the instruction width.
Now that we are here, we might as well learn how to log the data that was fetched from DRAM.
Fist we determine the expected bytes from the disassembly:
./disas --arch aarch64 --userland userland/arch/aarch64/freestanding/linux/hello.S _start
which shows us the initial instruction encodings near the entry point _start:
0x0000000000400078 <+0>: 20 00 80 d2 mov x0, #0x1 // #1 0x000000000040007c <+4>: e1 00 00 10 adr x1, 0x400098 <msg>
Now, TODO :-) The DRAM logs don’t contain data. Maybe this can be done with CommMonitor, but it is no exposed on fs.py
24.22.4.2.6. TimingSimpleCPU analysis #6
Schedules DRAMCtrl::processNextReqEvent through:
EventManager::schedule DRAMCtrl::addToReadQueue DRAMCtrl::recvTimingReq DRAMCtrl::MemoryPort::recvTimingReq TimingRequestProtocol::sendReq MasterPort::sendTimingReq CoherentXBar::recvTimingReq CoherentXBar::CoherentXBarSlavePort::recvTimingReq TimingRequestProtocol::sendReq MasterPort::sendTimingReq TimingSimpleCPU::sendFetch TimingSimpleCPU::FetchTranslation::finish ArmISA::TLB::translateComplete ArmISA::TLB::translateTiming ArmISA::TLB::translateTiming TimingSimpleCPU::fetch
The event loop has started, and magic initialization schedulings are not happening anymore: now every event is being scheduled from another event:
From the trace, we see that we are already running from the event queue under TimingSimpleCPU::fetch as expected.
From the backtrace we see the tortuous path that the data request takes, going through:
-
ArmISA::TLB -
CoherentXBar -
DRAMCtrl
This matches the config.ini system image, since we see that the request goes through the CoherentXBar before reaching memory, like all other CPU memory accesses, see also: gem5 crossbar interconnect.
The scheduling happens at frame DRAMCtrl::addToReadQueue:
// If we are not already scheduled to get a request out of the
// queue, do so now
if (!nextReqEvent.scheduled()) {
DPRINTF(DRAM, "Request scheduled immediately\n");
schedule(nextReqEvent, curTick());
}
From this we deduce that the DRAM has a request queue of some sort, and that the fetch:
-
has added a read request to that queue
-
and has made a future request to read from the queue
The signature of the function is:
DRAMCtrl::addToReadQueue(PacketPtr pkt, unsigned int pktCount)
where PacketPtr is of class `Packet, and so clearly the packet is coming from above.
From:
p/x *pkt
we see:
addr = 0x78
which from TimingSimpleCPU analysis #5 we know is the physical address of the ELF entry point.
Communication goes through certain components via the class Port interface, e.g. at TimingSimpleCPU::sendFetch a call is made to send the packet forward:
icachePort.sendTimingReq(ifetch_pkt)
which ends up calling:
peer->recvTimingReq(pkt);
to reach the receiving side:
CoherentXBar::CoherentXBarSlavePort::recvTimingReq
Ports are also used to connect the XBar and the DRAM.
We will then see that at TimingSimpleCPU analysis #20 a reply packet will come back through the port interface down to the icache port, and only then does the decoding and execution happen.
24.22.4.2.7. TimingSimpleCPU analysis #7
Schedules BaseXBar::Layer::releaseLayer through:
EventManager::schedule BaseXBar::Layer<SlavePort, MasterPort>::occupyLayer BaseXBar::Layer<SlavePort, MasterPort>::succeededTiming CoherentXBar::recvTimingReq CoherentXBar::CoherentXBarSlavePort::recvTimingReq TimingRequestProtocol::sendReq MasterPort::sendTimingReq TimingSimpleCPU::sendFetch TimingSimpleCPU::FetchTranslation::finish ArmISA::TLB::translateComplete ArmISA::TLB::translateTiming ArmISA::TLB::translateTiming TimingSimpleCPU::fetch
which schedules a SimpleMemory::release.
24.22.4.2.8. TimingSimpleCPU analysis #8
Executes DRAMCtrl::processNextReqEvent.
24.22.4.2.9. TimingSimpleCPU analysis #9
Schedules DRAMCtrl::Rank::processActivateEvent through:
EventManager::schedule DRAMCtrl::activateBank DRAMCtrl::doDRAMAccess DRAMCtrl::processNextReqEvent
24.22.4.2.10. TimingSimpleCPU analysis #10
Schedules DRAMCtrl::processRespondEvent through:
EventManager::schedule DRAMCtrl::processNextReqEvent
24.22.4.2.11. TimingSimpleCPU analysis #11
Schedules DRAMCtrl::processNextReqEvent through:
EventManager::schedule DRAMCtrl::processNextReqEvent
24.22.4.2.12. TimingSimpleCPU analysis #12
Executes DRAMCtrl::Rank::processActivateEvent.
which schedules:
24.22.4.2.13. TimingSimpleCPU analysis #13
Schedules DRAMCtrl::Rank::processPowerEvent through:
EventManager::schedule DRAMCtrl::Rank::schedulePowerEvent DRAMCtrl::Rank::processActivateEvent
24.22.4.2.14. TimingSimpleCPU analysis #14
Executes DRAMCtrl::Rank::processPowerEvent.
This it must just be some power statistics stuff, as it does not schedule anything else.
24.22.4.2.15. TimingSimpleCPU analysis #15
Executes BaseXBar::Layer<SrcType, DstType>::releaseLayer.
24.22.4.2.16. TimingSimpleCPU analysis #16
Executes DRAMCtrl::processNextReqEvent().
24.22.4.2.17. TimingSimpleCPU analysis #17
Executes DRAMCtrl::processRespondEvent().
24.22.4.2.18. TimingSimpleCPU analysis #18
Schedules PacketQueue::processSendEvent() through:
PacketQueue::schedSendEvent PacketQueue::schedSendTiming QueuedSlavePort::schedTimingResp DRAMCtrl::accessAndRespond DRAMCtrl::processRespondEvent
24.22.4.2.19. TimingSimpleCPU analysis #19
Executes PacketQueue::processSendEvent().
24.22.4.2.20. TimingSimpleCPU analysis #20
Schedules PacketQueue::processSendEvent through:
EventManager::schedule PacketQueue::schedSendEvent PacketQueue::schedSendTiming QueuedSlavePort::schedTimingResp CoherentXBar::recvTimingResp CoherentXBar::CoherentXBarMasterPort::recvTimingResp TimingResponseProtocol::sendResp SlavePort::sendTimingResp RespPacketQueue::sendTiming PacketQueue::sendDeferredPacket PacketQueue::processSendEvent
From this backtrace, we see that this event is happening as the fetch reply packet finally comes back from DRAM.
24.22.4.2.21. TimingSimpleCPU analysis #21
Schedules BaseXBar::Layer<SrcType, DstType>::releaseLayer through:
EventManager::schedule BaseXBar::Layer<MasterPort, SlavePort>::occupyLayer BaseXBar::Layer<MasterPort, SlavePort>::succeededTiming CoherentXBar::recvTimingResp CoherentXBar::CoherentXBarMasterPort::recvTimingResp TimingResponseProtocol::sendResp SlavePort::sendTimingResp RespPacketQueue::sendTiming PacketQueue::sendDeferredPacket PacketQueue::processSendEvent
24.22.4.2.22. TimingSimpleCPU analysis #22
Executes BaseXBar::Layer<SrcType, DstType>::releaseLayer.
24.22.4.2.23. TimingSimpleCPU analysis #23
Executes PacketQueue::processSendEvent.
24.22.4.2.24. TimingSimpleCPU analysis #24
Schedules TimingSimpleCPU::IcachePort::ITickEvent::process() through:
EventManager::schedule TimingSimpleCPU::TimingCPUPort::TickEvent::schedule TimingSimpleCPU::IcachePort::recvTimingResp TimingResponseProtocol::sendResp SlavePort::sendTimingResp RespPacketQueue::sendTiming PacketQueue::sendDeferredPacket PacketQueue::processSendEvent
24.22.4.2.25. TimingSimpleCPU analysis #25
Executes TimingSimpleCPU::IcachePort::ITickEvent::process().
This custom process then calls TimingSimpleCPU::completeIfetch(PacketPtr pkt), and that finally executes the very first instruction:
77000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue : movz x0, #1, #0 : IntAlu : D=0x0000000000000001 flags=(IsInteger)
The end of this instruction must be setting things up in a way that can continue the PC walk loop, and by looking at the source and traces, it is clearly from: TimingSimpleCPU::advanceInst which calls TimingSimpleCPU::fetch.
And TimingSimpleCPU::fetch is the very thing we did in this simulation at TimingSimpleCPU analysis #0!!! OMG, that’s the loop.
24.22.4.2.26. TimingSimpleCPU analysis #26
Schedules DRAMCtrl::processNextReqEvent through:
EventManager::schedule DRAMCtrl::addToReadQueue DRAMCtrl::recvTimingReq DRAMCtrl::MemoryPort::recvTimingReq TimingRequestProtocol::sendReq MasterPort::sendTimingReq CoherentXBar::recvTimingReq CoherentXBar::CoherentXBarSlavePort::recvTimingReq TimingRequestProtocol::sendReq MasterPort::sendTimingReq TimingSimpleCPU::sendFetch TimingSimpleCPU::FetchTranslation::finish ArmISA::TLB::translateComplete ArmISA::TLB::translateTiming ArmISA::TLB::translateTiming TimingSimpleCPU::fetch TimingSimpleCPU::advanceInst TimingSimpleCPU::completeIfetch TimingSimpleCPU::IcachePort::ITickEvent::process
24.22.4.2.27. TimingSimpleCPU analysis #27
Schedules BaseXBar::Layer<SrcType, DstType>::releaseLayer through:
EventManager::schedule BaseXBar::Layer<SlavePort, MasterPort>::occupyLayer BaseXBar::Layer<SlavePort, MasterPort>::succeededTiming CoherentXBar::recvTimingReq CoherentXBar::CoherentXBarSlavePort::recvTimingReq TimingRequestProtocol::sendReq MasterPort::sendTimingReq TimingSimpleCPU::sendFetch TimingSimpleCPU::FetchTranslation::finish ArmISA::TLB::translateComplete ArmISA::TLB::translateTiming ArmISA::TLB::translateTiming TimingSimpleCPU::fetch TimingSimpleCPU::advanceInst TimingSimpleCPU::completeIfetch TimingSimpleCPU::IcachePort::ITickEvent::process
24.22.4.2.28. TimingSimpleCPU analysis #28
Execute DRAMCtrl::processNextReqEvent.
24.22.4.2.29. TimingSimpleCPU analysis #29
Schedule DRAMCtrl::processRespondEvent().
24.22.4.2.30. TimingSimpleCPU analysis: LDR stall
One important thing we want to check now, is how the memory reads are going to make the processor stall in the middle of an instruction.
This is also discussed at: gem5 execute vs initiateAcc vs completeAcc.
Since we were using a simple CPU without a pipeline, the data memory access stall everything: there is no further progress until memory comes back.
For that, we can GDB to the TimingSimpleCPU::completeIfetch of the first LDR done in our test program.
By doing that, we see that this time at:
if (curStaticInst && curStaticInst->isMemRef()) {
// load or store: just send to dcache
Fault fault = curStaticInst->initiateAcc(&t_info, traceData);
if (_status == BaseSimpleCPU::Running) {
}
} else if (curStaticInst) {
// non-memory instruction: execute completely now
Fault fault = curStaticInst->execute(&t_info, traceData);
-
curStaticInst->isMemRef()is true, and there is no instructionexecutecall in that part of the branch, only for instructions that don’t touch memory -
_statusisBaseSimpleCPU::Status::DcacheWaitResponseandadvanceInstis not yet called
We can verify that execute never happens by putting a breakpoint on ArmISAInst::LDRXL64_LIT::execute which never gets called.
Therefore, we conclude that initiateAcc is what actually starts the memory request.
Later on, when the memory access completes the event calls TimingSimpleCPU::completeDataAccess which calls ArmISAInst::LDRXL64_LIT::completeAcc, which sets the register value to what was read from memory.
More memory event details can be seen at: gem5 functional vs atomic vs timing memory requests.
The following is the region of interest of the event log:
175000: Event: Event_40: Timing CPU icache tick 40 executed @ 175000 175000: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 9 scheduled @ 175000 175000: Event: system.membus.reqLayer0.wrapped_function_event: EventFunctionWrapped 60 scheduled @ 176000 175000: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 9 executed @ 175000 175000: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 10 scheduled @ 193750 175000: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 9 scheduled @ 175000 175000: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 9 executed @ 175000 176000: Event: system.membus.reqLayer0.wrapped_function_event: EventFunctionWrapped 60 executed @ 176000 193750: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 10 executed @ 193750 193750: Event: system.mem_ctrls.port-RespPacketQueue.wrapped_function_event: EventFunctionWrapped 8 scheduled @ 221750 221750: Event: system.mem_ctrls.port-RespPacketQueue.wrapped_function_event: EventFunctionWrapped 8 executed @ 221750 221750: Event: system.membus.slave[2]-RespPacketQueue.wrapped_function_event: EventFunctionWrapped 66 scheduled @ 224000 221750: Event: system.membus.respLayer2.wrapped_function_event: EventFunctionWrapped 67 scheduled @ 224000 224000: Event: system.membus.respLayer2.wrapped_function_event: EventFunctionWrapped 67 executed @ 224000 224000: Event: system.membus.slave[2]-RespPacketQueue.wrapped_function_event: EventFunctionWrapped 66 executed @ 224000 224000: Event: Event_42: Timing CPU dcache tick 42 scheduled @ 224000 224000: Event: Event_42: Timing CPU dcache tick 42 executed @ 224000 175000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+8 : ldr w2, #4194464 : MemRead : D=0x0000000000000006 A=0x4000a0 flags=(IsInteger|IsMemRef|IsLoad)
We first find it by looking for the ExecEnable of LDR.
Then, we go up to the previous Timing CPU icache tick event, which from the analysis of previous instruction traces, we know is where the instruction execution starts, the LDR instruction fetch is done by then!
Next, several events happen as the data request must be percolating through the memory system, it must be very similar to the instruction fetches. TODO analyze event function names.
Finally, at last we reach
224000: Event: Event_42: Timing CPU dcache tick 42 executed @ 224000 175000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+8 : ldr w2, #4194464 : MemRead : D=0x0000000000000006 A=0x4000a0 flags=(IsInteger|IsMemRef|IsLoad)
from which we guess:
-
224000: this is the time that the data request finally returned, and at which execute gets called -
175000: the log finally prints at the end of execution, but it does not show the actual time that things finished, but rather the time that the ifetch finished, which happened in the past
24.22.4.3. gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis with caches
Let’s just add --caches to gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis to see if things go any faster, and add Cache to --trace as in:
--trace Cache,Event,ExecAll,-ExecSymbol,FmtFlag
The resulting trace is:
#0 0: Event: system.cpu.wrapped_function_event: EventFunctionWrapped 43 scheduled @ 0
#2 0: Event: system.mem_ctrls_0.wrapped_function_event: EventFunctionWrapped 14 scheduled @ 7786250
#3 0: Event: system.mem_ctrls_1.wrapped_function_event: EventFunctionWrapped 20 scheduled @ 7786250
#4 0: Event: Event_84: generic 84 scheduled @ 0
#5 0: Event: Event_84: generic 84 rescheduled @ 18446744073709551615
#6 0: Event: system.cpu.wrapped_function_event: EventFunctionWrapped 43 executed @ 0
#7 0: Cache: system.cpu.icache: access for ReadReq [78:7b] IF miss
#8 0: Event: system.cpu.icache.mem_side-MemSidePort.wrapped_function_event: EventFunctionWrapped 59 scheduled @ 1000
#9 1000: Event: system.cpu.icache.mem_side-MemSidePort.wrapped_function_event: EventFunctionWrapped 59 executed @ 1000
#10 1000: Cache: system.cpu.icache: sendMSHRQueuePacket: MSHR ReadReq [78:7b] IF
#12 1000: Cache: system.cpu.icache: createMissPacket: created ReadCleanReq [40:7f] IF from ReadReq [78:7b] IF
#13 1000: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 9 scheduled @ 1000
#14 1000: Event: system.membus.reqLayer0.wrapped_function_event: EventFunctionWrapped 70 scheduled @ 2000
#15 1000: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 9 executed @ 1000
#16 1000: Event: system.mem_ctrls_0.wrapped_function_event: EventFunctionWrapped 12 scheduled @ 1000
#17 1000: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 10 scheduled @ 46250
#18 1000: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 9 scheduled @ 5000
#19 1000: Event: system.mem_ctrls_0.wrapped_function_event: EventFunctionWrapped 12 executed @ 1000
#20 1000: Event: system.mem_ctrls_0.wrapped_function_event: EventFunctionWrapped 15 scheduled @ 1000
#22 1000: Event: system.mem_ctrls_0.wrapped_function_event: EventFunctionWrapped 15 executed @ 1000
#23 2000: Event: system.membus.reqLayer0.wrapped_function_event: EventFunctionWrapped 70 executed @ 2000
#24 5000: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 9 executed @ 5000
#25 46250: Event: system.mem_ctrls.wrapped_function_event: EventFunctionWrapped 10 executed @ 46250
#26 46250: Event: system.mem_ctrls.port-RespPacketQueue.wrapped_function_event: EventFunctionWrapped 8 scheduled @ 74250
#27 74250: Event: system.mem_ctrls.port-RespPacketQueue.wrapped_function_event: EventFunctionWrapped 8 executed @ 74250
#28 74250: Event: system.membus.slave[1]-RespPacketQueue.wrapped_function_event: EventFunctionWrapped 74 scheduled @ 77000
#29 74250: Event: system.membus.respLayer1.wrapped_function_event: EventFunctionWrapped 75 scheduled @ 80000
#30 77000: Event: system.membus.slave[1]-RespPacketQueue.wrapped_function_event: EventFunctionWrapped 74 executed @ 77000
#32 77000: Cache: system.cpu.icache: recvTimingResp: Handling response ReadResp [40:7f] IF
#33 77000: Cache: system.cpu.icache: Block for addr 0x40 being updated in Cache
#34 77000: Cache: system.cpu.icache: Block addr 0x40 (ns) moving from state 0 to state: 7 (E) valid: 1 writable: 1 readable: 1 dirty: 0 | tag: 0 set: 0x1 way: 0
#35 77000: Event: system.cpu.icache.cpu_side-CpuSidePort.wrapped_function_event: EventFunctionWrapped 57 scheduled @ 78000
#36 78000: Event: system.cpu.icache.cpu_side-CpuSidePort.wrapped_function_event: EventFunctionWrapped 57 executed @ 78000
#37 78000: Event: Event_40: Timing CPU icache tick 40 scheduled @ 78000
#38 78000: Event: Event_40: Timing CPU icache tick 40 executed @ 78000
#39 78000: ExecEnable: system.cpu: A0 T0 : 0x400078 : movz x0, #1, #0 : IntAlu : D=0x0000000000000001 flags=(IsInteger)
#40 78000: Cache: system.cpu.icache: access for ReadReq [7c:7f] IF hit state: 7 (E) valid: 1 writable: 1 readable: 1 dirty: 0 | tag: 0 set: 0x1 way: 0
#42 78000: Event: system.cpu.icache.cpu_side-CpuSidePort.wrapped_function_event: EventFunctionWrapped 57 scheduled @ 83000
#43 80000: Event: system.membus.respLayer1.wrapped_function_event: EventFunctionWrapped 75 executed @ 80000
#44 83000: Event: system.cpu.icache.cpu_side-CpuSidePort.wrapped_function_event: EventFunctionWrapped 57 executed @ 83000
#45 83000: Event: Event_40: Timing CPU icache tick 40 scheduled @ 83000
#46 83000: Event: Event_40: Timing CPU icache tick 40 executed @ 83000
#47 83000: ExecEnable: system.cpu: A0 T0 : 0x40007c : adr x1, #28 : IntAlu : D=0x0000000000400098 flags=(IsInteger)
#48 83000: Event: system.cpu.icache.mem_side-MemSidePort.wrapped_function_event: EventFunctionWrapped 59 scheduled @ 84000
[...]
191000: Event: Event_85: generic 85 scheduled @ 191000
191000: Event: Event_85: generic 85 executed @ 191000
So yes, --caches does work here, leading to a runtime of 191000 rather than 469000 without caches!
Notably, we now see that very little time passed between the first and second instructions which are marked with ExecEnable in #39 and #47, presumably because rather than going out all the way to the DRAM system the event chain stops right at the icache.cpu_side when a hit happens, which must have been the case for the second instruction, which is just adjacent to the first one.
It is also interested to look into the generated config.dot.svg to compare it to the one without caches: Figure 3, “config.dot.svg for a TimingSimpleCPU without caches.”. With caches: Figure 4, “config.dot.svg for a TimingSimpleCPU with caches.”.
We can see from there, that we now have icache and dcache elements inside the CPU block, and that the CPU icache and dcache ports go through the caches to the SystemXBar rather than being directly connected as before.
It is worth noting that the caches do not affect the ArmITB and ArmDTB TLBs, since those are already caches themselves.

config.dot.svg for a TimingSimpleCPU with caches.We can break down the events between the instructions as follows.
First, based on TimingSimpleCPU analysis #5, we b TimingSimpleCPU::fetch to see how the initial magically scheduled fetch, and necessarily cache miss, work:
EventManager::schedule PacketQueue::schedSendEvent BaseCache::CacheMasterPort::schedSendEvent BaseCache::schedMemSideSendEvent BaseCache::allocateMissBuffer BaseCache::handleTimingReqMiss Cache::handleTimingReqMiss BaseCache::recvTimingReq Cache::recvTimingReq BaseCache::CpuSidePort::recvTimingReq TimingRequestProtocol::sendReq MasterPort::sendTimingReq TimingSimpleCPU::sendFetch TimingSimpleCPU::FetchTranslation::finish ArmISA::TLB::translateComplete ArmISA::TLB::translateTiming ArmISA::TLB::translateTiming TimingSimpleCPU::fetch
By comparing this to the uncached access at TimingSimpleCPU analysis #25, we see that this one does not reach the CoherentXBar at all: the cache must be scheduling an event in the future to model a delay between the cache request and XBar communication.
A quick source structural view shows that the source for non-Ruby caches such as the ones from this example are located under:
src/mem/cache
and the following simple class hierarchy:
-
BaseCache-
Cache -
NoncoherentCache
-
Next, we fast forward to #39 with b TimingSimpleCPU::IcachePort::ITickEvent::process which as we knows from previous sections, is the event that executes instructions, and therefore leaves us at the start of the second instruction.
Then, we b EventManager::schedule to see what that schedules:
EventManager::schedule PacketQueue::schedSendEvent PacketQueue::schedSendTiming QueuedSlavePort::schedTimingResp BaseCache::handleTimingReqHit Cache::handleTimingReqHit BaseCache::recvTimingReq Cache::recvTimingReq BaseCache::CpuSidePort::recvTimingReq TimingRequestProtocol::sendReq MasterPort::sendTimingReq TimingSimpleCPU::sendFetch TimingSimpleCPU::FetchTranslation::finish ArmISA::TLB::translateComplete ArmISA::TLB::translateTiming ArmISA::TLB::translateTiming TimingSimpleCPU::fetch TimingSimpleCPU::advanceInst TimingSimpleCPU::completeIfetch TimingSimpleCPU::IcachePort::ITickEvent::process
By comparing this trace from the this cache hit and the previous cache miss, we see that BaseCache::recvTimingReq decides between either: Cache::handleTimingReqHit and Cache::handleTimingReqMiss, and from there we see that the key function that decides if the block is present is BaseCache::access.
We can see access behaviour at on the log lines, e.g.:
#7 0: Cache: system.cpu.icache: access for ReadReq [78:7b] IF miss #40 78000: Cache: system.cpu.icache: access for ReadReq [7c:7f] IF hit state: 7 (E) valid: 1 writable: 1 readable: 1 dirty: 0 | tag: 0 set: 0x1 way: 0
which makes sense since from TimingSimpleCPU analysis #5 we know that the physical address of the initial instruction is 0x78, and 4 bytes are read for each instruction, so the second instruction access is at 0x7c.
The hit line also shows the precise cache state E from the MOESI protocol: What is the coherency protocol implemented by the classic cache system in gem5?.
The other log lines are also very clear, e.g. for the miss we see the following lines:
#10 1000: Cache: system.cpu.icache: sendMSHRQueuePacket: MSHR ReadReq [78:7b] IF #12 1000: Cache: system.cpu.icache: createMissPacket: created ReadCleanReq [40:7f] IF from ReadReq [78:7b] IF #32 77000: Cache: system.cpu.icache: recvTimingResp: Handling response ReadResp [40:7f] IF #33 77000: Cache: system.cpu.icache: Block for addr 0x40 being updated in Cache #34 77000: Cache: system.cpu.icache: Block addr 0x40 (ns) moving from state 0 to state: 7 (E) valid: 1 writable: 1 readable: 1 dirty: 0 | tag: 0 set: 0x1 way: 0
This shows us that the cache miss fills the cache line 40:7f, so we deduce that the cache block size is 0x40 == 64 bytes. The second address only barely hit at the last bytes of the block!
It also informs us that the cache moved to E (from the initial I) state since a memory read was done.
We can confirm this with --trace DRAM which shows:
1000: DRAM: system.mem_ctrls: recvTimingReq: request ReadCleanReq addr 64 size 64
Contrast this with the non --cache version seen at TimingSimpleCPU analysis #5 in which DRAM only actually reads the 4 required bytes.
The only cryptic thing about the messages is the IF flag, but good computer architects would have guessed it correctly that it is "instruction fetch" and src/mem/packet.cc confirms:
void
Packet::print(std::ostream &o, const int verbosity,
const std::string &prefix) const
{
ccprintf(o, "%s%s [%x:%x]%s%s%s%s%s%s", prefix, cmdString(),
getAddr(), getAddr() + getSize() - 1,
req->isSecure() ? " (s)" : "",
req->isInstFetch() ? " IF" : "",
req->isUncacheable() ? " UC" : "",
isExpressSnoop() ? " ES" : "",
req->isToPOC() ? " PoC" : "",
req->isToPOU() ? " PoU" : "");
}
Another interesting observation of running with --trace Cache,DRAM,XBar is that between the execution of both instructions, there is a Cache event, but no DRAM or XBar events:
78000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue : movz x0, #1, #0 : IntAlu : D=0x0000000000000001 flags=(IsInteger) 78000: Cache: system.cpu.icache: access for ReadReq [7c:7f] IF hit state: 7 (E) valid: 1 writable: 1 readable: 1 dirty: 0 | tag: 0 set: 0x1 way: 0 83000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+4 : adr x1, #28 : IntAlu : D=0x0000000000400098 flags=(IsInteger)
which is further consistent with the cache hit idea: no traffic goes down to the DRAM nor crossbar.
This block size parameter can be seen set on the gem5 config.ini file:
[system] cache_line_size=64
so it is runtime configurable. The other key cache parameters can be seen further down in the config:
[system.cpu.dcache] assoc=2 size=65536 [system.cpu.dcache.replacement_policy] type=LRURP [system.cpu.dcache.tags.indexing_policy] type=SetAssociative
so we understand that by default the classic cache:
-
is 2-way https://en.wikipedia.org/wiki/CPU_cache#Two-way_set_associative_cache
-
has 16KiB total size
-
uses LRURP replacement policy. LRU is a well known policy, "LRU RP" seems to simply stand for "LRU Replacement Policy". Other policies can be seen under: src/mem/cache/replacement_policies/
At:
#7 0: Cache: system.cpu.icache: access for ReadReq [78:7b] IF miss #8 0: Event: system.cpu.icache.mem_side-MemSidePort.wrapped_function_event: EventFunctionWrapped 59 scheduled @ 1000 #9 1000: Event: system.cpu.icache.mem_side-MemSidePort.wrapped_function_event: EventFunctionWrapped 59 executed @ 1000 #10 1000: Cache: system.cpu.icache: sendMSHRQueuePacket: MSHR ReadReq [78:7b] IF #12 1000: Cache: system.cpu.icache: createMissPacket: created ReadCleanReq [40:7f] IF from ReadReq [78:7b] IF
we can briefly see the gem5 MSHR doing its thing.
At time 0, the CPU icache wants to read, so it creates a packet that reads 4 bytes only ([78:7b]) for the instruction, and that goes into the MSHR, to be treated in a future event.
At 1000, the future event is executed, and so it reads the original packet from the MSHR, and uses that to create a new request [40:7f] which gets forwarded.
24.22.4.3.1. What is the coherency protocol implemented by the classic cache system in gem5?
MOESI cache coherence protocol: https://github.com/gem5/gem5/blob/9fc9c67b4242c03f165951775be5cd0812f2a705/src/mem/cache/cache_blk.hh#L352
The actual representation is done via separate state bits: https://github.com/gem5/gem5/blob/9fc9c67b4242c03f165951775be5cd0812f2a705/src/mem/cache/cache_blk.hh#L66 and MOESI appears explicitly only on the pretty printing.
This pretty printing appears for example in the --trace Cache lines as shown at gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis with caches and with a few more transitions visible at Section 24.22.4.4, “gem5 event queue AtomicSimpleCPU syscall emulation freestanding example analysis with caches and multiple CPUs”.
24.22.4.4. gem5 event queue AtomicSimpleCPU syscall emulation freestanding example analysis with caches and multiple CPUs
It would be amazing to analyze a simple example with interconnect packets possibly invalidating caches of other CPUs.
To observe it we could create one well controlled workload with instructions that flush memory, and run it on two CPUs.
If we don’t use such instructions that flush memory, we would only see the interconnect at work when caches run out.
For this study, we will use the same CLI as gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis but with multiple CPUs and a multithreaded which shares a variable across threads.
We can use userland/c/atomic.c (see also C multithreading) at LKMC 7c01b29f1ee7da878c7cc9cb4565f3f3cf516a92 and gem5 872cb227fdc0b4d60acc7840889d567a6936b6e1 was with as in Detailed gem5 analysis of how data races happen:
./run \ --arch aarch64 \ --cli-args '2 10' \ --cpus 3 \ --emulator gem5 \ --trace FmtFlag,Cache,DRAM,ExecAll,XBar \ --userland userland/c/atomic.c \ -- \ --caches \ ;
The config.dot.svg now looks like this but with 3 CPUs instead of 2:

config.dot.svg for a system with two TimingSimpleCPU with caches.Once again we focus on the shared function region my_thread_main which is where the interesting cross core memory collisions will be happening.
As a maybe-not-so-interesting, we have a look at the very first my_thread_main icache hit points:
93946000: Cache: system.cpu1.icache: access for ReadReq [8b0:8b3] IF miss 93946000: Cache: system.cpu1.icache: createMissPacket: created ReadCleanReq [880:8bf] IF from ReadReq [8b0:8b3] IF 93946000: Cache: system.cpu1.icache: handleAtomicReqMiss: Sending an atomic ReadCleanReq [880:8bf] IF 93946000: CoherentXBar: system.membus: recvAtomicBackdoor: src system.membus.slave[5] packet ReadCleanReq [880:8bf] IF 93946000: CoherentXBar: system.membus: recvAtomicBackdoor: src system.membus.slave[5] packet ReadCleanReq [880:8bf] IF SF size: 1 lat: 1 93946000: Cache: system.cpu0.icache: handleSnoop: snoop hit for ReadCleanReq [880:8bf] IF, old state is state: 7 (E) valid: 1 writable: 1 readable: 1 dirty: 0 | tag: 0 set: 0x22 way: 0 93946000: Cache: system.cpu0.icache: new state is state: 5 (S) valid: 1 writable: 0 readable: 1 dirty: 0 | tag: 0 set: 0x22 way: 0 93946000: DRAM: system.mem_ctrls: recvAtomic: ReadCleanReq 0x880 93946000: Cache: system.cpu1.icache: handleAtomicReqMiss: Receive response: ReadResp [880:8bf] IF in state 0 93946000: Cache: system.cpu1.icache: Block addr 0x880 (ns) moving from state 0 to state: 5 (S) valid: 1 writable: 0 readable: 1 dirty: 0 | tag: 0 set: 0x22 way: 0 93946000: ExecEnable: system.cpu1: A0 T0 : @my_thread_main : sub sp, sp, #48 : IntAlu : D=0x0000003fffd6b9a0 flags=(IsInteger) 93946500: Cache: system.cpu1.icache: access for ReadReq [8b4:8b7] IF hit state: 5 (S) valid: 1 writable: 0 readable: 1 dirty: 0 | tag: 0 set: 0x22 way: 0 93946500: Cache: system.cpu1.dcache: access for WriteReq [a19a8:a19af] hit state: f (M) valid: 1 writable: 1 readable: 1 dirty: 1 | tag: 0x14 set: 0x66 way: 0 93946500: ExecEnable: system.cpu1: A0 T0 : @my_thread_main+4 : str x0, [sp, #8] : MemWrite : D=0x0000007ffffefc70 A=0x3fffd6b9a8 flags=(IsInteger|IsMemRef|IsStore)
Now that we know how to read cache logs from gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis with caches, it is easier to understand what happened:
-
the physical address for
my_thread_mainis at 0x8b0, which gets requested is a miss, since it is the first time CPU1 goes near that region, since CPU1 was previously executing in standard library code far from our text segment -
CPU0 already has has that cache line (0x880) in its cache at state E of MOESI, so it snoops and moves to S. We can look up the logs to see exactly where CPU0 had previously read that address:
59135500: Cache: system.cpu0.icache: Block addr 0x880 (ns) moving from state 0 to state: 7 (E) valid: 1 writable: 1 readable: 1 dirty: 0 | tag: 0 set: 0x22 way: 0 59135500: CoherentXBar: system.membus: recvAtomicBackdoor: src system.membus.slave[1] packet WritebackClean [8880:88bf] 59135500: CoherentXBar: system.membus: recvAtomicBackdoor: src system.membus.slave[1] packet WritebackClean [8880:88bf] SF size: 0 lat: 1 59135500: DRAM: system.mem_ctrls: recvAtomic: WritebackClean 0x8880 59135500: ExecEnable: system.cpu0: A0 T0 : @frame_dummy : stp
-
the request does touch RAM, it does not get served by the other cache directly. CPU1 is now also at state S for the block
-
the second cache request from CPU1 is 4 bytes further ahead 0x8b4, and this time it is of course a hit.
Since this is an STR, it also does a dcache access, to 0xA19A8 in this case near its stack SP, and it is a hit, which is not surprising, since basically stack accesses are the very first thing any C code does, and there must be some setup code running on CPU1 before
my_thread_main.
Now let’s look for the incremented integer address that is shared across threads. We know from Detailed gem5 analysis of how data races happen that the read happens at my_thread_main+36, so searching for he first occurrence:
93952500: Cache: system.cpu1.icache: access for ReadReq [8d4:8d7] IF hit state: 7 (E) valid: 1 writable: 1 readable: 1 dirty: 0 | tag: 0 set: 0x23 way: 0 93952500: Cache: system.cpu1.dcache: access for ReadReq [2060:2063] miss 93952500: Cache: system.cpu1.dcache: createMissPacket: created ReadSharedReq [2040:207f] from ReadReq [2060:2063] 93952500: Cache: system.cpu1.dcache: handleAtomicReqMiss: Sending an atomic ReadSharedReq [2040:207f] 93952500: CoherentXBar: system.membus: recvAtomicBackdoor: src system.membus.slave[6] packet ReadSharedReq [2040:207f] 93952500: CoherentXBar: system.membus: recvAtomicBackdoor: src system.membus.slave[6] packet ReadSharedReq [2040:207f] SF size: 0 lat: 1 93952500: DRAM: system.mem_ctrls: recvAtomic: ReadSharedReq 0x2040 93952500: Cache: system.cpu1.dcache: handleAtomicReqMiss: Receive response: ReadResp [2040:207f] in state 0 93952500: Cache: system.cpu1.dcache: Block addr 0x2040 (ns) moving from state 0 to state: 7 (E) valid: 1 writable: 1 readable: 1 dirty: 0 | tag: 0 set: 0x81 way: 0 93952500: ExecEnable: system.cpu1: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000000 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad)
so we determine its physical address of 0x2060. It was a miss, and then it went into E.
So we look ahead to the following accesses to that physical address, before CPU2 reaches that point of the code and starts making requests as well.
First there is the STR for the first LDR which is of course a hit:
93954500: Cache: system.cpu1.dcache: access for WriteReq [2060:2063] hit state: 7 (E) valid: 1 writable: 1 readable: 1 dirty: 0 | tag: 0 set: 0x81 way: 0 93954500: ExecEnable: system.cpu1: A0 T0 : @my_thread_main+52 : str x1, [x0] : MemWrite : D=0x0000000000000001 A=0x411060 flags=(IsInteger|IsMemRef|IsStore)
If found the line in E, so we presume that it moves it to M. Then the second read confirms that it was in M:
93964500: Cache: system.cpu1.dcache: access for ReadReq [2060:2063] hit state: f (M) valid: 1 writable: 1 readable: 1 dirty: 1 | tag: 0 set: 0x81 way: 0 93964500: ExecEnable: system.cpu1: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000001 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad)
and so on.
Now let’s jump to when CPU2 starts making requests.
The first time this happens is on its first LDR at:
94058500: Cache: system.cpu2.dcache: access for ReadReq [2060:2063] miss 94058500: Cache: system.cpu2.dcache: createMissPacket: created ReadSharedReq [2040:207f] from ReadReq [2060:2063] 94058500: Cache: system.cpu2.dcache: handleAtomicReqMiss: Sending an atomic ReadSharedReq [2040:207f] 94058500: CoherentXBar: system.membus: recvAtomicBackdoor: src system.membus.slave[10] packet ReadSharedReq [2040:207f] 94058500: CoherentXBar: system.membus: recvAtomicBackdoor: src system.membus.slave[10] packet ReadSharedReq [2040:207f] SF size: 1 lat: 1 94058500: Cache: system.cpu1.dcache: handleSnoop: snoop hit for ReadSharedReq [2040:207f], old state is state: f (M) valid: 1 writable: 1 readable: 1 dirty: 1 | tag: 0 set: 0x81 way: 0 94058500: Cache: system.cpu1.dcache: new state is state: d (O) valid: 1 writable: 0 readable: 1 dirty: 1 | tag: 0 set: 0x81 way: 0 94058500: CoherentXBar: system.membus: recvAtomicBackdoor: Not forwarding ReadSharedReq [2040:207f] 94058500: Cache: system.cpu2.dcache: handleAtomicReqMiss: Receive response: ReadResp [2040:207f] in state 0 94058500: Cache: system.cpu2.dcache: Block addr 0x2040 (ns) moving from state 0 to state: 5 (S) valid: 1 writable: 0 readable: 1 dirty: 0 | tag: 0 set: 0x81 way: 0 94058500: ExecEnable: system.cpu2: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000009 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad)
and from this we see:
-
CPU1 moves from M to O
-
CPU2 moves from I to S
It also appears that no DRAM was accessed since there are no logs for it, so did the XBar get the value directly from the other cache? TODO: why did the earlier 93946000: DRAM read happened then, since CPU0 had the line when CPU1 asked for it?
The above log sequence also makes it clear that it is the XBar that maintains coherency: it appears that the CPU2 caches tells the XBar what it is doing, and then the XBar tells other caches on other CPUs about it, which leads CPU1 to move to O.
Then CPU1 hits its LDR on O:
94060500: Cache: system.cpu1.dcache: access for ReadReq [2060:2063] hit state: d (O) valid: 1 writable: 0 readable: 1 dirty: 1 | tag: 0 set: 0x81 way: 0 94060500: ExecEnable: system.cpu1: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000009 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad)
and then CPU2 writes moving to M and moving CPU1 to I:
94060500: Cache: system.cpu2.dcache: access for WriteReq [2060:2063] hit state: 5 (S) valid: 1 writable: 0 readable: 1 dirty: 0 | tag: 0 set: 0x81 way: 0 94060500: Cache: system.cpu2.dcache: createMissPacket: created UpgradeReq [2040:207f] from WriteReq [2060:2063] 94060500: Cache: system.cpu2.dcache: handleAtomicReqMiss: Sending an atomic UpgradeReq [2040:207f] 94060500: CoherentXBar: system.membus: recvAtomicBackdoor: src system.membus.slave[10] packet UpgradeReq [2040:207f] 94060500: CoherentXBar: system.membus: recvAtomicBackdoor: src system.membus.slave[10] packet UpgradeReq [2040:207f] SF size: 1 lat: 1 94060500: Cache: system.cpu1.dcache: handleSnoop: snoop hit for UpgradeReq [2040:207f], old state is state: d (O) valid: 1 writable: 0 readable: 1 dirty: 1 | tag: 0 set: 0x81 way: 0 94060500: Cache: system.cpu1.dcache: new state is state: 0 (I) valid: 0 writable: 0 readable: 0 dirty: 0 | tag: 0xffffffffffffffff set: 0x81 way: 0 94060500: CoherentXBar: system.membus: recvAtomicBackdoor: Not forwarding UpgradeReq [2040:207f] 94060500: Cache: system.cpu2.dcache: handleAtomicReqMiss: Receive response: UpgradeResp [2040:207f] in state 5 94060500: Cache: system.cpu2.dcache: Block addr 0x2040 (ns) moving from state 5 to state: f (M) valid: 1 writable: 1 readable: 1 dirty: 1 | tag: 0 set: 0x81 way: 0 94060500: ExecEnable: system.cpu2: A0 T0 : @my_thread_main+52 : str x1, [x0] : MemWrite : D=0x000000000000000a A=0x411060 flags=(IsInteger|IsMemRef|IsStore)
and so on, they just keep fighting over that address and changing one another’s state.
24.22.4.5. gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis with caches and multiple CPUs
Like gem5 event queue AtomicSimpleCPU syscall emulation freestanding example analysis with caches and multiple CPUs but with gem5 TimingSimpleCPU and userland/c/atomic/aarch64_add.c:
./build-userland --arch aarch64 --optimization-level 3 --userland-build-id o3 ./run \ --arch aarch64 \ --cli-args '2 1000' \ --cpus 3 \ --emulator gem5 \ --trace FmtFlag,CacheAll,DRAM,Event,ExecAll,SimpleCPU,XBar \ --userland userland/c/atomic/aarch64_add.c \ --userland-build-id o3 \ -- \ --caches \ --cpu-type TimingSimpleCPU \ ;
This is arguably the best experiment to study the gem5 crossbar interconnect.
We increase the loop count to 100 loops because 100 did not show memory conflicts. The output is:
expect 200 global 147
Let’s double check what it compiles to with disas:
./disas --arch aarch64 --userland userland/c/atomic/aarch64_add.c --userland-build-id o3 my_thread_main
which contains:
0x0000000000400a70 <+0>: 03 00 40 f9 ldr x3, [x0] 0x0000000000400a74 <+4>: 63 01 00 b4 cbz x3, 0x400aa0 <my_thread_main+48> 0x0000000000400a78 <+8>: 82 00 00 d0 adrp x2, 0x412000 <malloc@got.plt> 0x0000000000400a7c <+12>: 42 a0 01 91 add x2, x2, #0x68 0x0000000000400a80 <+16>: 00 00 80 d2 mov x0, #0x0 // #0 0x0000000000400a84 <+20>: 1f 20 03 d5 nop 0x0000000000400a88 <+24>: 41 00 40 f9 ldr x1, [x2] 0x0000000000400a8c <+28>: 21 04 00 91 add x1, x1, #0x1 0x0000000000400a90 <+32>: 41 00 00 f9 str x1, [x2] 0x0000000000400a94 <+36>: 00 04 00 91 add x0, x0, #0x1 0x0000000000400a98 <+40>: 7f 00 00 eb cmp x3, x0 0x0000000000400a9c <+44>: 68 ff ff 54 b.hi 0x400a88 <my_thread_main+24> // b.pmore 0x0000000000400aa0 <+48>: 00 00 80 52 mov w0, #0x0 // #0 0x0000000000400aa4 <+52>: c0 03 5f d6 ret
Grepping the logs with grep '@my_thread_main\+24 shows where the first non-atomic interleaves happen at:
[many other CPU1 hits] 471199000: ExecEnable: system.cpu1: A0 T0 : @my_thread_main+24 : ldr x1, [x2] : MemRead : D=0x000000000000002e A=0x412068 flags=(IsInteger|IsMemRef|IsLoad) 471207000: ExecEnable: system.cpu1: A0 T0 : @my_thread_main+24 : ldr x1, [x2] : MemRead : D=0x000000000000002f A=0x412068 flags=(IsInteger|IsMemRef|IsLoad) 471202000: ExecEnable: system.cpu2: A0 T0 : @my_thread_main+24 : ldr x1, [x2] : MemRead : D=0x000000000000002f A=0x412068 flags=(IsInteger|IsMemRef|IsLoad) 471239000: ExecEnable: system.cpu2: A0 T0 : @my_thread_main+24 : ldr x1, [x2] : MemRead : D=0x0000000000000030 A=0x412068 flags=(IsInteger|IsMemRef|IsLoad) 471228000: ExecEnable: system.cpu1: A0 T0 : @my_thread_main+24 : ldr x1, [x2] : MemRead : D=0x0000000000000030 A=0x412068 flags=(IsInteger|IsMemRef|IsLoad) 471269000: ExecEnable: system.cpu1: A0 T0 : @my_thread_main+24 : ldr x1, [x2] : MemRead : D=0x0000000000000031 A=0x412068 flags=(IsInteger|IsMemRef|IsLoad)
after a long string of cpu1 hits, since CPU1 was forked first and therefore had more time to run that operation.
From those and logs around we deduce that:
-
the shared address of interest is 0x412068
-
the physical address is 0x2068
-
it fits into the cache line for 0x2040:0x207f
With that guide, we look at the fuller logs around that region of interest. With start at the first ifetch that CPU2 does for our LDR of interest at 0x400a88:
471201000: SimpleCPU: system.cpu2: Fetch 471201000: SimpleCPU: system.cpu2: Translating address 0x400a88
Things get a bit interleaved with CPU1, but soon afterwards we see the CPU2 make its memory request to the cache:
471202000: Event: Event_134: Timing CPU icache tick 134 executed @ 471202000 471202000: SimpleCPU: system.cpu2: Complete ICache Fetch for addr 0xa88 471202000: Cache: system.cpu2.dcache: access for ReadReq [2068:206f] D=c879334bb1550000 num=266073 miss 471202000: CachePort: system.cpu2.dcache.mem_side: Scheduling send event at 471203000 471202000: Event: system.cpu2.dcache.mem_side-MemSidePort.wrapped_function_event: EventFunctionWrapped 140 scheduled @ 471203000
Before the request moves on, some CPU1 action happens: a CPU1 is sending its data out! It hit the cache, and now we confirm that the cache is in state: M as expected, since CPU1 had already been previously writting repeatedly to that address:
471202000: Event: Event_87: Timing CPU icache tick 87 executed @ 471202000 471202000: SimpleCPU: system.cpu1: Complete ICache Fetch for addr 0xa90 471202000: Cache: system.cpu1.dcache: access for WriteReq [2068:206f] D=2f00000000000000 num=266074 hit state: f (M) valid: 1 writable: 1 readable: 1 dirty: 1 | tag: 0 set: 0x81 way: 0 471202000: CacheVerbose: system.cpu1.dcache: satisfyRequest for WriteReq [2068:206f] D=2f00000000000000 num=266074 (write) 471202000: Event: system.cpu1.dcache.cpu_side-CpuSidePort.wrapped_function_event: EventFunctionWrapped 91 scheduled @ 471203000
Immediately afterwards, CPU1 gets its reply from the cache, which is fast as that was a hit, and its STR finishes:
471203000: Event: system.cpu1.dcache.cpu_side-CpuSidePort.wrapped_function_event: EventFunctionWrapped 91 executed @ 471203000 471203000: SimpleCPU: system.cpu1.dcache_port: Received load/store response 0x2068 471203000: Event: Event_89: Timing CPU dcache tick 89 scheduled @ 471203000 471203000: Event: Event_89: Timing CPU dcache tick 89 executed @ 471203000 471202000: ExecEnable: system.cpu1: A0 T0 : @my_thread_main+32 : str x1, [x2] : MemWrite : D=0x000000000000002f A=0x412068 flags=(IsInteger|IsMemRef|IsStore)
Now we approach the crux of this example: cpu2 dcache decides to forward its read request:
471203000: Event: system.cpu2.dcache.mem_side-MemSidePort.wrapped_function_event: EventFunctionWrapped 140 executed @ 471203000 471203000: Cache: system.cpu2.dcache: sendMSHRQueuePacket: MSHR ReadReq [2068:206f] D=c879334bb1550000 num=266073 471203000: Cache: system.cpu2.dcache: createMissPacket: created ReadSharedReq [2040:207f] D=40cfe14bb15500005b323036383a323036665d20443d63383739333334626231353530303030206e756d3d32363630373300000000016d6973730a0000000000 num=266076 from ReadReq [2068:206f] D=c879334bb1550000 num=266073
Here, CPU2 dcache finally forwards to the XBar its request via the gem5 MSHR mechanism as in gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis with caches
createMissPacket creates a new packet for the cache request with a different type: ReadSharedReq instead of the original ReadReq, and then it sends that packet into CoherentXBar:
471203000: CoherentXBar: system.membus: recvTimingReq: src system.membus.slave[10] packet ReadSharedReq [2040:207f] D=40cfe14bb15500005b323036383a323036665d20443d63383739333334626231353530303030206e756d3d32363630373300000000016d6973730a0000000000 num=266076 471203000: SnoopFilter: system.membus.snoop_filter: lookupRequest: src system.membus.slave[10] packet ReadSharedReq [2040:207f] D=40cfe14bb15500005b323036383a323036665d20443d63383739333334626231353530303030206e756d3d32363630373300000000016d6973730a0000000000 num=266076 471203000: SnoopFilter: system.membus.snoop_filter: lookupRequest: SF value 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000.0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000001000 471203000: SnoopFilter: system.membus.snoop_filter: lookupRequest: new SF value 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000100000.0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000001000 471203000: CoherentXBar: system.membus: recvTimingReq: src system.membus.slave[10] packet ReadSharedReq [2040:207f] D=40cfe14bb15500005b323036383a323036665d20443d63383739333334626231353530303030206e756d3d32363630373300000000016d6973730a0000000000 num=266076 SF size: 1 lat: 1 471203000: CoherentXBar: system.membus: forwardTiming for ReadSharedReq [2040:207f] D=40cfe14bb15500005b323036383a323036665d20443d63383739333334626231353530303030206e756d3d32363630373300000000016d6973730a0000000000 num=266076
The XBar receives the request, and notices that CPU1 cares about it, because obviously it has that line from previous writes, so the XBar forwards the exact same request to the CPU1 dcache:
471203000: CacheVerbose: system.cpu1.dcache: recvTimingSnoopReq: for ReadSharedReq [2040:207f] D=40cfe14bb15500005b323036383a323036665d20443d63383739333334626231353530303030206e756d3d32363630373300000000016d6973730a0000000000 num=266076 471203000: CacheVerbose: system.cpu1.dcache: handleSnoop: for ReadSharedReq [2040:207f] D=40cfe14bb15500005b323036383a323036665d20443d63383739333334626231353530303030206e756d3d32363630373300000000016d6973730a0000000000 num=266076 471203000: Cache: system.cpu1.dcache: handleSnoop: snoop hit for ReadSharedReq [2040:207f] D=40cfe14bb15500005b323036383a323036665d20443d63383739333334626231353530303030206e756d3d32363630373300000000016d6973730a0000000000 num=266076, old state is state: f (M) valid: 1 writable: 1 readable: 1 dirty: 1 | tag: 0 set: 0x81 way: 0 471203000: Cache: system.cpu1.dcache: new state is state: d (O) valid: 1 writable: 0 readable: 1 dirty: 1 | tag: 0 set: 0x81 way: 0 471203000: Cache: system.cpu1.dcache: doTimingSupplyResponse: for ReadSharedReq [2040:207f] D=40cfe14bb15500005b323036383a323036665d20443d63383739333334626231353530303030206e756d3d32363630373300000000016d6973730a0000000000 num=266076 471203000: CacheVerbose: system.cpu1.dcache: doTimingSupplyResponse: created response: ReadResp [2040:207f] D=700640000000000070064000000000000000000000000000000000000000000000000000000000002f0000000000000000000000000000000000000000000000 num=266078 tick: 471212000 471203000: Event: system.cpu1.dcache.mem_side-MemSidePort.wrapped_function_event: EventFunctionWrapped 94 scheduled @ 471212000 471203000: CoherentXBar: system.membus: recvTimingReq: Not forwarding ReadSharedReq [2040:207f] D=40cfe14bb15500005b323036383a323036665d20443d63383739333334626231353530303030206e756d3d32363630373300000000016d6973730a0000000000 num=266076
and from this we see that this read request from CPU2 made a cache from CPU1 go from M to O! Cache coherence is being maintained!
Furthermore, it also suggests that now CPU1 is going to supply the response to CPU2 directly from its cache, and the memory request will be suppressed! As mentioned in lecture notes from Cache coherence, we know that this is one of the ways that cache coherence may be maintained in MOESI-like protocols.
After this point, CPU1 continues to go around the loop. After a few instructions we don’t care about, we once again reach the LDR:
471207000: SimpleCPU: system.cpu1: Complete ICache Fetch for addr 0xa88 471207000: Cache: system.cpu1.dcache: access for ReadReq [2068:206f] D=c879334bb1550000 num=266082 hit state: d (O) valid: 1 writable: 0 readable: 1 dirty: 1 | tag: 0 set: 0x81 way: 0 471207000: Event: system.cpu1.dcache.cpu_side-CpuSidePort.wrapped_function_event: EventFunctionWrapped 91 scheduled @ 471208000 471208000: Event: system.cpu1.dcache.cpu_side-CpuSidePort.wrapped_function_event: EventFunctionWrapped 91 executed @ 471208000 471208000: SimpleCPU: system.cpu1.dcache_port: Received load/store response 0x2068 471208000: Event: Event_89: Timing CPU dcache tick 89 scheduled @ 471208000 471208000: Event: Event_89: Timing CPU dcache tick 89 executed @ 471208000 471207000: ExecEnable: system.cpu1: A0 T0 : @my_thread_main+24 : ldr x1, [x2] : MemRead : D=0x000000000000002f A=0x412068 flags=(IsInteger|IsMemRef|IsLoad)
but it is immediately satisfied since the line is already in O, and nothing needs to be sent out to the bus since it’s a read.
Then the add 1 runs entirely from cache of course, and then CPU1 starts its STR:
471210000: Event: Event_87: Timing CPU icache tick 87 executed @ 471210000 471210000: SimpleCPU: system.cpu1: Complete ICache Fetch for addr 0xa90 471210000: Cache: system.cpu1.dcache: access for WriteReq [2068:206f] D=3000000000000000 num=266085 hit state: d (O) valid: 1 writable: 0 readable: 1 dirty: 1 | tag: 0 set: 0x81 way: 0 471210000: CachePort: system.cpu1.dcache.mem_side: Scheduling send event at 471211000 471210000: Event: system.cpu1.dcache.mem_side-MemSidePort.wrapped_function_event: EventFunctionWrapped 93 scheduled @ 471211000
In parallel, the CPU1 snoop response to the CPU2 LDR that had been previously sent reaches the XBar:
471212000: Event: system.cpu1.dcache.mem_side-MemSidePort.wrapped_function_event: EventFunctionWrapped 94 executed @ 471212000 471212000: CoherentXBar: system.membus: recvTimingSnoopResp: src system.membus.slave[6] packet ReadResp [2040:207f] D=700640000000000070064000000000000000000000000000000000000000000000000000000000002f0000000000000000000000000000000000000000000000 num=266078 471212000: SnoopFilter: system.membus.snoop_filter: updateSnoopResponse: rsp system.membus.slave[6] req system.membus.slave[10] packet ReadResp [2040:207f] D=700640000000000070064000000000000000000000000000000000000000000000000000000000002f0000000000000000000000000000000000000000000000 num=266078 471212000: SnoopFilter: system.membus.snoop_filter: updateSnoopResponse: old SF value 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000100000.0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000001000 471212000: SnoopFilter: system.membus.snoop_filter: updateSnoopResponse: new SF value 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000.0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000101000 471212000: CoherentXBar: system.membus: recvTimingSnoopResp: src system.membus.slave[6] packet ReadResp [2040:207f] D=700640000000000070064000000000000000000000000000000000000000000000000000000000002f0000000000000000000000000000000000000000000000 num=266078 FWD RESP 471212000: Event: system.membus.slave[10]-RespPacketQueue.wrapped_function_event: EventFunctionWrapped 186 scheduled @ 471214000 471212000: Event: system.membus.respLayer10.wrapped_function_event: EventFunctionWrapped 187 scheduled @ 471217000 471212000: BaseXBar: system.membus.respLayer10: The crossbar layer is now busy from tick 471212000 to 471217000
We know that it is the same one based on the packet num= match.
And just after that, by coincidence, the CPU1 STR write request also starts going to the XBar:
471212001: Event: system.cpu1.dcache.mem_side-MemSidePort.wrapped_function_event: EventFunctionWrapped 93 executed @ 471212001 471212001: Cache: system.cpu1.dcache: sendMSHRQueuePacket: MSHR WriteReq [2068:206f] D=3000000000000000 num=266085 471212001: Cache: system.cpu1.dcache: createMissPacket: created UpgradeReq [2040:207f] D= num=266086 from WriteReq [2068:206f] D=3000000000000000 num=266085 471212001: CoherentXBar: system.membus: recvTimingReq: src system.membus.slave[6] packet UpgradeReq [2040:207f] D= num=266086 471212001: SnoopFilter: system.membus.snoop_filter: lookupRequest: src system.membus.slave[6] packet UpgradeReq [2040:207f] D= num=266086 471212001: SnoopFilter: system.membus.snoop_filter: lookupRequest: SF value 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000.0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000101000 471212001: SnoopFilter: system.membus.snoop_filter: lookupRequest: new SF value 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000001000.0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000101000 471212001: CoherentXBar: system.membus: recvTimingReq: src system.membus.slave[6] packet UpgradeReq [2040:207f] D= num=266086 SF size: 1 lat: 1 471212001: CoherentXBar: system.membus: forwardTiming for UpgradeReq [2040:207f] D= num=266086 471212001: CacheVerbose: system.cpu2.dcache: recvTimingSnoopReq: for UpgradeReq [2040:207f] D= num=266086 471212001: Cache: global: handleSnoop for UpgradeReq [2040:207f] D= num=266086 471212001: CacheVerbose: system.cpu2.dcache: handleSnoop: for UpgradeReq [2040:207f] D= num=266086 471212001: CacheVerbose: system.cpu2.dcache: handleSnoop: snoop miss for UpgradeReq [2040:207f] D= num=266086
This time, we can see that the WriteReq gets turned into an UpgradeReq by the cache.
It does not however change the CPU2 cacheline state, because the CPU2 cache is not yet valid line because LDR reply still hasn’t come back! We see on the source code:
Cache::handleSnoop(PacketPtr pkt, CacheBlk *blk, bool is_timing,
bool is_deferred, bool pending_inval)
{
} else if (!blk_valid) {
DPRINTF(CacheVerbose, "%s: snoop miss for %s\n", __func__,
pkt->print());
At last, the CPU1 snoop reply reaches the CPU2 dcache with the (now old 2f) data:
471214000: Event: system.membus.reqLayer0.wrapped_function_event: EventFunctionWrapped 164 executed @ 471214000 471214000: Event: system.membus.slave[10]-RespPacketQueue.wrapped_function_event: EventFunctionWrapped 186 executed @ 471214000 471214000: Cache: system.cpu2.dcache: recvTimingResp: Handling response ReadResp [2040:207f] D=700640000000000070064000000000000000000000000000000000000000000000000000000000002f0000000000000000000000000000000000000000000000 num=266078 471214000: Cache: system.cpu2.dcache: Block for addr 0x2040 being updated in Cache 471214000: CacheRepl: system.cpu2.dcache: Replacement victim: state: 0 (I) valid: 0 writable: 0 readable: 0 dirty: 0 | tag: 0xffffffffffffffff set: 0x81 way: 0 471214000: Cache: system.cpu2.dcache: Block addr 0x2040 (ns) moving from state 0 to state: 5 (S) valid: 1 writable: 0 readable: 1 dirty: 0 | tag: 0 set: 0x81 way: 0
On the above, we see that this initially moves the cache to S state.
However, remember that after CPU2 started its LDR, CPU1 did an STR, and that STR was already snooped by CPU2 above? Well, the MSHR or the cache had noted that down, and now it proceeds to invalidate the line:
471214000: Cache: system.cpu2.dcache: serviceMSHRTargets: updated cmd to ReadRespWithInvalidate [2068:206f] D=2f00000000000000 num=266073 471214000: Event: system.cpu2.dcache.cpu_side-CpuSidePort.wrapped_function_event: EventFunctionWrapped 138 scheduled @ 471215000 471214000: Cache: system.cpu2.dcache: processing deferred snoop... 471214000: CacheVerbose: system.cpu2.dcache: handleSnoop: for UpgradeReq [2040:207f] D= num=266087 471214000: Cache: system.cpu2.dcache: handleSnoop: snoop hit for UpgradeReq [2040:207f] D= num=266087, old state is state: 5 (S) valid: 1 writable: 0 readable: 1 dirty: 0 | tag: 0 set: 0x81 way: 0 471214000: Cache: system.cpu2.dcache: new state is state: 0 (I) valid: 0 writable: 0 readable: 0 dirty: 0 | tag: 0xffffffffffffffff set: 0x81 way: 0 471214000: CacheVerbose: system.cpu2.dcache: recvTimingResp: Leaving with ReadResp [2040:207f] D=700640000000000070064000000000000000000000000000000000000000000000000000000000002f0000000000000000000000000000000000000000000000 num=266078
It is a bit funny, but we see that at the same time, both the response arrived with the data, and the cache gets invalidated with a delay. The MSHR kept track of that for us. On the above logs, actually Cache: global: handleSnoop is the line in question.
And at long long last, the CPU2 LDR finishes:
471215000: Event: system.cpu2.dcache.cpu_side-CpuSidePort.wrapped_function_event: EventFunctionWrapped 138 executed @ 471215000 471215000: SimpleCPU: system.cpu2.dcache_port: Received load/store response 0x2068 471215000: Event: Event_136: Timing CPU dcache tick 136 scheduled @ 471215000 471215000: Event: Event_136: Timing CPU dcache tick 136 executed @ 471215000 471202000: ExecEnable: system.cpu2: A0 T0 : @my_thread_main+24 : ldr x1, [x2] : MemRead : D=0x000000000000002f A=0x412068 flags=(IsInteger|IsMemRef|IsLoad)
We note therefore that no DRAM access was involved, one cache services the other directly!
Tested on LKMC 4f82f79be7b0717c12924f4c9b7c4f46f8f18e2f + 1, gem5 3ca404da175a66e0b958165ad75eb5f54cb5e772 with a hack to add packet IDs and data to Packet::print.
24.22.4.6. gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis with caches and multiple CPUs and Ruby
Now let’s do the exact same we did for gem5 event queue AtomicSimpleCPU syscall emulation freestanding example analysis with caches and multiple CPUs, but with Ruby rather than the classic system and TimingSimpleCPU (atomic does not work with Ruby)
Since we have fully understood coherency in that previous example, it should now be easier to understand what is going on with Ruby:
./run \ --arch aarch64 \ --cli-args '2 10' \ --cpus 3 \ --emulator gem5 \ --trace FmtFlag,DRAM,ExecAll,Ruby \ --userland userland/c/atomic.c \ -- \ --cpu-type TimingSimpleCPU \ --ruby \ ;
Note that now the --trace Cache,XBar flags have no effect, since Ruby replaces those classic memory model components entirely with the Ruby version, so we enable the Ruby flag version instead. Note however that this flag is very verbose and produces about 10x more output than the classic memory experiment.
Also remember that ARM’s default Ruby protocol is 'MOESI_CMP_directory'.
First we note that the output of the experiment is the same:
atomic 20 non-atomic 19
TODO
24.22.4.7. gem5 event queue MinorCPU syscall emulation freestanding example analysis
The events for the Atomic CPU were pretty simple: basically just ticks.
But as we venture into more complex CPU models such as MinorCPU, the events get much more complex and interesting.
The memory system system part must be similar to that of TimingSimpleCPU that we previously studied gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis: the main thing we want to see is how the CPU pipeline speeds up execution by preventing some memory stalls.
The config.dot.svg also indicates that: everything is exactly as in gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis with caches, except that the CPU is a MinorCPU instead of TimingSimpleCPU, and the --caches are now mandatory:
./run \ --arch aarch64 \ --emulator gem5 \ --userland userland/arch/aarch64/freestanding/linux/hello.S \ --trace FmtFlag,Cache,Event,ExecAll,Minor \ --trace-stdout \ -- \ --cpu-type MinorCPU \ --caches \ ;
and here’s a handy link to the source: userland/arch/aarch64/freestanding/linux/hello.S.
On LKMC ce3ea9faea95daf46dea80d4236a30a0891c3ca5 gem5 872cb227fdc0b4d60acc7840889d567a6936b6e1 we see the following.
First there is a missed instruction fetch for the initial entry address which we know from gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis with caches is the virtual address 0x400078 which maps to physical 0x78:
500: Cache: system.cpu.icache: access for ReadReq [40:7f] IF miss
The memory request comes back later on at:
77000: Cache: system.cpu.icache: recvTimingResp: Handling response ReadResp [40:7f] IF
and soon after the CPU also ifetches across the barrier:
79000: Cache: system.cpu.icache: access for ReadReq [80:bf] IF miss
TODO why? We have 0x78 and 0x7c, and those should be it since we are dual issue, right? Is this prefetching at work?
Later on we see the first instruction, our MOVZ, was decoded:
80000: MinorExecute: system.cpu.execute: Trying to issue inst: 0/1.1/1/1.1 pc: 0x400078 (movz) to FU: 0
and that issue succeeds, because the functional unit 0 (FU 0) is an IntAlu as shown at gem5 functional units:
80000: MinorExecute: system.cpu.execute: Issuing inst: 0/1.1/1/1.1 pc: 0x400078 (movz) into FU 0
At the very same tick, the second instruction is also decoded, our ADR:
80000: MinorExecute: system.cpu.execute: Trying to issue inst: 0/1.1/1/2.2 pc: 0x40007c (adr) to FU: 0 80000: MinorExecute: system.cpu.execute: Can't issue as FU: 0 is already busy 80000: MinorExecute: system.cpu.execute: Trying to issue inst: 0/1.1/1/2.2 pc: 0x40007c (adr) to FU: 1 80000: MinorExecute: system.cpu.execute: Issuing inst: 0/1.1/1/2.2 pc: 0x40007c (adr) into FU 1
This is also an IntAlu instruction, and it can’t run on FU 0 because the first instruction is already running there. But to our luck, FU 1 is also an IntAlu unit, and so it runs there.
Crap, those Minor logs should say what OpClass each instruction is, that would make things clearer.
TODO what is that 0/1.1/1/1.1 notation that shows up everywhere? Must be important, let’s look at the source.
Soon after (3 ticks later, so guessing due to opLat=3?), the execution appears to be over already since we see the ExecAll come through, which generally happens at the very end:
81500: MinorExecute: system.cpu.execute: Attempting to commit [tid:0] 81500: MinorExecute: system.cpu.execute: Committing micro-ops for interrupt[tid:0] 81500: MinorExecute: system.cpu.execute: Trying to commit canCommitInsts: 1 81500: MinorExecute: system.cpu.execute: Trying to commit from FUs 81500: MinorExecute: global: ExecContext setting PC: (0x400078=>0x40007c).(0=>1) 81500: MinorExecute: system.cpu.execute: Committing inst: 0/1.1/1/1.1 pc: 0x400078 (movz) 81500: MinorExecute: system.cpu.execute: Unstalling 0 for inst 0/1.1/1/1.1 81500: MinorExecute: system.cpu.execute: Completed inst: 0/1.1/1/1.1 pc: 0x400078 (movz) 81500: MinorScoreboard: system.cpu.execute.scoreboard0: Clearing inst: 0/1.1/1/1.1 pc: 0x400078 (movz) regIndex: 0 final numResults: 0 81500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue : movz x0, #1, #0 : IntAlu : D=0x0000000000000001 FetchSeq=1 CPSeq=1 flags=(IsInteger) 81500: MinorExecute: system.cpu.execute: Trying to commit canCommitInsts: 1 81500: MinorExecute: system.cpu.execute: Trying to commit from FUs 81500: MinorExecute: global: ExecContext setting PC: (0x40007c=>0x400080).(0=>1) 81500: MinorExecute: system.cpu.execute: Committing inst: 0/1.1/1/2.2 pc: 0x40007c (adr) 81500: MinorExecute: system.cpu.execute: Unstalling 1 for inst 0/1.1/1/2.2 81500: MinorExecute: system.cpu.execute: Completed inst: 0/1.1/1/2.2 pc: 0x40007c (adr) 81500: MinorScoreboard: system.cpu.execute.scoreboard0: Clearing inst: 0/1.1/1/2.2 pc: 0x40007c (adr) regIndex: 1 final numResults: 0 81500: MinorExecute: system.cpu.execute: Reached inst commit limit 81500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+4 : adr x1, #28 : IntAlu : D=0x0000000000400098 FetchSeq=2 CPSeq=2 flags=(IsInteger)
The ifetch for the third instruction returns at:
129000: Cache: system.cpu.icache: recvTimingResp: Handling response ReadResp [80:bf] IF
so now we are ready to run the third and fourth instructions of the program:
ldr x2, =len
mov x8, 64
The LDR goes all the way down to FU 6 which is the memory one:
132000: MinorExecute: system.cpu.execute: Trying to issue inst: 0/1.1/2/3.3 pc: 0x400080 (ldr) to FU: 0 132000: MinorExecute: system.cpu.execute: Can't issue as FU: 0 isn't capable 132000: MinorExecute: system.cpu.execute: Trying to issue inst: 0/1.1/2/3.3 pc: 0x400080 (ldr) to FU: 1 132000: MinorExecute: system.cpu.execute: Can't issue as FU: 1 isn't capable 132000: MinorExecute: system.cpu.execute: Trying to issue inst: 0/1.1/2/3.3 pc: 0x400080 (ldr) to FU: 2 132000: MinorExecute: system.cpu.execute: Can't issue as FU: 2 isn't capable 132000: MinorExecute: system.cpu.execute: Trying to issue inst: 0/1.1/2/3.3 pc: 0x400080 (ldr) to FU: 3 132000: MinorExecute: system.cpu.execute: Can't issue as FU: 3 isn't capable 132000: MinorExecute: system.cpu.execute: Trying to issue inst: 0/1.1/2/3.3 pc: 0x400080 (ldr) to FU: 4 132000: MinorExecute: system.cpu.execute: Can't issue as FU: 4 isn't capable 132000: MinorExecute: system.cpu.execute: Trying to issue inst: 0/1.1/2/3.3 pc: 0x400080 (ldr) to FU: 5 132000: MinorExecute: system.cpu.execute: Can't issue as FU: 5 isn't capable 132000: MinorExecute: system.cpu.execute: Trying to issue inst: 0/1.1/2/3.3 pc: 0x400080 (ldr) to FU: 6 132000: MinorExecute: system.cpu.execute: Issuing inst: 0/1.1/2/3.3 pc: 0x400080 (ldr) into FU 6
and then the MOV issue follows soon afterwards (TODO why not at the same time like for the previous pair?):
132500: MinorExecute: system.cpu.execute: Trying to issue inst: 0/1.1/2/4.4 pc: 0x400084 (movz) to FU: 0 132500: MinorExecute: system.cpu.execute: Issuing inst: 0/1.1/2/4.4 pc: 0x400084 (movz) into FU 0
24.22.4.8. gem5 event queue DerivO3CPU syscall emulation freestanding example analysis
Like gem5 event queue MinorCPU syscall emulation freestanding example analysis but even more complex since for the gem5 DerivO3CPU!
The key new debug flag is O3CPUAll:
./run \ --arch aarch64 \ --emulator gem5 \ --userland userland/arch/aarch64/freestanding/linux/hello.S \ --trace FmtFlag,Cache,Event,ExecAll,O3CPUAll \ --trace-stdout \ -- \ --cpu-type DerivO3CPU \ --caches \ ;
The output is huge and contains about 7 thousand lines!!!
This section and children are tested at LKMC 144a552cf926ea630ef9eadbb22b79fe2468c456.
24.22.4.8.1. gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: hazardless
Let’s have a look at the arguably simplest example userland/arch/aarch64/freestanding/linux/hazardless.S.
First let’s start with a gem5 util/o3-pipeview.py O3 pipeline viewer visualization:
// f = fetch, d = decode, n = rename, p = dispatch, i = issue, c = complete, r = retire
timeline tick pc.upc disasm seq_num
[.ic.r........................................................................fdn]-( 40000) 0x00400078.0 movz x0, #0, #0 [ 1]
[.ic.r........................................................................fdn]-( 40000) 0x0040007c.0 movz x1, #1, #0 [ 2]
[....................fdn.ic.r....................................................]-( 120000) 0x00400080.0 movz x2, #2, #0 [ 3]
[....................fdn.ic.r....................................................]-( 120000) 0x00400084.0 movz x3, #3, #0 [ 4]
[....................fdn.ic.r....................................................]-( 120000) 0x00400088.0 movz x4, #4, #0 [ 5]
[....................fdn.ic.r....................................................]-( 120000) 0x0040008c.0 movz x5, #5, #0 [ 6]
[....................fdn.ic.r....................................................]-( 120000) 0x00400090.0 movz x6, #6, #0 [ 7]
[....................fdn.ic.r....................................................]-( 120000) 0x00400094.0 movz x7, #7, #0 [ 8]
[....................fdn.pic.r...................................................]-( 120000) 0x00400098.0 movz x8, #8, #0 [ 9]
[....................fdn.pic.r...................................................]-( 120000) 0x0040009c.0 movz x9, #9, #0 [ 10]
[.....................fdn.ic.r...................................................]-( 120000) 0x004000a0.0 movz x10, #10, #0 [ 11]
[.....................fdn.ic.r...................................................]-( 120000) 0x004000a4.0 movz x11, #11, #0 [ 12]
[.....................fdn.ic.r...................................................]-( 120000) 0x004000a8.0 movz x12, #12, #0 [ 13]
[.....................fdn.ic.r...................................................]-( 120000) 0x004000ac.0 movz x13, #13, #0 [ 14]
[.....................fdn.pic.r..................................................]-( 120000) 0x004000b0.0 movz x14, #14, #0 [ 15]
[.....................fdn.pic.r..................................................]-( 120000) 0x004000b4.0 movz x15, #15, #0 [ 16]
[.....................fdn.pic.r..................................................]-( 120000) 0x004000b8.0 movz x16, #16, #0 [ 17]
[.....................fdn.pic.r..................................................]-( 120000) 0x004000bc.0 movz x17, #17, #0 [ 18]
[............................................fdn.ic.r............................]-( 160000) 0x004000c0.0 movz x18, #18, #0 [ 19]
[............................................fdn.ic.r............................]-( 160000) 0x004000c4.0 movz x19, #19, #0 [ 20]
[............................................fdn.ic.r............................]-( 160000) 0x004000c8.0 movz x20, #20, #0 [ 21]
[............................................fdn.ic.r............................]-( 160000) 0x004000cc.0 movz x21, #21, #0 [ 22]
[............................................fdn.ic.r............................]-( 160000) 0x004000d0.0 movz x22, #22, #0 [ 23]
[............................................fdn.ic.r............................]-( 160000) 0x004000d4.0 movz x23, #23, #0 [ 24]
[............................................fdn.pic.r...........................]-( 160000) 0x004000d8.0 movz x24, #24, #0 [ 25]
[............................................fdn.pic.r...........................]-( 160000) 0x004000dc.0 movz x25, #25, #0 [ 26]
[.............................................fdn.ic.r...........................]-( 160000) 0x004000e0.0 movz x26, #26, #0 [ 27]
[.............................................fdn.ic.r...........................]-( 160000) 0x004000e4.0 movz x27, #27, #0 [ 28]
[.............................................fdn.ic.r...........................]-( 160000) 0x004000e8.0 movz x28, #28, #0 [ 29]
[.............................................fdn.ic.r...........................]-( 160000) 0x004000ec.0 movz x29, #29, #0 [ 30]
[.............................................fdn.pic.r..........................]-( 160000) 0x004000f0.0 movz x0, #0, #0 [ 31]
[.............................................fdn.pic.r..........................]-( 160000) 0x004000f4.0 movz x1, #1, #0 [ 32]
[.............................................fdn.pic.r..........................]-( 160000) 0x004000f8.0 movz x2, #2, #0 [ 33]
[.............................................fdn.pic.r..........................]-( 160000) 0x004000fc.0 movz x3, #3, #0 [ 34]
The first of instructions has only two instructions because the first instruction is at address 0x400078, so only two instructions fit on that cache line, as the next cache line starts at 0x400080!
The initial fdn on top middle is likely bugged out, did it wrap around? But the rest makes sense.
From this, we clearly see that up to 8 instructions can be issued concurrently, which matches the default width values we had seen at gem5 DerivO3CPU.
For example, we can clearly see how:
-
movz x2through tomovz x9start running at the exact same time. TODO why doesmov x7dofdn.ic.rwhilemov x8dofdn.ic.r? How are they different? -
movz x10throughmovz x17then starts running one step later. This second chunk is fully pipelined with the first instruction pack -
then comes a pause while the next fetch comes back. This group of 16 instructions took up the entire 64-byte cacheline that had been read
First we can have a look at ExecEnable to get an initial ideal of how many instructions are run at one time:
78500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue : movz x0, #0, #0 : IntAlu : D=0x0000000000000000 FetchSeq=1 CPSeq=1 flags=(IsInteger) 78500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+4 : movz x1, #1, #0 : IntAlu : D=0x0000000000000001 FetchSeq=2 CPSeq=2 flags=(IsInteger) 130000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+8 : movz x2, #2, #0 : IntAlu : D=0x0000000000000002 FetchSeq=3 CPSeq=3 flags=(IsInteger) 130000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+12 : movz x3, #3, #0 : IntAlu : D=0x0000000000000003 FetchSeq=4 CPSeq=4 flags=(IsInteger) 130000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+16 : movz x4, #4, #0 : IntAlu : D=0x0000000000000004 FetchSeq=5 CPSeq=5 flags=(IsInteger) 130000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+20 : movz x5, #5, #0 : IntAlu : D=0x0000000000000005 FetchSeq=6 CPSeq=6 flags=(IsInteger) 130000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+24 : movz x6, #6, #0 : IntAlu : D=0x0000000000000006 FetchSeq=7 CPSeq=7 flags=(IsInteger) 130000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+28 : movz x7, #7, #0 : IntAlu : D=0x0000000000000007 FetchSeq=8 CPSeq=8 flags=(IsInteger) 130000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+32 : movz x8, #8, #0 : IntAlu : D=0x0000000000000008 FetchSeq=9 CPSeq=9 flags=(IsInteger) 130000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+36 : movz x9, #9, #0 : IntAlu : D=0x0000000000000009 FetchSeq=10 CPSeq=10 flags=(IsInteger) 130500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+40 : movz x10, #10, #0 : IntAlu : D=0x000000000000000a FetchSeq=11 CPSeq=11 flags=(IsInteger) 130500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+44 : movz x11, #11, #0 : IntAlu : D=0x000000000000000b FetchSeq=12 CPSeq=12 flags=(IsInteger) 130500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+48 : movz x12, #12, #0 : IntAlu : D=0x000000000000000c FetchSeq=13 CPSeq=13 flags=(IsInteger) 130500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+52 : movz x13, #13, #0 : IntAlu : D=0x000000000000000d FetchSeq=14 CPSeq=14 flags=(IsInteger) 130500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+56 : movz x14, #14, #0 : IntAlu : D=0x000000000000000e FetchSeq=15 CPSeq=15 flags=(IsInteger) 130500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+60 : movz x15, #15, #0 : IntAlu : D=0x000000000000000f FetchSeq=16 CPSeq=16 flags=(IsInteger) 130500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+64 : movz x16, #16, #0 : IntAlu : D=0x0000000000000010 FetchSeq=17 CPSeq=17 flags=(IsInteger) 130500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+68 : movz x17, #17, #0 : IntAlu : D=0x0000000000000011 FetchSeq=18 CPSeq=18 flags=(IsInteger)
This suggests 8, but remember that ExecEnable shows issue time labels, which do not coincide necessarily with commit times. As we saw in the pipeline viewer above, instructions 9 and 10 have one extra stage.
After the initial two execs from the first cache line, the full commit log chunk around the first group of six `ExecEnable`s looks like:
133500: Commit: system.cpu.commit: Getting instructions from Rename stage. 133500: Commit: system.cpu.commit: Trying to commit instructions in the ROB. 133500: Commit: system.cpu.commit: Trying to commit head instruction, [tid:0] [sn:3] 133500: Commit: system.cpu.commit: [tid:0] [sn:3] Committing instruction with PC (0x400080=>0x400084).(0=>1) 130000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+8 : movz x2, #2, #0 : IntAlu : D=0x0000000000000002 FetchSeq=3 CPSeq=3 flags=(IsInteger) 133500: ROB: system.cpu.rob: [tid:0] Retiring head instruction, instruction PC (0x400080=>0x400084).(0=>1), [sn:3] 133500: O3CPU: system.cpu: Removing committed instruction [tid:0] PC (0x400080=>0x400084).(0=>1) [sn:3] 133500: Commit: system.cpu.commit: Trying to commit head instruction, [tid:0] [sn:4] 133500: Commit: system.cpu.commit: [tid:0] [sn:4] Committing instruction with PC (0x400084=>0x400088).(0=>1) 130000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+12 : movz x3, #3, #0 : IntAlu : D=0x0000000000000003 FetchSeq=4 CPSeq=4 flags=(IsInteger) 133500: ROB: system.cpu.rob: [tid:0] Retiring head instruction, instruction PC (0x400084=>0x400088).(0=>1), [sn:4] 133500: O3CPU: system.cpu: Removing committed instruction [tid:0] PC (0x400084=>0x400088).(0=>1) [sn:4] 133500: Commit: system.cpu.commit: Trying to commit head instruction, [tid:0] [sn:5] 133500: Commit: system.cpu.commit: [tid:0] [sn:5] Committing instruction with PC (0x400088=>0x40008c).(0=>1) 130000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+16 : movz x4, #4, #0 : IntAlu : D=0x0000000000000004 FetchSeq=5 CPSeq=5 flags=(IsInteger) 133500: ROB: system.cpu.rob: [tid:0] Retiring head instruction, instruction PC (0x400088=>0x40008c).(0=>1), [sn:5] 133500: O3CPU: system.cpu: Removing committed instruction [tid:0] PC (0x400088=>0x40008c).(0=>1) [sn:5] 133500: Commit: system.cpu.commit: Trying to commit head instruction, [tid:0] [sn:6] 133500: Commit: system.cpu.commit: [tid:0] [sn:6] Committing instruction with PC (0x40008c=>0x400090).(0=>1) 130000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+20 : movz x5, #5, #0 : IntAlu : D=0x0000000000000005 FetchSeq=6 CPSeq=6 flags=(IsInteger) 133500: ROB: system.cpu.rob: [tid:0] Retiring head instruction, instruction PC (0x40008c=>0x400090).(0=>1), [sn:6] 133500: O3CPU: system.cpu: Removing committed instruction [tid:0] PC (0x40008c=>0x400090).(0=>1) [sn:6] 133500: Commit: system.cpu.commit: Trying to commit head instruction, [tid:0] [sn:7] 133500: Commit: system.cpu.commit: [tid:0] [sn:7] Committing instruction with PC (0x400090=>0x400094).(0=>1) 130000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+24 : movz x6, #6, #0 : IntAlu : D=0x0000000000000006 FetchSeq=7 CPSeq=7 flags=(IsInteger) 133500: ROB: system.cpu.rob: [tid:0] Retiring head instruction, instruction PC (0x400090=>0x400094).(0=>1), [sn:7] 133500: O3CPU: system.cpu: Removing committed instruction [tid:0] PC (0x400090=>0x400094).(0=>1) [sn:7] 133500: Commit: system.cpu.commit: Trying to commit head instruction, [tid:0] [sn:8] 133500: Commit: system.cpu.commit: [tid:0] [sn:8] Committing instruction with PC (0x400094=>0x400098).(0=>1) 130000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+28 : movz x7, #7, #0 : IntAlu : D=0x0000000000000007 FetchSeq=8 CPSeq=8 flags=(IsInteger) 133500: ROB: system.cpu.rob: [tid:0] Retiring head instruction, instruction PC (0x400094=>0x400098).(0=>1), [sn:8] 133500: O3CPU: system.cpu: Removing committed instruction [tid:0] PC (0x400094=>0x400098).(0=>1) [sn:8] 133500: Commit: system.cpu.commit: [tid:0] Marking PC (0x400098=>0x40009c).(0=>1), [sn:9] ready within ROB. 133500: Commit: system.cpu.commit: [tid:0] Marking PC (0x40009c=>0x4000a0).(0=>1), [sn:10] ready within ROB. 133500: Commit: system.cpu.commit: [tid:0] Marking PC (0x4000a0=>0x4000a4).(0=>1), [sn:11] ready within ROB. 133500: Commit: system.cpu.commit: [tid:0] Marking PC (0x4000a4=>0x4000a8).(0=>1), [sn:12] ready within ROB. 133500: Commit: system.cpu.commit: [tid:0] Marking PC (0x4000a8=>0x4000ac).(0=>1), [sn:13] ready within ROB. 133500: Commit: system.cpu.commit: [tid:0] Marking PC (0x4000ac=>0x4000b0).(0=>1), [sn:14] ready within ROB. 133500: Commit: system.cpu.commit: [tid:0] Instruction [sn:9] PC (0x400098=>0x40009c).(0=>1) is head of ROB and ready to commit 133500: Commit: system.cpu.commit: [tid:0] ROB has 10 insts & 182 free entries.
ROB stands for Re-order buffer.
0x400080⇒0x400084 is an old/new PC address of the first committed instruction.
Another thing we can do, it to try to follow one of the instructions back as it goes through the pipeline. Searching for example for the address 0x400080, we find:
The first mention of the address happens when is the fetch of the two initial instructions completes. TODO not sure why it doesn’t just also fetch the next cache line at the same time:
FullO3CPU: Ticking main, FullO3CPU. 78500: Fetch: system.cpu.fetch: Running stage. 78500: Fetch: system.cpu.fetch: Attempting to fetch from [tid:0] 78500: Fetch: system.cpu.fetch: [tid:0] Icache miss is complete. 78500: Fetch: system.cpu.fetch: [tid:0] Adding instructions to queue to decode. 78500: DynInst: global: DynInst: [sn:1] Instruction created. Instcount for system.cpu = 1 78500: Fetch: system.cpu.fetch: [tid:0] Instruction PC 0x400078 (0) created [sn:1]. 78500: Fetch: system.cpu.fetch: [tid:0] Instruction is: movz x0, #0, #0 78500: Fetch: system.cpu.fetch: [tid:0] Fetch queue entry created (1/32). 78500: DynInst: global: DynInst: [sn:2] Instruction created. Instcount for system.cpu = 2 78500: Fetch: system.cpu.fetch: [tid:0] Instruction PC 0x40007c (0) created [sn:2]. 78500: Fetch: system.cpu.fetch: [tid:0] Instruction is: movz x1, #1, #0 78500: Fetch: system.cpu.fetch: [tid:0] Fetch queue entry created (2/32). 78500: Fetch: system.cpu.fetch: [tid:0] Issuing a pipelined I-cache access, starting at PC (0x400080=>0x400084).(0=>1). 78500: Fetch: system.cpu.fetch: [tid:0] Fetching cache line 0x400080 for addr 0x400080
so we observe that the first two instructions arrived, and the CPU noticed that 0x400080 hasn’t been fetched yet.
Then for several cycles that follow, the fetch stage just says that it is blocked on data returning:
FullO3CPU: Ticking main, FullO3CPU. 79000: Fetch: system.cpu.fetch: Running stage. 79000: Fetch: system.cpu.fetch: There are no more threads available to fetch from. 79000: Fetch: system.cpu.fetch: [tid:0] Fetch is waiting cache response!
At the same time, the execution of the initial 2 instructions progresses through the pipeline.
These progress up until:
88000: O3CPU: system.cpu: Idle!
at which point there are no more events scheduled besides waiting for the second cache line to come back.
After this, some time passes without events, and the next tick happens when the fetch data returns:
FullO3CPU: Ticking main, FullO3CPU. 130000: Fetch: system.cpu.fetch: Running stage. 130000: Fetch: system.cpu.fetch: Attempting to fetch from [tid:0] 130000: Fetch: system.cpu.fetch: [tid:0] Icache miss is complete. 130000: Fetch: system.cpu.fetch: [tid:0] Adding instructions to queue to decode. 130000: DynInst: global: DynInst: [sn:3] Instruction created. Instcount for system.cpu = 1 130000: Fetch: system.cpu.fetch: [tid:0] Instruction PC 0x400080 (0) created [sn:3]. 130000: Fetch: system.cpu.fetch: [tid:0] Instruction is: movz x2, #2, #0 130000: Fetch: system.cpu.fetch: [tid:0] Fetch queue entry created (1/32). 130000: DynInst: global: DynInst: [sn:4] Instruction created. Instcount for system.cpu = 2 130000: Fetch: system.cpu.fetch: [tid:0] Instruction PC 0x400084 (0) created [sn:4]. 130000: Fetch: system.cpu.fetch: [tid:0] Instruction is: movz x3, #3, #0 130000: Fetch: system.cpu.fetch: [tid:0] Fetch queue entry created (2/32). 130000: DynInst: global: DynInst: [sn:5] Instruction created. Instcount for system.cpu = 3
24.22.4.8.2. gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: hazard
Now let’s do the same as in gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: hazardless but with a hazard: userland/arch/aarch64/freestanding/linux/hazard.S.
// f = fetch, d = decode, n = rename, p = dispatch, i = issue, c = complete, r = retire
timeline tick pc.upc disasm seq_num
[.ic.r........................................................................fdn]-( 40000) 0x00400078.0 movz x0, #0, #0 [ 1]
[.ic.r........................................................................fdn]-( 40000) 0x0040007c.0 movz x1, #1, #0 [ 2]
[....................fdn.ic.r....................................................]-( 120000) 0x00400080.0 movz x2, #2, #0 [ 3]
[....................fdn.pic.r...................................................]-( 120000) 0x00400084.0 add x3, x2, #1 [ 4]
[....................fdn.ic..r...................................................]-( 120000) 0x00400088.0 movz x4, #4, #0 [ 5]
[....................fdn.ic..r...................................................]-( 120000) 0x0040008c.0 movz x5, #5, #0 [ 6]
[....................fdn.ic..r...................................................]-( 120000) 0x00400090.0 movz x6, #6, #0 [ 7]
[....................fdn.ic..r...................................................]-( 120000) 0x00400094.0 movz x7, #7, #0 [ 8]
[....................fdn.ic..r...................................................]-( 120000) 0x00400098.0 movz x8, #8, #0 [ 9]
[....................fdn.pic.r...................................................]-( 120000) 0x0040009c.0 movz x9, #9, #0 [ 10]
[.....................fdn.ic.r...................................................]-( 120000) 0x004000a0.0 movz x10, #10, #0 [ 11]
[.....................fdn.ic..r..................................................]-( 120000) 0x004000a4.0 movz x11, #11, #0 [ 12]
[.....................fdn.ic..r..................................................]-( 120000) 0x004000a8.0 movz x12, #12, #0 [ 13]
[.....................fdn.ic..r..................................................]-( 120000) 0x004000ac.0 movz x13, #13, #0 [ 14]
[.....................fdn.pic.r..................................................]-( 120000) 0x004000b0.0 movz x14, #14, #0 [ 15]
[.....................fdn.pic.r..................................................]-( 120000) 0x004000b4.0 movz x15, #15, #0 [ 16]
[.....................fdn.pic.r..................................................]-( 120000) 0x004000b8.0 movz x16, #16, #0 [ 17]
[.....................fdn.pic.r..................................................]-( 120000) 0x004000bc.0 movz x17, #17, #0 [ 18]
[............................................fdn.ic.r............................]-( 160000) 0x004000c0.0 movz x18, #18, #0 [ 19]
[............................................fdn.ic.r............................]-( 160000) 0x004000c4.0 movz x19, #19, #0 [ 20]
[............................................fdn.ic.r............................]-( 160000) 0x004000c8.0 movz x20, #20, #0 [ 21]
[............................................fdn.ic.r............................]-( 160000) 0x004000cc.0 movz x21, #21, #0 [ 22]
[............................................fdn.ic.r............................]-( 160000) 0x004000d0.0 movz x22, #22, #0 [ 23]
[............................................fdn.ic.r............................]-( 160000) 0x004000d4.0 movz x23, #23, #0 [ 24]
[............................................fdn.pic.r...........................]-( 160000) 0x004000d8.0 movz x24, #24, #0 [ 25]
[............................................fdn.pic.r...........................]-( 160000) 0x004000dc.0 movz x25, #25, #0 [ 26]
[.............................................fdn.ic.r...........................]-( 160000) 0x004000e0.0 movz x0, #0, #0 [ 27]
[.............................................fdn.ic.r...........................]-( 160000) 0x004000e4.0 movz x8, #93, #0 [ 28]
TODO understand how the hazard happens in detail.
24.22.4.8.3. gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: hazard4
Like gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: hazard but a hazard of depth 4: userland/arch/aarch64/freestanding/linux/hazard.S.
// f = fetch, d = decode, n = rename, p = dispatch, i = issue, c = complete, r = retire
timeline tick pc.upc disasm seq_num
[.ic.r........................................................................fdn]-( 40000) 0x00400078.0 movz x0, #0, #0 [ 1]
[.ic.r........................................................................fdn]-( 40000) 0x0040007c.0 movz x1, #1, #0 [ 2]
[....................fdn.ic.r....................................................]-( 120000) 0x00400080.0 movz x2, #2, #0 [ 3]
[....................fdn.pic.r...................................................]-( 120000) 0x00400084.0 add x3, x2, #1 [ 4]
[....................fdn.p.ic.r..................................................]-( 120000) 0x00400088.0 add x4, x3, #1 [ 5]
[....................fdn.p..ic.r.................................................]-( 120000) 0x0040008c.0 add x5, x4, #1 [ 6]
[....................fdn.p...ic.r................................................]-( 120000) 0x00400090.0 add x6, x5, #1 [ 7]
[....................fdn.ic.....r................................................]-( 120000) 0x00400094.0 movz x7, #7, #0 [ 8]
[....................fdn.ic.....r................................................]-( 120000) 0x00400098.0 movz x8, #8, #0 [ 9]
[....................fdn.ic.....r................................................]-( 120000) 0x0040009c.0 movz x9, #9, #0 [ 10]
[.....................fdn.ic....r................................................]-( 120000) 0x004000a0.0 movz x10, #10, #0 [ 11]
[.....................fdn.ic....r................................................]-( 120000) 0x004000a4.0 movz x11, #11, #0 [ 12]
[.....................fdn.ic....r................................................]-( 120000) 0x004000a8.0 movz x12, #12, #0 [ 13]
[.....................fdn.ic....r................................................]-( 120000) 0x004000ac.0 movz x13, #13, #0 [ 14]
[.....................fdn.ic.....r...............................................]-( 120000) 0x004000b0.0 movz x14, #14, #0 [ 15]
[.....................fdn.pic....r...............................................]-( 120000) 0x004000b4.0 movz x15, #15, #0 [ 16]
[.....................fdn.pic....r...............................................]-( 120000) 0x004000b8.0 movz x16, #16, #0 [ 17]
[.....................fdn.pic....r...............................................]-( 120000) 0x004000bc.0 movz x17, #17, #0 [ 18]
[............................................fdn.ic.r............................]-( 160000) 0x004000c0.0 movz x18, #18, #0 [ 19]
[............................................fdn.ic.r............................]-( 160000) 0x004000c4.0 movz x19, #19, #0 [ 20]
[............................................fdn.ic.r............................]-( 160000) 0x004000c8.0 movz x20, #20, #0 [ 21]
[............................................fdn.ic.r............................]-( 160000) 0x004000cc.0 movz x21, #21, #0 [ 22]
[............................................fdn.ic.r............................]-( 160000) 0x004000d0.0 movz x22, #22, #0 [ 23]
[............................................fdn.ic.r............................]-( 160000) 0x004000d4.0 movz x23, #23, #0 [ 24]
[............................................fdn.pic.r...........................]-( 160000) 0x004000d8.0 movz x24, #24, #0 [ 25]
[............................................fdn.pic.r...........................]-( 160000) 0x004000dc.0 movz x25, #25, #0 [ 26]
[.............................................fdn.ic.r...........................]-( 160000) 0x004000e0.0 movz x0, #0, #0 [ 27]
[.............................................fdn.ic.r...........................]-( 160000) 0x004000e4.0 movz x8, #93, #0 [ 28]
24.22.4.8.4. gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: stall
Like gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: hazard but now with an LDR stall: userland/arch/aarch64/freestanding/linux/stall.S.
We can see here that:
-
the addition of a data section entry changed our previous address setup a bit, the entry point was now 0x004000b0 which fits 4 instructions in the cacheline instead of 2
-
the LDR happens to be the fourth instruction, so it takes a long time to retire. The time is about 40k ticks, which is about the same time it takes for the instruction fetch as expected.
-
fetch does not continue past the LDR, and so nothing is gained in this particular example, since the next instructions haven’t been fetched from memory yet!
// f = fetch, d = decode, n = rename, p = dispatch, i = issue, c = complete, r = retire
timeline tick pc.upc disasm seq_num
[.ic.r........................................................................fdn]-( 40000) 0x004000b0.0 movz x0, #0, #0 [ 1]
[.ic.r........................................................................fdn]-( 40000) 0x004000b4.0 movz x1, #1, #0 [ 2]
[.ic.r........................................................................fdn]-( 40000) 0x004000b8.0 adr x2, #65780 [ 3]
[.............................................................................fdn]-( 40000) 0x004000bc.0 ldr x3, [x2] [ 4]
[.pic............................................................................]-( 80000) ...
[................................r...............................................]-( 120000) ...
[....................fdn.ic......r...............................................]-( 120000) 0x004000c0.0 movz x4, #4, #0 [ 5]
[....................fdn.ic......r...............................................]-( 120000) 0x004000c4.0 movz x5, #5, #0 [ 6]
[....................fdn.ic......r...............................................]-( 120000) 0x004000c8.0 movz x6, #6, #0 [ 7]
[....................fdn.ic......r...............................................]-( 120000) 0x004000cc.0 movz x7, #7, #0 [ 8]
[....................fdn.ic......r...............................................]-( 120000) 0x004000d0.0 movz x8, #8, #0 [ 9]
[....................fdn.ic......r...............................................]-( 120000) 0x004000d4.0 movz x9, #9, #0 [ 10]
[....................fdn.pic.....r...............................................]-( 120000) 0x004000d8.0 movz x10, #10, #0 [ 11]
[....................fdn.pic......r..............................................]-( 120000) 0x004000dc.0 movz x11, #11, #0 [ 12]
[.....................fdn.ic......r..............................................]-( 120000) 0x004000e0.0 movz x12, #12, #0 [ 13]
[.....................fdn.ic......r..............................................]-( 120000) 0x004000e4.0 movz x13, #13, #0 [ 14]
[.....................fdn.ic......r..............................................]-( 120000) 0x004000e8.0 movz x14, #14, #0 [ 15]
[.....................fdn.ic......r..............................................]-( 120000) 0x004000ec.0 movz x15, #15, #0 [ 16]
[.....................fdn.pic.....r..............................................]-( 120000) 0x004000f0.0 movz x16, #16, #0 [ 17]
[.....................fdn.pic.....r..............................................]-( 120000) 0x004000f4.0 movz x17, #17, #0 [ 18]
[.....................fdn.pic.....r..............................................]-( 120000) 0x004000f8.0 movz x18, #18, #0 [ 19]
[.....................fdn.pic......r.............................................]-( 120000) 0x004000fc.0 movz x19, #19, #0 [ 20]
24.22.4.8.5. gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: stall_gain
Like gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: stall but now with an LDR stall: userland/arch/aarch64/freestanding/linux/stall_gain.S.
So in this case we see that there were actual potential gains, since the movz x11 started running immediately. We just stopped at movz x20 because a new ifetch was needed.
// f = fetch, d = decode, n = rename, p = dispatch, i = issue, c = complete, r = retire
timeline tick pc.upc disasm seq_num
[.ic.r........................................................................fdn]-( 40000) 0x004000b0.0 movz x0, #0, #0 [ 1]
[.ic.r........................................................................fdn]-( 40000) 0x004000b4.0 movz x1, #1, #0 [ 2]
[.ic.r........................................................................fdn]-( 40000) 0x004000b8.0 movz x2, #4, #0 [ 3]
[.ic.r........................................................................fdn]-( 40000) 0x004000bc.0 movz x3, #5, #0 [ 4]
[....................fdn.ic.r....................................................]-( 120000) 0x004000c0.0 adr x4, #65772 [ 5]
[....................fdn.pic.....................................................]-( 120000) 0x004000c4.0 ldr x5, [x4] [ 6]
[........................................................r.......................]-( 160000) ...
[....................fdn.ic......................................................]-( 120000) 0x004000c8.0 movz x6, #6, #0 [ 7]
[........................................................r.......................]-( 160000) ...
[....................fdn.ic......................................................]-( 120000) 0x004000cc.0 movz x7, #7, #0 [ 8]
[........................................................r.......................]-( 160000) ...
[....................fdn.ic......................................................]-( 120000) 0x004000d0.0 movz x8, #8, #0 [ 9]
[........................................................r.......................]-( 160000) ...
[....................fdn.ic......................................................]-( 120000) 0x004000d4.0 movz x9, #9, #0 [ 10]
[........................................................r.......................]-( 160000) ...
[....................fdn.ic......................................................]-( 120000) 0x004000d8.0 movz x10, #10, #0 [ 11]
[........................................................r.......................]-( 160000) ...
[....................fdn.pic.....................................................]-( 120000) 0x004000dc.0 movz x11, #11, #0 [ 12]
[........................................................r.......................]-( 160000) ...
[.....................fdn.ic.....................................................]-( 120000) 0x004000e0.0 movz x12, #12, #0 [ 13]
[........................................................r.......................]-( 160000) ...
[.....................fdn.ic.....................................................]-( 120000) 0x004000e4.0 movz x13, #13, #0 [ 14]
[.........................................................r......................]-( 160000) ...
[.....................fdn.ic.....................................................]-( 120000) 0x004000e8.0 movz x14, #14, #0 [ 15]
[.........................................................r......................]-( 160000) ...
[.....................fdn.ic.....................................................]-( 120000) 0x004000ec.0 movz x15, #15, #0 [ 16]
[.........................................................r......................]-( 160000) ...
[.....................fdn.ic.....................................................]-( 120000) 0x004000f0.0 movz x16, #16, #0 [ 17]
[.........................................................r......................]-( 160000) ...
[.....................fdn.pic....................................................]-( 120000) 0x004000f4.0 movz x17, #17, #0 [ 18]
[.........................................................r......................]-( 160000) ...
[.....................fdn.pic....................................................]-( 120000) 0x004000f8.0 movz x18, #18, #0 [ 19]
[.........................................................r......................]-( 160000) ...
[.....................fdn.pic....................................................]-( 120000) 0x004000fc.0 movz x19, #19, #0 [ 20]
[.........................................................r......................]-( 160000) ...
[............................................fdn.ic.......r......................]-( 160000) 0x00400100.0 movz x20, #20, #0 [ 21]
[............................................fdn.ic........r.....................]-( 160000) 0x00400104.0 movz x21, #21, #0 [ 22]
[............................................fdn.ic........r.....................]-( 160000) 0x00400108.0 movz x22, #22, #0 [ 23]
[............................................fdn.ic........r.....................]-( 160000) 0x0040010c.0 movz x23, #23, #0 [ 24]
[............................................fdn.ic........r.....................]-( 160000) 0x00400110.0 movz x24, #24, #0 [ 25]
[............................................fdn.ic........r.....................]-( 160000) 0x00400114.0 movz x25, #25, #0 [ 26]
[............................................fdn.pic.......r.....................]-( 160000) 0x00400118.0 movz x26, #26, #0 [ 27]
[............................................fdn.pic.......r.....................]-( 160000) 0x0040011c.0 movz x27, #27, #0 [ 28]
[.............................................fdn.ic.......r.....................]-( 160000) 0x00400120.0 movz x28, #28, #0 [ 29]
[.............................................fdn.ic........r....................]-( 160000) 0x00400124.0 movz x29, #29, #0 [ 30]
[.............................................fdn.ic........r....................]-( 160000) 0x00400128.0 movz x0, #0, #0 [ 31]
[.............................................fdn.ic........r....................]-( 160000) 0x0040012c.0 movz x1, #1, #0 [ 32]
[.............................................fdn.pic.......r....................]-( 160000) 0x00400130.0 movz x2, #2, #0 [ 33]
[.............................................fdn.pic.......r....................]-( 160000) 0x00400134.0 movz x3, #3, #0 [ 34]
[.............................................fdn.pic.......r....................]-( 160000) 0x00400138.0 movz x4, #4, #0 [ 35]
[.............................................fdn.pic.......r....................]-( 160000) 0x0040013c.0 movz x5, #5, #0 [ 36]
We now also understand the graph better from lines such as this:
[....................fdn.pic.....................................................]-( 120000) 0x004000c4.0 ldr x5, [x4] [ 6] [........................................................r.......................]-( 160000) ... [....................fdn.ic......................................................]-( 120000) 0x004000c8.0 movz x6, #6, #0 [ 7] [........................................................r.......................]-( 160000) ...
We see that extra lines are drawn (the 160000 … lines here) whenever something stalls for a period longer than the width of the visualisation.
Things are still relatively readable because the wrapping aligns them with events that actually happened on that line directly e.g. 160000) 0x00400100.0 movz x20, #20, #0..
But from this we kind of see the need for: gem5 Konata O3 pipeline viewer.
24.22.4.8.6. gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: stall_hazard4
Like gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: stall_gain but now with some dependencies after the LDR: userland/arch/aarch64/freestanding/linux/stall_hazard4.S.
So in this case the ic of dependencies like add x6, x5, #1 have to wait until the LDR is finished:
// f = fetch, d = decode, n = rename, p = dispatch, i = issue, c = complete, r = retire
timeline tick pc.upc disasm seq_num
[.ic.r........................................................................fdn]-( 40000) 0x004000b0.0 movz x0, #0, #0 [ 1]
[.ic.r........................................................................fdn]-( 40000) 0x004000b4.0 movz x1, #1, #0 [ 2]
[.ic.r........................................................................fdn]-( 40000) 0x004000b8.0 movz x2, #4, #0 [ 3]
[.ic.r........................................................................fdn]-( 40000) 0x004000bc.0 movz x3, #5, #0 [ 4]
[....................fdn.ic.r....................................................]-( 120000) 0x004000c0.0 adr x4, #65772 [ 5]
[....................fdn.pic.....................................................]-( 120000) 0x004000c4.0 ldr x5, [x4] [ 6]
[........................................................r.......................]-( 160000) ...
[....................fdn.p.......................................................]-( 120000) 0x004000c8.0 add x6, x5, #1 [ 7]
[......................................................ic.r......................]-( 160000) ...
[....................fdn.p.......................................................]-( 120000) 0x004000cc.0 add x7, x6, #1 [ 8]
[.......................................................ic.r.....................]-( 160000) ...
[....................fdn.p.......................................................]-( 120000) 0x004000d0.0 add x8, x7, #1 [ 9]
[........................................................ic.r....................]-( 160000) ...
[....................fdn.p.......................................................]-( 120000) 0x004000d4.0 add x9, x8, #1 [ 10]
[.........................................................ic.r...................]-( 160000) ...
[....................fdn.ic......................................................]-( 120000) 0x004000d8.0 movz x10, #10, #0 [ 11]
[............................................................r...................]-( 160000) ...
[....................fdn.ic......................................................]-( 120000) 0x004000dc.0 movz x11, #11, #0 [ 12]
[............................................................r...................]-( 160000) ...
[.....................fdn.ic.....................................................]-( 120000) 0x004000e0.0 movz x12, #12, #0 [ 13]
[............................................................r...................]-( 160000) ...
[.....................fdn.ic.....................................................]-( 120000) 0x004000e4.0 movz x13, #13, #0 [ 14]
[............................................................r...................]-( 160000) ...
[.....................fdn.ic.....................................................]-( 120000) 0x004000e8.0 movz x14, #14, #0 [ 15]
[............................................................r...................]-( 160000) ...
[.....................fdn.ic.....................................................]-( 120000) 0x004000ec.0 movz x15, #15, #0 [ 16]
[............................................................r...................]-( 160000) ...
[.....................fdn.ic.....................................................]-( 120000) 0x004000f0.0 movz x16, #16, #0 [ 17]
[............................................................r...................]-( 160000) ...
[.....................fdn.ic.....................................................]-( 120000) 0x004000f4.0 movz x17, #17, #0 [ 18]
[.............................................................r..................]-( 160000) ...
[.....................fdn.pic....................................................]-( 120000) 0x004000f8.0 movz x18, #18, #0 [ 19]
[.............................................................r..................]-( 160000) ...
[.....................fdn.pic....................................................]-( 120000) 0x004000fc.0 movz x19, #19, #0 [ 20]
[.............................................................r..................]-( 160000) ...
[............................................fdn.ic...........r..................]-( 160000) 0x00400100.0 movz x20, #20, #0 [ 21]
[............................................fdn.ic...........r..................]-( 160000) 0x00400104.0 movz x21, #21, #0 [ 22]
[............................................fdn.ic...........r..................]-( 160000) 0x00400108.0 movz x22, #22, #0 [ 23]
[............................................fdn.ic...........r..................]-( 160000) 0x0040010c.0 movz x23, #23, #0 [ 24]
[............................................fdn.ic...........r..................]-( 160000) 0x00400110.0 movz x24, #24, #0 [ 25]
[............................................fdn.ic............r.................]-( 160000) 0x00400114.0 movz x25, #25, #0 [ 26]
[............................................fdn.pic...........r.................]-( 160000) 0x00400118.0 movz x26, #26, #0 [ 27]
[............................................fdn.pic...........r.................]-( 160000) 0x0040011c.0 movz x27, #27, #0 [ 28]
[.............................................fdn.ic...........r.................]-( 160000) 0x00400120.0 movz x28, #28, #0 [ 29]
[.............................................fdn.ic...........r.................]-( 160000) 0x00400124.0 movz x29, #29, #0 [ 30]
[.............................................fdn.ic...........r.................]-( 160000) 0x00400128.0 movz x0, #0, #0 [ 31]
[.............................................fdn.ic...........r.................]-( 160000) 0x0040012c.0 movz x1, #1, #0 [ 32]
[.............................................fdn.pic..........r.................]-( 160000) 0x00400130.0 movz x2, #2, #0 [ 33]
[.............................................fdn.pic...........r................]-( 160000) 0x00400134.0 movz x3, #3, #0 [ 34]
[.............................................fdn.pic...........r................]-( 160000) 0x00400138.0 movz x4, #4, #0 [ 35]
[.............................................fdn.pic...........r................]-( 160000) 0x0040013c.0 movz x5, #5, #0 [ 36]
24.22.4.8.7. gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: speculative
Now let’s try to see some Speculative execution in action with userland/arch/aarch64/freestanding/linux/speculative.S.
That program is setup such that the branch is not taken if an extra CLI argument is passed with --cli-args.
We purposefully set things up so that speculation will be running from the icache so we can see what is going on more clearly without ifetch stalls.
Without an extra CLI argument (the branch is taken):
// f = fetch, d = decode, n = rename, p = dispatch, i = issue, c = complete, r = retire
timeline tick pc.upc disasm seq_num
[.............................................................................fdn]-( 40000) 0x00400078.0 ldr x0, [sp] [ 1]
[.ic.............................................................................]-( 80000) ...
[................................r...............................................]-( 120000) ...
[.............................................................................fdn]-( 40000) 0x0040007c.0 movz x1, #1, #0 [ 2]
[.ic.............................................................................]-( 80000) ...
[................................r...............................................]-( 120000) ...
[....................fdn.ic......r...............................................]-( 120000) 0x00400080.0 movz x2, #2, #0 [ 3]
[....................fdn.ic......r...............................................]-( 120000) 0x00400084.0 movz x3, #3, #0 [ 4]
[....................fdn.ic......r...............................................]-( 120000) 0x00400088.0 movz x4, #4, #0 [ 5]
[....................fdn.ic......r...............................................]-( 120000) 0x0040008c.0 movz x5, #5, #0 [ 6]
[....................fdn.ic......r...............................................]-( 120000) 0x00400090.0 movz x6, #6, #0 [ 7]
[....................fdn.p.....ic..r.............................................]-( 120000) 0x00400094.0 subs x0, #2 [ 8]
[....................fdn.ic........r.............................................]-( 120000) 0x00400098.0 movz x0, #3, #0 [ 9]
[....................fdn.p......ic.r.............................................]-( 120000) 0x0040009c.0 b.lt 0x400080 [ 10]
[=====================fdn=ic=====================================================]-( 120000) 0x004000a0.0 -----movz x10, #10, #0 [ 11]
[=====================fdn=ic=====================================================]-( 120000) 0x004000a4.0 -----movz x11, #11, #0 [ 12]
[=====================fdn=ic=====================================================]-( 120000) 0x004000a8.0 -----movz x12, #12, #0 [ 13]
[=====================fdn=ic=====================================================]-( 120000) 0x004000ac.0 -----movz x13, #13, #0 [ 14]
[=====================fdn=ic=====================================================]-( 120000) 0x004000b0.0 -----movz x14, #14, #0 [ 15]
[=====================fdn=ic=====================================================]-( 120000) 0x004000b4.0 -----movz x15, #15, #0 [ 16]
[=====================fdn=pic====================================================]-( 120000) 0x004000b8.0 -----movz x16, #16, #0 [ 17]
[=====================fdn=pic====================================================]-( 120000) 0x004000bc.0 -----movz x17, #17, #0 [ 18]
[.....................................fdn.ic.r...................................]-( 120000) 0x00400080.0 movz x2, #2, #0 [ 19]
[.....................................fdn.ic.r...................................]-( 120000) 0x00400084.0 movz x3, #3, #0 [ 20]
[.....................................fdn.ic.r...................................]-( 120000) 0x00400088.0 movz x4, #4, #0 [ 21]
[.....................................fdn.ic.r...................................]-( 120000) 0x0040008c.0 movz x5, #5, #0 [ 22]
[.....................................fdn.ic.r...................................]-( 120000) 0x00400090.0 movz x6, #6, #0 [ 23]
[.....................................fdn.pic.r..................................]-( 120000) 0x00400098.0 movz x0, #3, #0 [ 25]
[.....................................fdn.pic.r..................................]-( 120000) 0x0040009c.0 b.lt 0x400080 [ 26]
[......................................fdn.ic.r..................................]-( 120000) 0x004000a0.0 movz x10, #10, #0 [ 27]
[......................................fdn.ic.r..................................]-( 120000) 0x004000a4.0 movz x11, #11, #0 [ 28]
[......................................fdn.ic.r..................................]-( 120000) 0x004000a8.0 movz x12, #12, #0 [ 29]
[......................................fdn.ic.r..................................]-( 120000) 0x004000ac.0 movz x13, #13, #0 [ 30]
[......................................fdn.pic.r.................................]-( 120000) 0x004000b0.0 movz x14, #14, #0 [ 31]
[......................................fdn.pic.r.................................]-( 120000) 0x004000b4.0 movz x15, #15, #0 [ 32]
[......................................fdn.pic.r.................................]-( 120000) 0x004000b8.0 movz x16, #16, #0 [ 33]
[......................................fdn.pic.r.................................]-( 120000) 0x004000bc.0 movz x17, #17, #0 [ 34]
[.............................................fdn.ic.r...........................]-( 160000) 0x004000c0.0 movz x0, #0, #0 [ 35]
[.............................................fdn.ic.r...........................]-( 160000) 0x004000c4.0 movz x8, #93, #0 [ 36]
So here we see that the CPU mispredicted! After the BLT instruction, the CPU continued to run movz x10, assuming that the branch would not be taken.
Then, at time 120000, the LDR data came back, after the wrong prediction had already been fully executed.
The CPU then noticed that it mispredicted, and so it started again from the correct branch target movz x2, and the instructions that were thrown away are marked as ===== in the timeline.
We can also see some Branch predictor log lines in the O3CPUAll log:
130000: Fetch: system.cpu.fetch: [tid:0] [sn:10] Branch at PC 0x40009c predicted to be not taken 130000: Fetch: system.cpu.fetch: [tid:0] [sn:10] Branch at PC 0x40009c predicted to go to (0x4000a0=>0x4000a4).(0=>1) 131500: Commit: system.cpu.commit: [tid:10] [sn:0] Inserting PC (0x40009c=>0x4000a0).(0=>1) into ROB. 131500: ROB: system.cpu.rob: Adding inst PC (0x40009c=>0x4000a0).(0=>1) to the ROB. 131500: ROB: system.cpu.rob: [tid:0] Now has 10 instructions. 132000: IEW: system.cpu.iew: [tid:0] Issue: Adding PC (0x40009c=>0x4000a0).(0=>1) [sn:10] [tid:0] to IQ. 132000: IQ: system.cpu.iq: Adding instruction [sn:10] PC (0x40009c=>0x4000a0).(0=>1) to the IQ. 132000: IQ: system.cpu.iq: Instruction PC (0x40009c=>0x4000a0).(0=>1) has src reg 6 (CCRegClass) that is being added to the dependency chain. 132000: IQ: system.cpu.iq: Instruction PC (0x40009c=>0x4000a0).(0=>1) has src reg 8 (CCRegClass) that is being added to the dependency chain. 132000: IQ: system.cpu.iq: Instruction PC (0x40009c=>0x4000a0).(0=>1) has src reg 7 (CCRegClass) that is being added to the dependency chain. 135500: IQ: system.cpu.iq: Waking up a dependent instruction, [sn:10] PC (0x40009c=>0x4000a0).(0=>1). 135500: IQ: global: [sn:10] has 1 ready out of 3 sources. RTI 0) 135500: IQ: system.cpu.iq: Waking any dependents on register 7 (CCRegClass). 135500: IQ: system.cpu.iq: Waking up a dependent instruction, [sn:10] PC (0x40009c=>0x4000a0).(0=>1). 135500: IQ: global: [sn:10] has 2 ready out of 3 sources. RTI 0) 135500: IQ: system.cpu.iq: Waking any dependents on register 8 (CCRegClass). 135500: IQ: system.cpu.iq: Waking up a dependent instruction, [sn:10] PC (0x40009c=>0x4000a0).(0=>1). 135500: IQ: global: [sn:10] has 3 ready out of 3 sources. RTI 0) 135500: IQ: system.cpu.iq: Instruction is ready to issue, putting it onto the ready list, PC (0x40009c=>0x4000a0).(0=>1) opclass:1 [sn:10]. 135500: IEW: system.cpu.iew: Setting Destination Register 6 (CCRegClass) 135500: Scoreboard: system.cpu.scoreboard: Setting reg 6 (CCRegClass) as ready 135500: IEW: system.cpu.iew: Setting Destination Register 7 (CCRegClass) 135500: Scoreboard: system.cpu.scoreboard: Setting reg 7 (CCRegClass) as ready 135500: IEW: system.cpu.iew: Setting Destination Register 8 (CCRegClass) 135500: Scoreboard: system.cpu.scoreboard: Setting reg 8 (CCRegClass) as ready 135500: IQ: system.cpu.iq: Attempting to schedule ready instructions from the IQ. 135500: IQ: system.cpu.iq: Thread 0: Issuing instruction PC (0x40009c=>0x4000a0).(0=>1) [sn:10] 136000: IEW: system.cpu.iew: Execute: Processing PC (0x40009c=>0x4000a0).(0=>1), [tid:0] [sn:10]. 136000: IEW: global: RegFile: Access to cc register 6, has data 0x2 136000: IEW: global: RegFile: Access to cc register 8, has data 0 136000: IEW: global: RegFile: Access to cc register 7, has data 0 136000: IEW: system.cpu.iew: Current wb cycle: 0, width: 8, numInst: 0 wbActual:0 136000: IEW: system.cpu.iew: [tid:0] [sn:10] Execute: Branch mispredict detected. 136000: IEW: system.cpu.iew: [tid:0] [sn:10] Predicted target was PC: (0x4000a0=>0x4000a4).(0=>1) 136000: IEW: system.cpu.iew: [tid:0] [sn:10] Execute: Redirecting fetch to PC: (0x40009c=>0x400080).(0=>1) 136000: IEW: system.cpu.iew: [tid:0] [sn:10] Squashing from a specific instruction, PC: (0x40009c=>0x400080).(0=>1) 136500: Commit: system.cpu.commit: [tid:0] Squashing due to branch mispred PC:0x40009c [sn:10] 136500: Commit: system.cpu.commit: [tid:0] Redirecting to PC 0x400084 136500: ROB: system.cpu.rob: Starting to squash within the ROB. 136500: ROB: system.cpu.rob: [tid:0] Squashing instructions until [sn:10]. 136500: ROB: system.cpu.rob: [tid:0] Squashing instruction PC (0x4000bc=>0x4000c0).(0=>1), seq num 18. 136500: ROB: system.cpu.rob: [tid:0] Squashing instruction PC (0x4000b8=>0x4000bc).(0=>1), seq num 17. 136500: ROB: system.cpu.rob: [tid:0] Squashing instruction PC (0x4000b4=>0x4000b8).(0=>1), seq num 16. 136500: ROB: system.cpu.rob: [tid:0] Squashing instruction PC (0x4000b0=>0x4000b4).(0=>1), seq num 15. 136500: ROB: system.cpu.rob: [tid:0] Squashing instruction PC (0x4000ac=>0x4000b0).(0=>1), seq num 14. 136500: ROB: system.cpu.rob: [tid:0] Squashing instruction PC (0x4000a8=>0x4000ac).(0=>1), seq num 13. 136500: ROB: system.cpu.rob: [tid:0] Squashing instruction PC (0x4000a4=>0x4000a8).(0=>1), seq num 12. 136500: ROB: system.cpu.rob: [tid:0] Squashing instruction PC (0x4000a0=>0x4000a4).(0=>1), seq num 11. 136500: ROB: system.cpu.rob: [tid:0] Done squashing instructions. 136500: Commit: system.cpu.commit: [tid:0] Marking PC (0x40009c=>0x400080).(0=>1), [sn:10] ready within ROB. 137000: Commit: system.cpu.commit: [tid:0] [sn:10] Committing instruction with PC (0x40009c=>0x400080).(0=>1) 130000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+36 : b.lt 0x400080 : IntAlu : FetchSeq=10 CPSeq=10 flags=(IsControl|IsDirectControl|IsCondControl) 137000: ROB: system.cpu.rob: [tid:0] Retiring head instruction, instruction PC (0x40009c=>0x400080).(0=>1), [sn:10] 137000: O3CPU: system.cpu: Removing committed instruction [tid:0] PC (0x40009c=>0x400080).(0=>1) [sn:10] 137000: Commit: system.cpu.commit: Trying to commit head instruction, [tid:0] [sn:11] 137000: Commit: system.cpu.commit: Retiring squashed instruction from ROB. 137000: Commit: system.cpu.commit: Trying to commit head instruction, [tid:0] [sn:10] 137000: Commit: system.cpu.commit: [tid:0] [sn:10] Committing instruction with PC (0x40009c=>0x400080).(0=>1) 130000: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+36 : b.lt 0x400080 : IntAlu : FetchSeq=10 CPSeq=10 flags=(IsControl|IsDirectControl|IsCondControl) 138500: Fetch: system.cpu.fetch: [tid:0] [sn:26] Branch at PC 0x40009c predicted to be not taken 138500: Fetch: system.cpu.fetch: [tid:0] [sn:26] Branch at PC 0x40009c predicted to go to (0x4000a0=>0x4000a4).(0=>1) 142500: Commit: system.cpu.commit: [tid:0] [sn:26] Committing instruction with PC (0x40009c=>0x4000a0).(0=>1) 138500: ExecEnable: system.cpu: A0 T0 : @asm_main_after_prologue+36 : b.lt 0x400080 : IntAlu : FetchSeq=26 CPSeq=18 flags=(IsControl|IsDirectControl|IsCondControl) 142500: ROB: system.cpu.rob: [tid:0] Retiring head instruction, instruction PC (0x40009c=>0x4000a0).(0=>1), [sn:26]
With an extra CLI (the branch is not taken):
// f = fetch, d = decode, n = rename, p = dispatch, i = issue, c = complete, r = retire
timeline tick pc.upc disasm seq_num
[.............................................................................fdn]-( 40000) 0x00400078.0 ldr x0, [sp] [ 1]
[.ic.............................................................................]-( 80000) ...
[................................r...............................................]-( 120000) ...
[.............................................................................fdn]-( 40000) 0x0040007c.0 movz x1, #1, #0 [ 2]
[.ic.............................................................................]-( 80000) ...
[................................r...............................................]-( 120000) ...
[....................fdn.ic......r...............................................]-( 120000) 0x00400080.0 movz x2, #2, #0 [ 3]
[....................fdn.ic......r...............................................]-( 120000) 0x00400084.0 movz x3, #3, #0 [ 4]
[....................fdn.ic......r...............................................]-( 120000) 0x00400088.0 movz x4, #4, #0 [ 5]
[....................fdn.ic......r...............................................]-( 120000) 0x0040008c.0 movz x5, #5, #0 [ 6]
[....................fdn.ic......r...............................................]-( 120000) 0x00400090.0 movz x6, #6, #0 [ 7]
[....................fdn.ic.......r..............................................]-( 120000) 0x00400098.0 movz x0, #3, #0 [ 9]
[....................fdn.p......ic.r.............................................]-( 120000) 0x0040009c.0 b.lt 0x400080 [ 10]
[.....................fdn.ic.......r.............................................]-( 120000) 0x004000a0.0 movz x10, #10, #0 [ 11]
[.....................fdn.ic.......r.............................................]-( 120000) 0x004000a4.0 movz x11, #11, #0 [ 12]
[.....................fdn.ic.......r.............................................]-( 120000) 0x004000a8.0 movz x12, #12, #0 [ 13]
[.....................fdn.ic.......r.............................................]-( 120000) 0x004000ac.0 movz x13, #13, #0 [ 14]
[.....................fdn.ic.......r.............................................]-( 120000) 0x004000b0.0 movz x14, #14, #0 [ 15]
[.....................fdn.ic.......r.............................................]-( 120000) 0x004000b4.0 movz x15, #15, #0 [ 16]
[.....................fdn.pic......r.............................................]-( 120000) 0x004000b8.0 movz x16, #16, #0 [ 17]
[.....................fdn.pic.......r............................................]-( 120000) 0x004000bc.0 movz x17, #17, #0 [ 18]
[............................................fdn.ic.r............................]-( 160000) 0x004000c0.0 movz x0, #0, #0 [ 19]
[............................................fdn.ic.r............................]-( 160000) 0x004000c4.0 movz x8, #93, #0 [ 20]
So this time the prediction was correct. Retire is delayed until the memory comes back, but we otherwise just kept running forward until hitting the next ifetch cache line.
24.22.5. gem5 instruction definitions
This is one of the parts of gem5 that rely on semi-useless code generation inside the .isa sublanguage.
Which is mostly Python, with some magic letters thrown in for good measure.
The class definitions get all dumped into one humongous C++ include file:
build/ARM/arch/arm/generated/exec-ns.cc.inc
That file defines the key methods of each instruction, e.g. the ARM immediate ADD instruction has its execute method defined there:
Fault AddImm::execute(
ExecContext *xc, Trace::InstRecord *traceData) const
or for example the key methods of an ARM 64-bit (X) STR with an immediate offset (STR <Wt>, [<Xn|SP>], #<simm>):
Fault STRX64_IMM::execute(ExecContext *xc,
Trace::InstRecord *traceData) const
Fault STRX64_IMM::initiateAcc(ExecContext *xc,
Trace::InstRecord *traceData) const
Fault STRX64_IMM::completeAcc(PacketPtr pkt, ExecContext *xc,
Trace::InstRecord *traceData) const
{
return NoFault;
}
We also notice that the key argument passed to those instructions is of type ExecContext, which is discussed further at: Section 24.22.6.3, “gem5 ExecContext”.
The file is an include so that compilation can be split up into chunks by the autogenerated includers
build/ARM/arch/arm/generated/generic_cpu_1.cc build/ARM/arch/arm/generated/generic_cpu_2.cc ...
via the __SPLIT macro as in:
#include "exec-g.cc.inc"
#include "cpu/exec_context.hh"
#include "decoder.hh"
namespace ArmISAInst {
#define __SPLIT 1
#include "exec-ns.cc.inc"
}
This is likely done to not overload the C++ compiler? But sure enough overloads IDEs and GDB which takes forever to load the source of any frames going through it.
We should split that file into one per class for the love of God.
The autogenerated instruction class declarations can be found at:
build/ARM/arch/arm/generated/decoder-ns.hh.inc
and the autogenerated bulk of the decoder:
build/ARM/arch/arm/generated/decoder-ns.cc.inc
which also happens to contain the constructor definitions of the instruction classes, e.g. for the ADD immediate because why not:
AddImm::AddImm(ExtMachInst machInst,
IntRegIndex _dest,
IntRegIndex _op1,
uint32_t _imm,
bool _rotC)
The above files get tied in the autogenerated:
build/ARM/arch/arm/generated/decoder.hh
which contains:
#include "decoder-g.hh.inc"
namespace ArmISAInst {
#include "decoder-ns.hh.inc"
}
Different instructions inherit form different classes, e.g. the ARM immediate ADD instruction is a DataImmOp:
class AddImm : public DataImmOp
{
public:
// Constructor
AddImm(ExtMachInst machInst, IntRegIndex _dest,
IntRegIndex _op1, uint32_t _imm, bool _rotC=true);
Fault execute(ExecContext *, Trace::InstRecord *) const override;
};
and STRX64_IMM is an ArmISA::MemoryImm64:
class STRX64_IMM : public ArmISA::MemoryImm64
{
public:
/// Constructor.
STRX64_IMM(ExtMachInst machInst,
IntRegIndex _dest, IntRegIndex _base, int64_t _imm);
Fault execute(ExecContext *, Trace::InstRecord *) const override;
Fault initiateAcc(ExecContext *, Trace::InstRecord *) const override;
Fault completeAcc(PacketPtr, ExecContext *,
Trace::InstRecord *) const override;
void
annotateFault(ArmFault *fault) override
{
fault->annotate(ArmFault::SAS, 3);
fault->annotate(ArmFault::SSE, false);
fault->annotate(ArmFault::SRT, dest);
fault->annotate(ArmFault::SF, true);
fault->annotate(ArmFault::AR, false);
}
};
but different memory instructions can have different base classes too e.g. STXR:
class STXRX64 : public ArmISA::MemoryEx64
A summarized class hierarchy for the above is:
-
StaticInst-
ArmISA::ArmStaticInst-
ArmISA::PredOp-
ArmISA::DataImmOp-
ArmISA::AddImm
-
-
ArmISA::MightBeMicro64-
ArmISA::Memory64
-
ArmISA::MemoryImm64-
ArmISA::MemoryEx64-
ArmISA::STXRX64
-
-
-
-
-
-
-
Tested in gem5 b1623cb2087873f64197e503ab8894b5e4d4c7b4.
24.22.5.1. gem5 execute vs initiateAcc vs completeAcc
These are the key methods defined in instruction definitions, so lets see when each one gets called and what they do more or less.
execute is the only one of the three that gets defined by "non-memory" instructions.
Memory instructions define all three.
The three methods are present in the base class StaticInst:
virtual Fault execute(ExecContext *xc,
Trace::InstRecord *traceData) const = 0;
virtual Fault initiateAcc(ExecContext *xc,
Trace::InstRecord *traceData) const
{
panic("initiateAcc not defined!");
}
virtual Fault completeAcc(Packet *pkt, ExecContext *xc,
Trace::InstRecord *traceData) const
{
panic("completeAcc not defined!");
}
so we see that all instructions must implement execute, while overriding initiateAcc and completeAcc are optional and only done by classes for which those might get called: memory instructions.
execute is what does the actual job for non-memory instructions (obviously, since it is the only one of the three methods that is defined as not panic for those).
Memory instructions however run either:
-
executeinAtomicSimpleCPU: this does the entire memory access in one go -
initiateAcc+completeAccin timing CPUs.initiateAccis called when the instruction starts executing, andcompleteAccis called when the memory fetch returns from the memory system.
This can be seen concretely in GDB from the analysis done at: TimingSimpleCPU analysis: LDR stall and for more memory details see gem5 functional vs atomic vs timing memory requests.
24.22.5.1.1. gem5 completeAcc
completeAcc is boring on most simple store memory instructions, e.g. a simple STR:
Fault STRX64_IMM::completeAcc(PacketPtr pkt, ExecContext *xc,
Trace::InstRecord *traceData) const
{
return NoFault;
}
This is because the store does all of its job on completeAcc basically, creating the memory write request.
Loads however have non-trivial completeAcc, because now we have at the very least, to save the value read from memory into a CPU address.
Things are much more interesting however on more interesting loads, for example STXR (hand formatted here):
Fault STXRX64::completeAcc(PacketPtr pkt, ExecContext *xc,
Trace::InstRecord *traceData) const {
Fault fault = NoFault;
uint64_t XResult = 0;
uint32_t SevMailbox = 0;
uint32_t LLSCLock = 0;
uint64_t writeResult = pkt->req->getExtraData();
XResult = !writeResult; SevMailbox = 1; LLSCLock = 0;
if (fault == NoFault) {
{
uint64_t final_val = XResult;
xc->setIntRegOperand(this, 0, (XResult) & mask(aarch64 ? 64 : 32));
if (traceData) { traceData->setData(final_val); }
}
xc->setMiscRegOperand(this, 1, SevMailbox);
if (traceData) { traceData->setData(SevMailbox); }
xc->setMiscRegOperand(this, 2, LLSCLock);
if (traceData) { traceData->setData(LLSCLock); }
}
return fault;
}
From GDB on TimingSimpleCPU analysis: LDR stall we see that completeAcc gets called from TimingSimpleCPU::completeDataAccess.
24.22.5.2. gem5 microops
Some gem5 instructions break down into multiple microops.
Microops are very similar to regular instructions, and show on the gem5 ExecAll trace format since that flag implies ExecMicro.
On aarch64 for example, one of the simplest microoped instructions is STP, which does the relatively complex operation of storing two values to memory at once, and is therefore a good candidate for being broken down into microops. We can observe it when executing:
./run \ --arch arch64 \ --emulator gem5 \ --trace-insts-stdout \ --userland userland/arch/aarch64/freestanding/linux/disassembly_test.S \ ;
which contains in gem5’s broken-ish disassembly that the input:
stp x1, x2 [x0, 16]
generated the output:
16500: system.cpu: A0 T0 : @_start+108 : stp 16500: system.cpu: A0 T0 : @_start+108. 0 : addxi_uop ureg0, x0, #16 : IntAlu : D=0x0000000000420010 flags=(IsInteger|IsMicroop|IsDelayedCommit|IsFirstMicroop) 17000: system.cpu: A0 T0 : @_start+108. 1 : strxi_uop w1, [ureg0] : MemWrite : D=0x000000009abcdef0 A=0x420010 flags=(IsInteger|IsMemRef|IsStore|IsMicroop|IsDelayedCommit) 17500: system.cpu: A0 T0 : @_start+108. 2 : strxi_uop w2, [ureg0, #8] : MemWrite : D=0x0000000000000002 A=0x420018 flags=(IsInteger|IsMemRef|IsStore|IsMicroop|IsLastMicroop)
Where @_start+108. 0, @_start+108. 1 and @_start+108. 2 all happen at the same PC, and are therefore microops of STP.
From their names, which are of course not specified in the ARMv8 architecture reference manual, we guess that:
-
addxi_uop: adds 16 -
strxi_uop: stores one of the two members of the pair, like a regular STR
From the gem5 source code, we see that STP is a class LdpStp : public PairMemOp, and then the constructor of PairMemOp sets up the microops depending on the exact type of LDP/STP:
24.22.6. gem5 ThreadContext vs ThreadState vs ExecContext vs Process
These classes get used everywhere, and they have a somewhat convoluted relation with one another, so let’s figure it out this mess.
None of those objects are SimObjects, so they must all belong to some higher SimObject.
This section and all children tested at gem5 b1623cb2087873f64197e503ab8894b5e4d4c7b4.
24.22.6.1. gem5 ThreadContext
As we delve into more details below, we will reach the following conclusion: a ThreadContext represents on thread of a CPU with multiple Hardware threads.
We therefore we can have multiple ThreadContext for each BaseCPU.
ThreadContext is what gets passed in syscalls, e.g.:
src/sim/syscall_emul.hh
template <class OS>
SyscallReturn
readFunc(SyscallDesc *desc, ThreadContext *tc,
int tgt_fd, Addr buf_ptr, int nbytes)
The class hierarchy for ThreadContext looks like:
ThreadContext O3ThreadContext SimpleThread
where the gem5 MinorCPU also uses SimpleThread:
/** Minor will use the SimpleThread state for now */ typedef SimpleThread MinorThread;
It is a bit confusing, things would be much clearer if SimpleThread was called instead SimpleThreadContext!
readIntReg and other register access methods are some notable methods implemented in descendants, e.g. SimpleThread::readIntReg.
Essentially all methods of the base ThreadContext are pure virtual.
24.22.6.1.1. gem5 SimpleThread
SimpleThread storage defined on BaseSimpleCPU for simple CPUs like AtomicSimpleCPU:
for (unsigned i = 0; i < numThreads; i++) {
if (FullSystem) {
thread = new SimpleThread(this, i, p->system,
p->itb, p->dtb, p->isa[i]);
} else {
thread = new SimpleThread(this, i, p->system, p->workload[i],
p->itb, p->dtb, p->isa[i]);
}
threadInfo.push_back(new SimpleExecContext(this, thread));
ThreadContext *tc = thread->getTC();
threadContexts.push_back(tc);
}
and on MinorCPU for Minor:
MinorCPU::MinorCPU(MinorCPUParams *params) :
BaseCPU(params),
threadPolicy(params->threadPolicy)
{
/* This is only written for one thread at the moment */
Minor::MinorThread *thread;
for (ThreadID i = 0; i < numThreads; i++) {
if (FullSystem) {
thread = new Minor::MinorThread(this, i, params->system,
params->itb, params->dtb, params->isa[i]);
thread->setStatus(ThreadContext::Halted);
} else {
thread = new Minor::MinorThread(this, i, params->system,
params->workload[i], params->itb, params->dtb,
params->isa[i]);
}
threads.push_back(thread);
ThreadContext *tc = thread->getTC();
threadContexts.push_back(tc);
}
Those are used from gem5 ExecContext.
From this we see that one CPU can have multiple threads, and that this is controlled from the Python:
BaseCPU::BaseCPU(Params *p, bool is_checker)
: numThreads(p->numThreads)
and since SimpleThread contains its registers, this must represent Hardware threads.
If we analyse SimpleThread::readIntReg, we see that the actual register data is contained inside ThreadContext descendants, e.g. in SimpleThread:
RegVal
readIntReg(RegIndex reg_idx) const override
{
int flatIndex = isa->flattenIntIndex(reg_idx);
assert(flatIndex < TheISA::NumIntRegs);
uint64_t regVal(readIntRegFlat(flatIndex));
DPRINTF(IntRegs, "Reading int reg %d (%d) as %#x.\n",
reg_idx, flatIndex, regVal);
return regVal;
}
RegVal readIntRegFlat(RegIndex idx) const override { return intRegs[idx]; }
void
setIntRegFlat(RegIndex idx, RegVal val) override
{
intRegs[idx] = val;
}
std::array<RegVal, TheISA::NumIntRegs> intRegs;
Another notable type of method contained in Thread context are methods that forward to gem5 ThreadState.
24.22.6.1.2. gem5 O3ThreadContext
Instantiation happens in the FullO3CPU constructor:
FullO3CPU<Impl>::FullO3CPU(DerivO3CPUParams *params)
for (ThreadID tid = 0; tid < this->numThreads; ++tid) {
if (FullSystem) {
// SMT is not supported in FS mode yet.
assert(this->numThreads == 1);
this->thread[tid] = new Thread(this, 0, NULL);
// Setup the TC that will serve as the interface to the threads/CPU.
O3ThreadContext<Impl> *o3_tc = new O3ThreadContext<Impl>;
and the SimObject DerivO3CPU is just a FullO3CPU instantiation:
class DerivO3CPU : public FullO3CPU<O3CPUImpl>
O3ThreadContext is a template class:
template <class Impl> class O3ThreadContext : public ThreadContext
The only Impl used appears to be O3CPUImpl? This is explicitly instantiated in the source:
template class O3ThreadContext<O3CPUImpl>;
Unlike in SimpleThread however, O3ThreadContext does not contain the register data itself, e.g. O3ThreadContext::readIntRegFlat instead forwards to cpu:
template <class Impl>
RegVal
O3ThreadContext<Impl>::readIntRegFlat(RegIndex reg_idx) const
{
return cpu->readArchIntReg(reg_idx, thread->threadId());
}
where:
typedef typename Impl::O3CPU O3CPU;
/** Pointer to the CPU. */
O3CPU *cpu;
and:
struct O3CPUImpl
{
/** The O3CPU type to be used. */
typedef FullO3CPU<O3CPUImpl> O3CPU;
and at long last FullO3CPU contains the register values:
template <class Impl>
RegVal
FullO3CPU<Impl>::readArchIntReg(int reg_idx, ThreadID tid)
{
intRegfileReads++;
PhysRegIdPtr phys_reg = commitRenameMap[tid].lookup(
RegId(IntRegClass, reg_idx));
return regFile.readIntReg(phys_reg);
}
So we guess that this difference from SimpleThread is due to register renaming of the out of order implementation.
24.22.6.2. gem5 ThreadState
Owned one per ThreadContext.
Many ThreadContext methods simply forward to ThreadState implementations.
SimpleThread inherits from ThreadState, and forwards to it on several methods e.g.:
int cpuId() const override { return ThreadState::cpuId(); }
uint32_t socketId() const override { return ThreadState::socketId(); }
int threadId() const override { return ThreadState::threadId(); }
void setThreadId(int id) override { ThreadState::setThreadId(id); }
ContextID contextId() const override { return ThreadState::contextId(); }
void setContextId(ContextID id) override { ThreadState::setContextId(id); }
O3ThreadContext on the other hand contains an O3ThreadState:
template <class Impl> struct O3ThreadState : public ThreadState
at:
template <class Impl>
class O3ThreadContext : public ThreadContext
{
O3ThreadState<Impl> *thread
ContextID contextId() const override { return thread->contextId(); }
void setContextId(ContextID id) override { thread->setContextId(id); }
24.22.6.3. gem5 ExecContext
ExecContext gets used in gem5 instruction definitions, e.g.:
build/ARM/arch/arm/generated/exec-ns.cc.inc
contains:
Fault Mul::execute(
ExecContext *xc, Trace::InstRecord *traceData) const
It contains methods to allow interacting with CPU state from inside instruction execution, notably reading and writing from/to registers.
For example, the ARM mul instruction uses ExecContext to read the input operands, multiply them, and write to the output:
Fault Mul::execute(
ExecContext *xc, Trace::InstRecord *traceData) const
{
Fault fault = NoFault;
uint64_t resTemp = 0;
resTemp = resTemp;
uint32_t OptCondCodesNZ = 0;
uint32_t OptCondCodesC = 0;
uint32_t OptCondCodesV = 0;
uint32_t Reg0 = 0;
uint32_t Reg1 = 0;
uint32_t Reg2 = 0;
OptCondCodesNZ = xc->readCCRegOperand(this, 0);
OptCondCodesC = xc->readCCRegOperand(this, 1);
OptCondCodesV = xc->readCCRegOperand(this, 2);
Reg1 =
((reg1 == PCReg) ? readPC(xc) : xc->readIntRegOperand(this, 3));
Reg2 =
((reg2 == PCReg) ? readPC(xc) : xc->readIntRegOperand(this, 4));
if (testPredicate(OptCondCodesNZ, OptCondCodesC, OptCondCodesV, condCode)/*auto*/)
{
Reg0 = resTemp = Reg1 * Reg2;;
if (fault == NoFault) {
{
uint32_t final_val = Reg0;
((reg0 == PCReg) ? setNextPC(xc, Reg0) : xc->setIntRegOperand(this, 0, Reg0));
if (traceData) { traceData->setData(final_val); }
};
}
} else {
xc->setPredicate(false);
}
return fault;
}
ExecContext is however basically just a wrapper that forwards to other classes that actually contain the data in a microarchitectural neutral manner. For example, in SimpleExecContext:
/** Reads an integer register. */
RegVal
readIntRegOperand(const StaticInst *si, int idx) override
{
numIntRegReads++;
const RegId& reg = si->srcRegIdx(idx);
assert(reg.isIntReg());
return thread->readIntReg(reg.index());
}
So we see that this just does some register position bookkeeping needed for instruction execution, but the actual data comes from SimpleThread::readIntReg, which is a specialization of gem5 ThreadContext.
ExecContext is a fully virtual class. The hierarchy is:
-
ExecContext-
SimpleExecContext -
Minor::MinorExecContext -
BaseDynInst-
BaseO3DynInst
-
-
If we follow SimpleExecContext creation for example, we see:
class BaseSimpleCPU : public BaseCPU
{
std::vector<SimpleExecContext*> threadInfo;
and:
BaseSimpleCPU::BaseSimpleCPU(BaseSimpleCPUParams *p)
: BaseCPU(p),
curThread(0),
branchPred(p->branchPred),
traceData(NULL),
inst(),
_status(Idle)
{
SimpleThread *thread;
for (unsigned i = 0; i < numThreads; i++) {
if (FullSystem) {
thread = new SimpleThread(this, i, p->system,
p->itb, p->dtb, p->isa[i]);
} else {
thread = new SimpleThread(this, i, p->system, p->workload[i],
p->itb, p->dtb, p->isa[i]);
}
threadInfo.push_back(new SimpleExecContext(this, thread));
ThreadContext *tc = thread->getTC();
threadContexts.push_back(tc);
}
therefore there is one ExecContext for each ThreadContext, and each ExecContext knows about its own ThreadContext.
This makes sense, since each ThreadContext represents one CPU register set, and therefore needs a separate ExecContext which allows instruction implementations to access those registers.
24.22.6.3.1. gem5 ExecContext::readIntRegOperand register resolution
Let’s have a look at how ExecContext::readIntRegOperand actually matches registers to decoded registers IDs, since it is not obvious.
Let’s study a simple aarch64 register register addition:
add x0, x1, x2
which corresponds to the AddXSReg instruction (formatted and simplified):
Fault AddXSReg::execute(ExecContext *xc, Trace::InstRecord *traceData) const {
uint64_t Op264 = 0;
uint64_t Dest64 = 0;
uint64_t Op164 = 0;
Op264 = ((xc->readIntRegOperand(this, 0)) & mask(intWidth));
Op164 = ((xc->readIntRegOperand(this, 1)) & mask(intWidth));
uint64_t secOp = shiftReg64(Op264, shiftAmt, shiftType, intWidth);
Dest64 = Op164 + secOp;
uint64_t final_val = Dest64;
xc->setIntRegOperand(this, 0, (Dest64) & mask(intWidth));
if (traceData) { traceData->setData(final_val); }
return NoFault;
}
So what are those magic 0 and 1 constants on xc→readIntRegOperand(this, 0) and xc→readIntRegOperand(this, 1)?
First, we guess that they must be related to the reading of x1 and x2, which are the inputs of the addition.
Next, we also guess that the 0 read must correspond to x2, since it later gets potentially shifted as mentioned at Section 30.4.4.1, “ARM shift suffixes”.
Let’s also have a look at the decoder code that builds the instruction instance in build/ARM/arch/arm/generated/decoder-ns.cc.inc:
ArmShiftType type =
(ArmShiftType)(uint8_t)bits(machInst, 23, 22);
if (type == ROR)
return new Unknown64(machInst);
uint8_t imm6 = bits(machInst, 15, 10);
if (!bits(machInst, 31) && bits(imm6, 5))
return new Unknown64(machInst);
IntRegIndex rd = (IntRegIndex)(uint8_t)bits(machInst, 4, 0);
IntRegIndex rdzr = makeZero(rd);
IntRegIndex rn = (IntRegIndex)(uint8_t)bits(machInst, 9, 5);
IntRegIndex rm = (IntRegIndex)(uint8_t)bits(machInst, 20, 16);
return new AddXSReg(machInst, rdzr, rn, rm, imm6, type);
and the ARM instruction pseudocode from the ARMv8 architecture reference manual:
ADD <Xd>, <Xn>, <Xm>{, <shift> #<amount>}
and the constructor:
AddXSReg::AddXSReg(ExtMachInst machInst,
IntRegIndex _dest,
IntRegIndex _op1,
IntRegIndex _op2,
int32_t _shiftAmt,
ArmShiftType _shiftType
) : DataXSRegOp("add", machInst, IntAluOp,
_dest, _op1, _op2, _shiftAmt, _shiftType) {
_numSrcRegs = 0;
_numDestRegs = 0;
_numFPDestRegs = 0;
_numVecDestRegs = 0;
_numVecElemDestRegs = 0;
_numVecPredDestRegs = 0;
_numIntDestRegs = 0;
_numCCDestRegs = 0;
_srcRegIdx[_numSrcRegs++] = RegId(IntRegClass, op2);
_destRegIdx[_numDestRegs++] = RegId(IntRegClass, dest);
_numIntDestRegs++;
_srcRegIdx[_numSrcRegs++] = RegId(IntRegClass, op1);
flags[IsInteger] = true;;
}
where RegId is just a container class, and so the lines that we care about for now are:
_srcRegIdx[_numSrcRegs++] = RegId(IntRegClass, op2); _srcRegIdx[_numSrcRegs++] = RegId(IntRegClass, op1);
which matches the guess we made earlier: op2 is 0 and op1 is 1 (op1 and op2 are the same as _op1 and _op2 which are set in the base constructor DataXSRegOp).
We also note that the register decodings (which the ARM spec says are 1 for x1 and 2 for x2) are actually passed as enum IntRegIndex:
IntRegIndex _op1,
IntRegIndex _op2,
which are defined at src/arch/arm/interegs.hh:
enum IntRegIndex
{
/* All the unique register indices. */
INTREG_R0,
INTREG_R1,
INTREG_R2,
Then SimpleExecContext::readIntRegOperand does:
/** Reads an integer register. */
RegVal
readIntRegOperand(const StaticInst *si, int idx) override
{
numIntRegReads++;
const RegId& reg = si->srcRegIdx(idx);
assert(reg.isIntReg());
return thread->readIntReg(reg.index());
}
and:
const RegId& srcRegIdx(int i) const { return _srcRegIdx[i]; }
which is what is populated in the constructor.
Then, RegIndex::index() { return regIdx; } just returns the decoded register bytes, and now SimpleThread::readIntReg:
RegVal readIntReg(RegIndex reg_idx) const override {
int flatIndex = isa->flattenIntIndex(reg_idx);
return readIntRegFlat(flatIndex);
}
readIntRegFlag is what finally reads from the int register array:
RegVal SimpleThreadContext::readIntRegFlat(RegIndex idx) const override { return intRegs[idx]; }
std::array<RegVal, TheISA::NumIntRegs> SimpleThreadContext::intRegs;
and then there is the flattening magic at:
int
flattenIntIndex(int reg) const
{
assert(reg >= 0);
if (reg < NUM_ARCH_INTREGS) {
return intRegMap[reg];
} else if (reg < NUM_INTREGS) {
return reg;
} else if (reg == INTREG_SPX) {
CPSR cpsr = miscRegs[MISCREG_CPSR];
ExceptionLevel el = opModeToEL(
(OperatingMode) (uint8_t) cpsr.mode);
if (!cpsr.sp && el != EL0)
return INTREG_SP0;
switch (el) {
case EL3:
return INTREG_SP3;
case EL2:
return INTREG_SP2;
case EL1:
return INTREG_SP1;
case EL0:
return INTREG_SP0;
default:
panic("Invalid exception level");
return 0; // Never happens.
}
} else {
return flattenIntRegModeIndex(reg);
}
}
Then:
NUM_ARCH_INTREGS = 32,
so we undertand that this covers x0 to x31. NUM_INTREGS is also 32, so I’m a bit confused, that case is never reached.
INTREG_SPX = NUM_INTREGS,
SP is 32, but it is a bit more magic, since in ARM there is one SP per exception level as mentioned at ARM SP0 vs SPx.
INTREG_SPX = NUM_INTREGS
We can also have a quick look at the AddXImm instruction which corresponds to a simple addition of an immediate as shown in userland/arch/aarch64/add.S:
add x0, x1, 2
Its execute method contains in build/ARM/arch/arm/generated/exec-ns.cc.inc (hand formatted and slightly simplified):
Fault AddXImm::execute(ExecContext *xc, Trace::InstRecord *traceData) const {
uint64_t Dest64 = 0;
uint64_t Op164 = 0;
Op164 = ((xc->readIntRegOperand(this, 0)) & mask(intWidth));
Dest64 = Op164 + imm;
uint64_t final_val = Dest64;
xc->setIntRegOperand(this, 0, (Dest64) & mask(intWidth));
if (traceData) { traceData->setData(final_val); }
return NoFault;
}
and imm is set directly on the constructor.
24.22.6.4. gem5 Process
The Process class is used only for gem5 syscall emulation mode, and it represents a process like a Linux userland process, in addition to any further gem5 specific data needed to represent the process.
The first thing most syscall implementations do is to actually pull Process out of gem5 ThreadContext, e.g.:
template <class OS>
SyscallReturn
readFunc(SyscallDesc *desc, ThreadContext *tc,
int tgt_fd, Addr buf_ptr, int nbytes)
{
auto p = tc->getProcessPtr();
For example, we can readily see from its interface that it contains several accessors for common process fields:
inline uint64_t uid() { return _uid; }
inline uint64_t euid() { return _euid; }
inline uint64_t gid() { return _gid; }
inline uint64_t egid() { return _egid; }
Process is a SimObject, and therefore produced directly in e.g. se.py.
se.py produces one process per-executable given:
workloads = options.cmd.split(';')
idx = 0
for wrkld in workloads:
process = Process(pid = 100 + idx)
and those are placed in the workload property:
for i in range(np):
if options.smt:
system.cpu[i].workload = multiprocesses
elif len(multiprocesses) == 1:
system.cpu[i].workload = multiprocesses[0]
else:
system.cpu[i].workload = multiprocesses[i]
and finally each thread of a CPU gets assigned to a different such workload:
BaseSimpleCPU::BaseSimpleCPU(BaseSimpleCPUParams *p)
: BaseCPU(p),
curThread(0),
branchPred(p->branchPred),
traceData(NULL),
inst(),
_status(Idle)
{
SimpleThread *thread;
for (unsigned i = 0; i < numThreads; i++) {
if (FullSystem) {
thread = new SimpleThread(this, i, p->system,
p->itb, p->dtb, p->isa[i]);
} else {
thread = new SimpleThread(this, i, p->system, p->workload[i],
p->itb, p->dtb, p->isa[i]);
}
threadInfo.push_back(new SimpleExecContext(this, thread));
ThreadContext *tc = thread->getTC();
threadContexts.push_back(tc);
}
24.22.7. gem5 functional units
Each instruction is marked with a class, and each class can execute in a given functional unit.
24.22.7.1. gem5 MinorCPU default functional units
Which units are available is visible for example on the gem5 config.ini of a gem5 MinorCPU run. Functional units are not present in simple CPUs like gem5 TimingSimpleCPU.
For example, on gem5 872cb227fdc0b4d60acc7840889d567a6936b6e1, the config.ini of a minor run:
./run \ --arch aarch64 \ --emulator gem5 \ --userland userland/arch/aarch64/freestanding/linux/hello.S \ --trace-insts-stdout \ -- \ --cpu-type MinorCPU \ --caches
contains:
[system.cpu] type=MinorCPU children=branchPred dcache dtb executeFuncUnits icache interrupts isa itb power_state tracer workload executeInputWidth=2 executeIssueLimit=2
Here also note the executeInputWidth=2 and executeIssueLimit=2 suggesting that this is a dual issue superscalar processor.
The system.cpu points to:
[system.cpu.executeFuncUnits] type=MinorFUPool children=funcUnits0 funcUnits1 funcUnits2 funcUnits3 funcUnits4 funcUnits5 funcUnits6 funcUnits7
and the two first units are in full:
[system.cpu.executeFuncUnits.funcUnits0] type=MinorFU children=opClasses timings opClasses=system.cpu.executeFuncUnits.funcUnits0.opClasses opLat=3 [system.cpu.executeFuncUnits.funcUnits0.opClasses] type=MinorOpClassSet children=opClasses [system.cpu.executeFuncUnits.funcUnits0.opClasses.opClasses] type=MinorOpClass opClass=IntAlu
and:
[system.cpu.executeFuncUnits.funcUnits1] type=MinorFU children=opClasses timings opLat=3 [system.cpu.executeFuncUnits.funcUnits1.opClasses] type=MinorOpClassSet children=opClasses opClasses=system.cpu.executeFuncUnits.funcUnits1.opClasses.opClasses [system.cpu.executeFuncUnits.funcUnits1.opClasses.opClasses] type=MinorOpClass opClass=IntAlu
So we understand that both:
-
the first and second functional units are
IntAlu, so doing integer arithmetic operations -
both have a latency of 3
-
each functional unit can have a set of
opClasswith more than one type. Those first two units just happen to have a single type.
The full list is:
-
0, 1:
IntAlu,opLat=3 -
2:
IntMult,opLat=3 -
3:
IntDiv,opLat=9. So we see that a more complex operation such as division has higher latency. -
4:
FloatAdd,FloatCmp, and a gazillion other floating point related things.opLat=6. -
5:
SimdPredAlu: TODO SVE-related?opLat=3 -
6:
MemRead,MemWrite,FloatMemRead,FloatMemWrite.opLat=1 -
7:
IprAccess(TODO),InstPrefetch
These are of course all specified in from the Python at src/cpu/minor/MinorCPU.py:
class MinorDefaultFUPool(MinorFUPool):
funcUnits = [MinorDefaultIntFU(), MinorDefaultIntFU(),
MinorDefaultIntMulFU(), MinorDefaultIntDivFU(),
MinorDefaultFloatSimdFU(), MinorDefaultPredFU(),
MinorDefaultMemFU(), MinorDefaultMiscFU()]
We then expect that each instruction has a certain opClass that determines on which unit it can run.
For example: class AddImm, which is what we get on a simple add x1, x2, 0, sets itself as an IntAluOp on the constructor as expected:
AddImm::AddImm(ExtMachInst machInst,
IntRegIndex _dest,
IntRegIndex _op1,
uint32_t _imm,
bool _rotC)
: DataImmOp("add", machInst, IntAluOp,
_dest, _op1, _imm, _rotC)
24.22.7.2. gem5 DerivO3CPU default functional units
On gem5 3ca404da175a66e0b958165ad75eb5f54cb5e772, after running:
./run \ --arch aarch64 \ --emulator gem5 \ --userland userland/arch/aarch64/freestanding/linux/hello.S \ --trace-insts-stdout \ -- \ --cpu-type Derivo3CPU \ --caches
we see:
[system.cpu] type=DerivO3CPU children=branchPred dcache dtb fuPool icache interrupts isa itb power_state tracer workload
and following fuPool:
[system.cpu.fuPool] type=FUPool children=FUList0 FUList1 FUList2 FUList3 FUList4 FUList5 FUList6 FUList7 FUList8 FUList9
so for example FUList0 is:
[system.cpu.fuPool.FUList0] type=FUDesc children=opList count=6 eventq_index=0 opList=system.cpu.fuPool.FUList0.opList [system.cpu.fuPool.FUList0.opList] type=OpDesc eventq_index=0 opClass=IntAlu opLat=1 pipelined=true
and FUList1:
[system.cpu.fuPool.FUList1.opList0] type=OpDesc eventq_index=0 opClass=IntMult opLat=3 pipelined=true [system.cpu.fuPool.FUList1.opList1] type=OpDesc eventq_index=0 opClass=IntDiv opLat=20 pipelined=false
So summarizing all units we have:
-
0, 1:
IntAluwithopLat=3 -
2:
IntMultwithopLat=3andIntDivwithopLat=20 -
3:
FloatAdd,FloatCmp,FloatCvtwithopLat=2 -
TODO lazy to finish the list :-)
24.22.8. gem5 code generation
gem5 uses a ton of code generation, which makes the project horrendous:
-
lots of magic happen on top of pybind11, which is already magic, to more automatically glue the C++ and Python worlds: gem5 Python C++ interaction
-
.isa code which describes most of the instructions: gem5 instruction definitions
-
Ruby for memory systems
To find files that are not symlinks use https://stackoverflow.com/questions/16303449/how-to-find-files-excluding-symbolic-links
find build -type f
To find the definition of generated code, do a:
grep -I -r build/ 'code of interest'
where:
-
-I: ignore binray file matches on built objects -
-r: ignore symlinks due to Why are all C++ symlinked into the gem5 build dir? as explained at https://stackoverflow.com/questions/21738574/how-do-you-exclude-symlinks-in-a-grep
The code generation exists partly to support insanely generic cross ISA instructions mapping to one compute model, where it might be reasonable.
But it has been widely overused to insanity. It likely also exists partly because when the project started in 2003 C++ compilers weren’t that good, so you couldn’t rely on features like templates that much.
24.22.8.1. gem5 THE_ISA
Generated code at: build/<ISA>/config/the_isa.hh which e.g. for ARM contains:
#ifndef __CONFIG_THE_ISA_HH__
#define __CONFIG_THE_ISA_HH__
#define ARM_ISA 1
#define MIPS_ISA 2
#define NULL_ISA 3
#define POWER_ISA 4
#define RISCV_ISA 5
#define SPARC_ISA 6
#define X86_ISA 7
enum class Arch {
ArmISA = ARM_ISA,
MipsISA = MIPS_ISA,
NullISA = NULL_ISA,
PowerISA = POWER_ISA,
RiscvISA = RISCV_ISA,
SparcISA = SPARC_ISA,
X86ISA = X86_ISA
};
#define THE_ISA ARM_ISA
#define TheISA ArmISA
#define THE_ISA_STR "arm"
#endif // __CONFIG_THE_ISA_HH__
Generation code: src/SConscript at def makeTheISA.
Tested on gem5 b1623cb2087873f64197e503ab8894b5e4d4c7b4.
24.22.9. gem5 build system
24.22.9.1. M5_OVERRIDE_PY_SOURCE
Running gem5 with the M5_OVERRIDE_PY_SOURCE=true environment variable allows you to modify a file under src/python and run it without rebuilding in gem5?
We set this environment variable by default in our run script.
How M5_OVERRID_PY_SOURCE works is shown at: gem5 m5.objects module.
24.22.9.2. gem5 build broken on recent compiler version
gem5 moves a bit slowly, and if your host compiler is very new, the gem5 build might be broken for it, e.g. this was the case for Ubuntu 19.10 with GCC 9 and gem5 62d75e7105fe172eb906d4f80f360ff8591d4178 from Dec 2019.
This happens mostly because GCC keeps getting more strict with warnings and gem5 uses -Werror.
The specific problem mentioned above was later fixed, but if it ever happens again, you can work around it by either by or by disabling -Werror:
./build-gem5 -- CCFLAGS=-Wno-error
or by installing an older compiler and using it with something like:
./build-gem5 -- CC=gcc-8 CXX=g++-8
24.22.9.3. gem5 polymorphic ISA includes
E.g. src/cpu/decode_cache.hh includes:
#include "arch/isa_traits.hh"
which in turn is meant to refer to files of form:
src/arch/<isa>/isa_traits.hh
What happens is that the build system creates a file:
build/ARM/arch/isa_traits.hh
which contains just:
#include "arch/arm/isa_traits.hh"
and puts that in the -I include path during build.
It appears to be possible to deal with it using preprocessor macros, but it is ugly: https://stackoverflow.com/questions/3178946/using-define-to-include-another-file-in-c-c/3179218#3179218
In addition to the header polymorphism, gem5 also namespaces classes with TheISA::, e.g. in src/cpu/decode_cache.hh:
Value items[TheISA::PageBytes];
which is defined at:
build/ARM/config/the_isa.hh
as:
#define TheISA ArmISA
and forces already arm/ specific headers to define their symbols under:
namespace ArmISA
so I don’t see the point of this pattern, why not just us PageBytes directly? Looks like a documentation mechanism to indicate that a certain symbol is ISA specific.
Tested in gem5 2a242c5f59a54bc6b8953f82486f7e6fe0aa9b3d.
24.22.9.4. Why are all C++ symlinked into the gem5 build dir?
Upstream request: https://gem5.atlassian.net/browse/GEM5-469
Some scons madness.
https://scons.org/doc/2.4.1/HTML/scons-user.html#idp1378838508 generates hard links by default.
Then the a5bc2291391b0497fdc60fdc960e07bcecebfb8f SConstruct use symlinks in a futile attempt to make things better for editors or build systems from the past century.
It was not possible to disable the symlinks automatically for the entire project when I last asked: https://stackoverflow.com/questions/53656787/how-to-set-disable-duplicate-0-for-all-scons-build-variants-without-repeating-th
The horrendous downsides of this are:
-
it is basically impossible to setup an IDE properly with gem5: gem5 Eclipse configuration
-
It is likely preventing ccache hits when building to different output paths, because it makes the
-Iincludes point to different paths. This is especially important for gem5 Ruby build, which could have the exact same source files as the non-Ruby builds: https://stackoverflow.com/questions/60340271/can-ccache-handle-symlinks-to-the-same-input-source-file-as-hits -
when debugging the emulator, it shows you directories inside the build directory rather than in the source tree
-
it is harder to separate which files are generated and which are in-tree when grepping for code generated definitions
25. Gensim
Source at: https://github.com/gensim-project/gensim previously at: https://bitbucket.org/gensim/gensim
MIT licensed Binary translation simulator, so a bit like an MIT QEMU.
Video showing it boot Linux fast: https://www.youtube.com/watch?v=aZXx17oYumc
Its name is unfortunately completely and totally overshadowed by an unrelated software with the sane name: https://radimrehurek.com/gensim/
TODO: advantages over QEMU. Like the name implies, they seem to have a nice ISA description language. From quick internals look, seems to generate LLVM intermediate language, which sound good.
Build on Ubuntu 20.04:
git submodule update --init submodules/gensim sudo apt install libantlr3c-dev cd submodule/gensim make
First fails with:
arm-none-eabi-gcc: error: unrecognized -march target: armv5
Let’s try just armv8, who cares about arvm5!!!
mkdir build cd build cmake -DTESTING_ENABLED=FALSE -DCMAKE_BUILD_TYPE=DEBUGOPT .. make -j`nproc` model-armv8
Now fails as mentioned at https://bitbucket.org/gensim/gensim/issues/34/build-fails-with-unrecognised-intrinsic:
terminate called after throwing an instance of 'std::logic_error' what(): Unrecognised intrinsic: __builtin_abs64 Aborted (core dumped)
Get the failing command with:
make VERBOSE=1 model-armv8
and we see some code generation step:
cd /home/ciro/bak/git/linux-kernel-module-cheat/submodules/gensim/models/armv8 && \ /home/ciro/bak/git/linux-kernel-module-cheat/submodules/gensim/build/dist/bin/gensim \ -a /home/ciro/bak/git/linux-kernel-module-cheat/submodules/gensim/models/armv8/aarch64.ac \ -s module,arch,decode,disasm,ee_interp,ee_blockjit,jumpinfo,function,makefile \ -o decode.GenerateDotGraph=1,makefile.libtrace_path=/home/ciro/bak/git/linux-kernel-module-cheat/submodules/gensim/support/libtrace/inc,makefile.archsim_path=/home/ciro/bak/git/linux-kernel-module-cheat/submodules/gensim/archsim/inc,makefile.llvm_path=,makefile.Optimise=2,makefile.Debug=1 \ -t /home/ciro/bak/git/linux-kernel-module-cheat/submodules/gensim/build/models/armv8/output-aarch64/
We can see an inclusion path:
gensim/models/armv8/aarch64.ac
ac_isa("isa.ac");
gensim/models/armv8/isa.ac
ac_execute("execute.simd");
and where gensim/models/armv8/isa.ac contains __builtin_abs64 usages.
Rebuilding with -DCMAKE_BUILD_TYPE=DEBUG + GDB on gensim shows that the error comes from a call to gci.GenerateExecuteBodyFor(body_str, *action);, so it looks like there are some missing cases in gensim/src/generators/GenCInterpreter/InterpreterNodeWalker.cpp function SSAIntrinsicStatementWalker::EmitFixedCode, e.g. there should be one for __builtin_abs64.
This is completely broken academic code! They must be using an off-tree of part of the tool and forgot to commit.
26. Buildroot
26.1. Introduction to Buildroot
Buildroot is a set of Make scripts that download and compile from source compatible versions of:
-
GCC
-
Linux kernel
-
C standard library: Buildroot supports several implementations, see: Section 26.10, “libc choice”
-
BusyBox: provides the shell and basic command line utilities
It therefore produces a pristine, blob-less, debuggable setup, where all moving parts are configured to work perfectly together.
Perhaps the awesomeness of Buildroot only sinks in once you notice that all it takes is 4 commands as explained at Section 26.11, “Buildroot hello world”.
The downsides of Buildroot are:
-
the first build takes a while compared to downloading prebuilts, but it is well worth it
-
the selection of software packages is relatively limited if compared to Debian.
In theory, any software can be packaged, and the Buildroot side is easy.
The hard part is dealing with crappy third party build systems and huge dependency chains.
-
it is written in Make and Bash rather than Python like LKMC
-
it downloads packages from upstream mirrors rather than having its own copy of them. Therefore, whenever some random French research institute decides to break links, your build also breaks. This is not acceptable. There are some mirroring options: https://risc-a-day.blogspot.com/2015/10/creating-local-mirror-for-buildroot.html but it’s not on by default it seems, Buildroot has to have their own official and default mirror of everything.
This repo basically wraps around that, and tries to make everything even more awesome for kernel developers by adding the capability of seamlessly running the stuff you’ve built on emulators usually via ./run.
This runnable part of selecting the command line options for different emulators and setups is to a large extent what Libvirt does. But we feel that having both build and run on the same repository is the key.
As this repo develops however, we’ve started taking some of the build out of Buildroot, e.g. notably the Linux kernel to have more build flexibility and faster build startup times.
Therefore, more and more, this repo wants to take over everything that Buildroot does, and one day completely replace it to achieve emulation Nirvana, see e.g.:
26.2. Custom Buildroot configs
We provide the following mechanisms:
-
./build-buildroot --config-fragment data/br2: append the Buildroot configuration filedata/br2to a single build. Must be passed every time you run./build. The format is the same as buildroot_config/default. -
./build-buildroot --config 'BR2_SOME_OPTION="myval"': append a single option to a single build.
For example, if you decide to Enable Buildroot compiler optimizations after an initial build is finished, you must Clean the build and rebuild:
./build-buildroot \ --config 'BR2_OPTIMIZE_3=y' \ --config 'BR2_PACKAGE_SAMPLE_PACKAGE=y' \ -- sample_package-dirclean \ sample_package-reconfigure \ ;
as explained at: https://buildroot.org/downloads/manual/manual.html#rebuild-pkg
The clean is necessary because the source files didn’t change, so make would just check the timestamps and not build anything.
You will then likely want to make those more permanent as explained at: Section 38.4, “Default command line arguments”.
26.2.1. Enable Buildroot compiler optimizations
If you are benchmarking compiled programs instead of hand written assembly, remember that we configure Buildroot to disable optimizations by default with:
BR2_OPTIMIZE_0=y
to improve the debugging experience.
You will likely want to change that to:
BR2_OPTIMIZE_3=y
Our buildroot_packages/sample_package package correctly forwards the Buildroot options to the build with $(TARGET_CONFIGURE_OPTS), so you don’t have to do any extra work.
Don’t forget to do that if you are adding a new package with your own build system.
Then, you have two choices:
-
if you already have a full
-O0build, you can choose to rebuild just your package of interest to save some time as described at: Section 26.2, “Custom Buildroot configs”./build-buildroot \ --config 'BR2_OPTIMIZE_3=y' \ --config 'BR2_PACKAGE_SAMPLE_PACKAGE=y' \ -- \ sample_package-dirclean \ sample_package-reconfigure \ ;
However, this approach might not be representative since calls to an unoptimized libc and other libraries will have a negative performance impact.
Maybe you can get away with rebuilding libc, but I’m not sure that it will work properly.
Kernel-wise it should be fine though as mentioned at: Section 3.1.2, “Disable kernel compiler optimizations”
-
clean the build and rebuild from scratch:
mv out out~ ./build-buildroot --config 'BR2_OPTIMIZE_3=y'
26.3. Find Buildroot options with make menuconfig
make menuconfig is a convenient way to find Buildroot configurations:
cd "$(./getvar buildroot_build_dir)" make menuconfig
Hit / and search for the settings.
Save and quit.
diff -u .config.olg .config
Then copy and paste the diff additions to buildroot_config/default to make them permanent.
26.4. Change user
At startup, we login automatically as the root user.
If you want to switch to another user to test some permissions, we have already created an user0 user through the user_table file, and you can just login as that user with:
login user0
and password:
a
Then test that the user changed with:
id
which gives:
uid=1000(user0) gid=1000(user0) groups=1000(user0)
26.4.1. Login as a non-root user without password
Replace on inittab:
::respawn:-/bin/sh
with:
::respawn:-/bin/login -f user0
-f forces login without asking for the password.
26.5. Add new files to the Buildroot image
These are your options:
-
create a Buildroot package: Add new Buildroot packages
This is the most general option, but the most laborious. No big deal if you copy our template however as shown in that section.
Handles any type of cross compilation, including multiple input sources.
-
drop your files directly in rootfs_overlay and follow instructions from that section.
Files in that directory are directly copied to the image, so this is the best option for files that don’t need to be compiled such as Interpreted languages.
You could also use this method to inject compiled binaries into the image for quick-and-dirty testing.
But it will be much more likely to work if you use our cross compiler with run-toolchain or getvar.
If you can’t do that, at the very least make it statically with
-staticcompiled to remove the possibility of binary mismatch with our dynamic glibc.But things can still break if your random glibc is configured to work with a newer Linux kernel than ours.
It often just works even if they are not perfectly matched however, partly because the Linux kernel is highly backwards compatible
-
fork this repo and add new files to userland/ or kernel_modules/
To add a simple executable that compiles from a single source file, like the dozens of examples that we have, you could just go this route.
This mechanisms bypasses having to create/modify Buildroot packages, and is very simple when you have a single input single output executable.
-
9P. OK, this is not really adding to the image, but it is the most convenient way to quickly modify a binary on the host, cross compile, and test it out without rebooting.
Related threads:
26.5.1. Add new Buildroot packages
First, see if you can’t get away without actually adding a new package, for example:
-
if you have a standalone C file with no dependencies besides the C standard library to be compiled with GCC, just add a new file under buildroot_packages/sample_package and you are done
-
if you have a dependency on a library, first check if Buildroot doesn’t have a package for it already with
ls buildroot/package. If yes, just enable that package as explained at: Section 26.2, “Custom Buildroot configs”
If none of those methods are flexible enough for you, you can just fork or hack up buildroot_packages/sample_package the sample package to do what you want.
For how to use that package, see: Section 38.15.2, “buildroot_packages directory”.
Then iterate trying to do what you want and reading the manual until it works: https://buildroot.org/downloads/manual/manual.html
26.6. Remove Buildroot packages
Once you’ve built a package in to the image, there is no easy way to remove it.
26.7. BR2_TARGET_ROOTFS_EXT2_SIZE
When adding new large package to the Buildroot root filesystem, it may fail with the message:
Maybe you need to increase the filesystem size (BR2_TARGET_ROOTFS_EXT2_SIZE)
The solution is to simply add:
./build-buildroot --config 'BR2_TARGET_ROOTFS_EXT2_SIZE="512M"'
where 512Mb is "large enough".
Note that dots cannot be used as in 1.5G, so just use Megs as in 1500M instead.
Unfortunately, TODO we don’t have a perfect way to find the right value for BR2_TARGET_ROOTFS_EXT2_SIZE. One good heuristic is:
du -hsx "$(./getvar --arch arm buildroot_target_dir)"
Some promising ways to overcome this problem include:
-
SquashFS TODO benchmark: would gem5 suffer a considerable disk read performance hit due to decompressing SquashFS?
-
libguestfs: https://serverfault.com/questions/246835/convert-directory-to-qemu-kvm-virtual-disk-image/916697#916697, in particular
vfs-minimum-size -
use methods described at: Section 24.6.3, “gem5 checkpoint restore and run a different script” instead of putting builds on the root filesystem
Bibliography: https://stackoverflow.com/questions/49211241/is-there-a-way-to-automatically-detect-the-minimum-required-br2-target-rootfs-ex
26.7.1. SquashFS
SquashFS creation with mksquashfs does not take fixed sizes, and I have successfully booted from it, but it is readonly, which is unacceptable.
But then we could mount ramfs on top of it with OverlayFS to make it writable, but my attempts failed exactly as mentioned at OverlayFS.
This is the exact unanswered question: https://unix.stackexchange.com/questions/343484/mounting-squashfs-image-with-read-write-overlay-for-rootfs
26.8. Buildroot rebuild is slow when the root filesystem is large
Buildroot is not designed for large root filesystem images, and the rebuild becomes very slow when we add a large package to it.
This is due mainly to the pkg-generic GLOBAL_INSTRUMENTATION_HOOKS sanitation which go over the entire tree doing complex operations… I no like, in particular check_bin_arch and check_host_rpath
We have applied 983fe7910a73923a4331e7d576a1e93841d53812 to out Buildroot fork which removes part of the pain by not running:
>>> Sanitizing RPATH in target tree
which contributed to a large part of the slowness.
Test how Buildroot deals with many files with:
./build-buildroot \ --config 'BR2_PACKAGE_LKMC_MANY_FILES=y' \ -- \ lkmc_many_files-reconfigure \ |& \ ts -i '%.s' \ ; ./build-buildroot |& ts -i '%.s'
and notice how the second build, which does not rebuilt the package at all, still gets stuck in the RPATH check forever without our Buildroot patch.
26.9. Report upstream bugs
When asking for help on upstream repositories outside of this repository, you will need to provide the commands that you are running in detail without referencing our scripts.
For example, QEMU developers will only want to see the final QEMU command that you are running.
For the configure and build, search for the Building and Configuring parts of the build log, then try to strip down all Buildroot related paths, to keep only options that seem to matter.
We make that easy by building commands as strings, and then echoing them before evaling.
So for example when you run:
./run --arch arm
the very first stdout output of that script is the actual QEMU command that is being run.
The command is also saved to a file for convenience:
cat "$(./getvar --arch arm run_cmd_file)"
which you can manually modify and execute during your experiments later:
vim "$(./getvar --arch arm run_cmd_file)" ./"$(./getvar --arch arm run_cmd_file)"
If you are not already on the master of the given component, you can do that neatly with Build variants.
E.g., to check if a QEMU bug is still present on master, you can do as explained at QEMU build variants:
git -C "$(./getvar qemu_source_dir)" checkout master ./build-qemu --clean --qemu-build-id master ./build-qemu --qemu-build-id master git -C "$(./getvar qemu_source_dir)" checkout - ./run --qemu-build-id master
Then, you will also want to do a Bisection to pinpoint the exact commit to blame, and CC that developer.
Finally, give the images you used save upstream developers' time as shown at: Section 38.19.2, “release-zip”.
For Buildroot problems, you should wither provide the config you have:
./getvar buildroot_config_file
or try to reproduce with a minimal config, see: https://github.com/cirosantilli/buildroot/tree/in-tree-package-master
26.10. libc choice
Buildroot supports several libc implementations, including:
We currently use glibc, which is selected by:
BR2_TOOLCHAIN_BUILDROOT_GLIBC=y
Ideally we would like to use uClibc, as it is more minimal and easier to understand, but unfortunately there are some very few packages that use some weird glibc extension that uClibc hasn’t implemented yet, e.g.:
-
SELinux. Trivial unmerged fix at: http://lists.busybox.net/pipermail/buildroot/2017-July/197793.html just missing the uClibc option to expose
fts.h…
The full list of unsupported packages can be found by grepping the Buildroot source:
git -C "$(./getvar buildroot_source_dir)" grep 'depends on BR2_TOOLCHAIN_USES_GLIBC'
One "downside" of glibc is that it exercises much more kernel functionality on its more bloated pre-main init, which breaks user mode C hello worlds more often, see: Section 11.4, “User mode simulation with glibc”. I quote "downside" because glibc is actually exposing emulator bugs which we should actually go and fix.
26.11. Buildroot hello world
This repo doesn’t do much more other than setting a bunch of Buildroot configurations and building it.
The minimal work you have to do to get QEMU to boot Buildroot from scratch is tiny if, about 4 commands!
Here are some good working commands for several ISAs:
-
-
aarch64 U-Boot: https://stackoverflow.com/questions/58028789/how-to-boot-linux-aarch64-with-u-boot-with-buildroot-on-qemu Also mentioned at: U-Boot.
-
-
PPC https://stackoverflow.com/questions/48021127/build-powerpc-kernel-and-boot-powerpc-kernel-on-qemu/49349262#49349262 just work commands for PPC, comment on how to replace kernel
These can come in handy if you want to debug something in Buildroot itself and possibly report an upstream bug.
26.12. Update the Buildroot toolchain
Users of this repo will often want to update the compilation toolchain to the latest version to get fresh new features like new ISA instructions.
Because the toolchain is so complex and tightly knitted with the rest of the system, this is more of an art than a science.
However, it is not something to be feared, and you will get there without help in most cases.
In this section we cover the most common cases.
26.12.1. Update GCC: GCC supported by Buildroot
This is of course the simplest case.
You can quickly determine all the GCC versions supported by Buildroot by looking at:
submodules/buildroot/package/gcc/Config.in.host
For example, in Buildroot 2018.08, which was used at LKMC 5d10529c10ad8a4777b0bac1543320df0c89a1ce, the default toolchain was 7.3.0, and the latest supported one was 8.2.0.
To just upgrade the toolchain to 8.2.0, and rebuild some userland executables to later run them, we could do:
cd submodules/gcc git fetch up git checkout -b lkmc-gcc-8_2_0-release gcc-8_2_0-release git am ../buildroot/package/gcc/8.2.0/* cd ../.. ./build-buildroot \ --arch aarch64 \ --buildroot-build-id gcc-8-2 \ --config 'BR2_GCC_VERSION_8_X=y' \ --config 'BR2_GCC_VERSION="8.2.0"' \ --no-all \ -- \ toolchain \ ; ./build-userland \ --arch aarch64 \ --buildroot-build-id gcc-8-2 \ --out-rootfs-overlay-dir-prefix gcc-8-2 \ --userland-build-id gcc-8-2 \ ; ./build-buildroot --arch aarch64
where the toolchain Buildroot target builds only Buildroot: https://stackoverflow.com/questions/44521150/buildroot-install-and-build-the-toolchain-only
Note that this setup did not overwrite any of our default Buildroot due to careful namespacing with our gcc-8-2 prefix!
Now you can either run the executables on User mode simulation with:
./run --arch aarch64 --userland userland/c/hello.c --userland-build-id gcc-8-2
or in full system with:
./run --arch aarch64 --eval-after './gcc-8-2/c/hello.out'
where the gcc-8-2 prefix was added by --out-rootfs-overlay-dir-prefix.
ARM SVE support was only added to GCC 8 and can be enabled with the flag: -march=armv8.2-a+sve.
We already even had a C SVE test in-tree, but it was disabled because the old toolchain does not support it.
So once the new GCC 8 toolchain was built, we can first enable that test by editing the path_properties.py file to not skip C SVE tests anymore:
#os.path.splitext(self.path_components[-1])[1] == '.c' and self['arm_sve']
and then rebuild run one of the experiments from Change ARM SVE vector length in emulators:
./build-userland \ --arch aarch64 \ --buildroot-build-id gcc-8-2 \ --force-rebuild \ --march=armv8.2-a+sve \ --out-rootfs-overlay-dir-prefix gcc-8-2 \ --static \ --userland-build-id gcc-8-2 \ ; ./run \ --arch aarch64 \ --userland userland/arch/aarch64/inline_asm/sve_addvl.c \ --userland-build-id gcc-8-2 \ --static \ --gem5-worktree master \ -- \ --param 'system.cpu[:].isa[:].sve_vl_se = 4' \
Bibliography:
26.12.2. Update GCC: GCC not supported by Buildroot
Now it gets fun, but well, guess what, we will try to do the same as Section 26.12.1, “Update GCC: GCC supported by Buildroot” but:
-
pick the Buildroot version that comes closest to the GCC you want
-
if any
git ampatches don’t apply, skip them
Now, if things fail, you can try:
-
if the GCC version is supported by a newer Buildroot version:
-
quick and dirty: see what they are doing differently there, and patch it in here
-
golden star: upgrade our default Buildroot, test it well, and send a pull request!
-
-
otherwise: OK, go and patch Buildroot, time to become a Buildroot dev
Known setups:
-
Buildroot 2018.08:
-
GCC 8.3.0: OK
-
GCC 9.2.0: KO https://github.com/cirosantilli/linux-kernel-module-cheat/issues/97
-
26.13. Buildroot vanilla kernel
By default, our build system uses build-linux, and the Buildroot kernel build is disabled: https://stackoverflow.com/questions/52231793/can-buildroot-build-the-root-filesystem-without-building-the-linux-kernel
There are however some cases where we want that ability, e.g.: kernel_modules buildroot package and Benchmark Linux kernel boot.
The build of the kernel can be enabled with the --build-kernel option of build-buildroot.
For example, to build the kernel and then boot it you could do:
./build-buildroot --arch aarch64 --build-linux ./run --arch aarch64 --linux-exec "$(./getvar --arch aarch64 TODO)/vmlinux"
TODO: fails on LKMC d53ffcff18aa26d24ea34b86fb80e4a5694378dch with "ERROR: No hash found for linux-4.19.16.tar.xz": https://github.com/cirosantilli/linux-kernel-module-cheat/issues/115
Note that this kernel is not configured at all by LKMC, and there is no support to do that currently: the Buildroot default kernel configs for a target are used unchanged, e.g. make qemu_aarch64_virt_defconfig,see also; About Buildroot’s kernel configs.
Therefore, this kernel might be missing certain key capabilities, e.g. filesystem support required to boot.
27. Userland content
This section documents our test and educational userland content, such as C, C++ and POSIX examples, present mostly under userland/.
Getting started at: Section 2.8, “Userland setup”
Userland assembly content is located at: Section 28, “Userland assembly”. It was split from this section basically because we were hitting the HTML h6 limit, stupid web :-)
This content makes up the bulk of the userland/ directory.
The quickest way to run the arch agnostic examples, which comprise the majority of the examples, is natively as shown at: Section 2.8.2.1, “Userland setup getting started natively”
This section was originally moved in here from: https://github.com/cirosantilli/cpp-cheat
27.1. build-userland
Build userland programs.
Build all with:
./build-userland
or build only those under e.g. userland/c with:
./build-userland userland/c
The executables are not automatically added to the Buildroot image, you must follow the command with a ./build-buildroot command as in:
./build-userland ./build-buildroot
Remember that certain executables have specific requirements, e.g.:
-
userland/arch/ programs only build if the target arch matches
-
userland/libs directory require the
--packageoption userland/libs directory
Default: build all examples that have their package dependencies met, e.g.:
-
an OpenBLAS example can only be built if the target root filesystem has the OpenBLAS libraries and headers installed, which you must inform with --package
27.2. C
Programs under userland/c/ are examples of ANSI C programming:
-
mainand environment-
userland/c/command_line_arguments.c: print one command line argument per line using
argcandargv.Good sanity check for user mode: QEMU user mode getting started
-
Standard library
-
assert.h -
stdlib.h-
exit
-
-
stdio.h-
File IO
-
-
userland/c/cat.c: a quick and dirty
catimplementation for interactive User mode simulation tests
-
-
userland/linux/open_o_tmpfile.c: https://stackoverflow.com/questions/4508998/what-is-an-anonymous-inode-in-linux/44388030#44388030
-
-
time.h-
userland/c/timespec_get.c
timespec_getis a C11 forclock_gettimehttp://stackoverflow.com/questions/361363/how-to-measure-time-in-milliseconds-using-ansi-c/36095407#36095407
-
-
-
Fun
27.2.1. malloc
Allocate memory! Vs using the stack: https://stackoverflow.com/questions/4584089/what-is-the-function-of-the-push-pop-instructions-used-on-registers-in-x86-ass/33583134#33583134
userland/c/malloc.c: malloc hello world: allocate two ints and use them.
Linux 5.1 / glibc 2.29 implements it with the mmap system call.
malloc leads to the infinite joys of Memory leaks.
27.2.1.1. malloc implementation
TODO: the exact answer is going to be hard.
But at least let’s verify that large malloc calls use the mmap syscall with:
strace -x ./c/malloc_size.out 0x100000 2>&1 | grep mmap | tail -n 1 strace -x ./c/malloc_size.out 0x200000 2>&1 | grep mmap | tail -n 1 strace -x ./c/malloc_size.out 0x400000 2>&1 | grep mmap | tail -n 1
Source: userland/c/malloc_size.c.
From this we sese that the last mmap calls are:
mmap(NULL, 1052672, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7ffff7ef2000 mmap(NULL, 2101248, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7ffff7271000 mmap(NULL, 4198400, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7ffff7071000
which in hex are:
printf '%x\n' 1052672 # 101000 printf '%x\n' 2101248 # 201000 printf '%x\n' 4198400 # 401000
so we figured out the pattern: those 1, 2, and 4 MiB mallocs are mmaping N + 0x1000 bytes.
27.2.1.2. malloc maximum size
General overview at: https://stackoverflow.com/questions/2798330/maximum-memory-which-malloc-can-allocate
See also:
From Memory size and ./run --help, we see that at we set the emulator memory by default to 256MB. Let’s see how much Linux allows us to malloc.
Then from malloc implementation we see that malloc is implemented with mmap. Therefore, let’s simplify the problam and try to understand what is the larges mmap we can do first. This way we can ignore how glibc implements malloc for now.
In Linux, the maximum mmap value in controlled by:
cat /proc/sys/vm/overcommit_memory
which is documented in man proc.
The default value is 0, which I can’t find a precise documentation for. 2 is precisely documented but I’m lazy to do all calculations. So let’s just verify 0 vs 1 by trying to mmap 1GiB of memory:
echo 0 > /proc/sys/vm/overcommit_memory ./linux/mmap_anonymous.out 0x40000000 echo 1 > /proc/sys/vm/overcommit_memory ./linux/mmap_anonymous.out 0x40000000
Source: userland/linux/mmap_anonymous.c
With 0, we get a failure:
mmap: Cannot allocate memory
but with 1 the allocation works.
We are allowed to allocate more than the actual memory + swap because the memory is only virtual, as explained at: https://stackoverflow.com/questions/7880784/what-is-rss-and-vsz-in-linux-memory-management/57453334#57453334
If we start using the pages, the OOM killer would sooner or later step in and kill our process: Linux out-of-memory killer.
27.2.1.2.1. Linux out-of-memory killer
We can observe the OOM in LKMC 1e969e832f66cb5a72d12d57c53fb09e9721d589 which defaults to 256MiB of memory with:
echo 1 > /proc/sys/vm/overcommit_memory ./linux/mmap_anonymous_touch.out 0x40000000 0x8000000
This first allows memory overcommit so to that the program can mmap 1GiB, 4x more than total RAM without failing as mentioned at malloc maximum size.
It then walks over every page and writes a value in it to ensure that it is used.
A Fork bomb is another example that can trigger the OOM killer.
Algorithm used by the OOM: https://unix.stackexchange.com/questions/153585/how-does-the-oom-killer-decide-which-process-to-kill-first
27.2.2. C multithreading
Added in C11!
Bibliography:
27.2.2.1. atomic.c
-
userland/c/atomic/: files in this directory use the same technique as atomic.cpp, i.e. with one special case per file.
Maybe userland/c/atomic.c should be deprecated in favor of those more minimal ones.
This was added because C++-pre main is too bloated, especially when we turn one a gazillion gem5 logs, it makes me want to cry.
And we want a single operation per test rather than to as in
atomic.cbecause when using gem5 we want absolute control over the microbenchmark.
Demonstrates atomic_int and thrd_create.
Disassembly with GDB at LKMC 619fef4b04bddc4a5a38aec5e207dd4d5a25d206 + 1:
./disas --arch aarch64 --userland userland/c/atomic.c my_thread_main
shows on ARM:
16 ++cnt; 0x00000000004008cc <+28>: 80 00 00 b0 adrp x0, 0x411000 <malloc@got.plt> 0x00000000004008d0 <+32>: 00 80 01 91 add x0, x0, #0x60 0x00000000004008d4 <+36>: 00 00 40 b9 ldr w0, [x0] 0x00000000004008d8 <+40>: 01 04 00 11 add w1, w0, #0x1 0x00000000004008dc <+44>: 80 00 00 b0 adrp x0, 0x411000 <malloc@got.plt> 0x00000000004008e0 <+48>: 00 80 01 91 add x0, x0, #0x60 0x00000000004008e4 <+52>: 01 00 00 b9 str w1, [x0] 17 ++acnt; 0x00000000004008e8 <+56>: 20 00 80 52 mov w0, #0x1 // #1 0x00000000004008ec <+60>: e0 1b 00 b9 str w0, [sp, #24] 0x00000000004008f0 <+64>: e0 1b 40 b9 ldr w0, [sp, #24] 0x00000000004008f4 <+68>: e2 03 00 2a mov w2, w0 0x00000000004008f8 <+72>: 80 00 00 b0 adrp x0, 0x411000 <malloc@got.plt> 0x00000000004008fc <+76>: 00 70 01 91 add x0, x0, #0x5c 0x0000000000400900 <+80>: 03 00 e2 b8 ldaddal w2, w3, [x0] 0x0000000000400904 <+84>: 61 00 02 0b add w1, w3, w2 0x0000000000400908 <+88>: e0 03 01 2a mov w0, w1 0x000000000040090c <+92>: e0 1f 00 b9 str w0, [sp, #28]
so:
With -O3:
16 ++cnt; 0x0000000000400a00 <+32>: 60 00 40 b9 ldr w0, [x3] 0x0000000000400a04 <+36>: 00 04 00 11 add w0, w0, #0x1 0x0000000000400a08 <+40>: 60 00 00 b9 str w0, [x3] 17 ++acnt; 0x0000000000400a0c <+44>: 20 00 80 52 mov w0, #0x1 // #1 0x0000000000400a10 <+48>: 40 00 e0 b8 ldaddal w0, w0, [x2]
so the situation is the same but without all the horrible stack noise.
27.2.3. GCC C extensions
27.2.3.2. OpenMP
GCC implements the OpenMP threading implementation: https://stackoverflow.com/questions/3949901/pthreads-vs-openmp
Example: userland/gcc/openmp.c
The implementation is built into GCC itself. It is enabled at GCC compile time by BR2_GCC_ENABLE_OPENMP=y on Buildroot, and at program compile time by -fopenmp.
It seems to be easier to use for compute parallelism and more language agnostic than POSIX threads.
pthreads are more versatile though and allow for a superset of OpenMP.
The implementation lives under libgomp in the GCC tree, and is documented at: https://gcc.gnu.org/onlinedocs/libgomp/
strace shows that OpenMP makes clone() syscalls in Linux. TODO: does it actually call pthread_ functions, or does it make syscalls directly? Or in other words, can it work on Freestanding programs? A quick grep shows many references to pthreads.
27.3. C++
Programs under userland/cpp/ are examples of ISO C programming.
-
iostream
-
userland/cpp/copyfmt.cpp:
std::copyfmtrestores stream state, see also: https://stackoverflow.com/questions/12560291/set-back-default-floating-point-print-precision-in-c/53673686#53673686
-
-
fstream
-
userland/cpp/temporary_directory.cpp: illustrates
std::filesystem::temp_directory_pathand answers https://stackoverflow.com/questions/3379956/how-to-create-a-temporary-directory-in-c/58454949#58454949
-
random
-
containers
-
associative
-
userland/cpp/set.cpp:
std::setcontains unique keys -
userland/cpp/map.cpp:
std::map -
userland/cpp/multimap.cpp:
std::multimap
-
-
Algorithms contains a benchmark comparison of different c++ containers
-
27.3.1. C++ classes
27.3.1.1. C++ constructor
-
userland/cpp/initializer_list_constructor.cpp: documents stuff like
std::vector<int> v{0, 1};andstd::initializer_list -
userland/cpp/most_vexing_parse.cpp: the most vexing parse is a famous constructor vs function declaration syntax gotcha!
-
virtualand polymorphism
27.3.1.1.1. C++ rule of five
Output Ubuntu 20.04 GCC 9.3:
constructor? constructor copy? constructor copy copy assignment? constructor copy assignment constructor copy move assignment destructor move? constructor move? constructor constructor move assignment destructor a bunch of destructors? destructor destructor destructor destructor destructor
27.3.2. C++ standards
Like for C, you have to pay for the standards… insane. So we just use the closest free drafts instead.
27.3.3. C++ initialization types
OMG this is hell, understand when primitive variables are initialized or not:
Intuition:
-
direct initialization: a constructor called explicitly with at least one argument: https://en.cppreference.com/w/cpp/language/direct_initialization
-
default initialization: does not initialize primitive types: https://en.cppreference.com/w/cpp/language/default_initialization
-
value initialization: maybe initializes primitive types: https://en.cppreference.com/w/cpp/language/value_initialization
-
zero initialization: initializes primitive types
Good rule:
-
initialize every single variable explicitly to prevent the risk of having uninitialized variables due to programmer error (which is easy to get wrong due to insane rules)
-
if you don’t define your own default constructor, always
= deleteit instead. This prevents the possibility that variables will be assigned twice due to zero initialization
27.3.4. C++ multithreading
-
-
userland/cpp/count.cpp Exemplifies:
std::this_thread::sleep_for -
userland/cpp/thread_hardware_concurrency.cpp
std::thread::hardware_concurrency -
userland/cpp/thread_get_id.cpp
std::thread::get_id -
userland/cpp/thread_return_value.cpp: how to return a value from a thread
-
-
<atomic>: C++17 N4659 standards draft 32 "Atomic operations library"
27.3.4.1. atomic.cpp
C version at: atomic.c.
In this set of examples, we exemplify various synchronization mechanisms, including assembly specific ones, by using the convenience of C++ multithreading:
-
userland/cpp/atomic/main.hpp: contains all the code which is then specialized in separated
.cppfiles with macros -
userland/cpp/atomic/aarch64_add.cpp: non synchronized aarch64 inline assembly
-
userland/cpp/atomic/aarch64_ldaxr_stlxr.cpp: see: ARM LDXR and STXR instructions
-
userland/cpp/atomic/aarch64_ldadd.cpp: synchronized aarch64 inline assembly with the ARM Large System Extensions (LSE) LDADD instruction
-
userland/cpp/atomic/fail.cpp: non synchronized C operator ``
-
userland/cpp/atomic/mutex.cpp: synchronized
std::mutex.std; -
userland/cpp/atomic/std_atomic.cpp: synchronized
std::atomic_ulong -
userland/cpp/atomic/x86_64_inc.cpp: non synchronized x86_64 inline assembly
-
userland/cpp/atomic/x86_64_lock_inc.cpp: synchronized x86_64 inline assembly with the x86 LOCK prefix
All examples do exactly the same thing: span N threads and loop M times in each thread incrementing a global integer.
For inputs large enough, the non-synchronized examples are extremely likely to produce "wrong" results, for example on 2017 Lenovo ThinkPad P51 Ubuntu 19.10 native with 2 threads and 10000 loops:
./fail.out 2 10000
we could get an output such as:
expect 20000 global 12676
The actual value is much smaller, because the threads have often overwritten one another with older values.
With --optimization-level 3, the result almost always equals that of a single thread, e.g.:
./build --optimization-level 3 --force-rebuild fail.cpp ./fail.out 4 1000000
usually gives:
expect 40000 global 10000
This is because now, instead of the horribly inefficient -O0 assembly that reads global from memory every time, the code:
-
reads
globalto a register -
increments the register
-
at end the end, the resulting value of each thread gets written back, overwriting each other with the increment of each thread
The -O0 code therefore mixes things up much more because it reads and write back to memory many many times.
This can be easily seen from the disassembly with:
gdb -batch -ex "disassemble threadMain" fail.out
which gives for -O0:
0x0000000000402656 <+0>: endbr64 0x000000000040265a <+4>: push %rbp 0x000000000040265b <+5>: mov %rsp,%rbp 0x000000000040265e <+8>: movq $0x0,-0x8(%rbp) 0x0000000000402666 <+16>: mov 0x5c2b(%rip),%rax # 0x408298 <niters> 0x000000000040266d <+23>: cmp %rax,-0x8(%rbp) 0x0000000000402671 <+27>: jae 0x40269b <threadMain()+69> 0x0000000000402673 <+29>: mov 0x5c26(%rip),%rdx # 0x4082a0 <global> 0x000000000040267a <+36>: mov -0x8(%rbp),%rax 0x000000000040267e <+40>: mov %rax,-0x8(%rbp) 0x0000000000402682 <+44>: mov 0x5c17(%rip),%rax # 0x4082a0 <global> 0x0000000000402689 <+51>: add $0x1,%rax 0x000000000040268d <+55>: mov %rax,0x5c0c(%rip) # 0x4082a0 <global> 0x0000000000402694 <+62>: addq $0x1,-0x8(%rbp) 0x0000000000402699 <+67>: jmp 0x402666 <threadMain()+16> 0x000000000040269b <+69>: nop 0x000000000040269c <+70>: pop %rbp 0x000000000040269d <+71>: retq
and for -O3:
0x00000000004017f0 <+0>: endbr64 0x00000000004017f4 <+4>: mov 0x2a25(%rip),%rcx # 0x404220 <niters> 0x00000000004017fb <+11>: test %rcx,%rcx 0x00000000004017fe <+14>: je 0x401824 <threadMain()+52> 0x0000000000401800 <+16>: mov 0x2a11(%rip),%rdx # 0x404218 <global> 0x0000000000401807 <+23>: xor %eax,%eax 0x0000000000401809 <+25>: nopl 0x0(%rax) 0x0000000000401810 <+32>: add $0x1,%rax 0x0000000000401814 <+36>: add $0x1,%rdx 0x0000000000401818 <+40>: cmp %rcx,%rax 0x000000000040181b <+43>: jb 0x401810 <threadMain()+32> 0x000000000040181d <+45>: mov %rdx,0x29f4(%rip) # 0x404218 <global> 0x0000000000401824 <+52>: retq
We can now look into how std::atomic is implemented. In -O3 the disassembly is:
0x0000000000401770 <+0>: endbr64 0x0000000000401774 <+4>: cmpq $0x0,0x297c(%rip) # 0x4040f8 <niters> 0x000000000040177c <+12>: je 0x401796 <threadMain()+38> 0x000000000040177e <+14>: xor %eax,%eax 0x0000000000401780 <+16>: lock addq $0x1,0x2967(%rip) # 0x4040f0 <global> 0x0000000000401789 <+25>: add $0x1,%rax 0x000000000040178d <+29>: cmp %rax,0x2964(%rip) # 0x4040f8 <niters> 0x0000000000401794 <+36>: ja 0x401780 <threadMain()+16> 0x0000000000401796 <+38>: retq
so we clearly see that basically a lock addq is used to do an atomic read and write to memory every single time, just like in our other example userland/cpp/atomic/x86_64_lock_inc.cpp.
This setup can also be used to benchmark different synchronization mechanisms. For example, std::mutex was about 1.5x slower with two cores than std::atomic, presumably because it relies on the futex system call as can be seen from strace -f -s999 -v logs, while std::atomic uses just userland instructions: https://www.quora.com/How-does-std-atomic-work-in-C++11/answer/Ciro-Santilli Tested in -O3 with:
time ./std_atomic.out 4 100000000 time ./mutex.out 4 100000000
Related examples:
-
POSIX pthread_mutex
-
C11 userland/c/atomic.c documented at C multithreading
Bibliography:
-
https://stackoverflow.com/questions/31978324/what-exactly-is-stdatomic/58904448#58904448 "What exactly is std::atomic?"
27.3.4.1.1. Detailed gem5 analysis of how data races happen
The smallest data race we managed to come up as of LKMC 7c01b29f1ee7da878c7cc9cb4565f3f3cf516a92 and gem5 872cb227fdc0b4d60acc7840889d567a6936b6e1 was with userland/c/atomic.c (see also C multithreading):
./run \ --arch aarch64 \ --cli-args '2 10' \ --cpus 3 \ --emulator gem5 \ --userland userland/c/atomic.c \ ;
which outputs:
atomic 20 non-atomic 19
Note that that the system is very minimal, and doesn’t even have caches, so I’m curious as to how this can happen at all.
So first we do a run with --trace Exec and look at the my_thread_main entries.
From there we see that first CPU1 enters the function, since it was spawned first.
Then for some time, both CPU1 and CPU2 are running at the same time.
Finally, CPU1 exists, then CPU2 runs alone for a while to finish its loops, and then CPU2 exits.
By greping the LDR data read from the log, we are able to easily spot the moment where things started to go wrong based on the D= data:
grep -E 'my_thread_main\+36' trace.txt > trace-ldr.txt
The grep output contains
94024500: system.cpu1: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000006 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad) 94036500: system.cpu1: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000007 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad) 94048500: system.cpu1: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000008 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad) 94058500: system.cpu2: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000009 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad) 94060500: system.cpu1: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000009 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad) 94070500: system.cpu2: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x000000000000000a A=0x411060 flags=(IsInteger|IsMemRef|IsLoad) 94082500: system.cpu2: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x000000000000000b A=0x411060 flags=(IsInteger|IsMemRef|IsLoad)
and so se see that it is at 94058500 that things started going bad, since two consecutive loads from different CPUs read the same value D=9! Actually, things were not too bad afterwards because this was by coincidence the last CPU1 read, we would have missed many more increments if the number of iterations had been larger.
Now that we have the first bad time, let’s look at the fuller disassembly to better understand what happens around that point.
94058500: system.cpu2: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000009 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad) 94059000: system.cpu2: A0 T0 : @my_thread_main+40 : add w1, w0, #1 : IntAlu : D=0x000000000000000a flags=(IsInteger) 94059000: system.cpu1: A0 T0 : @my_thread_main+120 : b.cc <my_thread_main+28> : IntAlu : flags=(IsControl|IsDirectControl|IsCondControl) 94059500: system.cpu1: A0 T0 : @my_thread_main+28 : adrp x0, #69632 : IntAlu : D=0x0000000000411000 flags=(IsInteger) 94059500: system.cpu2: A0 T0 : @my_thread_main+44 : adrp x0, #69632 : IntAlu : D=0x0000000000411000 flags=(IsInteger) 94060000: system.cpu2: A0 T0 : @my_thread_main+48 : add x0, x0, #96 : IntAlu : D=0x0000000000411060 flags=(IsInteger) 94060000: system.cpu1: A0 T0 : @my_thread_main+32 : add x0, x0, #96 : IntAlu : D=0x0000000000411060 flags=(IsInteger) 94060500: system.cpu1: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000009 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad) 94060500: system.cpu2: A0 T0 : @my_thread_main+52 : str x1, [x0] : MemWrite : D=0x000000000000000a A=0x411060 flags=(IsInteger|IsMemRef|IsStore)
and from this, all becomes crystal clear:
-
94058500: CPU2 loads
-
94060500: CPU1 loads
-
94060500: CPU2 stores
so we see that CPU2 just happened to store after CPU1 loads.
We also understand why LDADD solves the race problem in AtomicSimpleCPU: it does the load and store in one single go!
27.3.4.2. C++ std::memory_order
TODO let’s understand that fully one day.
This is the C++ version of the more general Memory consistency concept.
27.3.5. C++ templates
27.3.5.1. SFINAE
Not possible to do the typecheck automatically without explicitly giving type constraints: https://stackoverflow.com/questions/53441832/sfinae-automatically-check-that-function-body-compiles-without-explicit-constrai
27.3.7. C++ compile time magic
27.3.7.1. C++ decltype
C++11 keyword.
Replaces decltype with type of an expression at compile time.
More powerful than auto as you can use it in more places.
27.3.8. C++ concepts
27.3.8.1. C++ iterators
userland/cpp/custom_iterator.cpp: there is no way to easily define a nice custom iterator, you just have to wrap existing iterators and add a gazillion wrapper methods:
27.3.9. C++ third-party libraries
Under: userland/libs directory.
27.3.9.2. GoogleTest
On Ubuntu 20.04, the package:
sudo apt install googletest
does not contain prebuilts, and it is intentional, it is incomprehensible:
so you might as well just git clone and build the damned thing yourself:
git submodule update --init submodules/googletest cd submodules/googletest mkdir build cd build cmake .. make -j`nproc` cd ../../userland/libs/googletest ./build
-
userland/libs/googletest/main.cpp[]
27.3.9.3. HDF5
Binary format to store data. TODO vs databases, notably SQLite: https://datascience.stackexchange.com/questions/262/hierarchical-data-format-what-are-the-advantages-compared-to-alternative-format
Examples:
-
gem5 can dump statistics as HDF5: gem5 HDF5 statistics
27.4. POSIX
Programs under userland/posix/ are examples of POSIX C programming.
These links provide a clear overview of what POSIX is:
27.4.1. Environment variables
POSIX C example that prints all environment variables: userland/posix/environ.c
27.4.2. unistd.h
-
userland/posix/count.c illustrates
sleep() -
userland/posix/count_to.c minor variation of userland/posix/count.c
27.4.3. fork
POSIX' multiprocess API. Contrast with pthreads which are for threads.
Example: userland/posix/fork.c
Sample native userland output on Ubuntu 19.04 at 762cd8d601b7db06aa289c0fca7b40696299a868 + 1:
before fork before fork pid=13038 ppid=4805 after fork after fork pid=13038 ppid=4805 after (pid == 0) after (pid == 0) pid=13038 ppid=4805 after fork after fork pid=13039 ppid=13038 inside (pid == 0) inside (pid == 0) pid=13039 ppid=13038 after wait after wait pid=13038 ppid=4805 fork() return = 13039
Read the source comments and understand everything that is going on!
27.4.3.1. getpid
The minimal interesting example is to use fork and observe different PIDs.
A more minimal test-like example without forking can be seen at: userland/posix/getpid.c.
This example can for example be used used to play with: gem5 syscall emulation multiple executables.
27.4.3.2. Fork bomb
DANGER! Only run this on your host if you have saved all data you care about! Better run it inside an emulator! QEMU v4.0.0 user mode is not safe enough either because it is very native does not limit guest memory, so it will still blow up the host!
So without further ado, let’s rock with either:
./run --eval-after './posix/fork_bomb.out danger' ./run --eval-after './fork_bomb.sh danger'
Sources:
Outcome for the C version on LKMC 762cd8d601b7db06aa289c0fca7b40696299a868 + 1: after a few seconds of an unresponsive shell, we get a visit form the Linux out-of-memory killer, and the system is restored!
27.4.4. pthreads
POSIX' multithreading API. Contrast with fork which is for processes.
This was for a looong time the only "portable" multithreading alternative, until C++11 finally added threads, thus also extending the portability to Windows.
-
userland/posix/pthread_self.c: the simplest example possible
-
userland/posix/pthread_count.c: count an atomic varible across threads
-
userland/posix/pthread_deadlock.c: purposefully create a deadlock to see what it looks like
-
userland/posix/pthread_barrier.c: related: https://stackoverflow.com/questions/28663622/understanding-posix-barrier-mechanism
27.4.4.1. pthread_mutex
userland/posix/pthread_count.c exemplifies the functions:
-
pthread_mutex_lock -
pthread_mutex_unlock
That example that the same interface as: atomic.cpp. There are no non-locking atomic types or atomic primitives in POSIX: http://stackoverflow.com/questions/1130018/unix-portable-atomic-operations
pthread_mutex_lock and pthread_mutex_unlock and many other pthread functions already enforce cross thread memory synchronization:
27.4.5. sysconf
Examples:
-
userland/linux/sysconf.c showcases Linux extensions to POSIX
Note that this blows up on gem5 userland due to
NPROCESSORS_ONLNhowever: https://gem5.atlassian.net/browse/GEM5-622
Get lots of info on the system configuration.
The constants can also be viewed accessed on my Ubuntu 18.04 host with:
getconf -a
getconf is also specified by POSIX at: https://pubs.opengroup.org/onlinepubs/9699919799/utilities/getconf.html but not the -a option which shows all configurations.
Busybox 1.31.1 clearly states that getconf is not implemented however at docs/posix_conformance.txt:
POSIX Tools not supported: asa, at, batch, bc, c99, command, compress, csplit, ex, fc, file, gencat, getconf, iconv, join, link, locale, localedef, lp, m4,
27.4.6. mmap
The mmap system call allows advanced memory operations.
mmap is notably used to implement the malloc ANSI C function, replacing the previously used break system call.
Linux adds has several POSIX extension flags to it.
27.4.6.1. mmap MAP_ANONYMOUS
Basic mmap example, do the same as userland/c/malloc.c, but with mmap.
Example: userland/linux/mmap_anonymous.c
In POSIX 7 mmap always maps to a file.
If we add the MAP_ANONYMOUS Linux extension however, this is not required, and mmap can be used to allocate memory like malloc.
27.4.6.2. mmap file
Memory mapped file example: userland/posix/mmap_file.c
The example creates a file, mmaps to it, writes to maped memory, and then closes the file.
We then read the file and confirm it was written to.
27.4.6.3. brk
Example: userland/linux/brk.c
The example allocates two ints and uses them, and then deallocates back.
27.4.7. socket
A bit like read and write, but from / to the Internet!
-
userland/posix/wget.c tiny
wgetre-implementation. See: https://stackoverflow.com/questions/11208299/how-to-make-an-http-get-request-in-c-without-libcurl/35680609#35680609
27.5. Userland multithreading
The following sections are related to multithreading in userland:
27.6. C debugging
Let’s group the hard-to-debug undefined-behaviour-like stuff found in C / C+ here and how to tackle those problems.
27.6.1. Stack smashing
- Example
Leads to the dreadful "Stack smashing detected" message. Which is infinitely better than a silent break in any case.
We had also seen this error in our repository at: stack smashing detected when using glibc.
27.6.2. Memory leaks
How to debug: https://stackoverflow.com/questions/6261201/how-to-find-memory-leak-in-a-c-code-project/57877190#57877190
Example: userland/c/memory_leak.c
27.6.3. Profiling userland programs
OK, we have to learn this stuff.
Examples:
-
userland/gcc/profile.c: simple profiling example, where certain calls of a certain function can dominate the runtime
27.7. Interpreted languages
Maybe some day someone will use this setup to study the performance of interpreters.
27.7.1. Python
Examples:
-
rootfs_overlay/lkmc/python/hello.py: hello world
-
time-
rootfs_overlay/lkmc/python/count.py: count once every second
-
rootfs_overlay/lkmc/python/iter_method.py: how to implement
iteron a class
-
27.7.1.1. Python standard library
27.7.1.1.1. Python unittest
rootfs_overlay/lkmc/python/unittest_find/ contains examples to test how tests are found by unittest within directories. Related questions:
27.7.1.1.2. Python relative imports
rootfs_overlay/lkmc/python/relative_import/ contains examples to test how how to do relative imports in Python.
This subject is impossible to understand.
Related questions:
-
https://stackoverflow.com/questions/16981921/relative-imports-in-python-3
-
https://stackoverflow.com/questions/14132789/relative-imports-for-the-billionth-time
-
https://stackoverflow.com/questions/21490860/relative-imports-with-unittest-in-python
-
https://stackoverflow.com/questions/714063/importing-modules-from-parent-folder
27.7.1.2. Build and install the interpreter
Buildroot has a Python package that can be added to the guest image:
./build-buildroot --config 'BR2_PACKAGE_PYTHON3=y'
Usage from guest in full system:
./run
and then from there get an interactive shell with:
python3
or run an example with:
python3 python/hello.py
or:
./python/hello.py
User mode simulation interactive usage:
./run --userland "$(./getvar buildroot_target_dir)/usr/bin/python3"
Non-interactive usage:
./run --userland "$(./getvar buildroot_target_dir)/usr/bin/python3" --cli-args rootfs_overlay/lkmc/python/hello.py
27.7.1.3. Python gem5 user mode simulation
At LKMC 50ac89b779363774325c81157ec8b9a6bdb50a2f gem5 390a74f59934b85d91489f8a563450d8321b602da:
./run \ --emulator gem5 \ --userland "$(buildroot_target_dir)/usr/bin/python3" \ --cli-args rootfs_overlay/lkmc/python/hello.py \ ;
fails with:
fatal: Syscall 318 out of range
which corresponds to the glorious inotify_rm_watch syscall: https://github.com/torvalds/linux/blob/v5.4/arch/arm/tools/syscall.tbl#L335
and aarch64:
./run \ --arch aarch64 \ --emulator gem5 \ --userland "$(./getvar --arch aarch64 buildroot_target_dir)/usr/bin/python3" \ --cli-args rootfs_overlay/lkmc/python/hello.py \ ;
fails with:
fatal: syscall unused#278 (#278) unimplemented.
which corresponds to the glorious getrandom syscall: https://github.com/torvalds/linux/blob/v4.17/include/uapi/asm-generic/unistd.h#L707
Bibliography:
27.7.1.4. Embedding Python in another application
Here we will add some better examples and explanations for: https://docs.python.org/3/extending/embedding.html#very-high-level-embedding
"Embedding Python" basically means calling the Python interpreter from C, and possibly passing values between the two.
These examples show to to embed the Python interpreter into a C/C++ application to interface between them
-
userland/libs/python_embed/eval.c: this example simply does
evala Python string in C, and don’t communicate any values between the two.It could be used to call external commands that have external side effects, but it is not very exciting.
-
userland/libs/python_embed/pure.c: this example actually defines some Python classes and functions from C, implementing those entirely in C.
The C program that defines those classes then instantiates the interpreter calls some regular Python code from it: userland/libs/python_embed/pure.py
The regular Python code can then use the native C classes as if they were defined in Python.
Finally, the Python returns values back to the C code that called the interpreter.
-
userland/libs/python_embed/pure_cpp.cpp: C version of the above, the main goal of this example is to show how to interface with C classes.
One notable user of Python embedding is the gem5 simulator, see also: gem5 vs QEMU. gem5 embeds the Python interpreter in order to interpret scripts as seen from the CLI:
build/ARM/gem5.opt configs/example/fs.py
gem5 then runs that Python script, which instantiates C classes defined from Python, and then finally hands back control to the C runtime to run the actual simulation faster.
27.7.1.5. pybind11
pybind11 is amazingly easy to use. But it can also make your builds really slow:
-
pybind11 accounts for 50% of gem5 build time. As mentioned there, if pybind11 would split everything that can go into a cpp file from the hpp (i.e. everything except templates) that could already significantly reduce build times in certain cases. This is discussed upstream at: https://github.com/pybind/pybind11/issues/708
-
https://discuss.pytorch.org/t/how-are-python-bindings-created/46453/2
27.7.2. Node.js
Host installation shown at: https://askubuntu.com/questions/594656/how-to-install-the-latest-versions-of-nodejs-and-npm/971612#971612
Build and install the interpreter in Buildroot with:
./build-buildroot --config 'BR2_PACKAGE_NODEJS=y'
Everything is then the same as the Python interpreter setup, except that the executable name is now node!
TODO: build broken as of LKMC 3c3deb14dc8d6511680595dc42cb627d5781746d + 1:
ERROR: package host-nodejs installs executables without proper RPATH
Examples:
-
rootfs_overlay/lkmc/nodejs/hello.js: hello world
-
String
-
process -
fs -
class-
rootfs_overlay/lkmc/nodejs/object_to_string.js:
util.inspect.customandtoStringoverride experiment: https://stackoverflow.com/questions/24902061/is-there-an-repr-equivalent-for-javascript/26698403#26698403 -
rootfs_overlay/lkmc/nodejs/object_to_json.js:
toJSONexamples
-
-
rootfs_overlay/lkmc/nodejs/http.js:
httpmodule to create a simple HTTP server: https://nodejs.org/api/http.html -
rootfs_overlay/lkmc/nodejs/esm: https://stackoverflow.com/questions/58384179/syntaxerror-cannot-use-import-statement-outside-a-module
27.7.2.1. Node.js step debugging
Overviews:
Skip breaking on the first line every time: https://stackoverflow.com/questions/41153179/why-is-the-node-debugger-break-on-first-line-a-thing
27.7.2.2. NPM
Some sample packages can be found under: npm.
Local testing of those packages can be done as shown at: https://stackoverflow.com/questions/59389027/how-to-interactively-test-the-executable-of-an-npm-node-js-package-during-develo
The packages will also be published to the NPM registry, so you can also play with them as:
npm install cirosantilli-<directory-name>
27.7.2.2.1. NPM data-files
Illustrates how to add extra non-code data files to an NPM package, and then use those files at runtime.
27.7.3. Java
No OpenJDK package as of 2018.08: https://stackoverflow.com/questions/28874150/buildroot-with-jamvm-2-0-for-java-8/59290927#59290927 partly because their build system is shit like the rest of the project’s setup.
Unmerged patch at: http://lists.busybox.net/pipermail/buildroot/2018-February/213282.html
There is a JamVM package though https://en.wikipedia.org/wiki/JamVM which is something Android started before moving to Dalvik,
Maybe some day other Android Java runtimes will also become compilable. Maybe, since Android is also shit.
27.8. Algorithms
This is still work in progress and needs better automation, but is already a good sketch. Key missing features:
-
actually check that outputs are correct in
./test -
create a mechanism to run all or some selected hand coded inputs
-
create a mechanism to run generated input
The idea was originally started at: https://github.com/cirosantilli/algorithm-cheat
The key idea is that input / output pairs are present in human readable files generated either:
-
manually for small test inputs
-
with a Python script for larger randomized tests
Test programs then:
-
read input from sdtin
-
produce output to stdout
so that we can compare the output to the expected one.
This way, tests can be reused across several implementations in different languages, emulating the many multi-language programming competition websites out there.
For example, for a native run we can can run a set / sorting test:
cd userland/algorithm/set ./build # Run with a small hand written test. ./std_set.out < test_data/8.i > tmp.raw # Extract the output from the sorted stdout, which also # contained some timing information. ./parse_output output < tmp.raw > tmp.o # Compare the output to the Expected one. cmp tmp.o test_data/8.e # Same but now with a large randomly generated input. ./generate_io ./std_set.out < tmp.i | ./parse_output output > tmp.o cmp tmp.o tmp.e
It is also possible to the algorithm tests normally from emulators in User mode simulation by setting stdin as explained at syscall emulation mode program stdin, e.g.:
./run --arch aarch64 -u userland/algorithm/set/std_set.cpp --stdin-file userland/algorithm/set/test_data/8.i
Sources:
userland/algorithm/set/parse_output is needed because timing instrumentation measurements must be embedded in the program itself to allow:
-
discounting the input reading / output writing operations from the actual "read / write to / from memory algorithm" itself
-
measuring the evolution of the benchmark mid way, e.g. to see how the current container size affects insertion time: BST vs heap vs hashmap
The following are also interesting Buildroot libraries that we could benchmark:
-
Armadillo
C++: linear algebra -
fftw: Fourier transform
-
Flann
-
GSL: various
-
liblinear
-
libspacialindex
-
libtommath
-
qhull
These are good targets for performance analysis with gem5, and there is some overlap between this section and Benchmarks.
27.8.1. BST vs heap vs hashmap
TODO: move benchmark graph from userland/cpp/bst_vs_heap_vs_hashmap.cpp to userland/algorithm/set.
The following benchmark setup works both:
It has been used to answer:
To benchmark on the host, we do:
./build-userland-in-tree \ --force-rebuild \ --optimization-level 3 \ ./userland/cpp/bst_vs_heap_vs_hashmap.cpp \ ; ./userland/cpp/bst_vs_heap_vs_hashmap.out 10000000 10000 0 | tee bst_vs_heap_vs_hashmap.dat gnuplot \ -e 'input_noext="bst_vs_heap_vs_hashmap"' \ -e 'heap_zoom_max=50' \ -e 'hashmap_zoom_max=400' \ ./bst-vs-heap-vs-hashmap.gnuplot \ ; xdg-open bst_vs_heap_vs_hashmap.tmp.png
The parameters heap_zoom_max and hashmap_zoom_max are chosen manually interactively to best showcase the regions of interest in those plots.
To benchmark on gem5, we first build the benchmark with m5ops instructions enabled, and then we run it and extract the stats:
./build-userland \ --arch x86_64 \ --ccflags='-DLKMC_M5OPS_ENABLE=1' \ --force-rebuild userland/cpp/bst_vs_heap_vs_hashmap.cpp \ --optimization-level 3 \ ; ./run \ --arch x86_64 \ --emulator gem5 \ --userland userland/cpp/bst_vs_heap_vs_hashmap.cpp \ --cli-args='100000 1 0' \ -- \ --cpu-type=DerivO3CPU \ --caches \ --l2cache \ --l1d_size=32kB \ --l1i_size=32kB \ --l2_size=256kB \ --l3_size=20MB \ ; ./bst-vs-heap-vs-hashmap-gem5-stats --arch x86_64 | tee bst_vs_heap_vs_hashmap_gem5.dat gnuplot \ -e 'input_noext="bst_vs_heap_vs_hashmap_gem5"' \ -e 'heap_zoom_max=500' \ -e 'hashmap_zoom_max=400' \ ./bst-vs-heap-vs-hashmap.gnuplot \ ; xdg-open bst_vs_heap_vs_hashmap_gem5.tmp.png
TODO: the gem5 simulation blows up on a tcmalloc allocation somewhere near 25k elements as of 3fdd83c2c58327d9714fa2347c724b78d7c05e2b + 1, likely linked to the extreme inefficiency of the stats collection?
The cache sizes were chosen to match the host 2017 Lenovo ThinkPad P51 to improve the comparison. Ideally we should also use the same standard library.
Note that this will take a long time, and will produce a humongous ~40Gb stats file as explained at: Section 24.10.3.2, “gem5 only dump selected stats”
Sources:
27.8.2. BLAS
Buildroot supports it, which makes everything just trivial:
./build-buildroot --config 'BR2_PACKAGE_OPENBLAS=y' ./build-userland --package openblas -- userland/libs/openblas/hello.c ./run --eval-after './libs/openblas/hello.out; echo $?'
Outcome: the test passes:
0
Source: userland/libs/openblas/hello.c
The test performs a general matrix multiplication:
| 1.0 -3.0 | | 1.0 2.0 1.0 | | 0.5 0.5 0.5 | | 11.0 - 9.0 5.0 |
1 * | 2.0 4.0 | * | -3.0 4.0 -1.0 | + 2 * | 0.5 0.5 0.5 | = | - 9.0 21.0 -1.0 |
| 1.0 -1.0 | | 0.5 0.5 0.5 | | 5.0 - 1.0 3.0 |
This can be deduced from the Fortran interfaces at
less "$(./getvar buildroot_build_build_dir)"/openblas-*/reference/dgemmf.f
which we can map to our call as:
C := alpha*op( A )*op( B ) + beta*C, SUBROUTINE DGEMMF( TRANA, TRANB, M,N,K, ALPHA,A,LDA,B,LDB,BETA,C,LDC) cblas_dgemm( CblasColMajor, CblasNoTrans, CblasTrans,3,3,2 ,1, A,3, B,3, 2 ,C,3 );
27.8.3. Eigen
Header only linear algebra library with a mainline Buildroot package:
./build-buildroot --config 'BR2_PACKAGE_EIGEN=y' ./build-userland --package eigen -- userland/libs/eigen/hello.cpp
Just create an array and print it:
./run --eval-after './libs/eigen/hello.out'
Output:
3 -1 2.5 1.5
Source: userland/libs/eigen/hello.cpp
This example just creates a matrix and prints it out.
Tested on: a4bdcf102c068762bb1ef26c591fcf71e5907525
27.9. Benchmarks
These are good targets for performance analysis with gem5.
TODO also consider the following:
-
http://www.cs.virginia.edu/stream/ref.html STREAM memory bandwidth benchmarks.
-
https://github.com/kozyraki/stamp transactional memory benchmarks
27.9.1. Microbenchmarks
It eventually has to come to that, hasn’t it?
-
userland/gcc/busy_loop.c described at C busy loop
Of course, there is a continuum between what is a "microbenchmark" and a "macrobechmark".
One would hope that every microbenchmark exercises a concentrated subset of part of an important macro benchmark, otherwise what’s the point, right?
Also for parametrized "macro benchmark", you can always in theory reduce the problem size to be so small that it might be more appropriate to call it a micro benchmark.
So our working definition will be more of the type: "does it solve an understandable useful high level problem from start to end?".
If the answer is yes, then we call it a macro benchmark, otherwise micro.
Bibliography:
27.10. userland/libs directory
Tests under userland/libs require certain optional libraries to be installed on the target, and are not built or tested by default, you must enable them with either:
--package <package> --package-all
See for example BLAS. Since it is located under userland/libs/openblas, it will only build with either:
./build-userland --package openblas ./build-userland --package-all
As an exception, if you first cd directly into one of the directories and do a native host build, e.g.:
sudo apt install libeigen3-dev cd userland/libs/eigen ./build
then that library will be automatically enabled.
See also:
27.11. Userland content filename conventions
The following basenames should always refer to programs that do the same thing, but in different languages:
-
count: count to infinity, sleep one second between each number
27.12. Userland content bibliography
-
The Linux Programming Interface by Michael Kerrisk https://www.amazon.co.uk/Linux-Programming-Interface-System-Handbook/dp/1593272200 Lots of open source POSIX examples: https://github.com/cirosantilli/linux-programming-interface-kerrisk
28. Userland assembly
Programs under userland/arch/<arch>/ are examples of userland assembly programming.
This section will document ISA agnostic concepts, and you should read it first.
ISA specifics are covered at:
-
x86 userland assembly under userland/arch/x86_64/, originally migrated from: https://github.com/cirosantilli/x86-assembly-cheat
-
ARM userland assembly originally migrated from https://github.com/cirosantilli/arm-assembly-cheat under:
Like other userland programs, these programs can be run as explained at: Section 2.8, “Userland setup”.
As a quick reminder, the fastest setups to get started are:
-
Userland setup getting started natively if your host can run the examples, e.g. x86 example on an x86 host:
-
Userland setup getting started with prebuilt toolchain and QEMU user mode otherwise
However, as usual, it is saner to build your toolchain as explained at: Section 11.1, “QEMU user mode getting started”.
The first examples you should look into are:
-
add
-
mov between register and memory
-
addressing modes
-
registers, see: Section 28.1, “Assembly registers”
-
jumping:
-
SIMD
The add examples in particular:
-
introduce the basics of how a given assembly works: how many inputs / outputs, who is input and output, can it use memory or just registers, etc.
It is then a big copy paste for most other data instructions.
-
verify that the venerable ADD instruction and our assertions are working
Now try to modify modify the x86_64 add program to see the assertion fail:
LKMC_ASSERT_EQ(%rax, $4)
because 1 + 2 tends to equal 3 instead of 4.
And then watch the assertion fail:
./build-userland ./run --userland userland/arch/x86_64/add.S
with error message:
assert_eq_64 failed val1 0x3 val2 0x4 error: asm_main returned 1 at line 8
and notice how the error message gives both:
-
the actual assembly source line number where the failing assert was
-
the actual and expected values
Other infrastructure sanity checks that you might want to look into include:
-
LKMC_FAILtests -
LKMC_ASSERT_EQtests -
LKMC_ASSERT_MEMCMPtests
28.1. Assembly registers
After seeing an ADD hello world, you need to learn the general registers:
-
x86, see: Section 29.1, “x86 registers”
-
arm
-
aarch64
Bibliography: ARMv7 architecture reference manual A2.3 "ARM core registers".
28.1.1. ARMv8 aarch64 x31 register
Example: userland/arch/aarch64/x31.S
There is no X31 name, and the encoding can have two different names depending on the instruction:
-
XZR: zero register:
-
SP: stack pointer
To make things more confusing, some aliases can take either name, which makes them alias to different things, e.g. MOV accepts both:
mov x0, sp mov x0, xzr
and the first one is an alias to ADD while the second an alias to ORR.
The difference is documented on a per instruction basis. Instructions that encode 31 as SP say:
if d == 31 then SP[] = result; else X[d] = result;
And then those that don’t say that, B1.2.1 "Registers in AArch64 state" implies the zero register:
In instruction encodings, the value 0b11111 (31) is used to indicate the ZR (zero register). This indicates that the argument takes the value zero, but does not indicate that the ZR is implemented as a physical register.
This is also described on ARMv8 architecture reference manual C1.2.5 "Register names":
There is no register named W31 or X31.
The name SP represents the stack pointer for 64-bit operands where an encoding of the value 31 in the corresponding register field is interpreted as a read or write of the current stack pointer. When instructions do not interpret this operand encoding as the stack pointer, use of the name SP is an error.
The name XZR represents the zero register for 64-bit operands where an encoding of the value 31 in the corresponding register field is interpreted as returning zero when read or discarding the result when written. When instructions do not interpret this operand encoding as the zero register, use of the name XZR is an error
28.2. Floating point assembly
Keep in mind that many ISAs started floating point as an optional thing, and it later got better integrated into the main CPU, side by side with SIMD.
For this reason, there are sometimes multiple ways to do floating point operations in each ISA.
Let’s start as usual with floating point addition + register file:
28.3. SIMD assembly
Much like ADD for non-SIMD, start learning SIMD instructions by looking at the integer and floating point SIMD ADD instructions of each ISA:
-
x86
-
arm
-
aarch64
Then it is just a huge copy paste of infinite boring details:
To debug these instructions, you can see the register values in GDB with:
info registers float
or alternatively with register names (here the ARMv8 V0 register):
print $v0
as mentioned at:
Bibliography: https://stackoverflow.com/questions/1389712/getting-started-with-intel-x86-sse-simd-instructions/56409539#56409539
28.3.1. FMA instruction
Fused multiply add:
Bibliography:
Particularly important numerical analysis instruction, that is used in particular for;
-
Dot product
-
Matrix multiplication
FMA is so important that IEEE 754 specifies it with single precision drop compared to a separate add and multiply!
Historically, FMA instructions have been added relatively late to instruction sets.
28.4. User vs system assembly
By "userland assembly", we mean "the parts of the ISA which can be freely used from userland".
Most ISAs are divided into a system and userland part, and to running the system part requires elevated privileges such as ring0 in x86.
One big difference between both is that we can run userland assembly on Userland setup, which is easier to get running and debug.
In particular, most userland assembly examples link to the C standard library, see: Section 28.5, “Userland assembly C standard library”.
Userland assembly is generally simpler, and a pre-requisite for Baremetal setup.
System-land assembly cheats will be put under: Section 2.9, “Baremetal setup”.
28.5. Userland assembly C standard library
All examples except the Freestanding programs link to the C standard library.
This allows using the C standard library for IO, which is very convenient and portable across host OSes.
It also exposes other non-IO functionality that is very convenient such as memcmp.
The C standard library infrastructure is implemented in the common userland / baremetal source files:
28.5.1. Freestanding programs
Unlike most our other assembly examples, which use the C standard library for portability, examples under freestanding/ directories don’t link to the C standard library:
-
userland/freestanding/: freestanding programs that work on any ISA
As a result, those examples cannot do IO portably, and so they make raw system calls and only be run on one given OS, e.g. Linux system calls.
Such executables are called freestanding because they don’t execute the glibc initialization code, but rather start directly on our custom hand written assembly.
In order to GDB step debug those executables, you will want to use --no-continue, e.g.:
./run --arch aarch64 --userland userland/arch/aarch64/freestanding/linux/hello.S --gdb-wait ./run-gdb --arch aarch64 --no-continue --userland userland/arch/aarch64/freestanding/linux/hello.S
or in one go with tmux:
./run \ --arch aarch64 \ --gdb-wait \ --tmux-args=--no-continue \ --userland userland/arch/aarch64/freestanding/linux/hello.S \ ;
You are now left on the very first instruction of our tiny executable!
This is analogous to step debugging baremetal examples.
Related:
-
https://stackoverflow.com/questions/4783404/is-main-really-start-of-a-c-program/64116561#64116561 "Is main() really start of a C++ program?"
-
https://electronics.stackexchange.com/questions/258896/what-happens-before-main/404298#404298
-
https://electronics.stackexchange.com/questions/55767/who-receives-the-value-returned-by-main, more microcontroller focused, should entitled "how to quit a program in microcontroller"
-
https://stackoverflow.com/questions/53570678/what-happens-before-main-in-c "What happens before main in C++?"
-
https://www.quora.com/What-is-happening-before-the-main-function-is-called-in-C++-programming
-
https://stackoverflow.com/questions/2053029/how-exactly-does-attribute-constructor-work
28.5.1.1. nostartfiles programs
Assembly examples under nostartfiles directories can use the standard library, but they don’t use the pre-main boilerplate and start directly at our explicitly given _start:
I’m not sure how much stdlib functionality is supposed to work without the pre-main stuff, but I guess we’ll just have to find out!
Was going to ask the following markdown question, but I noticed half way that:
-
without
-static, I see a bunch of dynamic loader instructions, so not much is gained -
with
-static, the program segfaults, including on the host with stack:#0 0x0000000000429625 in _IO_cleanup () #1 0x0000000000400c72 in __run_exit_handlers () #2 0x0000000000400caa in exit () #3 0x0000000000400a01 in _start () at exit.S:4
so I didn’t really have a good question.
The Markdown question that was almost asked:
When working in emulators, I often want to keep my workloads as small as possible to more easily study instruction traces and reproduce bugs. One of the ways I often want to do that, especially when doing [user mode simulations](https://wiki.debian.org/QemuUserEmulation), is by not running [the code that normally runs before main](https://stackoverflow.com/questions/53570678/what-happens-before-main-in-c) so that I can start directly in the instructions of interest that I control myself, which can be achieved with the `gcc -nostartfiles` option and by starting the program directly at `_start`. Here is a tiny example that calls just `exit` from the C standard library: main.S
_start: mov $0, %rdi call exit
Compile and run with:
gcc -ggdb3 -nostartfiles -static -o exit.out exit.S qemu-x86_64 -d in_asm exit.out
However, for programming convenience, and to potentially keep my examples more OS portable, I would like to avoid making raw system calls, which would of course work, by using C standard library functions instead. But I'm afraid that some of those C standard library functions will fail in subtle ways because I have skipped required initialization steps that would normally happen before `main`. Is it any easy to determine which functions I can use or not, in case there are any that I can't use?
28.6. GCC inline assembly
Examples under arch/<arch>/c/ directories show to how use inline assembly from higher level languages such as C:
-
x86_64
-
userland/arch/x86_64/inline_asm/sqrt_x87.c Shows how to use the x86 x87 FPU instructions from inline assembly. Bibliography: https://stackoverflow.com/questions/6514537/how-do-i-specify-immediate-floating-point-numbers-with-inline-assembly/52906126#52906126
-
arm
-
aarch64
-
userland/arch/aarch64/inline_asm/inc_32.c: how to use 32-bit
wregisters in aarch64. We have to addwto the%as in%w[io]instead of%[io]
28.6.1. GCC inline assembly register variables
Used notably in some of the Linux system calls setups:
In x86, makes it possible to access variables not exposed with the one letter register constraints.
In arm, it is the only way to achieve this effect: https://stackoverflow.com/questions/10831792/how-to-use-specific-register-in-arm-inline-assembler
This feature notably useful for making system calls from C, see: Section 28.7, “Linux system calls”.
28.6.2. GCC inline assembly scratch registers
How to use temporary registers in inline assembly:
28.6.3. GCC inline assembly early-clobbers
An example of using the & early-clobber modifier: link:userland/arch/aarch64/earlyclobber.c
More details at: https://stackoverflow.com/questions/15819794/when-to-use-earlyclobber-constraint-in-extended-gcc-inline-assembly/54853663#54853663
The assertion may fail without it. It actually does fail in GCC 8.2.0.
28.6.4. GCC inline assembly floating point ARM
Not documented as of GCC 8.2, but possible: https://stackoverflow.com/questions/53960240/armv8-floating-point-output-inline-assembly
28.6.5. GCC intrinsics
Pre-existing C wrappers using inline assembly, this is what production programs should use instead of inline assembly for SIMD:
-
x86_64
-
userland/arch/x86_64/intrinsics/paddq.c. Intrinsics version of userland/arch/x86_64/paddq.S
-
userland/arch/x86_64/intrinsics/addpd.c. Intrinsics version of userland/arch/x86_64/addpd.S
-
28.6.5.1. GCC x86 intrinsics
Good official cheatsheet with all intrinsics and what they expand to: https://software.intel.com/sites/landingpage/IntrinsicsGuide
The functions use the the following naming convention:
<vector_size>_<intrin_op>_<suffix>
where:
-
<vector_size>:-
mm: 128-bit vectors (SSE) -
mm256: 256-bit vectors (AVX and AVX2) -
mm512: 512-bit vectors (AVX512)
-
-
<intrin_op>: operation of the intrinsic function, e.g. add, sub, mul, etc. -
<suffix>: data type:-
ps: 4 floats (Packed Single) -
pd: 2 doubles (Packed Double) -
ss: 1 float (Single Single), often the lowest order one -
sd: 1 double (Single Double) -
si128: 128-bits of integers of any size -
ep<int_type>integer types, e.g.:-
epi32: 32 bit signed integers -
epu16: 16 bit unsigned integers
-
-
Data types:
-
__m128: four floats -
__m128d: two doubles -
__m128i: integers: 8 x 16-bit, 4 x 32-bit, 2 x 64-bit
The headers to include are clarified at: https://stackoverflow.com/questions/11228855/header-files-for-x86-simd-intrinsics
x86intrin.h everything mmintrin.h MMX xmmintrin.h SSE emmintrin.h SSE2 pmmintrin.h SSE3 tmmintrin.h SSSE3 smmintrin.h SSE4.1 nmmintrin.h SSE4.2 ammintrin.h SSE4A wmmintrin.h AES immintrin.h AVX zmmintrin.h AVX512
Present in gcc-7_3_0-release tree at: gcc/config/i386/x86intrin.h.
Bibliography:
28.7. Linux system calls
The following Userland setup programs illustrate how to make system calls:
-
x86_64
-
userland/arch/x86_64/inline_asm/freestanding/linux/hello.c: this shows how to do system calls from inline assembly without any C standard library helpers like
syscall -
userland/arch/x86_64/inline_asm/freestanding/linux/hello_regvar.c: same as userland/arch/x86_64/inline_asm/freestanding/linux/hello.c but using register variables instead of register constraints
-
arm
-
userland/arch/arm/inline_asm/freestanding/linux/hello.c: there are no register constraints in ARM, so register variables are the most efficient way of storing variables in specific general purpose registers: https://stackoverflow.com/questions/3929442/how-to-specify-an-individual-register-as-constraint-in-arm-gcc-inline-assembly/54845046#54845046
-
aarch64
Determining the ARM syscall numbers:
Determining the ARM syscall interface:
Questions about the C inline assembly examples:
28.7.1. futex system call
This is how threads either:
-
request the kernel to sleep until they are woken up by other threads
-
request the kernel to wake up other threads that are waiting on a given futex
This syscall is rarely used on its own, and there isn’t even a glibc wrapper for it: you almost always just want to use the pthreads or C++ multithreading wrappers which use it for you to implement higher level constructs like mutexes.
Futexes are bit complicated, because in order to achieve their efficiency, basically nothing is guaranteed: the wait might not wait, and the wakes might not wake.
So you are just basically forced to use atomic operations on the futex memory address in order to be sure of anything (we encourage you to try without :-)).
Minimal examples:
-
lkmc/futex.h: our futex wrapper
-
userland/linux/futex.c: minimal example. It:
-
first spawns a child
-
then sleeps for 1 second and wakes up the futex if anyone is sleeping on it
-
the child sleeps on the futex if it reaches that futex before the end of the parent’s sleep (likely). If it did reach that
FUTEX_WAITthere, it gets awoken by the parent.So what you see is:
main start child start [wait 1s] parent after sleep child after parent sleep
-
28.7.1.1. Userland mutex implementation
The best article to understand spinlocks is: https://eli.thegreenplace.net/2018/basics-of-futexes/
The example in man futex is also a must.
28.7.2. getcpu system call and the sched_getaffinity glibc wrapper
Examples:
-
userland/linux/getcpu.c: a wrapper close the the syscall that also returns the current NUMA node
-
userland/linux/getcpu_syscall.c: the wrapper segfaults on error handling, so double checking with the real syscall: https://stackoverflow.com/questions/9260937/unix-socket-error-14-efault-bad-address/61879849#61879849
-
userland/linux/sched_getcpu_barrier.c: this uses a barrier to ensure that gem5 will run each thread on one separate CPU
Returns the CPU that the process/thread is currently running on:
So when running a multicore program, we may see that each thread can be running on a different core.
The cores in which the process runs can be fixed with sched_setaffinity as shown at: userland/linux/sched_getaffinity.c.
So when I run it with main thread + 4 threads on a 4 core CPUs:
./userland/linux/sched_getcpu.out 4
I see random outputs like:
7 2 1 5
and:
5 0 2 1
Due to the way that gem5 syscall emulation multithreading however, the output is more deterministic in that case, see that section for further details.
28.7.3. perf_event_open system call
On ARM, perf_event_open uses the ARM PMU. The mapping between kernel events and ARM PMU events can be found at: https://github.com/cirosantilli/linux/blob/v5.9/arch/arm64/kernel/perf_event.c
Bibliography:
-
man perf_event_open -
instruction counts: https://stackoverflow.com/questions/13313510/quick-way-to-count-number-of-instructions-executed-in-a-c-program/64863392#64863392
-
cycle counts:
28.8. Linux calling conventions
A summary of results is shown at: Table 3, “Summary of Linux calling conventions for several architectures”.
| arch | arguments | return value | callee saved registers |
|---|---|---|---|
x86_64 |
rdi, rsi, rdx, rcx, r8, r9, xmm0–7 |
rax, rdx |
rbx, rbp, r12–r15 |
arm |
r0-r3 |
r0-r3 |
r4-r11 |
aarch64 |
x0-x7 |
x0-x7 |
x19-x29 |
28.8.1. x86_64 calling convention
Examples:
-
lkmc/x86_64.h
ENTRYandEXIT
One important catch is that the stack must always be aligned to 16-bits before making calls: https://stackoverflow.com/questions/56324948/why-does-calling-the-c-abort-function-from-an-x86-64-assembly-function-lead-to
Bibliography:
28.8.2. ARM calling convention
Call C standard library functions from assembly and vice versa.
-
arm
-
lkmc/arm.h
ENTRYandEXIT
-
-
aarch64
ARM Architecture Procedure Call Standard (AAPCS) is the name that ARM Holdings gives to the calling convention.
Official specification: http://infocenter.arm.com/help/topic/com.arm.doc.ihi0042f/IHI0042F_aapcs.pdf
Bibliography:
-
https://en.wikipedia.org/wiki/Calling_convention#ARM_(A32) Wiki contains the master list as usual.
-
https://stackoverflow.com/questions/8422287/calling-c-functions-from-arm-assembly
-
https://stackoverflow.com/questions/261419/arm-to-c-calling-convention-registers-to-save
-
https://stackoverflow.com/questions/10494848/arm-whats-the-difference-between-apcs-and-aapcs-abi
28.9. GNU GAS assembler
GNU GAS is the default assembler used by GDB, and therefore it completely dominates in Linux.
The Linux kernel in particular uses GNU GAS assembly extensively for the arch specific parts under arch/.
28.9.1. GNU GAS assembler comments
In this tutorial, we use exclusively C Preprocessor /**/ comments because:
-
they are the same for all archs
-
we are already stuck to the C Preprocessor because GNU GAS macros are unusable so we need
#define -
mixing
#GNU GAS comments and#defineis a bad idea ;-)
But just in case you want to suffer, see this full explanation of GNU GAS comments: https://stackoverflow.com/questions/15663280/how-to-make-the-gnu-assembler-use-a-slash-for-comments/51991349#51991349
Examples:
28.9.2. GNU GAS assembler immediates
Summary:
-
x86 always dollar
$everywhere. -
ARM: can use either
#,$or nothing depending on v7 vs v8 and.syntax unified.
Examples:
28.9.3. GNU GAS assembler data sizes
Let’s see how many bytes go into each data type:
The results are shown at: Table 4, “Summary of GNU GAS assembler data sizes”.
| .byte | .word | .long | .quad | .octa |
|---|---|---|---|---|
x86 |
1 |
2 |
4 |
8 |
16 |
arm |
1 |
4 |
4 |
8 |
16 |
aarch64 |
1 |
4 |
and also keep in mind that according to the manual:
-
.intis the same as.long -
.hwordis the same as.shortwhich is usually the same as.word
Bibliography:
28.9.3.1. GNU GAS assembler ARM specifics
28.9.3.1.1. GNU GAS assembler ARM unified syntax
There are two types of ARMv7 assemblies:
-
.syntax divided -
.syntax unified
They are very similar, but unified is the new and better one, which we use in this tutorial.
Unfortunately, for backwards compatibility, GNU AS 2.31.1 and GCC 8.2.0 still use .syntax divided by default.
The concept of unified assembly is mentioned in ARM’s official assembler documentation: http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dui0473c/BABJIHGJ.html and is often called Unified Assembly Language (UAL).
Some of the differences include:
-
#is optional in unified syntax int literals, see GNU GAS assembler immediates -
many mnemonics changed:
-
most of them are condition code position changes, e.g. ANDSEQ vs ANDEQS: https://stackoverflow.com/questions/51184921/wierd-gcc-behaviour-with-arm-assembler-andseq-instruction
-
but there are some more drastic ones, e.g. SWI vs SVC: https://stackoverflow.com/questions/8459279/are-arm-instructuons-swi-and-svc-exactly-same-thing/54078731#54078731
-
-
cannot have implicit destination with shift, see: Section 30.4.4.1, “ARM shift suffixes”
28.9.3.2. GNU GAS assembler ARM .n and .w suffixes
When reading disassembly, many instructions have either a .n or .w suffix.
.n means narrow, and stands for the Thumb encoding of an instructions, while .w means wide and stands for the ARM encoding.
28.9.4. GNU GAS assembler char literals
This syntax plays horribly with the C preprocessor:
MACRO($'a)
fails because cpp treats string and char literals magically.
28.10. NOP instructions
-
x86: NOP
No OPeration.
Does nothing except take up one processor cycle and occupy some instruction memory.
29. x86 userland assembly
Arch agnostic infrastructure getting started at: Section 28, “Userland assembly”.
29.1. x86 registers
link:userland/arch/x86_64/registers.S
|-----------------------------------------------| | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | |-----------------------------------------------| | | | AH | AL | |-----------------------------------------------| | | | AX | |-----------------------------------------------| | | EAX | |-----------------------------------------------| | RAX | |-----------------------------------------------|
For the newer x86_64 registers, the naming convention is somewhat saner:
|-----------------------------------------------| | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | |-----------------------------------------------| | | |R12H |R12L | |-----------------------------------------------| | | | R12W | |-----------------------------------------------| | | R12D | |-----------------------------------------------| | R12 | |-----------------------------------------------|
Most of the 8 older x86 general purpose registers are not "really" general purpose in the sense that a few instructions magically use them without an explicit encoding. This is reflected in their names:
-
RAX: Accumulator. The general place where you add, subtract and otherwise manipulate results in-place. Magic for example for MUL.
-
RCX, RSI, RDI: Counter, Source and Destination. Used in x86 string instructions
29.1.1. x86 FLAGS registers
TODO: add some more info here. Just need a link placeholder for now.
29.2. x86 addressing modes
Example: userland/arch/x86_64/address_modes.S
Several x86 instructions can calculate addresses of a complex form:
s:a(b, c, d)
which expands to:
a + b + c * d
Where the instruction encoding allows for:
-
a: any 8 or 32-bit general purpose register -
b: any 32-bit general purpose register except ESP -
c: 1, 2, 4 or 8 (encoded in 2 SIB bits) -
d: immediate constant -
s: a segment register. Cannot be tested simply from userland, so we won’t talk about them here. See: https://github.com/cirosantilli/x86-bare-metal-examples/blob/6606a2647d44bc14e6fd695c0ea2b6b7a5f04ca3/segment_registers_real_mode.S
The common compiler usage is:
-
a: base pointer -
b: array offset -
candd: struct offset
Bibliography:
29.3. x86 data transfer instructions
5.1.1 "Data Transfer Instructions"
-
Integer typecasts
-
userland/arch/x86_64/movzx.S: MOVZX
-
userland/arch/x86_64/movsx.S: MOVSX
-
-
userland/arch/x86_64/bswap.S: BSWAP: convert between little endian and big endian
-
userland/arch/x86_64/pushf.S PUSHF: push and pop the x86 FLAGS registers to / from the stack
29.3.1. x86 exchange instructions
Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 1 7.3.1.2 "Exchange Instructions":
-
userland/arch/x86_64/xadd.S XADD: exchange and add. This is how C `<atomic>`'s' `` is implemented in GCC 5.1. TODO: why is the exchange part needed?
-
userland/arch/x86_64/xchg.S XCHG: exchange two values
TODO: concrete multi-thread GCC inline assembly examples of how all those instructions are normally used as synchronization primitives.
29.3.1.1. x86 CMPXCHG instruction
CMPXCHG: compare and exchange. cmpxchg a, b does:
if (RAX == b) {
ZF = 1
b = a
} else {
ZF = 0
RAX = b
}
TODO application: https://stackoverflow.com/questions/6935442/x86-spinlock-using-cmpxchg
29.3.2. x86 PUSH and POP instructions
push %rax is basically equivalent to:
sub $8, %rsp mov %rax, (%rsp)
and pop %rax:
mov (%rsp), %rax add $8, %rsp
Why do those instructions exist at all vs MOV / ADD / SUB: https://stackoverflow.com/questions/4584089/what-is-the-function-of-push-pop-registers-in-x86-assembly/33583134#33583134
29.3.3. x86 CQTO and CLTQ instructions
Examples:
Instructions without E suffix: sign extend RAX into RDX:RAX.
Instructions E suffix: sign extend withing RAX itself.
Common combo with IDIV 32-bit, which takes the input from EDX:EAX: so you need to set up EDX before calling it.
Has some Intel vs AT&T name overload hell:
GNU GAS accepts both syntaxes, see: Table 5, “CQTO and CLTQ family Intel vs AT&T”.
| Intel | AT&T | From |
|---|---|---|
To |
CBW |
CBTW |
AL |
AX |
CWDE |
CWTL |
AX |
EAX |
CWD |
CWTD |
AX |
DX:AX |
CDQ |
CLTD |
EAX |
EDX:EAX |
CDQE |
CLTQ |
EAX |
RAX |
CQO |
CQTO |
RAX |
29.3.4. x86 CMOVcc instructions
-
userland/arch/x86_64/cmovcc.S: CMOVcc
mov if a condition is met:
CMOVcc a, b
Equals:
if(flag) a = b
where cc are the same flags as Jcc.
Vs jmp:
Not necessarily faster because of branch prediction.
This is partly why the ternary ? C operator exists: https://stackoverflow.com/questions/3565368/ternary-operator-vs-if-else
It is interesting to compare this with ARMv7 conditional execution: which is available for all instructions, as shown at: Section 30.2.5, “ARM conditional execution”.
29.4. x86 binary arithmetic instructions
Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 1 5.1.2 "Binary Arithmetic Instructions":
-
userland/arch/x86_64/div.S: DIV
-
userland/arch/x86_64/div_overflow.S: DIV overflow
-
userland/arch/x86_64/div_zero.S: DIV zero
-
29.5. x86 logical instructions
Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 1 5.1.4 "Logical Instructions"
29.6. x86 shift and rotate instructions
Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 1 5.1.5 "Shift and Rotate Instructions"
-
SHift left or Right and insert 0.
CF == the bit that got shifted out.
Application: quick unsigned multiply and divide by powers of 2.
-
Application: signed multiply and divide by powers of 2.
Mnemonics: Shift Arithmetic Left and Right
Keeps the same sign on right shift.
Not directly exposed in C, for which signed shift is undetermined behavior, but does exist in Java via the
>>>operator. C compilers can omit it however.SHL and SAL are exactly the same and have the same encoding: https://stackoverflow.com/questions/8373415/difference-between-shl-and-sal-in-80x86/56621271#56621271
-
userland/arch/x86_64/rol.S: ROL and ROR
Rotates the bit that is going out around to the other side.
-
userland/arch/x86_64/rol.S: RCL and RCR
Like ROL and ROR, but insert the carry bit instead, which effectively generates a rotation of 8 + 1 bits. TODO application.
29.7. x86 bit and byte instructions
Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 1 5.1.6 "Bit and Byte Instructions"
-
Bit test: test if the Nth bit a bit of a register is set and store the result in the CF FLAG.
CF = reg[N]
-
userland/arch/x86_64/btr.S: BTR
Do a BT and then set the bit to 0.
-
userland/arch/x86_64/btc.S: BTC
Do a BT and then swap the value of the tested bit.
-
userland/arch/x86_64/setcc.S: SETcc
Set a byte of a register to 0 or 1 depending on the cc condition.
-
userland/arch/x86_64/popcnt.S: POPCNT
Count the number of 1 bits.
-
userland/arch/x86_64/test.S: TEST
Like CMP but does AND instead of SUB:
ZF = (!(X && Y)) ? 1 : 0
29.8. x86 control transfer instructions
Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 1 5.1.7 "Control Transfer Instructions"
-
userland/arch/x86_64/jmp.S: JMP
-
userland/arch/x86_64/jmp_indirect.S: JMP indirect
-
29.8.1. x86 Jcc instructions
Jump if certain conditions of the flags register are met.
Jcc includes the instructions:
-
JZ, JNZ
-
JE, JNE: same as JZ, with two separate manual entries that say almost the same thing, lol: https://stackoverflow.com/questions/14267081/difference-between-je-jne-and-jz-jnz/14267662#14267662
-
-
JG: greater than, signed
-
JA: Above: greater than, unsigned
-
-
JL: less than, signed
-
JB below: less than, unsigned
-
-
JC: carry
-
JO: overflow
-
JP: parity. Why it exists: https://stackoverflow.com/questions/25707130/what-is-the-purpose-of-the-parity-flag-on-a-cpu
-
JPE: parity even
-
JPO: parity odd
JG vs JA and JL vs JB:
29.8.3. x86 string instructions
Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 1 5.1.8 "String Instructions"
These instructions do some operation on an array item, and automatically update the index to the next item:
-
First example explained in more detail
-
userland/arch/x86_64/stos.S: STOS: STOre String: store register to memory. STOSD is called STOSL in GNU GAS as usual: https://stackoverflow.com/questions/6211629/gcc-inline-assembly-error-no-such-instruction-stosd
-
-
Further examples
-
userland/arch/x86_64/cmps.S: CMPS: CoMPare Strings: compare two values in memory with addresses given by RSI and RDI. Could be used to implement
memcmp. Store the result in JZ as usual. -
userland/arch/x86_64/lods.S: LODS: LOaD String: load from memory to register.
-
userland/arch/x86_64/movs.S: MOVS: MOV String: move from one memory to another with addresses given by RSI and RDI. Could be used to implement
memmov. -
userland/arch/x86_64/scas.S: SCAS: SCan String: compare memory to the value in a register. Could be used to implement
strchr.
-
The RSI and RDI registers are actually named after these intructions! S is the source of string instructions, D is the destination of string instructions: https://stackoverflow.com/questions/1856320/purpose-of-esi-edi-registers
The direction of the index increment depends on the direction flag of the FLAGS register: 0 means forward and 1 means backward: https://stackoverflow.com/questions/9636691/what-are-cld-and-std-for-in-x86-assembly-language-what-does-df-do
These instructions were originally developed to speed up "string" operations such as those present in the <string.h> header of the C standard library.
However, as computer architecture evolved, those instructions might not offer considerable speedups anymore, and modern glibc such as 2.29 just uses x86 SIMD operations instead:, see also: https://stackoverflow.com/questions/33480999/how-can-the-rep-stosb-instruction-execute-faster-than-the-equivalent-loop
29.8.3.1. x86 REP prefix
Example: userland/arch/x86_64/rep.S
Repeat a string instruction RCX times:
As the repetitions happen:
-
RCX decreases, until it reaches 0
-
RDI and RSI increase
The variants: REPZ, REPNZ (alias REPE, REPNE) repeat a given instruction until something happens.
REP and REPZ also additionally stop if the comparison operation they repeat fails.
-
REP: INS, OUTS, MOVS, LODS, and STOS
-
REPZ: CMPS and SCAS
29.8.4. x86 ENTER and LEAVE instructions
These instructions were designed to allocate and deallocate function stack frames in the prologue and epilogue: https://stackoverflow.com/questions/5959890/enter-vs-push-ebp-mov-ebp-esp-sub-esp-imm-and-leave-vs-mov-esp-ebp
ENTER appears obsolete and is kept mostly for backwards compatibility. LEAVE is still emitted by some compilers.
ENTER A, B is basically equivalent to:
push %rbp mov %rsp, %rbp sub %rsp, A
which implies an allocation of:
-
one dword to remember EBP
-
A bytes for local function variables
I didn’t have the patience to study the B parameter, and it does not seem to be used often: https://stackoverflow.com/questions/26323215/do-any-languages-compilers-utilize-the-x86-enter-instruction-with-a-nonzero-ne
LEAVE is equivalent to:
mov %rbp, %rsp pop %rbp
which restores RSP and RBP to the values they had before the prologue.
29.9. x86 miscellaneous instructions
Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 1 5.1.13 "Miscellaneous Instructions"
29.10. x86 random number generator instructions
Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 1 5.1.15 Random Number Generator Instructions
Example: userland/arch/x86_64/rdrand.S: RDRAND
If you run that executable multiple times, it prints a random number every time to stdout.
RDRAND is a true random number generator!
This Intel engineer says its based on quantum effects: https://stackoverflow.com/questions/17616960/true-random-numbers-with-c11-and-rdrand/18004959#18004959
Generated some polemic when kernel devs wanted to use it as part of /dev/random, because it could be used as a cryptographic backdoor by Intel since it is a black box.
RDRAND sets the carry flag when data is ready so we must loop if the carry flag isn’t set.
29.10.1. x86 CPUID instruction
Example: userland/arch/x86_64/cpuid.S
Fills EAX, EBX, ECX and EDX with CPU information.
The exact data to show depends on the value of EAX, and for a few cases instructions ECX. When it depends on ECX, it is called a sub-leaf. Out test program prints eax == 0.
On 2017 Lenovo ThinkPad P51 for example the output EAX, EBX, ECX and EDX are:
0x00000016 0x756E6547 0x6C65746E 0x49656E69
EBX and ECX are easy to interpret:
-
EBX: 75 6e 65 47 == 'u', 'n', 'e', 'G' in ASCII
-
ECX: 6C 65 74 6E == 'l', 'e', 't', 'n'
so we see the string Genu ntel which is a shorthand for "Genuine Intel". Ha, I wonder if they had serious CPU pirating problems in the past? :-)
Information available includes:
-
vendor
-
version
-
features (mmx, simd, rdrand, etc.) <http://en.wikipedia.org/wiki/CPUID# EAX.3D1:_Processor_Info_and_Feature_Bits>
-
caches
-
tlbs http://en.wikipedia.org/wiki/Translation_lookaside_buffer
The cool thing about this instruction is that it allows you to check the CPU specs and take alternative actions based on that inside your program.
On Linux, the capacity part of this information is parsed and made available at cat /proc/cpuinfo. See: http://unix.stackexchange.com/questions/43539/what-do-the-flags-in-proc-cpuinfo-mean
There is also the cpuinfo command line tool that parses the CPUID instruction from the command line. Source: http://www.etallen.com/cpuid.html
29.11. x86 x87 FPU instructions
Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 1 5.2 "X87 FPU INSTRUCTIONS"
Old floating point unit that you should likely not use anymore, prefer instead the newer x86 SIMD instructions.
-
FPU basic examples, start here
-
userland/arch/x86_64/fadd.S FADD. The x76 FPU works on a stack of floating point numbers.
-
userland/arch/x86_64/faddp.S FADDP. Instructions with the P suffix also Pop the stack. This is often what you want for most computations, where the intermediate results don’t matter.
-
userland/arch/x86_64/fldl_literal.S FLDL literal. It does not seem possible to either https://stackoverflow.com/questions/6514537/how-do-i-specify-immediate-floating-point-numbers-with-inline-assembly
-
load floating point immediates into x86 x87 FPU registers
-
encode floating point literals in x86 instructions, including MOV
-
-
-
Bulk instructions
-
userland/arch/x86_64/fabs.S FABS: absolute value:
ST0 = |ST0| -
userland/arch/x86_64/fchs.S FCHS: change sign:
ST0 = -ST0 -
userland/arch/x86_64/fild.S FILD: Integer Load. Convert integer to float.
-
userland/arch/x86_64/fld1.S FLD1: Push 1.0 to ST0. CISC!
-
userland/arch/x86_64/fldz.S FLDZ: Push 0.0 to ST0.
-
userland/arch/x86_64/fscale.S FSCALE:
ST0 = ST0 * 2 ^ RoundTowardZero(ST1) -
userland/arch/x86_64/fsqrt.S FSQRT: square root
-
userland/arch/x86_64/fxch.S FXCH: swap ST0 and another register
-
The ST0-ST7 x87 FPU registers are actually 80-bits wide, this can be seen from GDB with:
i r st0 st1
By counting the number of hex digits, we have 20 digits instead of 16!
Instructions such as FLDL convert standard IEEE 754 64-bit values from memory into this custom 80-bit format.
29.11.1. x86 x87 FPU vs SIMD
Modern x86 has two main ways of doing floating point operations:
Advantages of FPU:
-
present in old CPUs, while SSE2 is only required in x86-64
-
contains some instructions no present in SSE, e.g. trigonometric
-
higher precision: FPU holds 80 bit Intel extension, while SSE2 only does up to 64 bit operations despite having the 128-bit register
In GCC, you can choose between them with -mfpmath=.
29.12. x86 SIMD
Parent section: Section 28.3, “SIMD assembly”
History:
-
MMX: MultiMedia eXtension (unofficial name). 1997. MM0-MM7 64-bit registers.
-
SSE: Streaming SIMD Extensions. 1999. XMM0-XMM7 128-bit registers, XMM0-XMM15 for AMD in 64-bit mode.
-
SSE2: 2004
-
SSE3: 2006
-
SSE4: 2006
-
AVX: Advanced Vector Extensions. 2011. YMM0–YMM15 256-bit registers in 64-bit mode. Extension of XMM.
-
AVX2:2013
-
AVX-512: 2016. 512-bit ZMM registers. Extension of YMM.
29.12.1. x86 SSE instructions
Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 1 5.5 "SSE INSTRUCTIONS"
29.12.1.1. x86 SSE data transfer instructions
Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 1 5.5.1.1 "SSE Data Transfer Instructions"
-
userland/arch/x86_64/movaps.S: MOVAPS: move 4 x 32-bits between two XMM registeres or XMM registers and 16-byte aligned memory
-
userland/arch/x86_64/movaps.S: MOVUPS: like MOVAPS but also works for unaligned memory
-
userland/arch/x86_64/movss.S: MOVSS: move 32-bits between two XMM registeres or XMM registers and memory
29.12.1.2. x86 SSE packed arithmetic instructions
Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 1 5.5.1.2 "SSE Packed Arithmetic Instructions"
-
userland/arch/x86_64/addpd.S: ADDPS, ADDPD: good first instruction to learn SIMD assembly.
29.12.1.3. x86 SSE conversion instructions
Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 1 5.5.1.6 "SSE Conversion Instructions"
29.12.2. x86 SSE2 instructions
Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 1 5.6 "SSE2 INSTRUCTIONS"
-
userland/arch/x86_64/cvttss2si.S: CVTTSS2SI: convert 32-bit floating point to 32-bit integer, store the result in a general purpose register. Round towards 0.
29.12.2.1. x86 PADDQ instruction
userland/arch/x86_64/paddq.S: PADDQ, PADDL, PADDW, PADDB
Good first instruction to learn SIMD assembly.
29.12.3. x86 fused multiply add (FMA)
Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 1 5.15 "FUSED-MULTIPLY-ADD (FMA)"
-
userland/arch/x86_64/vfmadd132pd.S: VFMADD132PD: "Multiply packed double-precision floating-point values from xmm1 and xmm3/mem, add to xmm2 and put result in xmm1." TODO: but I don’t understand the manual, experimentally on 2017 Lenovo ThinkPad P51 Ubuntu 19.04 host the result is stored in XMM2!
These instructions were not part of any SSEn set: they actually have a dedicated CPUID flag for it! It appears under /proc/cpuinfo as fma. They were introduced into AVX512F however.
They are also unusual for x86 instructions in that they take 3 operands, as you would intuitively expect from the definition of FMA.
29.13. x86 system instructions
Intel 64 and IA-32 Architectures Software Developer’s Manuals Volume 1 5.20 "SYSTEM INSTRUCTIONS"
29.13.1. x86 RDTSC instruction
Sources:
Try running the programs multiple times, and watch the value increase, and then try to correlate it with /proc/cpuinfo frequency!
while true; do sleep 1 && ./userland/arch/x86_64/rdtsc.out; done
RDTSC stores its output to EDX:EAX, even in 64-bit mode, top bits are zeroed out.
TODO: review this section, make a more controlled userland experiment with m5ops instrumentation.
Let’s have some fun and try to correlate the gem5 m5out/stats.txt file system.cpu.numCycles cycle count with the x86 RDTSC instruction that is supposed to do the same thing:
./build-userland userland/arch/x86_64/inline_asm/rdtsc.S ./run --eval './arch/x86_64/rdtsc.out;m5 exit;' --emulator gem5 ./gem5-stat
RDTSC outputs a cycle count which we compare with gem5’s gem5-stat:
-
3828578153: RDTSC -
3830832635:gem5-stat
which gives pretty close results, and serve as a nice sanity check that the cycle counter is coherent.
It is also nice to see that RDTSC is a bit smaller than the stats.txt value, since the latter also includes the exec syscall for m5.
Bibliography:
29.13.1.1. x86 RDTSCP instruction
RDTSCP is like RDTSP, but it also stores the CPU ID into ECX: this is convenient because the value of RDTSC depends on which core we are currently on, so you often also want the core ID when you want the RDTSC.
Sources:
We can observe its operation with the good and old taskset, for example:
taskset -c 0 ./userland/arch/x86_64/rdtscp.out | tail -n 1 taskset -c 1 ./userland/arch/x86_64/rdtscp.out | tail -n 1
produces:
0x00000000 0x00000001
There is also the RDPID instruction that reads just the processor ID, but it appears to be very new for QEMU 4.0.0 or 2017 Lenovo ThinkPad P51, as it fails with SIGILL on both.
Bibliography:
29.14. x86 thread synchronization primitives
29.14.1. x86 LOCK prefix
Inline assembly example at: userland/cpp/atomic/x86_64_lock_inc.cpp, see also: atomic.cpp.
Ensures that memory modifications are visible across all CPUs, which is fundamental for thread synchronization.
Apparently already automatically implied by some of the x86 exchange instructions
Bibliography:
29.15. x86 assembly bibliography
29.15.1. x86 official bibliography
29.15.1.1. Intel 64 and IA-32 Architectures Software Developer’s Manuals
We are using the May 2019 version unless otherwise noted.
There are a few download forms at: https://software.intel.com/en-us/articles/intel-sdm
The single PDF one is useless however because it does not have a unified ToC nor inter Volume links, so I just download the 4-part one.
The Volumes are well split, so it is usually easy to guess where you should look into.
Also I can’t find older versions on the website easily, so I just web archive everything.
30. ARM userland assembly
Arch general getting started at: Section 28, “Userland assembly”.
Instructions here loosely grouped based on that of the ARMv7 architecture reference manual Chapter A4 "The Instruction Sets".
We cover here mostly ARMv7, and then treat aarch64 differentially, since much of the ARMv7 userland is the same in aarch32.
30.1. Introduction to the ARM architecture
The ARM architecture is has been used on the vast majority of mobile phones in the 2010’s, and on a large fraction of micro controllers.
It competes with x86 userland assembly because its implementations are designed for low power consumption, which is a major requirement of the cell phone market.
ARM is generally considered a RISC instruction set, although there are some more complex instructions which would not generally be classified as purely RISC.
ARM is developed by the British funded company ARM Holdings: https://en.wikipedia.org/wiki/Arm_Holdings which originated as a joint venture between Acorn Computers, Apple and VLSI Technology in 1990.
ARM Holdings was bought by the Japanese giant SoftBank in 2016.
30.1.1. ARMv8 vs ARMv7 vs AArch64 vs AArch32
ARMv7 is the older architecture described at: ARMv7 architecture reference manual.
ARMv8 is the newer architecture ISA released in 2013 and described at: ARMv8 architecture reference manual. It can be in either of two states:
-
aarch64
In the lose terminology of this repository:
-
armmeans basically AArch32 -
aarch64means ARMv8 AArch64
ARMv8 has had several updates since its release:
-
v8.1: 2014
-
v8.2: 2016
-
v8.3: 2016
-
v8.4: TODO
-
v8.5: 2018
They are described at: ARMv8 architecture reference manual A1.7 "ARMv8 architecture extensions".
30.1.1.1. AArch32
32-bit mode of operation of ARMv8.
Userland is highly / fully backwards compatible with ARMv7:
For this reason, QEMU and GAS seems to enable both AArch32 and ARMv7 under arm rather than aarch64.
There are however some extensions over ARMv7, many of them are functionality that ARMv8 has and that designers decided to backport on AArch32 as well, e.g.:
30.1.1.2. AArch32 vs AArch64
A great summary of differences can be found at: https://en.wikipedia.org/wiki/ARM_architecture#AArch64_features
Some random ones:
-
aarch32 has two encodings: Thumb and ARM: Section 30.1.3, “ARM instruction encodings”
-
in ARMv8, the stack can be enforced to 16-byte alignment: Section 30.3.2.2.1, “ARMV8 aarch64 stack alignment”
30.1.2. Free ARM implementations
The ARM instruction set is itself protected by patents / copyright / whatever, and you have to pay ARM Holdings a licence to implement it, even if you are creating your own custom Verilog code.
ARM has already sued people in the past for implementing ARM ISA: http://www.eetimes.com/author.asp?section_id=36&doc_id=1287452
Asanovic joked that the shortest unit of time is not the moment between a traffic light turning green in New York City and the cab driver behind the first vehicle blowing the horn; it’s someone announcing that they have created an open-source, ARM-compatible core and receiving a “cease and desist” letter from a law firm representing ARM.
This licensing however does have the following fairness to it: ARM Holdings invents a lot of money in making a great open source software environment for the ARM ISA, so it is only natural that it should be able to get some money from hardware manufacturers for using their ISA.
Patents for very old ISAs however have expired, Amber is one implementation of those: https://en.wikipedia.org/wiki/Amber_%28processor_core%29 TODO does it have any application?
Generally, it is mostly large companies that implement the CPUs themselves. For example, the Apple A12 chip, which is used in iPhones, has verilog designs:
The A12 features an Apple-designed 64-bit ARMv8.3-A six-core CPU, with two high-performance cores running at 2.49 GHz called Vortex and four energy-efficient cores called Tempest.
ARM designed CPUs however are mostly called Coretx-A<id>: https://en.wikipedia.org/wiki/List_of_applications_of_ARM_cores Vortex and Tempest are Apple designed ones.
Bibliography: https://www.quora.com/Why-is-it-that-you-need-a-license-from-ARM-to-design-an-ARM-CPU-How-are-the-instruction-sets-protected
30.1.3. ARM instruction encodings
Understanding the basics of instruction encodings is fundamental to help you to remember what instructions do and why some things are possible or not, notably the ARM LDR pseudo-instruction and the ADRP instruction.
aarch32 has two "instruction sets", which to look just like encodings.
The encodings are:
-
A32: every instruction is 4 bytes long. Can encode every instruction.
-
T32: most common instructions are 2 bytes long. Many others less common ones are 4 bytes long.
T stands for "Thumb", which is the original name for the technology, ARMv8 architecture reference manual A1.3.2 "The ARM instruction sets" says:
In previous documentation, these instruction sets were called the ARM and Thumb instruction sets
See also: ARMv8 architecture reference manual F2.1.3 "Instruction encodings".
Within each instruction set, there can be multiple encodings for a given function, and they are noted simply as:
-
A1, A2, …: A32 encodings
-
T1, T2, ..m: T32 encodings
The state bit PSTATE.T determines if the processor is in thumb mode or not. ARMv8 architecture reference manual says that this bit it can only be read from ARM BX instruction
https://stackoverflow.com/questions/22660025/how-can-i-tell-if-i-am-in-arm-mode-or-thumb-mode-in-gdb
TODO: details: https://stackoverflow.com/questions/22660025/how-can-i-tell-if-i-am-in-arm-mode-or-thumb-mode-in-gdb says it is 0x20 & CPSR.
This RISC-y mostly fixed instruction length design likely makes processor design easier and allows for certain optimizations, at the cost of slightly more complex assembly, as you can’t encode 4 / 8 byte addresses in a single instruction. Totally worth it IMHO.
This design can be contrasted with x86, which has widely variable instruction length.
We can swap between A32 and T32 with the BX and BLX instructions: http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.kui0100a/armasm_cihfddaf.htm puts it really nicely:
The BL and BLX instructions copy the address of the next instruction into lr (r14, the link register).
The BX and BLX instructions can change the processor state from ARM to Thumb, or from Thumb to ARM.
BLX label always changes the state.
BX Rm and BLX Rm derive the target state from bit[0] of Rm:
if bit[0] of Rm is 0, the processor changes to, or remains in, ARM state
if bit[0] of Rm is 1, the processor changes to, or remains in, Thumb state.
The BXJ instruction changes the processor state to Jazelle.
Bibliography:
30.1.3.1. ARM Thumb encoding
Thumb examples are available at:
For both of them, we can check that we are in thumb from inside GDB with:
-
disassemble, and observe that some of the instructions are only 2 bytes long instead of always 4 as in ARM -
print $cpsr & 0x20which is1on thumb and0otherwise
You should contrast those examples with similar non-thumb ones of course.
We also note that thumbness of those sources is determined solely by the .thumb_func directive, which implies that there must be some metadata to allow the linker to decide how that code should be called:
-
for the freestanding example, this is determined by the first bit of the entry address ELF header as mentioned at: https://stackoverflow.com/questions/20369440/can-start-be-the-thumb-function/20374451#20374451
We verify that with:
./run-toolchain --arch arm readelf -- -h "$(./getvar --arch arm userland_build_dir)/arch/arm/freestanding/linux/hello_thumb.out"
The Linux kernel must use that to decide put the CPU in thumb mode: that could be done simply with a regular BX.
-
on the non-freestanding one, the linker uses some ELF metadata to decide that
mainis thumb and jumps to it appropriately: https://reverseengineering.stackexchange.com/questions/6080/how-to-detect-thumb-mode-in-arm-disassemblyTODO details. Does the linker then resolve thumbness with address relocation? Doesn’t this imply that the compiler cannot generate BL (never changes) or BLX (always changes) across object files, only BX (target state controlled by lower bit)?
30.1.3.2. ARM big endian mode
ARM can switch between big and little endian mode on the fly!
However, everyone only uses little endian, so the big endian ecosystem is not as supported.
TODO is there any advantage of using big endian?
Here Peter mentions that QEMU does "support" big endian in theory, but that there are no machines for it not sure what that implies: https://stackoverflow.com/questions/41571643/emulatin-big-endian-arm-system-with-qemu
We can try it out quickly in user mode with:
touch userland/arch/aarch64/freestanding/linux/hello.S ./build-userland --arch aarch64 --ccflags=-mbig-endian userland/arch/aarch64/freestanding/linux/hello.S ./run --arch aarch64 --userland userland/arch/aarch64/freestanding/linux/hello.S
and it fails with:
Invalid ELF image for this architecture
From this we can guess that the big endian metadata is actually stored in the ELF file, and confirm that with:
./run-toolchain \ --arch aarch64 \ readelf \ -- \ --file-header "$(./getvar --arch aarch64 userland_build_dir)/arch/aarch64/freestanding/linux/hello.out" \ ;
which contains:
Data: 2's complement, big endian
instead of the default:
Data: 2's complement, little endian
TODO does the Linux kernel support running big endian executables? I tried after building the big endian executable:
./build-buildroot --arch aarch64 ./run --arch aarch64 --eval-after ./arch/aarch64/freestanding/linux/hello.out
but that failed with:
/lkmc/arch/aarch64/freestanding/linux/hello.out: line 1: ELF@x@0@8@: not found /lkmc/arch/aarch64/freestanding/linux/hello.out: line 2: @@: not found /lkmc/arch/aarch64/freestanding/linux/hello.out: line 3: syntax error: unexpected ")"
TODO:
-
can you compile the Linux kernel itself as big endian? Looks like yes since there is a
config CPU_BIG_ENDIANSee also: https://unix.stackexchange.com/questions/378829/getting-big-endian-linux-build-to-boot-on-arm-with-u-boot -
how can be is the endianess be checked and modified in the CPU?
30.2. ARM branch instructions
30.2.1. ARM B instruction
Unconditional branch.
Example: userland/arch/arm/b.S
The encoding stores PC offsets in 24 bits. The destination must be a multiple of 4, which is easy since all instructions are 4 bytes.
This allows for 26 bit long jumps, which is 64 MiB.
TODO: what to do if we want to jump longer than that?
30.2.2. ARM BEQ instruction
Branch if equal based on the status registers.
Examples:
The family of instructions includes:
-
BEQ: branch if equal
-
BNE: branch if not equal
-
BLE: less or equal
-
BGE: greater or equal
-
BLT: less than
-
BGT: greater than
30.2.3. ARM BL instruction
Branch with link, i.e. branch and store the return address on the RL register.
Example: userland/arch/arm/bl.S
This is the major way to make function calls.
The current ARM / Thumb mode is encoded in the least significant bit of lr.
30.2.3.2. ARMv8 aarch64 ret instruction
Example: userland/arch/aarch64/ret.S
ARMv8 AArch64 only:
-
there is no BX in AArch64 since no Thumb to worry about, so it is called just BR
-
the RET instruction was added in addition to BR, with the following differences:
-
provides a hint that this is a function call return
-
has a default argument X30 if none is given. This is where BL puts the return value.
-
30.2.4. ARM CBZ instruction
Compare and branch if zero.
Example: userland/arch/aarch64/cbz.S
Only in ARMv8 and ARMv7 Thumb mode, not in armv7 ARM mode.
Very handy!
30.2.5. ARM conditional execution
Weirdly, ARM B instruction and family are not the only instructions that can execute conditionally on the flags: the same also applies to most instructions, e.g. ADD.
Example: userland/arch/arm/cond.S
Just add the usual eq, ne, etc. suffixes just as for B.
The list of all extensions is documented at ARMv7 architecture reference manual "A8.3 Conditional execution".
30.3. ARM load and store instructions
In ARM, there are only two instruction families that do memory access:
-
ARM LDR instruction to load from memory to registers
-
ARM STR instruction to store from registers to memory
Everything else works on register and immediates.
This is part of the RISC-y beauty of the ARM instruction set, unlike x86 in which several operations can read from memory, and helps to predict how to optimize for a given CPU pipeline.
This kind of architecture is called a Load/store architecture.
30.3.1. ARM LDR instruction
30.3.1.1. ARM LDR pseudo-instruction
LDR can be either a regular instruction that loads stuff into memory, or also a pseudo-instruction (assembler magic): http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dui0041c/Babbfdih.html
The pseudo instruction version is when an equal sign appears on one of the operators.
The LDR pseudo instruction can automatically create hidden variables in a place called the "literal pool", and load them from memory with PC relative loads.
Example: userland/arch/arm/ldr_pseudo.S
This is done basically because all instructions are 32-bit wide, and there is not enough space to encode 32-bit addresses in them.
Bibliography:
30.3.1.2. ARM addressing modes
Example: userland/arch/arm/address_modes.S
Load and store instructions can update the source register with the following modes:
-
offset: add an offset, don’t change the address register. Notation:
ldr r1, [r0, 4]
-
pre-indexed: change the address register, and then use it modified. Notation:
ldr r1, [r0, 4]!
-
post-indexed: use the address register unmodified, and then modify it. Notation:
ldr r1, [r0], 4
The offset itself can come from the following sources:
-
immediate
-
register
-
scaled register: left shift the register and use that as an offset
The indexed modes are convenient to loop over arrays.
Bibliography: ARMv7 architecture reference manual:
-
A4.6.5 "Addressing modes"
-
A8.5 "Memory accesses"
ARMv8 architecture reference manual: C1.3.3 "Load/Store addressing modes"
30.3.1.2.1. ARM loop over array
As an application of the post-indexed addressing mode, let’s increment an array.
Example: userland/arch/arm/inc_array.S
30.3.1.3. ARM LDRH and LDRB instructions
There are LDR variants that load less than full 4 bytes:
-
userland/arch/arm/ldrb.S: load byte
-
userland/arch/arm/ldrh.S: load half word
These also have signed and unsigned versions to either zero or one extend the result:
-
userland/arch/aarch64/ldrsw.S: load byte and sign extend
30.3.2. ARM STR instruction
Store from memory into registers.
Example: userland/arch/arm/str.S
Basically everything that applies to ARM LDR instruction also applies here so we won’t go into much detail.
30.3.2.1. ARMv8 aarch64 STR instruction
PC-relative STR is not possible in aarch64.
For LDR it works as in aarch32.
As a result, it is not possible to load from the literal pool for STR.
Example: userland/arch/aarch64/str.S
This can be seen from ARMv8 architecture reference manual C3.2.1 "Load/Store register": LDR simply has on extra PC encoding that STR does not.
30.3.2.2. ARMv8 aarch64 LDP and STP instructions
Push a pair of registers to the stack.
TODO minimal example. Currently used in LKMC_PROLOGUE at lkmc/aarch64.h since it is the main way to restore register state.
30.3.2.2.1. ARMV8 aarch64 stack alignment
In ARMv8, the stack can be enforced to 16-byte alignment.
This is why the main way to push things to stack is with 8-byte pair pushes with the ARMv8 aarch64 LDP and STP instructions.
ARMv8 architecture reference manual db C1.3.3 "Load/Store addressing modes" says:
When stack alignment checking is enabled by system software and the base register is the SP, the current stack pointer must be initially quadword aligned, that is aligned to 16 bytes. Misalignment generates a Stack Alignment fault. The offset does not have to be a multiple of 16 bytes unless the specific Load/Store instruction requires this. SP cannot be used as a register offset.
ARMv8 architecture reference manual db C3.2 "Loads and stores" says:
The additional control bits SCTLR_ELx.SA and SCTLR_EL1.SA0 control whether the stack pointer must be quadword aligned when used as a base register. See SP alignment checking on page D1-2164. Using a misaligned stack pointer generates an SP alignment fault exception.
ARMv8 architecture reference manual db D1.8.2 "SP alignment checking" is then the main section.
TODO: what does the ABI say on this? Why don’t I observe faults on QEMU as mentioned at: https://stackoverflow.com/questions/212466/what-is-a-bus-error/31877230#31877230
See also:
30.3.3. ARM LDMIA instruction
Pop values form stack into the register and optionally update the address register.
STMDB is the push version.
Example: userland/arch/arm/ldmia.S
The mnemonics stand for:
-
STMDB: STore Multiple Decrement Before
-
LDMIA: LoaD Multiple Increment After
Example: userland/arch/arm/push.S
PUSH and POP are just mnemonics STDMDB and LDMIA using the stack pointer SP as address register:
stmdb sp!, reglist ldmia sp!, reglist
The ! indicates that we want to update the register.
The registers are encoded as single bits inside the instruction: each bit represents one register.
As a consequence, the push order is fixed no matter how you write the assembly instruction: there is just not enough space to encode ordering.
AArch64 loses those instructions, likely because it was not possible anymore to encode all registers: https://stackoverflow.com/questions/27941220/push-lr-and-pop-lr-in-arm-arch64 and replaces them with the ARMv8 aarch64 LDP and STP instructions
30.4. ARM data processing instructions
Arithmetic:
-
userland/arch/arm/mul.S: multiply
-
userland/arch/arm/sub.S: subtract
-
userland/arch/arm/rbit.S: reverse bit order
-
userland/arch/arm/rev.S: reverse byte order
30.4.1. ARM CSET instruction
Example: userland/arch/aarch64/cset.S
Set a register conditionally depending on the condition flags:
ARMv8-only, likely because in ARMv8 you can’t have conditional suffixes for every instruction.
30.4.2. ARM bitwise instructions
-
EOR: exclusive OR
-
userland/arch/arm/clz.S: count leading zeroes
30.4.2.1. ARM BIC instruction
Bitwise Bit Clear: clear some bits.
dest = left & ~right
Example: userland/arch/arm/bic.S
30.4.2.2. ARM UBFM instruction
Unsigned Bitfield Move.
copies any number of low-order bits from a source register into the same number of adjacent bits at any position in the destination register, with zeros in the upper and lower bits.
Example: userland/arch/aarch64/ubfm.S
TODO: explain full behaviour. Very complicated. Has several simpler to understand aliases.
30.4.2.2.1. ARM UBFX instruction
Alias for:
UBFM <Wd>, <Wn>, #<lsb>, #(<lsb>+<width>-1)
Example: userland/arch/aarch64/ubfx.S
The operation:
UBFX dest, src, lsb, width
does:
dest = (src & ((1 << width) - 1)) >> lsb;
30.4.2.3. ARM BFM instruction
TODO: explain. Similar to UBFM but leave untouched bits unmodified.
30.4.2.3.1. ARM BFI instruction
Examples:
Move the lower bits of source register into any position in the destination:
-
ARMv8: an alias for ARM BFM instruction
-
ARMv7: a real instruction
30.4.3. ARM MOV instruction
Move an immediate to a register, or a register to another register.
Cannot load from or to memory, since only the LDR and STR instruction families can do that in ARM as mentioned at: Section 30.3, “ARM load and store instructions”.
Example: userland/arch/arm/mov.S
Since every instruction has a fixed 4 byte size, there is not enough space to encode arbitrary 32-bit immediates in a single instruction, since some of the bits are needed to actually encode the instruction itself.
The solutions to this problem are mentioned at:
Summary of solutions:
-
place it in memory. But then how to load the address, which is also a 32-bit value?
-
use pc-relative addressing if the memory is close enough
-
use ORR encodable shifted immediates
-
The blog article summarizes nicely which immediates can be encoded and the design rationale:
An Operand 2 immediate must obey the following rule to fit in the instruction: an 8-bit value rotated right by an even number of bits between 0 and 30 (inclusive). This allows for constants such as 0xFF (0xFF rotated right by 0), 0xFF00 (0xFF rotated right by 24) or 0xF000000F (0xFF rotated right by 4).
In software - especially in languages like C - constants tend to be small. When they are not small they tend to be bit masks. Operand 2 immediates provide a reasonable compromise between constant coverage and encoding space; most common constants can be encoded directly.
Assemblers however support magic memory allocations which may hide what is truly going on: https://stackoverflow.com/questions/14046686/why-use-ldr-over-mov-or-vice-versa-in-arm-assembly Always ask your friendly disassembly for a good confirmation.
30.4.3.1. ARM movw and movt instructions
Set the higher or lower 16 bits of a register to an immediate in one go.
Example: userland/arch/arm/movw.S
The armv8 version analogue is ARMv8 aarch64 movk instruction.
30.4.3.2. ARMv8 aarch64 movk instruction
Fill a 64 bit register with 4 16-bit instructions one at a time.
Similar to ARM movw and movt instructions in v7.
Example: userland/arch/aarch64/movk.S
30.4.3.3. ARMv8 aarch64 movn instruction
Set 16-bits negated and the rest to 1.
Example: userland/arch/aarch64/movn.S
30.4.4. ARM data processing instruction suffixes
30.4.4.1. ARM shift suffixes
Most data processing instructions can also optionally shift the second register operand.
Example: userland/arch/arm/shift.S
The shift types are:
-
LSR and LFL: Logical Shift Right / Left. Insert zeroes.
-
ROR: Rotate Right / Left. Wrap bits around.
-
ASR: Arithmetic Shift Right. Keep sign.
Documented at: ARMv7 architecture reference manual "A4.4.1 Standard data-processing instructions"
30.4.4.2. ARM S suffix
Example: userland/arch/arm/s_suffix.S
The S suffix, present on most ARM data processing instructions, makes the instruction also set the Status register flags that control conditional jumps.
If the result of the operation is 0, then it triggers BEQ, since comparison is a subtraction, with success on 0.
CMP sets the flags by default of course.
30.4.5. ARM ADR instruction
Similar rationale to the ARM LDR pseudo-instruction, allowing to easily store a PC-relative reachable address into a register in one go, to overcome the 4-byte fixed instruction size.
Examples:
30.5. ARM miscellaneous instructions
30.5.1. ARM NOP instruction
Parent section: Section 28.10, “NOP instructions”
There are a few different ways to encode NOP, notably MOV a register into itself, and a dedicated miscellaneous instruction.
Example: userland/arch/arm/nop.S
Try disassembling the executable to see what the assembler is emitting:
gdb-multiarch -batch -ex 'arch arm' -ex "file v7/nop.out" -ex "disassemble/rs asm_main_after_prologue"
30.5.2. ARM UDF instruction
Guaranteed undefined! Therefore raise illegal instruction signal. Used by GCC __builtin_trap apparently: https://stackoverflow.com/questions/16081618/programmatically-cause-undefined-instruction-exception
Why GNU GAS 2.29 does not have a mnemonic for it in A64 because it is very recent: shows in ARMv8 architecture reference manual db but not ca.
30.5.3. ARM system register instructions
Examples of using them can be found at: dump_regs
aarch64 only uses exactly 2 instructions:
-
MRS: reads a system register to a regular register
-
MSR: writes to the system register
aarch32 is a bit more messy due to older setups, we have both:
-
MRS and MSR which are much like in aarch64
-
coprocessor accesses:
-
MRC: reads a system register, C means coprocessor, which is how system registers were previously known as
-
MCR: write to the system register
-
MRRC: like MRC, but used for the system registers that are marked as 64-bit, and reads to two general purpose register
-
MCRR: write version of MCRR
-
TODO why both? For example, as mentioned at https://stackoverflow.com/questions/62920281/cross-compilng-c-program-for-armv8-a-in-linux-x86-64-system/62922677#62922677 a register that was accessed with MRC in armv7 can move to MRS in aarch64, as is the case for:
mrs r0, ctr /* aarch32 */ mrc x0, ctr_el0 /* aarch64 */
Other functionality has moved away from coprocessors into actual instructions, e.g. cache invalidation:
/* aarch32: DCISW, Data Cache line Invalidate by Set/Way. */ mcr p15, 0, r5, c7, c6, 2 /* aarch64: moved to one of the DC instruction variants. */ dc isw
ARMv8 architecture reference manual db G1.19.4 "Background to the System register interface" says that only CP14 and CP15 are specified by the ISA:
The interface to the System registers was originally defined as part of a generic coprocessor interface, that gave access to 15 coprocessors, CP0 - CP15. Of these, CP8 - CP15 were reserved for use by Arm, while CP0 - CP7 were available for IMPLEMENTATION DEFINED coprocessors.
and the actual coprocessor registers are specified in Chapter G7 "AArch32 System Register Encoding" at:
-
CP14: Table G7-1 "Mapping of (coproc ==0b1110) MCR, MRC, and MRRC instruction arguments to System registers"
-
CP15: Table G7-3 "VMSAv8-32 (coproc==0b1111) register summary, in MCR/MRC parameter order."
The actual MRC assembly does not exactly match the order of that table, this is how you can decode it, sample MCR:
mcr p15, 0, r5, c7, c6, 2
what each part means:
mcr p<coproc>, <opc1>, <src-dest-reg>, <CRn>, <CRm>, <opc2>
30.5.3.1. ARM system register encodings
Each aarch64 system register is specified in the encoding of ARM system register instructions by 5 integer numbers:
-
op0 -
op1 -
CRn -
CRm -
op2
The encodings are given on large tables in ARMv8 architecture reference manual db Chapter D12 "AArch64 System Register Encoding".
As shown in baremetal/arch/aarch64/dump_regs.c as of LKMC 4e05b00d23c73cc4d3b83be94affdb6f28008d99, you can use the encoding parameters directly in GNU GAS assembly:
uint32_t id_isar6_el1;
__asm__ ("mrs %0, s3_0_c0_c2_7" : "=r" (id_isar6_el1) : :);
LKMC_DUMP_SYSTEM_REGS_PRINTF("ID_ISAR6_EL1 0x%" PRIX32 "\n", id_isar6_el1);
This can be useful to refer to new system registers which your older version of GNU GAS version does not yet have a name for.
The Linux kernel also uses explicit sysreg encoding extensively since it is of course a very early user of many new system registers, this is done at arch/arm64/include/asm/sysreg.h in Linux v5.4.
30.6. ARM SIMD
Parent section: Section 28.3, “SIMD assembly”
30.6.1. ARM VFP
The name for the ARMv7 and AArch32 floating point and SIMD instructions / registers.
Vector Floating Point extension.
TODO I think it was optional in ARMv7, find quote.
VFP has several revisions, named as VFPv1, VFPv2, etc. TODO: announcement dates.
As mentioned at: https://stackoverflow.com/questions/37790029/what-is-difference-between-arm64-and-armhf/48954012#48954012 the Linux kernel shows those capabilities in /proc/cpuinfo with flags such as vfp, vfpv3 and others, see:
When a certain version of VFP is present on a CPU, the compiler prefix typically contains the hf characters which stands for Hard Float, e.g.: arm-linux-gnueabihf. This means that the compiler will emit VFP instructions instead of just using software implementations.
Bibliography:
-
ARMv7 architecture reference manual Appendix D6 "Common VFP Subarchitecture Specification". It is not part of the ISA, but just an extension. TODO: that spec does not seem to have the instructions documented, and instruction like VMOV just live with the main instructions. Is VMOV part of VFP?
-
https://mindplusplus.wordpress.com/2013/06/25/arm-vfp-vector-programming-part-1-introduction/
-
https://en.wikipedia.org/wiki/ARM_architecture#Floating-point_(VFP)
30.6.1.1. ARM VFP registers
TODO example
ARMv8 architecture reference manual E1.3.1 "The SIMD and floating-point register file" Figure E1-1 "SIMD and floating-point register file, AArch32 operation":
+-----+-----+-----+ | S0 | | | +-----+ D0 + | | S1 | | | +-----+-----+ Q0 | | S2 | | | +-----+ D1 + | | S3 | | | +-----+-----+-----+ | S4 | | | +-----+ D2 + | | S5 | | | +-----+-----+ Q1 | | S6 | | | +-----+ D3 + | | S7 | | | +-----+-----+-----+
Note how Sn is weirdly packed inside Dn, and Dn weirdly packed inside Qn, likely for historical reasons.
And you can’t access the higher bytes at D16 or greater with Sn.
30.6.1.3. ARM VCVT instruction
Example: userland/arch/arm/vcvt.S
Convert between integers and floating point.
ARMv7 architecture reference manual on rounding:
The floating-point to fixed-point operation uses the Round towards Zero rounding mode. The fixed-point to floating-point operation uses the Round to Nearest rounding mode.
Notice how the opcode takes two types.
E.g., in our 32-bit float to 32-bit unsigned example we use:
vld1.32.f32
30.6.1.3.1. ARM VCVTR instruction
Example: userland/arch/arm/vcvtr.S
Like ARM VCVT instruction, but the rounding mode is selected by the FPSCR.RMode field.
Selecting rounding mode explicitly per instruction was apparently not possible in ARMv7, but was made possible in AArch32 e.g. with ARMv8 AArch32 VCVTA instruction.
Rounding mode selection is exposed in the ANSI C standard through fesetround.
TODO: is the initial rounding mode specified by the ELF standard? Could not find a reference.
30.6.1.3.2. ARMv8 AArch32 VCVTA instruction
Example: userland/arch/arm/vcvt.S
Added in ARMv8 AArch32 only, not present in ARMv7.
In ARMv7, to use a non-round-to-zero rounding mode, you had to set the rounding mode with FPSCR and use the R version of the instruction e.g. ARM VCVTR instruction.
Now in AArch32 it is possible to do it explicitly per-instruction.
Also there was no ties to away mode in ARMv7. This mode does not exist in C99 either.
30.6.2. ARMv8 Advanced SIMD and floating-point support
The ARMv8 architecture reference manual specifies floating point and SIMD support in the main architecture at A1.5 "Advanced SIMD and floating-point support".
The feature is often refered to simply as "SIMD&FP" throughout the manual.
The Linux kernel shows /proc/cpuinfo compatibility as neon, which is yet another intermediate name that came up at some point, see: Section 30.6.2.2, “ARM NEON”.
Vs ARM VFP: https://stackoverflow.com/questions/4097034/arm-cortex-a8-whats-the-difference-between-vfp-and-neon
30.6.2.1. ARMv8 floating point availability
Support is semi-mandatory. ARMv8 architecture reference manual A1.5 "Advanced SIMD and floating-point support":
ARMv8 can support the following levels of support for Advanced SIMD and floating-point instructions:
Full SIMD and floating-point support without exception trapping.
Full SIMD and floating-point support with exception trapping.
No floating-point or SIMD support. This option is licensed only for implementations targeting specialized markets.
Note: All systems that support standard operating systems with rich application environments provide hardware support for Advanced SIMD and floating-point. It is a requirement of the ARM Procedure Call Standard for AArch64, see Procedure Call Standard for the ARM 64-bit Architecture.
Therefore it is in theory optional, but highly available.
This is unlike ARMv7, where floating point is completely optional through ARM VFP.
30.6.2.2. ARM NEON
Just an informal name for the "Advanced SIMD instructions"? Very confusing.
ARMv8 architecture reference manual F2.9 "Additional information about Advanced SIMD and floating-point instructions" says:
The Advanced SIMD architecture, its associated implementations, and supporting software, are commonly referred to as NEON technology.
https://developer.arm.com/technologies/neon mentions that is is present on both ARMv7 and ARMv8:
NEON technology was introduced to the Armv7-A and Armv7-R profiles. It is also now an extension to the Armv8-A and Armv8-R profiles.
30.6.3. ARMv8 AArch64 floating point registers
TODO example.
ARMv8 architecture reference manual B1.2.1 "Registers in AArch64 state" describes the registers:
32 SIMD&FP registers, V0 to V31. Each register can be accessed as:
A 128-bit register named Q0 to Q31.
A 64-bit register named D0 to D31.
A 32-bit register named S0 to S31.
A 16-bit register named H0 to H31.
An 8-bit register named B0 to B31.
Notice how Sn is very different between v7 ARM VFP registers and v8! In v7 it goes across Dn, and in v8 inside each Dn:
128 64 32 16 8 0
+---------------------------+-------------------+-------+---+---+
| Vn |
+---------------------------------------------------------------+
| Qn |
+---------------------------+-----------------------------------+
| Dn |
+-----------------------------------+
| Sn |
+---------------+
| Hn |
+-------+
|Bn |
+---+
30.6.3.1. ARMv8 aarch64 add vector instruction
Good first instruction to learn SIMD: SIMD assembly.
30.6.3.2. ARMv8 aarch64 FADD instruction
30.6.3.2.1. ARM FADD vs VADD
It is very confusing, but FADDS and FADDD in Aarch32 are pre-UAL for vadd.f32 and vadd.f64 which we use in this tutorial, see: Section 30.6.1.2, “ARM VADD instruction”
The same goes for most ARMv7 mnemonics: f* is old, and v* is the newer better syntax.
But then, in ARMv8, they decided to use ARMv8 aarch64 FADD instruction as the main floating point add name, and get rid of VADD!
Also keep in mind that fused multiply add is FMADD.
Examples at: Section 28.3, “SIMD assembly”
30.6.3.3. ARMv8 aarch64 LD2 instruction
Example: userland/arch/aarch64/ld2.S
We can load multiple vectors interleaved from memory in one single instruction!
This is why the ldN instructions take an argument list denoted by {} for the registers, much like armv7 ARM LDMIA instruction.
There are analogous LD3 and LD4 instruction.
30.6.4. ARM SIMD bibliography
-
GNU GAS tests under
gas/testsuite/gas/aarch64 -
https://stackoverflow.com/questions/2851421/is-there-a-good-reference-for-arm-neon-intrinsics
-
assembly optimized libraries:
30.6.5. ARM SVE
Scalable Vector Extension.
Examples:
To understand it, the first thing you have to look at is the execution example at Fig 1 of: https://alastairreid.github.io/papers/sve-ieee-micro-2017.pdf
aarch64 only, newer than ARM NEON.
It is called Scalable because it does not specify the vector width! Therefore we don’t have to worry about new vector width instructions every few years! Hurray!
The instructions then allow:
-
incrementing loop index by the vector length without explicitly hardcoding it
-
when the last loop is reached, extra bytes that are not multiples of the vector length get automatically masked out by the predicate register, and have no effect
Added to QEMU in 3.0.0 and gem5 in 2019 Q3.
TODO announcement date. Possibly 2017: https://alastairreid.github.io/papers/sve-ieee-micro-2017.pdf There is also a 2016 mention: https://community.arm.com/tools/hpc/b/hpc/posts/technology-update-the-scalable-vector-extension-sve-for-the-armv8-a-architecture
The Linux kernel shows /proc/cpuinfo compatibility as sve.
SVE support is indicated by ID_AA64PFR0_EL1.SVE which is dumped from baremetal/arch/aarch64/dump_regs.c.
Using SVE normally requires setting the CPACR_EL1.FPEN and ZEN bits, which as as of lkmc 29fd625f3fda79f5e0ee6cac43517ba74340d513 + 1 we also enable in our Baremetal bootloaders, see also: aarch64 baremetal NEON setup.
30.6.5.1. ARM SVE VADDL instruction
Get the SVE vector length. The following programs do that and print it to stdout:
30.6.5.2. Change ARM SVE vector length in emulators
gem5 covered at: https://stackoverflow.com/questions/57692765/how-to-change-the-gem5-arm-sve-vector-length
It is fun to observe this directly with the ARM SVE VADDL instruction in SE:
./run --arch aarch64 --userland userland/arch/aarch64/sve_addvl.S --emulator gem5 -- --param 'system.cpu[:].isa[:].sve_vl_se = 1' ./run --arch aarch64 --userland userland/arch/aarch64/sve_addvl.S --emulator gem5 -- --param 'system.cpu[:].isa[:].sve_vl_se = 2' ./run --arch aarch64 --userland userland/arch/aarch64/sve_addvl.S --emulator gem5 -- --param 'system.cpu[:].isa[:].sve_vl_se = 4'
which consecutively:
0x0000000000000080 0x0000000000000100 0x0000000000000200
which are multiples of 128.
TODO how to set it on QEMU at runtime? As of LKMC 37b93ecfbb5a1fcbd0c631dd0b42c5b9f2f8a89a + 1 QEMU outputs:
0x0000000000000800
30.6.5.3. SVE bibliography
-
https://www.rico.cat/files/ICS18-gem5-sve-tutorial.pdf step by step of a complete code execution examples, the best initial tutorial so far
-
https://static.docs.arm.com/dui0965/c/DUI0965C_scalable_vector_extension_guide.pdf
-
https://developer.arm.com/products/software-development-tools/hpc/documentation/writing-inline-sve-assembly quick inlining guide
30.6.5.3.1. SVE spec
ARMv8 architecture reference manual A1.7 "ARMv8 architecture extensions" says:
SVE is an optional extension to ARMv8.2. That is, SVE requires the implementation of ARMv8.2.
A1.7.8 "The Scalable Vector Extension (SVE)": then says that only changes to the existing registers are described in that manual, and that you should look instead at the "ARM Architecture Reference Manual Supplement, The Scalable Vector Extension (SVE), for ARMv8-A."
We then download the zip from: https://developer.arm.com/docs/ddi0584/latest/arm-architecture-reference-manual-supplement-the-scalable-vector-extension-sve-for-armv8-a and it contains the PDF: DDI0584A_d_SVE_supp_armv8A.pdf which we use here.
That document then describes the SVE instructions and registers.
30.7. ARM thread synchronization primitives
Parent section: Userland multithreading.
30.7.1. ARM LDXR and STXR instructions
Parent section: atomic.cpp
LDXR and STXR vs LDAXR and STLXR: https://stackoverflow.com/questions/21535058/arm64-ldxr-stxr-vs-ldaxr-stlxr TODO understand better and example.
LDXR and STXR for a so-called "Load-link/store-conditional" (LLSC) pattern: https://en.wikipedia.org/wiki/Load-link/store-conditional which appears in many RISC ISAs.
This pattern makes it such that basically:
-
LDXR marks an address for exclusive access by the current CPU
-
STXR:
-
marks the address as not being exclusive to other CPUs that may have done LDXR before
-
loads fine if the address is still marked as exclusive, and stores 0 on a third register for success
-
fails to load if the address is not, and stores 1 on the third register for failure
-
In case of failure, we just have to loop back to just before the LDXR and try again.
This is therefore basically a spinlock and should only be used to cover very short critical sections such as atomic increments.
C++ std::atomic uses this for increments before v8.1 ARM Large System Extensions (LSE): https://stackoverflow.com/questions/56810/how-do-i-start-threads-in-plain-c/52453291#52453291
30.7.2. ARM Large System Extensions (LSE)
Set of atomic and synchronization primitives added in ARMv8.1 architecture extension.
Documented at ARMv8 architecture reference manual db "ARMv8.1-LSE, ARMv8.1 Large System Extensions"
-
LDADD: userland/cpp/atomic/aarch64_ldadd.cpp, see also: atomic.cpp. Kernel inspiration: https://github.com/torvalds/linux/blob/v5.4/arch/arm64/include/asm/atomic_lse.h#L56
Bibliography:
30.8. ARMv8 architecture extensions
30.8.1. ARMv8.1 architecture extension
ARMv8 architecture reference manual db A1.7.3 "The ARMv8.1 architecture extension"
30.9. ARM PMU
The PMU (Performance Monitor Unit) is an unit in the ARM CPU that counts performance events of interest. These can be used to benchmark, and sometimes debug, code running on ARM CPUs.
It is documented at ARMv8 architecture reference manual db Chapter D7 "The Performance Monitors Extension">
The Linux kernel exposes some (all?) of those events through the arch-agnostic perf_event_open system call system call.
Exposing the PMU to Linux v5.9.2 requires a DTB entry of type:
pmu {
compatible = "arm,armv8-pmuv3";
interrupts = <0x01 0x04 0xf04>;
};
and if sucessful, a boot message shows:
<6>[ 0.044391] hw perfevents: enabled with armv8_pmuv3 PMU driver, 32 counters available
The PMU is exposed through ARM system register instructions, with registers that start with the prefix PM*.
<6>[ 0.044391] hw perfevents: enabled with armv8_pmuv3 PMU driver, 32 counters available
ARMv8 architecture reference manual db D7.11.3 "Common event numbers" gives the available standardized events. Address space is also reverved for vendor extensions. For example, from it we see that the instruction count is documented at:
0x0008, INST_RETIRED, Instruction architecturally executed
The counter increments for every architecturally executed instruction.
where "architecturally executed" is a reference to the possibility of Out-of-order execution in the implementation, which leads to some instructions being executed speculatively, but not have any side effects in the end.
30.9.1. ARM PMCCNTR register
TODO We didn’t manage to find a working ARM analogue to x86 RDTSC instruction: kernel_modules/pmccntr.c is oopsing, and even it if weren’t, it likely won’t give the cycle count since boot since it needs to be activate before it starts counting anything:
30.10. ARM assembly bibliography
30.10.1. ARM non-official bibliography
Good getting started tutorials:
30.10.2. ARM official bibliography
The official manuals were stored in http://infocenter.arm.com but as of 2017 they started to slowly move to https://developer.arm.com.
Each revision of a document has a "ARM DDI" unique document identifier.
The "ARM Architecture Reference Manuals" are the official canonical ISA documentation document. In this repository, we always reference the following revisions:
Bibliography: https://www.quora.com/Where-can-I-find-the-official-documentation-of-ARM-instruction-set-architectures-ISAs
30.10.2.1. ARMv7 architecture reference manual
The official comprehensive ARMv7 reference.
We use by default: DDI 0406C.d: https://static.docs.arm.com/ddi0406/cd/DDI0406C_d_armv7ar_arm.pdf
30.10.2.2. ARMv8 architecture reference manual
Latest version: https://developer.arm.com/docs/ddi0487/latest/arm-architecture-reference-manual-armv8-for-armv8-a-architecture-profile
Versions are determined by two letteres in lexicographical order, e.g.:
-
a
-
af
-
aj
-
aj
-
b
-
ba
-
bb
-
ca
The link: https://static.docs.arm.com/ddi0487/ca/DDI0487C_a_armv8_arm.pdf is the ca version for example.
The official comprehensive ARMv8 reference.
ISA quick references can be found in some places:
30.10.2.5. Programmer’s Guide for ARMv8-A
A more terse human readable introduction to the ARM architecture than the reference manuals.
Does not have as many assembly code examples as you’d hope however…
Latest version at: https://developer.arm.com/docs/den0024/latest/preface
30.10.2.6. Arm A64 Instruction Set Architecture: Future Architecture Technologies in the A architecture profile Documentation
This page contains the documentation of architecture features that were publicly announced but haven’t been merged into the main spec yet.
30.10.2.7. ARM processor documentation
ARM also releases documentation specific to each given processor.
This adds extra details to the more portable ARMv8 architecture reference manual ISA documentation.
For every processor, there are basically two key documents:
-
technical reference manual, e.g.: Arm Cortex‑A77 Technical Reference Manual r1p1
-
software optimization guide, e.g.: Arm Cortex‑A77 Software Optimization Guide r1p1
This contains some approximate instruction latencies and pipeline properties.
31. ELF
This is the main format for executables, object files (.o) and shared libraries (.so) in Linux.
An introduction to the format can be found at: https://cirosantilli.com/elf-hello-world
32. IEEE 754
33. Baremetal
Getting started at: Section 2.9, “Baremetal setup”
33.1. Baremetal GDB step debug
GDB step debug works on baremetal exactly as it does on the Linux kernel, which is described at: Section 3, “GDB step debug”.
Except that is is even cooler here since we can easily control and understand every single instruction that is being run!
For example, on the first shell:
./run --arch arm --baremetal userland/c/hello.c --gdb-wait
then on the second shell:
./run-gdb --arch arm --baremetal userland/c/hello.c -- main
Or if you are a tmux pro, do everything in one go with:
./run --arch arm --baremetal userland/c/hello.c --gdb
Alternatively, to start from the very first executed instruction of our tiny Baremetal bootloaders:
./run \ --arch arm \ --baremetal userland/c/hello.c \ --gdb-wait \ --tmux-args=--no-continue \ ;
analogously to what is done for Freestanding programs.
Now you can just stepi to when jumping into main to go to the C code in userland/c/hello.c.
This is specially interesting for the executables that don’t use the bootloader from under baremetal/arch/<arch>/no_bootloader/*.S, e.g.:
./run \ --arch arm \ --baremetal baremetal/arch/arm/no_bootloader/semihost_exit.S \ --gdb-wait \ --tmux-args=--no-continue \ ;
The cool thing about those examples is that you start at the very first instruction of your program, which gives more control.
Examples without bootloader are somewhat analogous to user mode Freestanding programs.
33.2. Baremetal bootloaders
As can be seen from Baremetal GDB step debug, all examples under baremetal/, with the exception of baremetal/arch/<arch>/no_bootloader, start from our tiny bootloaders:
Out simplistic bootloaders basically setup up just enough system state to allow calling:
-
C functions such as
exitfrom the assembly examples -
the
mainof C examples itself
The most important things that we setup in the bootloaders are:
-
the stack pointer
-
TODO: we don’t do this currently but maybe we should setup BSS
The C functions that become available as a result are:
-
Newlib functions implemented at baremetal/lib/syscalls.c
-
lkmc_non-Newlib functions implemented at lkmc.c
It is not possible to call those C functions from the examples that don’t use a bootloader.
For this reason, we tend to create examples with bootloaders, as it is easier to write them portably.
33.3. Baremetal linker script
For things to work in baremetal, we often have to layout memory in specific ways.
Notably, since we start with paging disabled, there are more constraints on where memory can or cannot go.
Especially for C programs, this memory layout is specified by a "linker script", which is present at: baremetal/link.ld
Note how our linker script also exposes some symbols to C:
lkmc_heap_low = .; lkmc_heap_top = .;
Those for example are required to implement malloc in Newlib. We can play with those variables more explicitly with baremetal/linker_variables.c:
./run --arch aarch64 --baremetal baremetal/linker_variables.c
33.4. Baremetal command line arguments
QEMU and gem5 currently supports baremetal CLI arguments!
You can see them in action e.g. with:
./run --arch aarch64 --baremetal userland/c/command_line_arguments.c --cli-args 'aa bb cc' ./run --arch aarch64 --userland userland/c/command_line_arguments.c --cli-args 'aa bb cc'
both of which output the exact same thing:
aa bb cc
This is implemented by parsing the command line arguments and placing them into memory where the code will find them.
This works by:
-
fixing the
argcandargvaddresses in memory in the Baremetal linker script -
the Baremetal bootloaders pass those addresses correctly to the call of
main -
our Python scripts write the desired binary memory values to a file
-
QEMU loads those files into memory with
-device loader: https://github.com/qemu/qemu/blob/60905286cb5150de854e08279bca7dfc4b549e91/docs/generic-loader.txt
It is worth noting that e.g. ARM has a Semihosting mechanism for loading CLI arguments through SYS_GET_CMDLINE, but our mechanism works in principle for any ISA.
33.4.1. gem5 baremetal arm CLI args
Currently not supported, so we just hardcode argc 0 on the arm baremetal bootloader.
I think we have to keep the CLI args below 32 GiB, otherwise argc cannot be correctly setup. But currently the gem5 text segment is exactly at 32 GiB, and we always place the CLI args higher in the Baremetal linker script.
33.5. Semihosting
Semihosting is a publicly documented interface specified by ARM Holdings that allows us to do some magic operations very useful in development, such as writting to the terminal or reading and writing host files.
It is documented at: https://developer.arm.com/docs/100863/latest/introduction
For example, all the following code make QEMU exit:
./run --arch arm --baremetal baremetal/arch/arm/semihost_exit.S ./run --arch arm --baremetal baremetal/arch/arm/no_bootloader/semihost_exit.S ./run --arch aarch64 --baremetal baremetal/arch/aarch64/semihost_exit.S ./run --arch aarch64 --baremetal baremetal/arch/aarch64/no_bootloader/semihost_exit.S
Sources:
That arm program program contains the code:
mov r0, #0x18 ldr r1, =#0x20026 svc 0x00123456
and we can see from the docs that 0x18 stands for the SYS_EXIT command.
This is also how we implement the exit(0) system call in C for QEMU, which is used for example at userland/c/exit0.c through the Newlib via the _exit function at baremetal/lib/syscalls.c.
Other magic operations we can do with semihosting besides exiting the on the host include:
-
read and write to host stdin and stdout
-
read and write to host files
Alternatives exist for some semihosting operations, e.g.:
The big advantage of semihosting is that it is standardized across all ARM boards, and therefore allows you to make a single image that does those magic operations instead of having to compile multiple images with different magic addresses.
The downside of semihosting is that it is ARM specific. TODO is it an open standard that other vendors can implement?
In QEMU, we enable semihosting with:
-semihosting
Newlib 9c84bfd47922aad4881f80243320422b621c95dc already has a semi-hosting implementation at:
newlib/libc/sys/arm/syscalls.c
TODO: how to use it? Possible through crosstool-NG? In the worst case we could just copy it.
Bibliography:
33.5.1. gem5 semihosting
For gem5, you need patches/manual/gem5-semihost.patch:
patch -d "$(./getvar gem5_source_dir)" -p 1 < patches/manual/gem5-semihost.patch
33.6. gem5 baremetal carriage return
TODO: our example is printing newlines without automatic carriage return \r as in:
enter a character
got: a
We use m5term by default, and if we try telnet instead:
telnet localhost 3456
it does add the carriage returns automatically.
33.7. Baremetal host packaged toolchain
For arm, some baremetal examples compile fine with:
sudo apt-get install gcc-arm-none-eabi qemu-system-arm ./build-baremetal --arch arm --gcc-which host-baremetal ./run --arch arm --baremetal userland/c/hello.c --qemu-which host
However, there are as usual limitations to using prebuilts:
-
certain examples fail to build with the Ubuntu packaged toolchain. E.g.: userland/c/exit0.c fails with:
/usr/lib/gcc/arm-none-eabi/6.3.1/../../../arm-none-eabi/lib/libg.a(lib_a-fini.o): In function `__libc_fini_array': /build/newlib-8gJlYR/newlib-2.4.0.20160527/build/arm-none-eabi/newlib/libc/misc/../../../../../newlib/libc/misc/fini.c:33: undefined reference to `_fini' collect2: error: ld returned 1 exit status
with the prebuilt toolchain, and I’m lazy to debug.
-
there seems to to be no analogous
aarch64Ubuntu package togcc-arm-none-eabi: https://askubuntu.com/questions/1049249/is-there-a-package-with-the-aarch64-version-of-gcc-arm-none-eabi-for-bare-metal
33.8. Baremetal C++
Didn’t get it working, traking at: https://github.com/cirosantilli/linux-kernel-module-cheat/issues/119
33.9. GDB builtin CPU simulator
It is incredible, but GDB also has a CPU simulator inside of it as documented at: https://sourceware.org/gdb/onlinedocs/gdb/Target-Commands.html
TODO: any advantage over QEMU? I doubt it, mostly using it as as toy for now:
Without running ./run, do directly:
./run-gdb --arch arm --baremetal userland/c/hello.c --sim
Then inside GDB:
load starti
and now you can debug normally.
Enabled with the crosstool-NG configuration:
CT_GDB_CROSS_SIM=y
which by grepping crosstool-NG we can see does on GDB:
./configure --enable-sim
Those are not set by default on gdb-multiarch in Ubuntu 16.04.
Bibliography:
33.9.1. GDB builtin CPU simulator userland
Since I had this compiled, I also decided to try it out on userland.
I was also able to run a freestanding Linux userland example on it: https://github.com/cirosantilli/arm-assembly-cheat/blob/cd232dcaf32c0ba6399b407e0b143d19b6ec15f4/v7/linux/hello.S
It just ignores the ARM SVC instruction however, and does not forward syscalls to the host like QEMU does.
Then I tried a glibc example: https://github.com/cirosantilli/arm-assembly-cheat/blob/cd232dcaf32c0ba6399b407e0b143d19b6ec15f4/v7/mov.S
First it wouldn’t break, so I added -static to the Makefile, and then it started failing with:
Unhandled v6 thumb insn
Doing:
help architecture
shows ARM version up to armv6, so maybe armv6 is not implemented?
33.10. ARM baremetal
In this section we will focus on learning ARM architecture concepts that can only learnt on baremetal setups.
Userland information can be found at: https://github.com/cirosantilli/arm-assembly-cheat
33.10.1. ARM exception levels
ARM exception levels are analogous to x86 rings.
The current EL can be determined by reading from certain registers, which we do with bit disassembly at:
./run --arch arm --baremetal userland/arch/arm/dump_regs.c ./run --arch aarch64 --baremetal baremetal/arch/aarch64/dump_regs.c
The relevant bits are:
-
arm:
CPSR.M -
aarch64:
CurrentEl.EL. This register is not accessible from EL0 for some weird reason however.
Sources:
The instructions that find the ARM EL are explained at: https://stackoverflow.com/questions/31787617/what-is-the-current-execution-mode-exception-level-etc
The lower ELs are not mandated by the architecture, and can be controlled through command line options in QEMU and gem5.
In QEMU, you can configure the lowest EL as explained at https://stackoverflow.com/questions/42824706/qemu-system-aarch64-entering-el1-when-emulating-a53-power-up
./run --arch arm --baremetal userland/arch/arm/dump_regs.c | grep CPSR.M ./run --arch arm --baremetal userland/arch/arm/dump_regs.c -- -machine virtualization=on | grep CPSR.M ./run --arch arm --baremetal userland/arch/arm/dump_regs.c -- -machine secure=on | grep CPSR.M ./run --arch aarch64 --baremetal baremetal/arch/aarch64/dump_regs.c | grep CurrentEL.EL ./run --arch aarch64 --baremetal baremetal/arch/aarch64/dump_regs.c -- -machine virtualization=on | grep CurrentEL.EL ./run --arch aarch64 --baremetal baremetal/arch/aarch64/dump_regs.c -- -machine secure=on | grep CurrentEL.EL
outputs respectively:
CPSR.M 0x3 CPSR.M 0x3 CPSR.M 0x3 CurrentEL.EL 0x1 CurrentEL.EL 0x2 CurrentEL.EL 0x3
TODO: why is arm CPSR.M stuck at 0x3 which equals Supervisor mode?
In gem5, you can configure the lowest EL with:
./run --arch arm --baremetal userland/arch/arm/dump_regs.c --emulator gem5 grep CPSR.M "$(./getvar --arch arm --emulator gem5 gem5_guest_terminal_file)" ./run --arch arm --baremetal userland/arch/arm/dump_regs.c --emulator gem5 -- --param 'system.have_virtualization = True' grep CPSR.M "$(./getvar --arch arm --emulator gem5 gem5_guest_terminal_file)" ./run --arch arm --baremetal userland/arch/arm/dump_regs.c --emulator gem5 -- --param 'system.have_security = True' grep CPSR.M "$(./getvar --arch arm --emulator gem5 gem5_guest_terminal_file)" ./run --arch aarch64 --baremetal baremetal/arch/aarch64/dump_regs.c --emulator gem5 grep CurrentEL.EL "$(./getvar --arch aarch64 --emulator gem5 gem5_guest_terminal_file)" ./run --arch aarch64 --baremetal baremetal/arch/aarch64/dump_regs.c --emulator gem5 -- --param 'system.have_virtualization = True' grep CurrentEL.EL "$(./getvar --arch aarch64 --emulator gem5 gem5_guest_terminal_file)" ./run --arch aarch64 --baremetal baremetal/arch/aarch64/dump_regs.c --emulator gem5 -- --param 'system.have_security = True' grep CurrentEL.EL "$(./getvar --arch aarch64 --emulator gem5 gem5_guest_terminal_file)"
output:
CPSR.M 0x3 CPSR.M 0xA CPSR.M 0x3 CurrentEL.EL 0x1 CurrentEL.EL 0x2 CurrentEL.EL 0x3
TODO: the call:
./run --arch arm --baremetal userland/arch/arm/dump_regs.c --emulator gem5 -- --param 'system.have_virtualization = True'
started failing with an exception since https://github.com/cirosantilli/linux-kernel-module-cheat/commit/add6eedb76636b8f443b815c6b2dd160afdb7ff4 at the instruction:
vmsr fpexc, r0
in baremetal/lib/arm.S. That patch however enables SIMD in baremetal, which I feel is more important.
According to ARMv7 architecture reference manual, access to that register is controlled by other registers NSACR.{CP11, CP10} and HCPTR so those must be turned off, but I’m lazy to investigate now, even just trying to dump those registers in userland/arch/arm/dump_regs.c also leads to exceptions…
33.10.1.1. ARM change exception level
TODO. Create a minimal runnable example of going into EL0 and jumping to EL1.
33.10.1.2. ARM SP0 vs SPx
See ARMv8 architecture reference manual db D1.6.2 "The stack pointer registers".
There is one SP per exception level.
This can also be seen clearly on the analysis at gem5 ExecContext::readIntRegOperand register resolution.
TODO create a minimal runnable example.
TODO: how to select to use SP0 in an exception handler?
33.10.2. ARM SVC instruction
This is the most basic example of exception handling we have.
We a handler for SVC, do an SVC, and observe that the handler got called and returned from C and assembly:
./run --arch aarch64 --baremetal baremetal/arch/aarch64/svc.c ./run --arch aarch64 --baremetal baremetal/arch/aarch64/svc_asm.S
Sources:
Sample output for the C one:
DAIF 0x3C0 SPSEL 0x1 VBAR_EL1 0x40000800 after_svc 0x4000209c lkmc_vector_trap_handler exc_type 0x11 exc_type is LKMC_VECTOR_SYNC_SPX ESR 0x5600ABCD ESR.EC 0x15 ESR.EC.ISS.imm16 0xABCD SP 0x4200C510 ELR 0x4000209C SPSR 0x600003C5 x0 0x0 x1 0x1 x2 0x15 x3 0x15 x4 0x4000A178 x5 0xFFFFFFF6 x6 0x4200C390 x7 0x78 x8 0x1 x9 0x14 x10 0x0 x11 0x0 x12 0x0 x13 0x0 x14 0x0 x15 0x0 x16 0x0 x17 0x0 x18 0x0 x19 0x0 x20 0x0 x21 0x0 x22 0x0 x23 0x0 x24 0x0 x25 0x0 x26 0x0 x27 0x0 x28 0x0 x29 0x4200C510 x30 0x40002064
The C code does an:
svc 0xABCD
and the value 0xABCD appears at the bottom of ARM ESR register:
ESR 0x5600ABCD ESR.EC 0x15 ESR.EC.ISS.imm16 0xABCD
The other important register is the ARM ELR register, which contains the return address after the exception.
From the output, we can see that it matches the value as obtained by taking the address of a label placed just after the SVC:
after_svc 0x4000209c ELR 0x4000209C
Both QEMU and gem5 are able to trace interrupts in addition to instructions, and it is instructive to enable both and have a look at the traces.
With QEMU -d tracing:
./run \ --arch aarch64 \ --baremetal baremetal/arch/aarch64/svc.c \ -- -d in_asm,int \ ;
the output at 8f73910dd1fc1fa6dc6904ae406b7598cdcd96d7 contains:
---------------- IN: main 0x40002098: d41579a1 svc #0xabcd Taking exception 2 [SVC] ...from EL1 to EL1 ...with ESR 0x15/0x5600abcd ...with ELR 0x4000209c ...to EL1 PC 0x40000a00 PSTATE 0x3c5 ---------------- IN: 0x40000a00: 14000225 b #0x40001294 ---------------- IN: 0x40001294: a9bf7bfd stp x29, x30, [sp, #-0x10]! 0x40001298: a9bf73fb stp x27, x28, [sp, #-0x10]! 0x4000129c: a9bf6bf9 stp x25, x26, [sp, #-0x10]! 0x400012a0: a9bf63f7 stp x23, x24, [sp, #-0x10]! 0x400012a4: a9bf5bf5 stp x21, x22, [sp, #-0x10]! 0x400012a8: a9bf53f3 stp x19, x20, [sp, #-0x10]! 0x400012ac: a9bf4bf1 stp x17, x18, [sp, #-0x10]! 0x400012b0: a9bf43ef stp x15, x16, [sp, #-0x10]! 0x400012b4: a9bf3bed stp x13, x14, [sp, #-0x10]! 0x400012b8: a9bf33eb stp x11, x12, [sp, #-0x10]! 0x400012bc: a9bf2be9 stp x9, x10, [sp, #-0x10]! 0x400012c0: a9bf23e7 stp x7, x8, [sp, #-0x10]! 0x400012c4: a9bf1be5 stp x5, x6, [sp, #-0x10]! 0x400012c8: a9bf13e3 stp x3, x4, [sp, #-0x10]! 0x400012cc: a9bf0be1 stp x1, x2, [sp, #-0x10]! 0x400012d0: d5384015 mrs x21, spsr_el1 0x400012d4: a9bf03f5 stp x21, x0, [sp, #-0x10]! 0x400012d8: d5384035 mrs x21, elr_el1 0x400012dc: a9bf57ff stp xzr, x21, [sp, #-0x10]! 0x400012e0: d2800235 movz x21, #0x11 0x400012e4: d5385216 mrs x22, esr_el1 0x400012e8: a9bf5bf5 stp x21, x22, [sp, #-0x10]! 0x400012ec: 910003f5 mov x21, sp 0x400012f0: 910482b5 add x21, x21, #0x120 0x400012f4: f9000bf5 str x21, [sp, #0x10] 0x400012f8: 910003e0 mov x0, sp 0x400012fc: 9400023f bl #0x40001bf8 ---------------- IN: lkmc_vector_trap_handler 0x40001bf8: a9bd7bfd stp x29, x30, [sp, #-0x30]!
And with gem5 tracing:
./run \ --arch aarch64 \ --baremetal baremetal/arch/aarch64/svc_asm.S \ --trace ExecAll,Faults \ --trace-stdout \ ;
the output contains:
4000: system.cpu A0 T0 : @main+8 : svc #0x0 : IntAlu : flags=(IsSerializeAfter|IsNonSpeculative|IsSyscall) 4000: Supervisor Call: Invoking Fault (AArch64 target EL):Supervisor Call cpsr:0x3c5 PC:0x80000808 elr:0x8000080c newVec: 0x80001200 4500: system.cpu A0 T0 : @vector_table+512 : b <_curr_el_spx_sync> : IntAlu : flags=(IsControl|IsDirectControl|IsUncondControl)
So we see in both cases that the:
-
SVC is done
-
an exception happens, and the PC jumps to address 0x40000a00. From our custom terminal prints further on, we see that this equals
VBAR_EL1 + 0x200.According to the format of the ARMv8 exception vector table format, we see that the
+ 0x200means that we are jumping in the Current EL with SPx.This can also be deduced from the message
exc_type is LKMC_VECTOR_SYNC_SPX: we just manually store a different integer for every exception vector type in our handler code to be able to tell what happened.This is the one used because we are jumping from EL1 to EL1.
We set VBAR_EL1 to that address ourselves in the bootloader.
-
at 0x40000a00 a
b #0x40001294is done and then at 0x40001294 boilerplate preparation is done for lkmc_vector_trap_handler starting with several STP instructions.We have coded both of those in our vector table macro madness. As of LKMC 8f73910dd1fc1fa6dc6904ae406b7598cdcd96d7, both come from lkmc/aarch64.h:
-
b #0x40001294comes from:LKMC_VECTOR_ENTRY -
the STP come from:
LKMC_VECTOR_BUILD_TRAPFRAMEWe jump immediately from inside
LKMC_VECTOR_ENTRYtoLKMC_VECTOR_BUILD_TRAPFRAMEbecause we can only use 0x80 bytes of instructions for each one before reaching the next handler, so we might as well get it over with by jumping into a memory region without those constraints.TODO: why doesn’t QEMU show our nice symbol names? gem5 shows them fine, and
nmsays they are there!0000000040000800 T lkmc_vector_table 0000000040001294 T lkmc_vector_build_trapframe_curr_el_spx_sync
-
The exception return happens at the end of lkmc_vector_trap_handler:
---------------- IN: lkmc_vector_trap_handler 0x40002000: d503201f nop 0x40002004: a8c37bfd ldp x29, x30, [sp], #0x30 0x40002008: d65f03c0 ret ---------------- IN: 0x40001300: 910043ff add sp, sp, #0x10 0x40001304: a8c15bf5 ldp x21, x22, [sp], #0x10 0x40001308: d5184036 msr elr_el1, x22 ---------------- IN: 0x4000130c: a8c103f5 ldp x21, x0, [sp], #0x10 0x40001310: d5184015 msr spsr_el1, x21 ---------------- IN: 0x40001314: a8c10be1 ldp x1, x2, [sp], #0x10 0x40001318: a8c113e3 ldp x3, x4, [sp], #0x10 0x4000131c: a8c11be5 ldp x5, x6, [sp], #0x10 0x40001320: a8c123e7 ldp x7, x8, [sp], #0x10 0x40001324: a8c12be9 ldp x9, x10, [sp], #0x10 0x40001328: a8c133eb ldp x11, x12, [sp], #0x10 0x4000132c: a8c13bed ldp x13, x14, [sp], #0x10 0x40001330: a8c143ef ldp x15, x16, [sp], #0x10 0x40001334: a8c14bf1 ldp x17, x18, [sp], #0x10 0x40001338: a8c153f3 ldp x19, x20, [sp], #0x10 0x4000133c: a8c15bf5 ldp x21, x22, [sp], #0x10 0x40001340: a8c163f7 ldp x23, x24, [sp], #0x10 0x40001344: a8c16bf9 ldp x25, x26, [sp], #0x10 0x40001348: a8c173fb ldp x27, x28, [sp], #0x10 0x4000134c: a8c17bfd ldp x29, x30, [sp], #0x10 0x40001350: d69f03e0 eret Exception return from AArch64 EL1 to AArch64 EL1 PC 0x4000209c ---------------- IN: main 0x4000209c: d0000040 adrp x0, #0x4000c000
which does an eret and jumps back to 0x4000209c, which is 4 bytes and therefore one instruction after where SVC was taken at 0x40002098.
On the terminal output, we observe the initial values of:
-
DAIF: 0x3c0, i.e. 4 bits (6 to 9) set to 1, which means that exceptions are masked for each exception type: Synchronous, System error, IRQ and FIQ.
This reset value is defined by ARMv8 architecture reference manual C5.2.2 "DAIF, Interrupt Mask Bits".
-
SPSel: 0x1, which means: use SPx instead of SP0.
This reset value is defined by ARMv8 architecture reference manual C5.2.16 "SPSel, Stack Pointer Select".
-
VBAR_EL1: 0x0 holds the base address of the vector table
This reset value is defined UNKNOWN by ARMv8 architecture reference manual D10.2.116 "VBAR_EL1, Vector Base Address Register (EL1)", so we must set it to something ourselves to have greater portability.
Bibliography:
-
https://github.com/torvalds/linux/blob/v4.20/arch/arm64/kernel/entry.S#L430 this is where the kernel defines the vector table
-
https://github.com/dwelch67/qemu_arm_samples/tree/07162ba087111e0df3f44fd857d1b4e82458a56d/swi01
-
https://stackoverflow.com/questions/24162109/arm-assembly-code-and-svc-numbering/57064062#57064062
-
https://stackoverflow.com/questions/44991264/armv8-exception-vectors-and-handling
33.10.2.1. ARMv8 exception vector table format
The vector table format is described on ARMv8 architecture reference manual Table D1-7 "Vector offsets from vector table base address".
A good representation of the format of the vector table can also be found at Programmer’s Guide for ARMv8-A Table 10-2 "Vector table offsets from vector table base address".
The first part of the table contains: Table 6, “Summary of ARMv8 vector handlers”.
| Address | Exception type | Description |
|---|---|---|
VBAR_ELn + 0x000 |
Synchronous |
Current EL with SP0 |
VBAR_ELn + 0x080 |
IRQ/vIRQ |
Current EL with SP0 |
VBAR_ELn + 0x100 |
FIQ/vFIQ |
Current EL with SP0 |
VBAR_ELn + 0x180 |
SError/vSError |
Current EL with SP0 |
VBAR_ELn + 0x200 |
Synchronous |
Current EL with SPx |
VBAR_ELn + 0x280 |
IRQ/vIRQ |
Current EL with SPx |
VBAR_ELn + 0x300 |
FIQ/vFIQ |
Current EL with SPx |
VBAR_ELn + 0x380 |
SError/vSError |
Lower EL using AArch64 |
VBAR_ELn + 0x400 |
Synchronous |
Lower EL using AArch64 |
VBAR_ELn + 0x480 |
IRQ/vIRQ |
Lower EL using AArch64 |
VBAR_ELn + 0x500 |
FIQ/vFIQ |
Lower EL using AArch64 |
VBAR_ELn + 0x580 |
SError/vSError |
Lower EL using AArch64 |
VBAR_ELn + 0x600 |
Synchronous |
Lower EL using AArch32 |
VBAR_ELn + 0x680 |
IRQ/vIRQ |
Lower EL using AArch32 |
VBAR_ELn + 0x700 |
FIQ/vFIQ |
Lower EL using AArch32 |
VBAR_ELn + 0x780 |
SError/vSError |
Lower EL using AArch32 |
and the following other parts are analogous, but referring to SPx and lower ELs.
Now, to fully understand this table, we need the following concepts:
-
Synchronous: what happens for example when we do an ARM SVC instruction.
It is called synchronous because the CPU is generating it itself from an instruction, unlike an interrupt generated by a device like a keyboard, which ends up in an IRQ or FIQ
-
IRQ: an example can be found at: ARM timer
-
TODO FIQ vs IRQ
-
TODO SError
-
EL changes: ARM change exception level
-
SP0 vs SPx: ARM SP0 vs SPx.
33.10.2.2. ARM ESR register
Exception Syndrome Register.
See example at: Section 33.10.2, “ARM SVC instruction”
Documentation: ARMv8 architecture reference manual db D12.2.36 "ESR_EL1, Exception Syndrome Register (EL1)".
33.10.2.3. ARM ELR register
Exception Link Register.
See the example at: Section 33.10.2, “ARM SVC instruction”
33.10.3. ARM baremetal multicore
Examples:
./run --arch aarch64 --baremetal baremetal/arch/aarch64/no_bootloader/multicore_asm.S --cpus 2 ./run --arch aarch64 --baremetal baremetal/arch/aarch64/no_bootloader/multicore_asm.S --cpus 2 --emulator gem5 ./run --arch aarch64 --baremetal baremetal/arch/aarch64/multicore.c --cpus 2 ./run --arch aarch64 --baremetal baremetal/arch/aarch64/multicore.c --cpus 2 --emulator gem5 ./run --arch arm --baremetal baremetal/arch/arm/no_bootloader/multicore_asm.S --cpus 2 ./run --arch arm --baremetal baremetal/arch/arm/no_bootloader/multicore_asm.S --cpus 2 --emulator gem5 # TODO not working, hangs. # ./run --arch arm --baremetal baremetal/arch/arm/multicore.c --cpus 2 ./run --arch arm --baremetal baremetal/arch/arm/multicore.c --cpus 2 --emulator gem5
Sources:
CPU 0 of this program enters a spinlock loop: it repeatedly checks if a given memory address is 1.
So, we need CPU 1 to come to the rescue and set that memory address to 1, otherwise CPU 0 will be stuck there forever!
Don’t believe me? Then try:
./run --arch aarch64 --baremetal baremetal/arch/aarch64/multicore.c --cpus 1
and watch it hang forever.
Note that if you try the same thing on gem5:
./run --arch aarch64 --baremetal baremetal/arch/aarch64/multicore.c --cpus 1 --emulator gem5
then the gem5 actually exits with gem5 simulate() limit reached as opposed to the expected:
Exiting @ tick 36500 because m5_exit instruction encountered
since gem5 is able to detect when nothing will ever happen, and exits.
When GDB step debugging, switch between cores with the usual thread commands, see also: Section 3.9, “GDB step debug multicore userland”.
Bibliography: https://stackoverflow.com/questions/980999/what-does-multicore-assembly-language-look-like/33651438#33651438
33.10.3.1. ARM WFE and SEV instructions
The WFE and SEV instructions are just hints: a compliant implementation can treat them as NOPs.
Concrete examples of the instruction can be seen at:
-
userland/arch/aarch64/freestanding/linux/wfe_wfe.S: run WFE twice, because gem5 390a74f59934b85d91489f8a563450d8321b602d does not sleep on the first, see also: gem5 ARM WFE
-
baremetal/arch/aarch64/no_bootloader/wfe_loop.S, see: gem5 simulate() limit reached
-
userland/arch/aarch64/inline_asm/wfe_sev.cpp: one Linux thread runs WFE and the other runs SEV to wake it up
-
ARM baremetal multicore shows baremetal examples where WFE sleeps and another thread wakes it up:
However, likely no implementation likely does (TODO confirm), since:
-
WFE is intended to put the core in a low power mode
-
SEV wakes up cores from a low power mode
and power consumption is key in ARM applications.
Quotes for the above ARMv8 architecture reference manual db G1.18.1 "Wait For Event and Send Event":
The following events are WFE wake-up events:
\[…]
An event caused by the clearing of the global monitor associated with the PE
and ARMv8 architecture reference manual db E2.9.6 "Use of WFE and SEV instructions by spin-locks":
ARMv8 provides Wait For Event, Send Event, and Send Event Local instructions, WFE, SEV, SEVL, that can assist with reducing power consumption and bus contention caused by PEs repeatedly attempting to obtain a spin-lock. These instructions can be used at the application level, but a complete understanding of what they do depends on a system level understanding of exceptions. They are described in Wait For Event and Send Event on page G1-5308. However, in ARMv8, when the global monitor for a PE changes from Exclusive Access state to Open Access state, an event is generated.
Note This is equivalent to issuing an SEVL instruction on the PE for which the monitor state has changed. It removes the need for spinlock code to include an SEV instruction after clearing a spinlock.
The recommended ARMv8 spinlock implementation is shown at http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dht0008a/ch01s03s02.html where WAIT_FOR_UPDATE is as explained in that section a macro that expands to WFE. TODO SEV is used explicitly in those examples via SIGNAL_UPDATE, where is the example that shows how SEV can be eliminated due to implicit monitor signals?
In QEMU 3.0.0, SEV is a NOPs, and WFE might be, but I’m not sure, see: https://github.com/qemu/qemu/blob/v3.0.0/target/arm/translate-a64.c#L1423
case 2: /* WFE */
if (!(tb_cflags(s->base.tb) & CF_PARALLEL)) {
s->base.is_jmp = DISAS_WFE;
}
return;
case 4: /* SEV */
case 5: /* SEVL */
/* we treat all as NOP at least for now */
return;
TODO: what does the WFE code do? How can it not be a NOP if SEV is a NOP? https://github.com/qemu/qemu/blob/v3.0.0/target/arm/translate.c#L4609 might explain why, but it is Chinese to me (I only understand 30% ;-)):
* For WFI we will halt the vCPU until an IRQ. For WFE and YIELD we * only call the helper when running single threaded TCG code to ensure * the next round-robin scheduled vCPU gets a crack. In MTTCG mode we * just skip this instruction. Currently the SEV/SEVL instructions * which are *one* of many ways to wake the CPU from WFE are not * implemented so we can't sleep like WFI does. */
For gem5 however, if we comment out the SVE instruction, then it actually exits with simulate() limit reached, so the CPU truly never wakes up, which is a more realistic behaviour, since gem5 is more focused on simulating a realistic microarchitecture and power consumption.
The following Raspberry Pi bibliography helped us get this sample up and running:
For how userland spinlocks and mutexes are implemented see Userland mutex implementation.
33.10.3.1.1. ARM WFE global monitor events
Examples:
-
userland/arch/aarch64/inline_asm/futex_ldxr_stxr.c: tests that ldxr and stxr do not interact with futexes. This was leading to problems in gem5 syscall emulation mode at one point: https://gem5.atlassian.net/browse/GEM5-537
Correct outcome: gem5 simulate() limit reached.
Incorrect behaviour due to: https://gem5.atlassian.net/browse/GEM5-537: Exits successfully.
SEV is not the only thing that can wake up a WFE, it is only an explicit software way to do it.
Notably, global monitor operations on memory accesses of regions marked by LDAXR and STLXR instructions can also wake up a WFE sleeping core.
This is done to allow spinlocks opens to automatically wake up WFE sleeping cores at free time without the need for a explicit SEV.
In the shown in the wfe_ldxr_stxr.cpp example, which can only terminate in gem5 user mode simulation because due to this event.
Note that that program still terminates when running on top of the Linux kernel as explained at: WFE from userland.
33.10.3.1.2. WFE from userland
WFE and SEV are usable from userland, and are part of an efficient spinlock implementation (which userland should arguably stay away from and rather use the futex system call which allow for non busy sleep instead), which maybe is not something that userland should ever tho and just stick to mutexes?
There is a control bit SCTLR_EL1.nTWE that determines if WFE is trapped or not, i.e.: is that bit is set, then it is trapped and EL0 execution raises an exception in EL1.
Linux v5.2.1 does not set SCTLR_EL1.nTWE however, tested with gem5 tracing with --trace ExecAll,Failts and the dump_regs kernel module in a full system simulation.
The kernel seems to setup nTWE at:
include/asm/sysreg.h
#define SCTLR_EL1_SET (SCTLR_ELx_M | SCTLR_ELx_C | SCTLR_ELx_SA |\
...
SCTLR_EL1_NTWE | SCTLR_ELx_IESB | SCTLR_EL1_SPAN |\
and:
mm/proc.S
/* * Prepare SCTLR */ mov_q x0, SCTLR_EL1_SET
To reduce the number of instructions from our trace, first we boot, and then we restore a checkpoint after boot with gem5 checkpoint restore and run a different script with a restore command that runs userland/arch/aarch64/freestanding/linux/wfe_wfe.S:
./run --arch aarch64 --emulator gem5 --gem5-worktree master --gem5-restore 1 --gem5-readfile 'arch/aarch64/freestanding/linux/wfe_wfe.out' --trace ExecAll,Faults,FmtFlag,Thread
On the traces, we search for wfe, and there are just two hits, so they must be our instructions!
The traces then look like this at LKMC 777b7cbbd1d553baf2be9bc2075102be740054dd:
112285501668497000: Thread: system.cpu: suspend contextId 0 112285501668497000: ExecEnable: system.cpu: A0 T0 : 0x400078 : wfe : IntAlu : D=0x0000000000000000 flags=(IsSerializeAfter|IsNonSpeculative|IsQuiesce|IsUnverifiable) 112285501668497501: Thread: system.cpu: activate contextId 0 112285501668498000: Thread: system.cpu: suspend contextId 0 112285501668498000: ExecEnable: system.cpu: A0 T0 : 0x40007c : wfe : IntAlu : D=0x0000000000000000 flags=(IsSerializeAfter|IsNonSpeculative|IsQuiesce|IsUnverifiable) 112285501909320284: Thread: system.cpu: activate contextId 0 112285501909320500: Faults: IRQ: Invoking Fault (AArch64 target EL):IRQ cpsr:0x4003c5 PC:0x400080 elr:0x400080 newVec: 0xffffff8010082480 112285501909320500: ExecEnable: system.cpu: A0 T0 : @vectors+1152 : nop : IntAlu : flags=(IsNop) 112285501909321000: ExecEnable: system.cpu: A0 T0 : @vectors+1156 : nop : IntAlu : flags=(IsNop) [more exception handler, no ERET here] 112285501923080500: ExecEnable: system.cpu: A0 T0 : @finish_ret_to_user+188 : ldr x30, [sp, #240] : MemRead : D=0x0000000000000000 A=0xffffff8010cb3fb0 flags=(IsInteger|IsMemRef|IsLoad) 112285501923081000: ExecEnable: system.cpu: A0 T0 : @finish_ret_to_user+192 : add sp, sp, #320 : IntAlu : D=0xffffff8010cb4000 flags=(IsInteger) 112285501923081500: ExecEnable: system.cpu: A0 T0 : 0xffffff8010084144 : eret : IntAlu : D=0x0000000000000001 flags=(IsControl|IsSerializeAfter|IsNonSpeculative|IsSquashAfter) 112285501923082000: ExecEnable: system.cpu: A0 T0 : 0x400080 : movz x0, #0, #0 : IntAlu : D=0x0000000000000000 flags=(IsInteger) 112285501923082500: ExecEnable: system.cpu: A0 T0 : 0x400084 : movz x8, #93, #0 : IntAlu : D=0x000000000000005d flags=(IsInteger) 112285501923083000: ExecEnable: system.cpu: A0 T0 : 0x400088 : svc #0x0 : IntAlu : flags=(IsSerializeAfter|IsNonSpeculative|IsSyscall)
so we conclude that:
-
the second WFE made the CPU stop running instructions at time 112285501668498000 and PC 0x40007c
-
the next thing that happened a long time later (112285501909320500, while a following instruction would happen at 112285501668498000 + 1000) was an interrupt, presumably the ARM timer
-
after a few interrupt handler instructions, the first ERET instruction exits the handler and comes back directly to the instruction after the WFE at PC 0x400080 == 0x40007c + 4
-
the execution of the interrupt handler woke up the core that was in WFE, and it now continues normal execution past the WFE
Therefore, a WFE in userland is treated much like a busy loop by the Linux kernel: the kernel does not seem to try and explicitly make up room for other processes as would happen on a futex.
The following test checks that SEV events don’t wake up a futexes, running forever in case of success. In gem5 syscall emulation multithreading, this is crucial to prevent deadlocks:
33.10.3.1.3. ARMv8 spinlock pattern
sev
1: wfe
2: ldaxr w1, [w0]
cbnz w1, %1b
stxr w1, w2, [w0]
cbnz w1, %2b
It is the STXR from the unlock on another core that automatically wakes up the spinlock afterwards: https://stackoverflow.com/questions/32276313/how-is-a-spin-lock-woken-up-in-linux-arm64
33.10.3.1.4. gem5 ARM WFE
gem5 390a74f59934b85d91489f8a563450d8321b602d does not sleep on the first WFE on either syscall emulation or full system, because the code does:
Fault WfeInst::execute(
ExecContext *xc, Trace::InstRecord *traceData) const
{
[...]
if (SevMailbox == 1) {
SevMailbox = 0;
PseudoInst::quiesceSkip(tc);
} else if (tc->getCpuPtr()->getInterruptController(
tc->threadId())->checkInterrupts(tc)) {
PseudoInst::quiesceSkip(tc);
} else {
fault = trapWFx(tc, cpsr, scr, true);
if (fault == NoFault) {
PseudoInst::quiesce(tc);
} else {
PseudoInst::quiesceSkip(tc);
}
}
where "quiesce" means "sleep" for laymen like Ciro, and quiesceSkip means don’t sleep.
SevMailbox is read from MISCREG_SEV_MAILBOX which is initialized to 1 at:
ISA::clear()
{
[...]
miscRegs[MISCREG_SEV_MAILBOX] = 1;
33.10.3.2. ARM LDAXR and STLXR instructions
Can be used to implement atomic variables, see also:
The ARMv7 analogues are LDREX and STREX.
33.10.3.3. ARM PSCI
In QEMU, CPU 1 starts in a halted state. This can be observed from GDB, where:
info threads
shows something like:
* 1 Thread 1 (CPU#0 [running]) lkmc_start 2 Thread 2 (CPU#1 [halted ]) lkmc_start
To wake up CPU 1 on QEMU, we must use the Power State Coordination Interface (PSCI) which is documented at: https://developer.arm.com/docs/den0022/latest/arm-power-state-coordination-interface-platform-design-document.
This interface uses HVC calls, and the calling convention is documented at "SMC CALLING CONVENTION" https://developer.arm.com/docs/den0028/latest.
If we boot the Linux kernel on QEMU and dump the auto-generated device tree, we observe that it contains the address of the PSCI CPU_ON call:
psci {
method = "hvc";
compatible = "arm,psci-0.2", "arm,psci";
cpu_on = <0xc4000003>;
migrate = <0xc4000005>;
cpu_suspend = <0xc4000001>;
cpu_off = <0x84000002>;
};
The Linux kernel wakes up the secondary cores in this exact same way at: https://github.com/torvalds/linux/blob/v4.19/drivers/firmware/psci.c#L122 We first actually got it working here by grepping the kernel and step debugging that call :-)
In gem5, CPU 1 starts woken up from the start, so PSCI is not needed. TODO gem5 actually blows up if we try to do the HVC call, understand why.
33.10.3.4. ARM DMB instruction
TODO: create and study a minimal examples in gem5 where the DMB instruction leads to less cycles: https://stackoverflow.com/questions/15491751/real-life-use-cases-of-barriers-dsb-dmb-isb-in-arm
33.10.4. ARM timer
The ARM timer is the simplest way to generate hardware interrupts periodically, and therefore serves as the simples example of ARM GIC usage.
Working on QEMU: baremetal/arch/aarch64/timer.c
./run --arch aarch64 --baremetal baremetal/arch/aarch64/timer.c
Output at lkmc d8dae268c0a3e4e361002aca3b382fedd77f2567 + 1:
cntv_ctl_el0 0x0 cntfrq_el0 0x3B9ACA0 cntv_cval_el0 0x0 cntvct_el0 0x105113 cntvct_el0 0x1080BC cntvct_el0 0x10A118 IRQ number 0x1B cntvct_el0 0x14D25B cntv_cval_el0 0x3CE9CD6 IRQ number 0x1B cntvct_el0 0x3CF516F cntv_cval_el0 0x7893217 IRQ number 0x1B cntvct_el0 0x789B733 cntv_cval_el0 0xB439642
and new IRQ number section appears every second, when a clock interrupt is raised!
TODO make work on gem5. Fails with gem5 simulate() limit reached at the first WFI done in main, which means that the interrupt is never raised.
Once an interrupt is raised, the interrupt itself sets up a new interrupt to happen in one second in the future after cntv_cval_el0 is reached by the counter.
The timer is part of the aarch64 specification itself and is documented at: ARMv8 architecture reference manual db Chapter D10 "The Generic Timer in AArch64 state". The key registers to keep in mind are:
-
CNTVCT_EL0: "Counter-timer Virtual Count register". The increasing current counter value. -
CNTFRQ_EL0: "Counter-timer Frequency register". "Indicates the system counter clock frequency, in Hz." -
CNTV_CTL_EL0: "Counter-timer Virtual Timer Control register". This control register is very simple and only has three fields:-
CNTV_CTL_EL0.ISTATUSbit: set to 1 when the timer condition is met -
CNTV_CTL_EL0.IMASKbit: if 1, the interrupt does not happen whenISTATUSbecomes one -
CNTV_CTL_EL0.ENABLEbit: if 0, the counter is turned off, interrupts don’t happen
-
-
CNTV_CVAL_EL0: "Counter-timer Virtual Timer CompareValue register". The interrupt happens whenCNTVCT_EL0reaches the value in this register.
Due to QEMU’s non-determinism, each consecutive run has slightly different output values.
From the terminal output, we can see that the initial clock frequency is 0x3B9ACA0 == 62500000 Hz == 62.5MHz. Grepping QEMU source for that string leads us to:
/* Scale factor for generic timers, ie number of ns per tick. * This gives a 62.5MHz timer. */ #define GTIMER_SCALE 16
which in turn is used to set the initial reset value of the clock:
{ .name = "CNTFRQ_EL0", .state = ARM_CP_STATE_AA64,
.opc0 = 3, .opc1 = 3, .crn = 14, .crm = 0, .opc2 = 0,
.access = PL1_RW | PL0_R, .accessfn = gt_cntfrq_access,
.fieldoffset = offsetof(CPUARMState, cp15.c14_cntfrq),
.resetvalue = (1000 * 1000 * 1000) / GTIMER_SCALE,
where (1000 * 1000 * 1000) / 16 == 62500000.
Trying to set the frequency on QEMU by writing to the CNTFRQ register does change the value of future reads, but has no effect on the actual clock frequency as commented on the QEMU source code https://github.com/qemu/qemu/blob/v4.0.0/target/arm/helper.c#L2647
static const ARMCPRegInfo generic_timer_cp_reginfo[] = {
/* Note that CNTFRQ is purely reads-as-written for the benefit
* of software; writing it doesn't actually change the timer frequency.
* Our reset value matches the fixed frequency we implement the timer at.
*/
{ .name = "CNTFRQ", .cp = 15, .crn = 14, .crm = 0, .opc1 = 0, .opc2 = 0,
.type = ARM_CP_ALIAS,
.access = PL1_RW | PL0_R, .accessfn = gt_cntfrq_access,
.fieldoffset = offsetoflow32(CPUARMState, cp15.c14_cntfrq),
},
At each interrupt, we increase the compare value CVAL by about 1x the clock frequency 0x3B9ACA0 so that it will fire again in one second, e.g. 0x3CE9CD6 - 0x14D25B == 3B9CA7B. The increment is not perfect because the counter keeps ticking even while our register read and print instructions are running inside the interrupt handler!
We then observe that the next interrupt happens soon after CNTV_CVAL_EL0 is reached by CNTVCT_EL0:
cntv_cval_el0 0x3CE9CD6 IRQ number 0x1B cntvct_el0 0x3CF516F
Bibliography:
33.10.5. ARM GIC
Generic Interrupt Controller.
Examples:
ARM publishes both a GIC standard architecture specification, and specific implementations of these specifications.
The specification can be found at: https://developer.arm.com/docs/ihi0069/latest
As of 2019Q2 the latest version if v4.0, often called GICv4: https://static.docs.arm.com/ihi0069/e/Q1-IHI0069E_gic_architecture_specification_v3.1_19_01_21.pdf
That document clarifies that GICv2 is a legacy specification only:
Version 2.0 (GICv2) is only described in terms of the GICv3 optional support for legacy operation
The specific models have names of type GIC-600, GIC-500, etc.
In QEMU v4.0.0, the GICv3 can be selected with an extra -machine gic_version=3 option.
In gem5 3126e84db773f64e46b1d02a9a27892bf6612d30, the GIC is determined by selecting the platform as explained at: gem5 ARM platforms.
33.10.6. ARM paging
TODO create a minimal working aarch64 example analogous to the x86 one at: https://github.com/cirosantilli/x86-bare-metal-examples/blob/6dc9a73830fc05358d8d66128f740ef9906f7677/paging.S
A general introduction to paging with x86 examples can be found at: https://cirosantilli.com/x86-paging.
Then, this article is amazing: https://www.starlab.io/blog/deep-dive-mmu-virtualization-with-xen-on-arm
ARM paging is documented at ARMv8 architecture reference manual db Chapter D5 and is mostly called VMSAv8 in the ARMv8 manual (Virtual Memory System Architecture).
Paging is enabled by the SCTLR_EL1.M bit.
The base table address is selected by the register documented at ARMv8 architecture reference manual db D12.2.111 "TTBR0_EL1, Translation Table Base Register 0 (EL1)".
There is also a TTBR1_EL1 register, which is for the second translation stage to speed up virtualization: https://en.wikipedia.org/wiki/Second_Level_Address_Translation and will not be used in this section.
The translation types are described at: ARMv8 architecture reference manual db D5.2.4 "Memory translation granule size".
From this we can see that the translation scheme uses up to 4 levels (0 to 3) and has possible granule sizes 4KiB, 16KiB and 64KiB.
Page table formats are described at ARMv8 architecture reference manual db D5.3.1 "VMSAv8-64 translation table level 0, level 1, and level 2 descriptor formats".
33.10.7. ARM baremetal bibliography
First, also consider the userland bibliography: Section 30.10, “ARM assembly bibliography”.
The most useful ARM baremetal example sets we’ve seen so far are:
-
https://github.com/dwelch67/raspberrypi real hardware
-
https://github.com/dwelch67/qemu_arm_samples QEMU
-m vexpress -
https://github.com/bztsrc/raspi3-tutorial real hardware + QEMU
-m raspi -
https://github.com/LdB-ECM/Raspberry-Pi real hardware
33.10.7.1. NienfengYao/armv8-bare-metal
The only QEMU -m virt aarch64 example set that I can find on the web. Awesome.
A large part of the code is taken from the awesome educational OS under 2-clause BSD as can be seen from file headers: https://github.com/takeharukato/sample-tsk-sw/tree/ce7973aa5d46c9eedb58309de43df3b09d4f8d8d/hal/aarch64 but Nienfeng largely minimized it.
I needed the following minor patches: https://github.com/NienfengYao/armv8-bare-metal/pull/1
Handles an SVC and setups and handles the timer about once per second.
The source claims GICv3, however if I try to add -machine gic_version=3 on their command line with our QEMU v4.0.0, then it blows up at:
static void init_gicc(void)
{
uint32_t pending_irq;
/* Disable CPU interface */
*REG_GIC_GICC_CTLR = GICC_CTLR_DISABLE;
which tries to write to 0x8010000 according to GDB.
Without -machine, QEMU’s DTB clearly states GICv2, so I’m starting to wonder if Nienfeng just made a mistake there? The QEMU GICv3 DTB contains:
reg = <0x0 0x8000000 0x0 0x10000 0x0 0x80a0000 0x0 0xf60000>;
and the GICv2 one:
reg = <0x0 0x8000000 0x0 0x10000 0x0 0x8010000 0x0 0x10000>;
which further confirms that the exception is correct: v2 has a register range at 0x8010000 while in v3 it moved to 0x80a0000 and 0x8010000 is empty.
The original source does not mention GICv3 anywhere, only pl390, which is a specific GIC model that predates the GICv2 spec I believe.
TODO if I hack #define GIC_GICC_BASE (GIC_BASE + 0xa0000), then it goes a bit further, but the next loop never ends.
33.10.7.2. tukl-msd/gem5.bare-metal
Reiterated at: https://stackoverflow.com/questions/43682311/uart-communication-in-gem5-with-arm-bare-metal
Basic gem5 aarch64 baremetal setup that just works. Does serial IO and timer through GICv2. Usage:
# Build gem5. git clone https://gem5.googlesource.com/public/gem5 cd gem5 git checkout 60600f09c25255b3c8f72da7fb49100e2682093a scons --ignore-style -j`nproc` build/ARM/gem5.opt cd .. # Build example. sudo apt-get install gcc-arm-none-eabi git clone https://github.com/tukl-msd/gem5.bare-metal cd gem5.bare-metal git checkout 6ad1069d4299b775b5491e9252739166bfac9bfe cd Simple make CROSS_COMPILE_DIR=/usr/bin # Run example. ../../gem5/default/build/ARM/gem5.opt' \ ../../gem5/configs/example/fs.py' \ --bare-metal \ --disk-image="$(pwd)/../common/fake.iso" \ --kernel="$(pwd)/main.elf" \ --machine-type=RealView_PBX \ --mem-size=256MB \ ;
33.11. How we got some baremetal stuff to work
It is nice when thing just work.
But you can also learn a thing or two from how I actually made them work in the first place.
33.11.1. Find the UART address
Enter the QEMU console:
Ctrl-X C
Then do:
info mtree
And look for pl011:
0000000009000000-0000000009000fff (prio 0, i/o): pl011
On gem5, it is easy to find it on the source. We are using the machine RealView_PBX, and a quick grep leads us to: https://github.com/gem5/gem5/blob/a27ce59a39ec8fa20a3c4e9fa53e9b3db1199e91/src/dev/arm/RealView.py#L615
class RealViewPBX(RealView):
uart = Pl011(pio_addr=0x10009000, int_num=44)
33.11.2. aarch64 baremetal NEON setup
Inside baremetal/lib/aarch64.S there is a chunk of code that enables floating point operations:
mov x1, 0x3 << 20 msr cpacr_el1, x1 isb
CPACR_EL1 is documented at ARMv8 architecture reference manual D10.2.29 "CPACR_EL1, Architectural Feature Access Control Register".
Here we touch the CPACR_EL1.FPEN bits to 3, which enable floating point operations:
11 This control does not cause any instructions to be trapped.
We later also added an enable for the CPACR_EL1.ZEN bits, which are needed for ARM SVE.
Without CPACR_EL1.FPEN, the printf:
printf("got: %c\n", c);
compiled to a:
str q0, [sp, #80]
which uses NEON registers, and goes into an exception loop.
It was a bit confusing because there was a previous printf:
printf("enter a character\n");
which did not blow up because GCC compiles it into puts directly since it has no arguments, and that does not generate NEON instructions.
The last instructions ran was found with:
while(1) stepi end
or by hacking the QEMU CLI to contain:
-D log.log -d in_asm
I could not find any previous NEON instruction executed so this led me to suspect that some NEON initialization was required:
-
http://infocenter.arm.com/help/topic/com.arm.doc.dai0527a/DAI0527A_baremetal_boot_code_for_ARMv8_A_processors.pdf "Bare-metal Boot Code for ARMv8-A Processors"
-
https://community.arm.com/processors/f/discussions/5409/how-to-enable-neon-in-cortex-a8
-
https://stackoverflow.com/questions/19231197/enable-neon-on-arm-cortex-a-series
We then tried to copy the code from the "Bare-metal Boot Code for ARMv8-A Processors" document:
// Disable trapping of accessing in EL3 and EL2. MSR CPTR_EL3, XZR MSR CPTR_EL3, XZR // Disable access trapping in EL1 and EL0. MOV X1, #(0x3 << 20) // FPEN disables trapping to EL1. MSR CPACR_EL1, X1 ISB
but it entered an exception loop at MSR CPTR_EL3, XZR.
We then found out that QEMU starts in EL1, and so we kept just the EL1 part, and it worked. Related:
33.12. Baremetal tests
Baremetal tests work exactly like User mode tests, except that you have to add the --mode baremetal option, for example:
./test-executables --mode baremetal --arch aarch64
In baremetal, we detect if tests failed by parsing logs for the Magic failure string.
See: Section 38.16, “Test this repo” for more useful testing tips.
34. Android
Remember: Android AOSP is a huge undocumented piece of bloatware. It’s integration into this repo will likely never be super good. See also: https://cirosantilli.com#android
Verbose setup description: https://stackoverflow.com/questions/1809774/how-to-compile-the-android-aosp-kernel-and-test-it-with-the-android-emulator/48310014#48310014
Download, build and run with the prebuilt AOSP QEMU emulator and the AOSP kernel:
./build-android \ --android-base-dir /path/to/your/hd \ --android-version 8.1.0_r60 \ download \ build \ ; ./run-android \ --android-base-dir /path/to/your/hd \ --android-version 8.1.0_r60 \ ;
Sources:
TODO how to hack the AOSP kernel, userland and emulator?
Other archs work as well as usual with --arch parameter. However, running in non-x86 is very slow due to the lack of KVM.
Tested on: 8.1.0_r60.
34.1. Android image structure
The messy AOSP generates a ton of images instead of just one.
When the emulator launches, we can see them through QEMU -drive arguments:
emulator: argv[21] = "-initrd" emulator: argv[22] = "/data/aosp/8.1.0_r60/out/target/product/generic_x86_64/ramdisk.img" emulator: argv[23] = "-drive" emulator: argv[24] = "if=none,index=0,id=system,file=/path/to/aosp/8.1.0_r60/out/target/product/generic_x86_64/system-qemu.img,read-only" emulator: argv[25] = "-device" emulator: argv[26] = "virtio-blk-pci,drive=system,iothread=disk-iothread,modern-pio-notify" emulator: argv[27] = "-drive" emulator: argv[28] = "if=none,index=1,id=cache,file=/path/to/aosp/8.1.0_r60/out/target/product/generic_x86_64/cache.img.qcow2,overlap-check=none,cache=unsafe,l2-cache-size=1048576" emulator: argv[29] = "-device" emulator: argv[30] = "virtio-blk-pci,drive=cache,iothread=disk-iothread,modern-pio-notify" emulator: argv[31] = "-drive" emulator: argv[32] = "if=none,index=2,id=userdata,file=/path/to/aosp/8.1.0_r60/out/target/product/generic_x86_64/userdata-qemu.img.qcow2,overlap-check=none,cache=unsafe,l2-cache-size=1048576" emulator: argv[33] = "-device" emulator: argv[34] = "virtio-blk-pci,drive=userdata,iothread=disk-iothread,modern-pio-notify" emulator: argv[35] = "-drive" emulator: argv[36] = "if=none,index=3,id=encrypt,file=/path/to/aosp/8.1.0_r60/out/target/product/generic_x86_64/encryptionkey.img.qcow2,overlap-check=none,cache=unsafe,l2-cache-size=1048576" emulator: argv[37] = "-device" emulator: argv[38] = "virtio-blk-pci,drive=encrypt,iothread=disk-iothread,modern-pio-notify" emulator: argv[39] = "-drive" emulator: argv[40] = "if=none,index=4,id=vendor,file=/path/to/aosp/8.1.0_r60/out/target/product/generic_x86_64/vendor-qemu.img,read-only" emulator: argv[41] = "-device" emulator: argv[42] = "virtio-blk-pci,drive=vendor,iothread=disk-iothread,modern-pio-notify"
The root directory is the initrd given on the QEMU CLI, which /proc/mounts reports at:
rootfs on / type rootfs (ro,seclabel,size=886392k,nr_inodes=221598)
This contains the Android init, which through .rc must be mounting mounts the drives int o the right places TODO find exact point.
The drive order is:
system cache userdata encryptionkey vendor-qemu
Then, on the terminal:
mount | grep vd
gives:
/dev/block/vda1 on /system type ext4 (ro,seclabel,relatime,data=ordered) /dev/block/vde1 on /vendor type ext4 (ro,seclabel,relatime,data=ordered) /dev/block/vdb on /cache type ext4 (rw,seclabel,nosuid,nodev,noatime,errors=panic,data=ordered)
and we see that the order of vda, vdb, etc. matches that in which -drive were given to QEMU.
Tested on: 8.1.0_r60.
34.1.1. Android images read-only
From mount, we can see that some of the mounted images are ro.
Basically, every image that was given to QEMU as qcow2 is writable, and that qcow2 is an overlay over the actual original image.
In order to make /system and /vendor writable by using qcow2 for them as well, we must use the -writable-system option:
./run-android -- -writable-system
then:
su mount -o rw,remount /system date >/system/a
Now reboot, and relaunch with -writable-system once again to pick up the modified qcow2 images:
./run-android -- -writable-system
and the newly created file is still there:
date >/system/a
/system and /vendor can be nuked quickly with:
./build-android --extra-args snod ./build-android --extra-args vnod
as mentioned at: https://stackoverflow.com/questions/29023406/how-to-just-build-android-system-image and on:
./build-android --extra-args help
Tested on: 8.1.0_r60.
34.1.2. Android /data partition
When I install an app like F-Droid, it goes under /data according to:
find / -iname '*fdroid*'
and it persists across boots.
/data is behind a RW LVM device:
/dev/block/dm-0 on /data type ext4 (rw,seclabel,nosuid,nodev,noatime,errors=panic,data=ordered)
but TODO I can’t find where it comes from since I don’t have the CLI tools mentioned at:
However, by looking at:
./run-android -- -help
we see:
-data <file> data image (default <datadir>/userdata-qemu.img
which confirms the suspicion that this data goes in userdata-qemu.img.
To reset images to their original state, just remove the qcow2 overlay and regenerate it: https://stackoverflow.com/questions/54446680/how-to-reset-the-userdata-image-when-building-android-aosp-and-running-it-on-the
Tested on: 8.1.0_r60.
34.2. Install Android apps
I don’t know how to download files from the web on Vanilla android, the default browser does not download anything, and there is no wget:
Installing with adb install does however work: https://stackoverflow.com/questions/7076240/install-an-apk-file-from-command-prompt
F-Droid installed fine like that, however it does not have permission to install apps: https://www.maketecheasier.com/install-apps-from-unknown-sources-android/
And the Settings app crashes so I can’t change it, logcat contains:
No service published for: wifip2p
which is mentioned at: https://stackoverflow.com/questions/47839955/android-8-settings-app-crashes-on-emulator-with-clean-aosp-build
We also tried to enable it from the command line with:
settings put secure install_non_market_apps 1
as mentioned at: https://android.stackexchange.com/questions/77280/allow-unknown-sources-from-terminal-without-going-to-settings-app but it didn’t work either.
No person alive seems to know how to pre-install apps on AOSP: https://stackoverflow.com/questions/6249458/pre-installing-android-application
Tested on: 8.1.0_r60.
34.3. Android init
For Linux in general, see: Section 7, “init”.
The /init executable interprets the /init.rc files, which is in a custom Android init system language: https://android.googlesource.com/platform/system/core/+/ee0e63f71d90537bb0570e77aa8a699cc222cfaf/init/README.md
The top of that file then sources other .rc files present on the root directory:
import /init.environ.rc
import /init.usb.rc
import /init.${ro.hardware}.rc
import /vendor/etc/init/hw/init.${ro.hardware}.rc
import /init.usb.configfs.rc
import /init.${ro.zygote}.rc
TODO: how is ro.hardware determined? https://stackoverflow.com/questions/20572781/android-boot-where-is-the-init-hardware-rc-read-in-init-c-where-are-servic It is a system property and can be obtained with:
getprop ro.hardware
This gives:
ranchu
which is the codename for the QEMU virtual platform we are running on: https://www.oreilly.com/library/view/android-system-programming/9781787125360/9736a97c-cd09-40c3-b14d-955717648302.xhtml
TODO: is it possible to add a custom .rc file without modifying the initrd that gets mounted on root? https://stackoverflow.com/questions/9768103/make-persistent-changes-to-init-rc
Tested on: 8.1.0_r60.
35. Benchmark this repo
TODO: didn’t fully port during refactor after 3b0a343647bed577586989fb702b760bd280844a. Reimplementing should not be hard.
In this section document how benchmark builds and runs of this repo, and how to investigate what the bottleneck is.
Ideally, we should setup an automated build server that benchmarks those things continuously for us, but our Travis attempt failed.
So currently, we are running benchmarks manually when it seems reasonable and uploading them to: https://github.com/cirosantilli/linux-kernel-module-cheat-regression
All benchmarks were run on the 2017 Lenovo ThinkPad P51 machine, unless stated otherwise.
Run all benchmarks and upload the results:
cd .. git clone https://github.com/cirosantilli/linux-kernel-module-cheat-regression cd - ./bench-all -A
35.1. Continuous integration
We have explored a few Continuous integration solutions.
We haven’t setup any of them yet.
35.1.1. Travis
We tried to automate it on Travis with .travis.yml but it hits the current 50 minute job timeout: https://travis-ci.org/cirosantilli/linux-kernel-module-cheat/builds/296454523 And I bet it would likely hit a disk maxout either way if it went on.
35.1.2. CircleCI
This setup successfully built gem5 on every commit: .circleci/config.yml
Enabling it is however blocked on: https://github.com/cirosantilli/linux-kernel-module-cheat/issues/79 so we disabled the builds on the web UI.
If that ever gets done, we will also need to:
-
convert this to a nightly with a workflow, to save server resources: https://circleci.com/docs/2.0/configuration-reference/#triggers
-
download the prebuilt disk images and enable caches to save the images across runs
A build took about 1 hour of a core, and the free tier allows for 1000 minutes per month: https://circleci.com/pricing/ so about 17 hours. The cheapest non-free setup seems to be 50 dollars per month gets us infinite build minutes per month and 2 containers, so we could scale things to run in under 24 hours.
There is no result reporting web UI however… but neither does GitLab CI: https://gitlab.com/gitlab-org/gitlab-ce/issues/17081
35.2. Benchmark this repo benchmarks
35.2.1. Benchmark Linux kernel boot
Run all kernel boot benchmarks for one arch:
./build-test-boot --size 3 && ./test-boot --all-archs --all-emulators --size 3 cat "$(./getvar test_boot_benchmark_file)"
Sample results at LKMC 8fb9db39316d43a6dbd571e04dd46ae73915027f:
cmd ./run --arch x86_64 --eval './linux/poweroff.out' time 8.25 exit_status 0 cmd ./run --arch x86_64 --eval './linux/poweroff.out' --kvm time 1.22 exit_status 0 cmd ./run --arch x86_64 --eval './linux/poweroff.out' --trace exec_tb time 8.83 exit_status 0 instructions 2244297 cmd ./run --arch x86_64 --eval 'm5 exit' --emulator gem5 time 213.39 exit_status 0 instructions 318486337 cmd ./run --arch arm --eval './linux/poweroff.out' time 6.62 exit_status 0 cmd ./run --arch arm --eval './linux/poweroff.out' --trace exec_tb time 6.90 exit_status 0 instructions 776374 cmd ./run --arch arm --eval 'm5 exit' --emulator gem5 time 118.46 exit_status 0 instructions 153023392 cmd ./run --arch arm --eval 'm5 exit' --emulator gem5 -- --cpu-type=HPI --caches --l2cache --l1d_size=1024kB --l1i_size=1024kB --l2_size=1024kB --l3_size=1024kB time 2250.40 exit_status 0 instructions 151981914 cmd ./run --arch aarch64 --eval './linux/poweroff.out' time 4.94 exit_status 0 cmd ./run --arch aarch64 --eval './linux/poweroff.out' --trace exec_tb time 5.04 exit_status 0 instructions 233162 cmd ./run --arch aarch64 --eval 'm5 exit' --emulator gem5 time 70.89 exit_status 0 instructions 124346081 cmd ./run --arch aarch64 --eval 'm5 exit' --emulator gem5 -- --cpu-type=HPI --caches --l2cache --l1d_size=1024kB --l1i_size=1024kB --l2_size=1024kB --l3_size=1024kB time 381.86 exit_status 0 instructions 124564620 cmd ./run --arch aarch64 --eval 'm5 exit' --emulator gem5 --gem5-build-type fast time 58.00 exit_status 0 instructions 124346081 cmd ./run --arch aarch64 --eval 'm5 exit' --emulator gem5 --gem5-build-type debug time 1022.03 exit_status 0 instructions 124346081
TODO: aarch64 gem5 and QEMU use the same kernel, so why is the gem5 instruction count so much much higher?
2017 Lenovo ThinkPad P51 Ubuntu 19.10 LKMC b11e3cd9fb5df0e3fe61de28e8264bbc95ea9005 gem5 e779c19dbb51ad2f7699bd58a5c7827708e12b55 aarch64: 143s. Why huge increases from 70s on above table? Kernel size is also huge BTW: 147MB.
Note that https://gem5.atlassian.net/browse/GEM5-337 "ARM PAuth patch slows down Linux boot 2x from 2 minutes to 4 minutes" was already semi fixed at that point.
Same but with Buildroot vanilla kernel (kernel v4.19): 44s to blow up at "Please append a correct "root=" boot option; here are the available partitions" because missing some filesystem mount option. But likely wouldn’t be much more until after boot since we are almost already done by then! Therefore this vanilla kernel is much much faster! TODO find which config or kernel commit added so much time! Also that kernel is tiny at 8.5MB.
Same but hacking BR2_LINUX_KERNEL_LATEST_VERSION=y and BR2_PACKAGE_HOST_LINUX_HEADERS_CUSTOM_5_3=y which reaches kernel 5.3.14 which closer to the LKMC one 5.4.3: 40s, which is very similar for the older kernel. Therefore it does not loook like it is a problem of kernel code changes, but rather of configs.
Same but with: gem5 arm Linux kernel patches at v4.15: 73s, kernel size: 132M.
On Ubuntu 20.04, LKMC d3f8d3e99f2e554aae6c3b325b350bcf7f3f087f (Linux kernel 5.4.3), gem5 6bc2111c9674d0c8db22f6a6adcc00e49625aabd (sept 2020):
./run --arch aarch64 --emulator gem5 --quit-after-boot
took 193s. With some minimal newer kernel boot patches:
-
kernel v5.7: 238s
-
kernel v5.8: 239s
On Ubuntu 20.04 gem5 3ca404da175a66e0b958165ad75eb5f54cb5e772 this took 22 minutes 53 seconds:
./run -aa -eg --cpus 2 --tmux --quit-after-boot -- --cpu-type DerivO3CPU --caches
35.2.1.1. gem5 arm HPI boot takes much longer than aarch64
TODO 62f6870e4e0b384c4bd2d514116247e81b241251 takes 33 minutes to finish at 62f6870e4e0b384c4bd2d514116247e81b241251:
cmd ./run --arch arm --eval 'm5 exit' --emulator gem5 -- --caches --cpu-type=HPI
while aarch64 only 7 minutes.
I had previously documented on README 10 minutes at: 2eff007f7c3458be240c673c32bb33892a45d3a0 found with git log search for 10 minutes. But then I checked out there, run it, and kernel panics before any messages come out. Lol?
Logs of the runs can be found at: https://github.com/cirosantilli2/gem5-issues/tree/0df13e862b50ae20fcd10bae1a9a53e55d01caac/arm-hpi-slow
The cycle count is higher for arm, 350M vs 250M for aarch64, not nowhere near the 5x runtime time increase.
A quick look at the boot logs show that they are basically identical in structure: the same operations appear more ore less on both, and there isn’t one specific huge time pit in arm: it is just that every individual operation seems to be taking a lot longer.
35.2.1.2. gem5 x86_64 DerivO3CPU boot panics
Kernel panic - not syncing: Attempted to kill the idle task!
35.2.2. Benchmark emulators on userland executables
Let’s see how fast our simulators are running some well known or easy to understand userland benchmarks!
TODO: would be amazing to have an automated guest instructions per second count, but I’m not sure how to do that nicely for QEMU: QEMU get guest instruction count.
TODO: automate this further, produce the results table automatically, possibly by generalizing test-executables.
For now we can just run on gem5 to estimate the instruction count per input size and extrapolate?
For example, the simplest scalable CPU content would be an C busy loop, so let’s start by analyzing that one.
Summary of manually collected results on 2017 Lenovo ThinkPad P51 at LKMC a18f28e263c91362519ef550150b5c9d75fa3679 + 1: Table 7, “Busy loop MIPS for different simulator setups”. As expected, the less native/more detailed/more complex simulations are slower!
| Comment | LKMC | Benchmark build | Emulator command | Loops | Time (s) | Instruction count | Approximate MIPS | Hardware version | Host OS |
|---|---|---|---|---|---|---|---|---|---|
Native busy loop |
a7ae8e6a8e29ef46d79eb9178d8599d1faeea0e5 + 1 |
|
10^10 |
27 |
Ubuntu 20.04 |
||||
QEMU aarch64 busy loop |
a18f28e263c91362519ef550150b5c9d75fa3679 + 1 |
|
10^10 |
68 |
1.1 * 10^11 (approx) |
2000 |
|||
gem5 busy loop |
a18f28e263c91362519ef550150b5c9d75fa3679 |
|
10^6 |
18 |
2.4005699 * 10^7 |
1.3 |
|||
gem5 empty C program statically linked |
eb22fd3b6e7fff7e9ef946a88b208debf5b419d5 |
|
1 |
0 |
5475 |
872cb227fdc0b4d60acc7840889d567a6936b6e1 |
Ubuntu 20.04 |
||
gem5 empty C program dynamically linked |
eb22fd3b6e7fff7e9ef946a88b208debf5b419d5 |
|
1 |
0 |
106999 |
872cb227fdc0b4d60acc7840889d567a6936b6e1 |
Ubuntu 20.04 |
||
gem5 busy loop for a debug build |
a18f28e263c91362519ef550150b5c9d75fa3679 + 1 |
|
10^5 |
33 |
2.405682 * 10^6 |
0.07 |
|||
gem5 busy loop for a fast build |
0d5a41a3f88fcd7ed40fc19474fe5aed0463663f + 1 |
userland/gcc/busy_loop.c |
|
10^6 |
15 |
2.4005699 * 10^7 |
1.6 |
||
gem5 busy loop for a TimingSimpleCPU |
a18f28e263c91362519ef550150b5c9d75fa3679 + 1 |
|
10^6 |
26 |
2.4005699 * 10^7 |
0.9 |
|||
gem5 busy loop for a MinorCPU |
a18f28e263c91362519ef550150b5c9d75fa3679 + 1 |
|
10^6 |
31 |
1.1018152 * 10^7 |
0.4 |
|||
gem5 busy loop for a DerivO3CPU |
a18f28e263c91362519ef550150b5c9d75fa3679 + 1 |
|
10^6 |
52 |
1.1018128 * 10^7 |
0.2 |
|||
a18f28e263c91362519ef550150b5c9d75fa3679 + 1 |
|
1 * 1000000 = 10^6 |
63 |
1.1005150 * 10^7 |
0.2 |
||||
glibc C pre-main effects |
ab6f7331406b22f8ab6e2df5f8b8e464fb35b611 |
|
1 |
2 |
1.26479 * 10^5 |
0.05 |
|||
ab6f7331406b22f8ab6e2df5f8b8e464fb35b611 |
glibc C pre-main userland/c/m5ops.c |
|
1 |
2 |
1.26479 * 10^5 |
0.05 |
|||
ab6f7331406b22f8ab6e2df5f8b8e464fb35b611 |
glibc C++ pre-main userland/cpp/m5ops.cpp |
|
1 |
2 |
2.385012 * 10^6 |
1 |
|||
ab6f7331406b22f8ab6e2df5f8b8e464fb35b611 |
glibc C++ pre-main userland/cpp/m5ops.cpp |
|
1 |
25 |
2.385012 * 10^6 |
0.1 |
|||
gem5 optimized build immediate exit on first instruction to benchmark the simulator startup time |
ab6f7331406b22f8ab6e2df5f8b8e464fb35b611 |
immediate exit userland/freestanding/gem5_exit.S |
|
1 |
1 |
1 |
|||
same as above but debug build |
ab6f7331406b22f8ab6e2df5f8b8e464fb35b611 |
|
1 |
1 |
1 |
||||
Check the effect of an ExecAll log (log every instruction) on execution time, compare to analogous run without it. |
d29a07ddad499f273cc90dd66e40f8474b5dfc40 |
|
10^6 |
2.4106774 * 10^7 |
136 |
0.2 |
Same as above but with run command manually hacked to output to a ramfs. Slightly faster, but the bulk was still just in log format operations! |
The first step is to determine a number of loops that will run long enough to have meaningful results, but not too long that we will get bored, so about 1 minute.
On our 2017 Lenovo ThinkPad P51 machine, we found 10^7 (10 million == 1000 times 10000) loops to be a good number for a gem5 atomic simulation:
./run --arch aarch64 --emulator gem5 --userland userland/gcc/busy_loop.c --cli-args '1 10000000' ./gem5-stat --arch aarch64 sim_insts
as it gives:
-
time: 00:01:40
-
instructions: 110018162 ~ 110 millions
so ~ 110 million instructions / 100 seconds makes ~ 1 MIPS (million instructions per second).
This experiment also suggests that each loop is about 11 instructions long (110M instructions / 10M loops), which we confirm at Section 36.2, “C busy loop”, bingo!
Then for QEMU, we experimentally turn the number of loops up to 10^10 loops (100000 100000), which contains an expected 11 * 10^10 instructions, and the runtime is 00:01:08, so we have 1.1 * 10^11 instruction / 68 seconds ~ 2 * 10^9 = 2000 MIPS!
We can then repeat the experiment for other gem5 CPUs to see how they compare.
35.2.2.1. User mode vs full system benchmark
Let’s see if user mode runs considerably faster than full system or not, ignoring the kernel boot.
First we build dhrystonee manually statically since dynamic linking is broken in gem5 as explained at: Section 11.7, “gem5 syscall emulation mode”.
gem5 user mode:
./build-buildroot --arch arm --config 'BR2_PACKAGE_DHRYSTONE=y' make \ -B \ -C "$(./getvar --arch arm buildroot_build_build_dir)/dhrystone-2" \ CC="$(./run-toolchain --arch arm --print-tool gcc)" \ CFLAGS=-static \ ; time \ ./run \ --arch arm \ --emulator gem5 \ --userland "$(./getvar --arch arm buildroot_build_build_dir)/dhrystone-2/dhrystone" \ --cli-args 'asdf qwer' \ ;
gem5 full system:
time \ ./run \ --arch arm \ --eval-after './gem5.sh' \ --emulator gem5 --gem5-readfile 'dhrystone 100000' \ ;
QEMU user mode:
time qemu-arm "$(./getvar --arch arm buildroot_build_build_dir)/dhrystone-2/dhrystone" 100000000
QEMU full system:
time \ ./run \ --arch arm \ --eval-after 'time dhrystone 100000000;./linux/poweroff.out' \ ;
Result on 2017 Lenovo ThinkPad P51 at bad30f513c46c1b0995d3a10c0d9bc2a33dc4fa0:
-
gem5 user: 33 seconds
-
gem5 full system: 51 seconds
-
QEMU user: 45 seconds
-
QEMU full system: 223 seconds
35.2.3. Benchmark builds
The build times are calculated after doing ./configure and make source, which downloads the sources, and basically benchmarks the Internet.
Sample build time at 2c12b21b304178a81c9912817b782ead0286d282: 28 minutes, 15 with full ccache hits. Breakdown: 19% GCC, 13% Linux kernel, 7% uclibc, 6% host-python, 5% host-qemu, 5% host-gdb, 2% host-binutils
Buildroot automatically stores build timestamps as milliseconds since Epoch. Convert to minutes:
awk -F: 'NR==1{start=$1}; END{print ($1 - start)/(60000.0)}' "$(./getvar buildroot_build_build_dir)/build-time.log"
Or to conveniently do a clean build without affecting your current one:
./bench-all -b cat ../linux-kernel-module-cheat-regression/*/build-time.log
35.2.3.1. Find which Buildroot packages are making the build slow and big
./build-buildroot -- graph-build graph-size graph-depends cd "$(./getvar buildroot_build_dir)/graphs" xdg-open build.pie-packages.pdf xdg-open graph-depends.pdf xdg-open graph-size.pdf
35.2.3.1.1. Buildroot use prebuilt host toolchain
The biggest build time hog is always GCC, and it does not look like we can use a precompiled one: https://stackoverflow.com/questions/10833672/buildroot-environment-with-host-toolchain
35.2.3.2. Benchmark Buildroot build baseline
This is the minimal build we could expect to get away with.
We will run this whenever the Buildroot submodule is updated.
On the upstream Buildroot repo at :
./bench-all -B
Sample time on 2017.08: 11 minutes, 7 with full ccache hits. Breakdown: 47% GCC, 15% Linux kernel, 9% uclibc, 5% host-binutils. Conclusions:
-
we have bloated our kernel build 3x with all those delicious features :-)
-
GCC time increased 1.5x by our bloat, but its percentage of the total was greatly reduced, due to new packages being introduced.
make graph-dependsshows that most new dependencies come from QEMU and GDB, which we can’t get rid of anyway.
A quick look at the system monitor reveals that the build switches between times when:
-
CPUs are at a max, memory is fine. So we must be CPU / memory speed bound. I bet that this happens during heavy compilation.
-
CPUs are not at a max, and memory is fine. So we are likely disk bound. I bet that this happens during configuration steps.
This is consistent with the fact that ccache reduces the build time only partially, since ccache should only overcome the CPU bound compilation steps, but not the disk bound ones.
The instructions counts varied very little between the baseline and LKMC, so runtime overhead is not a big deal apparently.
Size:
-
bzImage: 4.4M -
rootfs.cpio: 1.6M
Zipped: 4.9M, rootfs.cpio deflates 50%, bzImage almost nothing.
35.2.3.3. Benchmark gem5 build
How long it takes to build gem5 itself.
We will update this whenever the gem5 submodule is updated.
All benchmarks done on 2017 Lenovo ThinkPad P51.
Get results with:
./bench-all --emulator gem5 tail -n+1 ../linux-kernel-module-cheat-regression/*/gem5-bench-build-*.txt
Ubuntu 19.10, GCC 9.2.1, LKMC 7c6bb29bc89ec3f1056c0680c3f08bd64018a7bc, gem5 d7d9bc240615625141cd6feddbadd392457e49eb (2020-02-18), ./build --arch aarch64 --gem5-worktree master --no-cache: 19m 33s TODO must investigate why it got so much worse.
Ubuntu 20.04, GCC 9.3.0, LKMC 6275f70ed8862d8fe4e58ca4524a6994d254be35, gem5 d9cb548d83fa81858599807f54b52e5be35a6b03 (2020-05-06), ./build --arch aarch64 --gem5-worktree master --no-cache: 28m!!! It’s out of control.
Same but gem5 d7d9bc240615625141cd6feddbadd392457e49eb (2018-06-17) hacked with -Wnoerror: 11m 37s. So there was a huge regression in the last two years! We have to find it out.
A profiling of the build has been done at: https://gem5.atlassian.net/browse/GEM5-277 Analysis there showed that d7d9bc240615625141cd6feddbadd392457e49eb (2018-06-17) is also composed of 50% pybind11 and with no obvious time sinks.
35.2.3.3.1. pybind11 accounts for 50% of gem5 build time
Yes, pybind11 is slow to build.
See also: gem5 Python C++ interaction.
35.2.3.3.2. Benchmark gem5 single file change rebuild time
This is the critical development parameter, and is dominated by the link time of huge binaries.
In order to benchmark it better, make a comment only change to:
vim submodules/gem5/src/sim/main.cc
then rebuild with:
./build-gem5 --arch aarch64 --verbose
and then copy the link command to a separate Bash file. Then you can time and modify it easily.
Some approximate reference values on 2017 Lenovo ThinkPad P51 LKMC d4b3e064adeeace3c3e7d106801f95c14637c12f + 1 (doing multiple runs to warm up disk caches):
-
opt-
unmodified: 10 seconds
-
LDFLAGS_EXTRA=-fuse-ld=gold: 6 seconds. Huge improvement! Note that in general you have to do a full rebuild or else link may fail: https://sourceware.org/bugzilla/show_bug.cgi?id=23869More info on gold:
-
-
debug-
unmodified: 14 seconds. Why so much slower than unmodified?
-
-fuse-ld=gold:internal error in read_cie, at ../../gold/ehframe.cc:919on Ubuntu 18.04 all GCC. https://sourceware.org/bugzilla/show_bug.cgi?id=23869
-
-
fast-
--force-lto: 1 minute. Slower as expected, since more optimizations are done at link time.--force-ltois only used forfast, and it adds-fltoto the build.
-
-
opt LDFLAGS_EXTRA=-s: stripping the executable greatly reduces link time, but you get no symbols
ramfs made no difference, the kernel must be caching files in memory very efficiently already.
In addition to the link time, scons startup time can also be considerable:
On LKMC 220c3a434499e4713664d4a47c246cb81ee0a06a gem5 63e96992568d8a8a0dccac477b8b7f1370ac7e98 (Sep 2020):
-
opt-
default link:
18.32user 3.99system 0:22.33elapsed 99%CPU (0avgtext+0avgdata 4622908maxresident)k -
LDFLAGS_EXTRA=-fuse-ld=lld(after a build with default linker):6.74user 1.81system 0:03.85elapsed 222%CPU (0avgtext+0avgdata 7025292maxresident)k -
LDFLAGS_EXTRA=-fuse-ld=gold:7.70user 1.36system 0:09.44elapsed 95%CPU (0avgtext+0avgdata 5959152maxresident)k-
LDFLAGS_EXTRA=-fuse-ld=gold -Wl,--threads -Wl,--thread-count=8:9.66user 1.86system 0:04.62elapsed 249%CPU (0avgtext+0avgdata 5989916maxresident)kArghhh, it does not use multile threads by default… https://stackoverflow.com/questions/5142753/can-gcc-use-multiple-cores-when-linking/42302047#42302047
-
-
35.3. Benchmark machines
35.3.1. 2017 Lenovo ThinkPad P51
Serial number: TYPE 20HH-CTO1WW S/N PF-0V5V5N 17/11
Hardware maintenance manual: https://download.lenovo.com/pccbbs/mobiles_pdf/p51_hmm_en_sp40k88791_01.pdf (archive)
Summary string of key hardware for copy paste:
Lenovo ThinkPad P51 laptop with CPU: Intel Core i7-7820HQ (4 cores / 8 threads, 2.90 GHz base, 8 MB cache), DRAM: 2x Samsung M471A2K43BB1-CRC (2x 16GiB, 2400 Mbps), SSD: Samsung MZVLB512HAJQ-000L7 (512GB, 3,000 MB/s).
Further specs:
-
Hard disk: Seagate ST1000LM035-1RK1 1TB hard disk
-
Pre-installed OS:
-
Windows 10 Pro 64
-
Windows 10 Pro 64 WE (EN/FR/DE/NL/IT)
-
-
Display: 15.6" FHD (1920x1080), anti-glare, IPS
-
With Color Sensor
-
720p HD Camera with Microphone
-
Keyboard with Number Pad - Euro English
-
3+3BCP, Fingerprint Reader,Color Sensor
-
Integrated Fingerprint Reader
-
Hardware dTPM2.0 Enabled
-
1TB 5400rpm HDD
-
170W AC Adapter - UK(3pin)
-
6 Cell Li-Polymer Battery, 90Wh
-
Intel Dual Band Wireless AC(2x2) 8265, Bluetooth Version 4.1, vPro
Parts:
-
keyboard FRU number: 01HW271 (written on part, Payton2Walter2 NBL KBD,USI,DFN according to https://support.lenovo.com/us/en/partslookup That website says 01ER981 is equivalent (Payton2Walter2 NBL KBD,USI,CHY), just different manufacturer
Reddit threads:
35.3.1.2. Intel Core i7-7820HQ CPU
https://ark.intel.com/products/97496/Intel-Core-i7-7820HQ-Processor-8M-Cache-up-to-3-90-GHz- (archive).
Cache: 8MB
Max frequency: 3.90GHz
Cores: 4
Recommended customer price: 378.00 USD
Launch date: Q1'17
Process: 14 nm
cat /proc/cpuinfo of one CPU on Ubuntu 20.04 Linux kernel 5.4.0:
processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 158 model name : Intel(R) Core(TM) i7-7820HQ CPU @ 2.90GHz stepping : 9 microcode : 0xd6 cpu MHz : 1025.664 cache size : 8192 KB physical id : 0 siblings : 8 core id : 0 cpu cores : 4 apicid : 0 initial apicid : 0 fpu : yes fpu_exception : yes cpuid level : 22 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_single pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp md_clear flush_l1d bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs taa itlb_multihit srbds bogomips : 5799.77 clflush size : 64 cache_alignment : 64 address sizes : 39 bits physical, 48 bits virtual power management:
getconf -a | grep CACHE on Ubuntu 20.04 Linux kernel 5.4.0:
LEVEL1_ICACHE_SIZE 32768 LEVEL1_ICACHE_ASSOC 8 LEVEL1_ICACHE_LINESIZE 64 LEVEL1_DCACHE_SIZE 32768 LEVEL1_DCACHE_ASSOC 8 LEVEL1_DCACHE_LINESIZE 64 LEVEL2_CACHE_SIZE 262144 LEVEL2_CACHE_ASSOC 4 LEVEL2_CACHE_LINESIZE 64 LEVEL3_CACHE_SIZE 8388608 LEVEL3_CACHE_ASSOC 16 LEVEL3_CACHE_LINESIZE 64 LEVEL4_CACHE_SIZE 0 LEVEL4_CACHE_ASSOC 0 LEVEL4_CACHE_LINESIZE 0
35.3.1.3. Samsung M471A2K43BB1-CRC 16GB DRAM
Nominal speed: 2400 Mbps
Type: SODIMM
https://www.amazon.co.uk/Samsung-DDR4-16-GB-DDR4-2400-MHz-Memory-Module/dp/B016N24XKQ (archive) 355.43 UK Pounds for 2x 16 GiB.
35.4. Benchmark Internets
35.4.1. 38Mbps internet
2c12b21b304178a81c9912817b782ead0286d282:
-
shallow clone of all submodules: 4 minutes.
-
make source: 2 minutes
Google M-lab speed test: 36.4Mbps
35.5. Benchmark this repo bibliography
gem5:
-
https://www.mail-archive.com/gem5-users@gem5.org/msg15262.html which parts of the gem5 code make it slow
-
what are the minimum system requirements:
36. Compilers
Argh, compilers are boring, let’s learn a bit about them.
36.1. Prevent statement reordering
We often need to do this to be sure that benchmark instrumentation is actually being put around the region of interest!
36.2. C busy loop
The hard part is how to prevent the compiler from optimizing it away: https://stackoverflow.com/questions/7083482/how-to-prevent-gcc-from-optimizing-out-a-busy-wait-loop/58758133#58758133
Disassembly analysis:
./disas --arch aarch64 --userland userland/gcc/busy_loop.out busy_loop
which contains at LKMC eb22fd3b6e7fff7e9ef946a88b208debf5b419d5:
10 ) {
0x0000000000400700 <+0>: ff 83 00 d1 sub sp, sp, #0x20
0x0000000000400704 <+4>: e0 07 00 f9 str x0, [sp, #8]
0x0000000000400708 <+8>: e1 03 00 f9 str x1, [sp]
11 for (unsigned long long i = 0; i < max2; i++) {
0x000000000040070c <+12>: ff 0f 00 f9 str xzr, [sp, #24]
0x0000000000400710 <+16>: 11 00 00 14 b 0x400754 <busy_loop+84>
12 for (unsigned long long j = 0; j < max; j++) {
0x0000000000400714 <+20>: ff 0b 00 f9 str xzr, [sp, #16]
0x0000000000400718 <+24>: 08 00 00 14 b 0x400738 <busy_loop+56>
13 __asm__ __volatile__ ("" : "+g" (i), "+g" (j) : :);
0x000000000040071c <+28>: e1 0f 40 f9 ldr x1, [sp, #24]
0x0000000000400720 <+32>: e0 0b 40 f9 ldr x0, [sp, #16]
0x0000000000400724 <+36>: e1 0f 00 f9 str x1, [sp, #24]
0x0000000000400728 <+40>: e0 0b 00 f9 str x0, [sp, #16]
12 for (unsigned long long j = 0; j < max; j++) {
0x000000000040072c <+44>: e0 0b 40 f9 ldr x0, [sp, #16]
0x0000000000400730 <+48>: 00 04 00 91 add x0, x0, #0x1
0x0000000000400734 <+52>: e0 0b 00 f9 str x0, [sp, #16]
0x0000000000400738 <+56>: e1 0b 40 f9 ldr x1, [sp, #16]
0x000000000040073c <+60>: e0 07 40 f9 ldr x0, [sp, #8]
0x0000000000400740 <+64>: 3f 00 00 eb cmp x1, x0
0x0000000000400744 <+68>: c3 fe ff 54 b.cc 0x40071c <busy_loop+28> // b.lo, b.ul, b.last
11 for (unsigned long long i = 0; i < max2; i++) {
0x0000000000400748 <+72>: e0 0f 40 f9 ldr x0, [sp, #24]
0x000000000040074c <+76>: 00 04 00 91 add x0, x0, #0x1
0x0000000000400750 <+80>: e0 0f 00 f9 str x0, [sp, #24]
0x0000000000400754 <+84>: e1 0f 40 f9 ldr x1, [sp, #24]
0x0000000000400758 <+88>: e0 03 40 f9 ldr x0, [sp]
0x000000000040075c <+92>: 3f 00 00 eb cmp x1, x0
0x0000000000400760 <+96>: a3 fd ff 54 b.cc 0x400714 <busy_loop+20> // b.lo, b.ul, b.last
14 }
15 }
16 }
0x0000000000400764 <+100>: 1f 20 03 d5 nop
0x0000000000400768 <+104>: ff 83 00 91 add sp, sp, #0x20
0x000000000040076c <+108>: c0 03 5f d6 ret
We look for the internal backwards jumps, and we find two:
0x00000000004006dc <+68>: c8 fe ff 54 b.hi 0x4006b4 <busy_loop+28> // b.pmore 0x00000000004006f8 <+96>: a8 fd ff 54 b.hi 0x4006ac <busy_loop+20> // b.pmore
and so clearly the one at 0x4006dc happens first and jumps to a larger address than the other one, so the internal loop must be between 4006dc and 4006b4, which contains exactly 11 instructions.
Oh my God, unoptimized code is so horrendously inefficient, even I can’t stand all those useless loads and stores to memory variables!!!
37. Computer architecture
37.1. Instruction pipelining
In gem5, can be seen on:
37.1.1. Classic RISC pipeline
gem5’s gem5 MinorCPU implements a similar but 4 stage pipeline. TODO why didn’t they go with the classic RISC pipeline instead?
37.2. Superscalar processor
http://www.lighterra.com/papers/modernmicroprocessors/ explains it well.
You basically decode multiple instructions in one go, and run them at the same time if they can go in separate functional units and have no conflicts. Genius!
And so the concept of branch predictor must come in here: when a conditional branch is reached, you have to decide which side to execute before knowing for sure.
This is why it is called a type of Instruction level parallelism.
Although this is a microarchitectural feature, it is so important that it is publicly documented. For example:
-
https://en.wikipedia.org/wiki/ARM_Cortex-A77: ARM Cortex A77 (2019) has a 4-wide superscalar decode (and is out-of-order)
37.2.1. Execution unit
gem5 calls them "functional units".
gem5 has functional units explicitly modelled as shown at gem5 functional units, and those are used by both gem5 MinorCPU and gem5 DerivO3CPU.
37.3. Out-of-order execution
gem5’s model is gem5 DerivO3CPU.
Allows working around data dependencies: you can execute the second next instruction forward if the first next depends on the current one.
Likely used on basically all (?) 2020 non-power-constrained CPUs.
As mentioned at: https://stackoverflow.com/questions/10074831/what-is-general-difference-between-superscalar-and-ooo-execution it is in theory possible for an out-of-order CPU to not a Superscalar processor, but the combination is so natural (since you can look ahead, you might as well run it!) that it is not super common.
37.3.1. Speculative execution
A gem5 example can be seen at: gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: speculative.
Bibliography:
37.3.1.1. Branch predictor
Comes in for superscalar processors.
A gem5 example can be seen at: gem5 event queue DerivO3CPU syscall emulation freestanding example analysis: speculative.
37.4. Instruction level parallelism
Basically means decoding and then potentially executing a bunch of instructions in one go.
Important examples:
37.5. Hardware threads
Intel name: "Hyperthreading"
gem5 appears to possibly have attempted to implement hardware threads in gem5 syscall emulation mode as mentioned at gem5 syscall emulation --smt.
On fs.py it is not exposed in any in-tree config however, and as pointed by the above issue O3 FS has an assert that prevents it in src/cpu/o3/cpu.cc:
// SMT is not supported in FS mode yet.
assert(this->numThreads == 1);
TODO why only in fs.py? Is there much difference between fs and se from a hyperthreading point of view? Maybe the message is there because as concluded in gem5 O3ThreadContext, registeres for DerivO3CPU are stored in DerivO3CPU itself (FullO3CPU), and therefore there is no way to to currently represent multiple register sets per CPU.
Other CPUs just appear to fail non-gracefully, e.g.:
./run --arch aarch64 --emulator gem5 -- --param 'system.cpu[0].numThreads = 2'
fails with:
fatal: fatal condition interrupts.size() != numThreads occurred: CPU system.cpu has 1 interrupt controllers, but is expecting one per thread (2)
37.6. Caches
https://courses.cs.washington.edu/courses/cse378/09wi/lectures/lec15.pdf contains some of the first pictures you should see.
In a direct-mapped cache architecture (every address has a single possible block), a memory address can be broken up into:
+-----+-------+--------------+ | | | | full address +-----+-------+--------------+ | | | | | tag | index | block offset |
where:
-
index: determines in which block the address will go. This is the "index/ID of the block" it will go into!
-
tag: allows us to differentiate between multiple addresses that have the same index
We really want tag to be the higher bits, so that consecutive blocks may be placed in the cache at once.
-
block offset: address withing the cache. Not used to find caches at all! Only used to find the data within the cache line
If the cache is set associative, we just simply make the index smaller and add a bits to the tag.
For example, for a 2-way associative cache, we remove on bit from the index, and add it to the tag.
37.6.1. Cache coherence
In simple terms, when a certain group of caches of different CPUs are coherent, reads on one core always see the writes previously made by other cores. TODO: is it that strict, or just ordering? TODO what about simultaneous read and writes?
Cache coherence:
-
guarantees eventual write propagation
-
guarantees a single order of all writes to same location
-
no guarantees on when writes propagate
And notably it contrasts that with Memory consistency, which according to them is about ordering requirements on different addresses.
Algorithms to keep the caches of different cores of a system coherent. Only matters for multicore systems.
The main goal of such systems is to reduce the number of messages that have to be sent on the coherency bus, and even more importantly, to memory (which passes first through the coherency bus).
The main software use case example to have in mind is that of multiple threads incrementing an atomic counter as in userland/cpp/atomic/std_atomic.cpp, see also: atomic.cpp. Then, if one processors writes to the cache, other processors have to know about it before they read from that address.
Even if caches are coherent, this is still not enough to avoid data race conditions, because this does not enforce atomicity of read modify write sequences. This is for example shown at: Detailed gem5 analysis of how data races happen.
37.6.1.1. Memory consistency
According to http://www.inf.ed.ac.uk/teaching/courses/pa/Notes/lecture07-sc.pdf "memory consistency" is about ordering requirements of different memory addresses.
This is represented explicitly in C++ for example C++ std::memory_order.
37.6.1.1.1. Sequential Consistency
According to http://www.inf.ed.ac.uk/teaching/courses/pa/Notes/lecture07-sc.pdf, the strongest possible consistency, everything nicely ordered as you’d expect.
37.6.1.2. Can caches snoop data from other caches?
Either they can snoop only control, or both control and data can be snooped.
The answer to this determines if some of the following design decisions make sense.
This is the central point in question at: https://electronics.stackexchange.com/questions/484830/why-is-a-flush-needed-in-the-msi-cache-coherency-protocol-when-moving-from-modif
If data snoops are not possible, then data must always to to DRAM first.
37.6.1.3. VI cache coherence protocol
Mentioned at:
This is the most trivial, but likely it is too bad and most sources don’t even mention it.
In what follows I make some stuff up with design choice comparisons, needs confirmation.
In this protocol, every cache only needs a single bit of state: validity.
At the start, everything is invalid.
Then, when you need to read and are invalid, you send a read on bus. If there is another valid cache in another CPU, it services the request. Otherwise, goes the request goes to memory. After read you become valid.
Read for valid generates no bus requests, which is good.
When you write, if you are invalid, you must first read to get the full cache line, like for any other protocol.
Then, there are two possible design choices, either:
-
that read is marked as exclusive, and all caches that had it, snoop it become invalid.
Upside: no need to send the new data to the bus.
Downside: more invalidations. But those are not too serious, because future invalid reads tend to just hit the remaining valid cache.
-
after the read and write, you send the data on the bus, and those that had it update and become valid.
Downside: much more data on bus, so likely this is not going to be the best choice.
So we take the first option.
When you write and are valid, you don’t need to read. But you still have invalidate everyone else, because multiple reads can lead to multiple valid holders, otherwise other valid holders would keep reading old values.
We could either do this with an exclusive read, and ignore the return, or with a new Invalidate request that has no reply. This invalidation is called BusUpgr to match with Wikipedia.
Write also has two other possible design choices, either:
-
every write writes through to memory. This is likely never the best option.
-
when the cache is full, eviction leads to a write to memory.
If multiple valid holders may exist, then this may lead to multiple write through evictions of the same thing.
So we take the second option.
With this we would have:
-
V
-
PrRd
-
V *
-
-
PrWr
-
V
-
BusUpgr
-
-
BusRd
-
V
-
BusData
-
-
BusRdX
-
I
-
BusData
-
-
BusUpgr
-
I *
-
-
-
I
-
PrRd
-
V
-
BusRd
-
-
PrWr
-
V
-
BusRdX
-
-
BusRd
-
I *
-
-
BusRdX
-
I *
-
-
BusUpgr
-
I *
-
-
Here Flush and BusData replies are omitted since those never lead to a change of state, nor to the sending of further messages.
TODO at:
why PrWr stays in invalid? Why do writes always go to memory? Why not wait until eviction?
37.6.1.4. MSI cache coherence protocol
This is the most basic non-trivial coherency protocol, and therefore the first one you should learn.
Compared to the VI cache coherence protocol, MSI:
-
adds one bit of knowledge per cache line (shared)
-
splits Valid into Modified and Shared depending on the shared bit
-
this allows us to not send BusUpgr messages on the bus when writing to Modified, since we now we know that the data is not present in any other cache!
Helpful video: https://www.youtube.com/watch?v=gAUVAel-2Fg "MSI Coherence - Georgia Tech - HPCA: Part 5" by Udacity.
Let’s focus on a single cache line representing a given memory address.
The system looks like this:
+----+ |DRAM| +----+ ^ | v +--------+ | BUS | +--------+ ^ ^ | | v v +------+ +------+ |CACHE1| |CACHE2| +------+ +------+ ^ ^ | | | | +----+ +----+ |CPU1| |CPU2| +----+ +----+
MSI stands for which states each cache can be in for a given cache line. The states are:
-
Modified: a single cache has the valid data and it has been modified from DRAM.
Both reads and writes are free, because we don’t have to worry about other processors.
-
Shared: the data is synchronized with DRAM, and may be present in multiple caches.
Reads are free, but writes need to do extra work.
This is the "most interesting" state of the protocol, as it allows for those free reads, even when multiple processors are using some address.
-
Invalid: the cache does not have the data, CPU reads and writes need to do extra work
The above allowed states can be summarized in the following table:
CACHE1
MSI
M nny
CACHE2 S nyy
I yyy
The whole goal of the protocol is to maintain that state at all times, so that we can get those free reads when in shared state!
To do so, the caches have to pass messages between themselves! This means generating bus traffic, which has a cost and must be kept to a minimum.
The system components can receive and send the following messages:
-
CPUn can send to CACHEn:
-
"Local read": CPU reads from cache
-
"Local write": CPU writes to cache
-
-
CACHEn to itself:
-
"Evict": the cache is running out of space due to another request
-
-
CACHEn can send the following message to the bus.
-
"Bus read": the cache needs to get the data. The reply will contain the full data line. It can come either from another cache that has the data, or from DRAM if none do.
-
"Bus write": the cache wants to modify some data, and it does not have the line.
The reply must contain the full data line, because maybe the processor just wants to change one byte, but the line is much larger.
That’s why this request can also be called "Read Exclusive", as it is basically a "Bus Read" + "Invalidate" in one
-
"Invalidate": the cache wants to modify some data, but it knows that all other caches are up to date, because it is in shared state.
Therefore, it does not need to fetch the data, which saves bus traffic compared to "Bus write" since the data itself does not need to be sent.
This is also called a Bus Upgrade message or BusUpgr, as it informs others that the value is going to be upgraded.
-
"Write back": send the data on the bus and tell someone to pick it up: either DRAM or another cache
-
When a message is sent to the bus:
-
all other caches and the DRAM will see it, this is called "snooping"
-
either caches or DRAM can reply if a reply is needed, but other caches get priority to reply earlier if they can, e.g. to serve a cache request from other caches rather than going all the way to DRAM
When a cache receives a message, it do one or both of:
-
change to another MSI state
-
send a message to the bus
And finally, the transitions are:
-
Modified:
-
"Local read": don’t need to do anything because only the current cache holds the data
-
"Local write": don’t need to do anything because only the current cache holds the data
-
"Evict": have to save data to DRAM so that our local modifications won’t be lost
-
Move to: Invalid
-
Send message: "Write back"
-
-
"Bus read": another cache is trying to read the address which we owned exclusively.
Since we know what the latest data is, we can move to "Shared" rather than "Invalid" to possibly save time on future reads.
But to do that, we need to write the data back to DRAM to maintain the shared state consistent. The MESI cache coherence protocol prevents that extra read in some cases.
And it has to be either: before the other cache gets its data from DRAM, or better, the other cache can get its data from our write back itself just like the DRAM.
-
Move to: Shared
-
Send message: "Write back"
-
-
"Bus write": someone else will write to our address.
We don’t know what they will write, so the best bet is to move to invalid.
Since the writer will become the new sole data owner, the writer can get the cache from us without going to DRAM at all! This is fine, because the writer will be the new sole owner of the line, so DRAM can remain dirty without problems.
TODO Wikipedia requires a Flush there, why? https://electronics.stackexchange.com/questions/484830/why-is-a-flush-needed-in-the-msi-cache-coherency-protocol-when-moving-from-modif
-
Move to: Invalid
-
Send message: "Write back"
-
-
-
Shared: TODO
-
"Local read":
-
"Local write":
-
"Evict":
-
"Bus read":
-
"Bus write":
-
-
Invalid: TODO
-
"Local read":
-
"Local write":
-
"Evict":
-
"Bus read":
-
"Bus write":
-
TODO gem5 concrete example.
37.6.1.4.1. MSI cache coherence protocol with transient states
TODO understand well why those are needed.
37.6.1.5. MESI cache coherence protocol
Splits the Shared of MSI cache coherence protocol into a new Exclusive state:
-
MESI Exclusive: clean but only present in one cache
-
MESI Shared: clean but present in more that one cache
Exclusive is entered from Invalid after a PrRd, but only if the reply came from DRAM (or if we snooped that no one sent the reply to DRAM for us to read it)! If the reply came from another cache, we go directly to shared instead. It is this extra information that allows for the split of S.
This is why the simplified transition diagram shown in many places e.g.: https://upload.wikimedia.org/wikipedia/commons/c/c1/Diagrama_MESI.GIF is not a proper state machine: I can go to either S or E given a PrRd.
{kind=link}
The advantage of this over MSI is that when we move from Exclusive to Modified, no invalidate message is required, reducing bus traffic: https://en.wikipedia.org/wiki/MESI_protocol#Advantages_of_MESI_over_MSI
This is a common case on read write modify loops. On MSI, it would:
-
first do PrRd
-
send BusRd (to move any M to S), get data, and go to Shared
-
then PrWr must send BusUpgr to invalidate other Shared and move to M
With MESI:
-
the PrRd could go to E instead of S depending on who services it
-
if it does go to E, then the PrWr only moves it to M, there is no need to send BusUpgr because we know that no one else is in S
gem5 12c917de54145d2d50260035ba7fa614e25317a3 has two Ruby MESI models implemented: MESI_Two_Level and MESI_Three_Level.
37.6.1.6. MOSI cache coherence protocol
https://en.wikipedia.org/wiki/MOSI_protocol The critical MSI vs MOSI section was a bit bogus though: https://en.wikipedia.org/w/index.php?title=MOSI_protocol&oldid=895443023 but I edited it :-)
In MSI, it feels wasteful that an MS transaction needs to flush to memory: why do we need to flush right now, since even more caches now have that data? Why not wait until later ant try to gain something from this deferral?
The problem with doing that in MSI, is that not flushing on an MS transaction would force us to every S eviction. So we would end up flushing even after reads!
MOSI solves that by making M move to O instead of S on BusRd. Now, O is the only responsible for the flush back on eviction.
So, in case we had:
-
processor 1: M
-
processor 2: I then read
-
processor 1: write
An MSI cache 1 would do:
-
write to main memory, go to S
-
BusUpgr, go back to M, 2 back to I
and MOSI would do:
-
go to O (no bus traffic)
-
BusUpgr, go back to M
This therefore saves one memory write through and its bus traffic.
37.6.1.7. MOESI cache coherence protocol
MESI cache coherence protocol + MOSI cache coherence protocol, not much else to it!
In gem5 9fc9c67b4242c03f165951775be5cd0812f2a705, MOESI is the default cache coherency protocol of the classic memory system as shown at Section 24.22.4.3.1, “What is the coherency protocol implemented by the classic cache system in gem5?”.
A good an simple example showing several MOESI transitions in the classic memory model can be seen at: Section 24.22.4.4, “gem5 event queue AtomicSimpleCPU syscall emulation freestanding example analysis with caches and multiple CPUs”.
gem5 12c917de54145d2d50260035ba7fa614e25317a3 has several Ruby MOESI models implemented: MOESI_AMD_Base, MOESI_CMP_directory, MOESI_CMP_token and MOESI_hammer.
38. About this repo
38.1. Supported hosts
The host requirements depend a lot on which examples you want to run.
Some setups of this repository are very portable, notably setups under Userland setup, e.g. C, and will likely work on any host system with minimal modification.
The least portable setups are those that require Buildroot and crosstool-NG.
We tend to test this repo the most on the latest Ubuntu and on the latest Ubuntu LTS.
For other Linux distros, everything will likely also just work if you install the analogous required packages for your distro.
Find out the packages that we install with:
cat ./setup ./build --download-dependencies --dry-run <some-target> | less
and then just look for the apt-get commands shown on the log.
After installing the missing packages for your distro, do the build with:
./build --download-dependencies --no-apt <some-target>
which does everything as normal, except that it skips any apt commands.
If something does not work however, Docker host setup should just work on any Linux distro.
Native Windows is unlikely feasible for Buildroot setups because Buildroot is a huge set of GNU Make scripts + host tools, just do everything from inside an Ubuntu in VirtualBox instance in that case.
Pull requests with ports to new host systems and reports on issues that things work or don’t work on your host are welcome.
38.2. Common build issues
38.2.1. You must put some 'source' URIs in your sources.list
If ./build --download-dependencies fails with:
E: You must put some 'source' URIs in your sources.list
see this: https://askubuntu.com/questions/496549/error-you-must-put-some-source-uris-in-your-sources-list/857433#857433 I don’t know how to automate this step. Why, Ubuntu, why.
38.2.2. Build from downloaded source zip files
It does not work if you just download the .zip with the sources for this repository from GitHub because we use Git submodules, you must clone this repo.
./build --download-dependencies then fetches only the required submodules for you.
38.3. Run command after boot
If you just want to run a command after boot ends without thinking much about it, just use the --eval-after option, e.g.:
./run --eval-after 'echo hello'
This option passes the command to our init scripts through Kernel command line parameters, and uses a few clever tricks along the way to make it just work.
See init for the gory details.
38.4. Default command line arguments
It gets annoying to retype --arch aarch64 for every single command, or to remember --config setups.
So simplify that, do:
cp config.py data/
and then edit the data/config file to your needs.
Source: config.py
You can also choose a different configuration file explicitly with:
./run --config data/config2.py
Almost all options names are automatically deduced from their command line --help name: just replace - with _.
More precisely, we use the dest= value of Python’s argparse module.
To get a list of all global options that you can use, try:
./getvar --type input
but note that this does not include script specific options.
38.5. Documentation
To learn how to build the documentation see: Section 2.10, “Build the documentation”.
38.5.1. Documentation verification
When running build-doc, we do the following checks:
-
<<>>inner links are not broken -
link:somefile[]links point to paths that exist via asciidoctor/extract-link-targets. Upstream wontfix at: https://github.com/asciidoctor/asciidoctor/issues/3210 -
all links in non-README files to README IDs exist via
git grep+ asciidoctor/extract-header-ids
The scripts prints what you have to fix and exits with an error status if there are any errors.
38.5.1.1. asciidoctor/extract-link-targets
Documentation for asciidoctor/extract-link-targets
Extract link targets from Asciidoctor document.
Usage:
./asciidoctor/extract-link-targets README.adoc
Output: one link target per line.
Hastily hacked from: https://asciidoctor.org/docs/user-manual/#inline-macro-processor-example
38.5.1.2. asciidoctor/extract-header-ids
Documentation for asciidoctor/extract-header-ids
Extract header IDs, both auto-generated and manually given.
E.g., for the document test.adoc:
= Auto generated [[explicitly-given]] == La la
the script:
./asciidoctor/extract-header-ids test.adoc
produces:
auto-generated explicitly-given
One application we have in mind for this is that as of 2.0.10 Asciidoctor does not warn on header ID collisions between auto-generated IDs: https://github.com/asciidoctor/asciidoctor/issues/3147 But this script doesn’t solve that yet as it would require generating the section IDs without the -N suffix. Section generation happens at Section.generate_id in Asciidoctor code.
Hastily hacked from: https://asciidoctor.org/docs/user-manual/#https://asciidoctor.org/docs/user-manual/#tree-processor-example until I noticed that that example had a bug at the time and so fixed it here: https://github.com/asciidoctor/asciidoctor/issues/3363
38.6. asciidoctor/link-target-up.rb
The Asciidoctor extension scripts:
-
link:asciidoctor-link-up.rb
-
link:asciidoctor-link-github.rb
hack the README link: targets to make them work from:
-
inside the
out/directory with../ -
GitHub pages, with explicit GitHub blob URLs
38.6.1. GitHub pages
As mentioned before the TOC, we have to push this README to GitHub pages due to: https://github.com/isaacs/github/issues/1610
For now, instead of pushing with git push, I just remember to always push with:
./publish-gh-pages
Source: publish-gh-pages
I’m going this way for now because:
-
the Jekyll Asciidoctor plugin is not enabled by default on GitHub: https://webapps.stackexchange.com/questions/114606/can-github-pages-render-asciidoc
-
I’m lazy to setup a proper Travis CI push
-
I’m the only contributor essentially, so no problems with pull requests
The only files used by the GitHub pages are:
38.7. Clean the build
You did something crazy, and nothing seems to work anymore?
All our build outputs are stored under out/, so the coarsest and most effective thing you can do is:
rm -rf out
This implies a full rebuild for all archs however, so you might first want to explore finer grained cleans first.
All our individual build-* scripts have a --clean option to completely nuke their builds:
./build-gem5 --clean ./build-qemu --clean ./build-buildroot --clean
Verify with:
ls "$(./getvar qemu_build_dir)" ls "$(./getvar gem5_build_dir)" ls "$(./getvar buildroot_build_dir)"
Note that host tools like QEMU and gem5 store all archs in a single directory to factor out build objects, so cleaning one arch will clean all of them.
To only nuke only one Buildroot package, we can use the -dirclean Buildroot target:
./build-buildroot --no-all -- <package-name>-dirclean
e.g.:
./build-buildroot --no-all -- sample_package-dirclean
Verify with:
ls "$(./getvar buildroot_build_build_dir)"
38.8. Custom build directory
For now there is no way to change the build directory from out/ (resp. out.docker for <<docker>.) to something else.
However, if you just want to place the build storage in your hard drive and the source in your SSD, which is a good configuration if you are doing lots of builds, just create a symlink as:
mkdir -p /mnt/hd/linux-kernel-module-cheat-out ln -s out /mnt/hd/linux-kernel-module-cheat-out
38.9. ccache
ccache might save you a lot of re-build when you decide to Clean the build or create a new build variant.
We have ccache enabled for everything we build by default.
However, you likely want to add the following to your .bashrc to take better advantage of ccache:
export CCACHE_DIR=~/.ccache export CCACHE_MAXSIZE="20G"
We cannot automate this because you have to decide:
-
should I store my cache on my HD or SSD?
-
how big is my build, and how many build configurations do I need to keep around at a time?
If you don’t those variables it, the default is to use ~/.buildroot-ccache with 5G, which is a bit small for us.
To check if ccache is working, run this command while a build is running on another shell:
watch -n1 'make -C "$(./getvar buildroot_build_dir)" ccache-stats'
or if you have it installed on host and the environment variables exported simply with:
watch -n1 'ccache -s'
and then watch the miss or hit counts go up.
We have enabled ccached builds by default.
BR2_CCACHE_USE_BASEDIR=n is used for Buildroot, which means that:
-
absolute paths are used and GDB can find source files
-
but builds are not reused across separated LKMC directories
ccache can be disabled with the --no-ccache option as in:
./build-gem5 --no-ccache
This can be useful to benchmark builds.
38.10. getvar
The getvar helper script can print the values of internal LKMC variables.
Within our Python scripts such as common.py, those variable are visible as self.env[<var>].
For example, to find the Buildroot output directory for an aarch64 build, you could use:
./getvar --arch aarch64 buildroot_build_dir
which as of LKMC b15a0e455d691afa49f3b813ad9b09394dfb02b7 outputs:
/path/to/linux-kernel-module-cheat/out/buildroot/build/default/aarch64
You can also list all available variables in one go with just:
./getvar
Using getvar makes it possible to make Bash scripts more portable if for example directory structure changes across LKMC versions.
For this reason, we use it in particular often in this README to reduce the need for refactoring.
38.10.1. run-toolchain
While you could just manually find/learn the path to toolchain tools, e.g. in LKMC b15a0e455d691afa49f3b813ad9b09394dfb02b7 they are:
./out/buildroot/build/default/aarch64/host/bin/aarch64-buildroot-linux-gnu-gcc userland/c/hello.c ./out/buildroot/build/default/aarch64/host/bin/aarch64-buildroot-linux-gnu-objdump -D a.out
you can save some typing and get portability across directory structure changes with our run-toolchain helper:
./run-toolchain --arch aarch64 gcc -- userland/c/hello.c ./run-toolchain --arch aarch64 objdump -- -D a.out
This plays nicely with getvar e.g. you could disassembly userland/c/hello.c with:
./run-toolchain --arch aarch64 objdump -- -D $(./getvar --arch aarch64 userland_build_dir)/c/hello.out
however disassembly is such a common use case that we have a shortcut for it: disas.
Alternatively, if you just need a variable to feed into your own Build system, you can also use getvar:
./getvar --arch aarch64 toolchain_prefix
which outputs as of LKMC b15a0e455d691afa49f3b813ad9b09394dfb02b7:
/path/to/linux-kernel-module-cheat/out/buildroot/build/default/aarch64/host/usr/bin/aarch64-buildroot-linux-gnu
38.10.1.1. disas
Since disassembly of a single function of a LKMC executable with GDB is such a common use case for run-toolchain via https://stackoverflow.com/questions/22769246/how-to-disassemble-one-single-function-using-objdump, we have this shortcut for it.
For example to disassemle a function from an userland binary:
./disas --arch aarch64 --userland userland/c/hello.c main
or to disassemble a function from the Linux kernel:
./disas --arch aarch64 start_kernel
and a baremetal executable:
./disas --arch aarch64 --baremetal baremetal/arch/aarch64/no_bootloader/exit.S _start
38.11. Rebuild Buildroot while running
It is not possible to rebuild the root filesystem while running QEMU because QEMU holds the file qcow2 file:
error while converting qcow2: Failed to get "write" lock
38.12. Simultaneous runs
When doing long simulations sweeping across multiple system parameters, it becomes fundamental to do multiple simulations in parallel.
This is specially true for gem5, which runs much slower than QEMU, and cannot use multiple host cores to speed up the simulation: https://github.com/cirosantilli2/gem5-issues/issues/15, so the only way to parallelize is to run multiple instances in parallel.
This also has a good synergy with Build variants.
First shell:
./run
Another shell:
./run --run-id 1
and now you have two QEMU instances running in parallel.
The default run id is 0.
Our scripts solve two difficulties with simultaneous runs:
-
port conflicts, e.g. GDB and gem5-shell
-
output directory conflicts, e.g. traces and gem5 stats overwriting one another
Each run gets a separate output directory. For example:
./run --arch aarch64 --emulator gem5 --run-id 0 &>/dev/null & ./run --arch aarch64 --emulator gem5 --run-id 1 &>/dev/null &
produces two separate m5out directories:
echo "$(./getvar --arch aarch64 --emulator gem5 --run-id 0 m5out_dir)" echo "$(./getvar --arch aarch64 --emulator gem5 --run-id 1 m5out_dir)"
and the gem5 host executable stdout and stderr can be found at:
less "$(./getvar --arch aarch64 --emulator gem5 --run-id 0 termout_file)" less "$(./getvar --arch aarch64 --emulator gem5 --run-id 1 termout_file)"
Each line is prepended with the timestamp in seconds since the start of the program when it appeared.
To have more semantic output directories names for later inspection, you can use a non numeric string for the run ID, and indicate the port offset explicitly:
./run --arch aarch64 --emulator gem5 --run-id some-experiment --port-offset 1
--port-offset defaults to the run ID when that is a number.
Like CPU architecture, you will need to pass the -n option to anything that needs to know runtime information, e.g. GDB step debug:
./run --run-id 1 ./run-gdb --run-id 1
To run multiple gem5 checkouts, see: Section 38.13.3.1, “gem5 worktree”.
Implementation note: we create multiple namespaces for two things:
-
run output directory
-
ports
-
QEMU allows setting all ports explicitly.
If a port is not free, it just crashes.
We assign a contiguous port range for each run ID.
-
gem5 automatically increments ports until it finds a free one.
gem5 60600f09c25255b3c8f72da7fb49100e2682093a does not seem to expose a way to set the terminal and VNC ports from
fs.py, so we just let gem5 assign the ports itself, and use-nonly to match what it assigned. Those ports both appear on gem5 config.ini.The GDB port can be assigned on
gem5.opt --remote-gdb-port, but it does not appear onconfig.ini.
-
38.13. Build variants
It often happens that you are comparing two versions of the build, a good and a bad one, and trying to figure out why the bad one is bad.
Our build variants system allows you to keep multiple built versions of all major components, so that you can easily switching between running one or the other.
38.13.1. Linux kernel build variants
If you want to keep two builds around, one for the latest Linux version, and the other for Linux v4.16:
# Build master. ./build-linux # Build another branch. git -C "$(./getvar linux_source_dir)" fetch --tags --unshallow git -C "$(./getvar linux_source_dir)" checkout v4.16 ./build-linux --linux-build-id v4.16 # Restore master. git -C "$(./getvar linux_source_dir)" checkout - # Run master. ./run # Run another branch. ./run --linux-build-id v4.16
The git fetch --unshallow is needed the first time because ./build --download-dependencies only does a shallow clone of the Linux kernel to save space and time, see also: https://stackoverflow.com/questions/6802145/how-to-convert-a-git-shallow-clone-to-a-full-clone
The --linux-build-id option should be passed to all scripts that support it, much like --arch for the CPU architecture, e.g. to step debug:
./run-gdb --linux-build-id v4.16
To run both kernels simultaneously, one on each QEMU instance, see: Section 38.12, “Simultaneous runs”.
You can also build Kernel modules against a specific prebuilt kernel with:
./build-modules --linux-build-id v4.16
This will then allow you to insmod the kernel modules on your newly built kernel.
Note that for this build to work the Linux kernel must remain checked out at the same version as it was built from, because the build dir which modules build against via the M= argument points to the absolute path of the Linux kernel source from which the headers are taken. For this reason, if you are going to be building kernel modules against a specific kernel version, it is a good idea to use a Linux worktree to ensure that the source for a build is always there.
38.13.1.1. Linux worktree
If you are working with multiple Linux versions at once, it can be helpful to have their source code checked out all the time, in particular if you are going to be GDB step debugging.
We have some automation for that. Suppose that you are also interested in the kernel v6.14.4. Then you could do:
git -C submodules/linux worktree add ../../data/wt/linux/v6.14.4 git -C data/wt/linux/v6.14.4 reset --hard v6.14.4
Then you can use a specific source for a specific Linux kernel build variants with:
./build-linux --linux-worktree v6.14.4 --linux-build-id v6.14.4 ./run --linux-build-id v6.14.4
38.13.2. QEMU build variants
Analogous to the Linux kernel build variants but with the --qemu-build-id option instead:
./build-qemu git -C "$(./getvar qemu_source_dir)" checkout v2.12.0 ./build-qemu --qemu-build-id v2.12.0 git -C "$(./getvar qemu_source_dir)" checkout - ./run ./run --qemu-build-id v2.12.0
38.13.3. gem5 build variants
Analogous to the Linux kernel build variants but with the --gem5-build-id option instead:
# Build master. ./build-gem5 # Build another branch. git -C "$(./getvar gem5_source_dir)" checkout some-branch ./build-gem5 --gem5-build-id some-branch # Restore master. git -C "$(./getvar gem5_source_dir)" checkout - # Run master. ./run --emulator gem5 # Run another branch. git -C "$(./getvar gem5_source_dir)" checkout some-branch ./run --gem5-build-id some-branch --emulator gem5
Don’t forget however that gem5 has Python scripts in its source code tree, and that those must match the source code of a given build.
Therefore, you can’t forget to checkout to the sources to that of the corresponding build before running, unless you explicitly tell gem5 to use a non-default source tree with gem5 worktree. This becomes inevitable when you want to launch multiple simultaneous runs at different checkouts.
38.13.3.1. gem5 worktree
--gem5-build-id goes a long way, but if you want to seamlessly switch between two gem5 tress without checking out multiple times, then --gem5-worktree is for you.
# Build gem5 at the revision in the gem5 submodule. ./build-gem5 # Create a branch at the same revision as the gem5 submodule. ./build-gem5 --gem5-worktree my-new-feature cd "$(./getvar --gem5-worktree my-new-feature)" vim create-bugs git add . git commit -m 'Created a bug' cd - ./build-gem5 --gem5-worktree my-new-feature # Run the submodule. ./run --emulator gem5 --run-id 0 &>/dev/null & # Run the branch the need to check out anything. # With --gem5-worktree, we can do both runs at the same time! ./run --emulator gem5 --gem5-worktree my-new-feature --run-id 1 &>/dev/null &
--gem5-worktree <worktree-id> automatically creates:
-
a Git worktree of gem5 if one didn’t exit yet for
<worktree-id> -
a separate build directory, exactly like
--gem5-build-id my-new-featurewould
We promise that the scripts sill never touch that worktree again once it has been created: it is now up to you to manage the code manually.
--gem5-worktree is required if you want to do multiple simultaneous runs of different gem5 versions, because each gem5 build needs to use the matching Python scripts inside the source tree.
The difference between --gem5-build-id and --gem5-worktree is that --gem5-build-id specifies only the gem5 build output directory, while --gem5-worktree specifies the source input directory.
Each Git worktree needs a branch name, and we append the wt/ prefix to the --gem5-worktree value, where wt stands for WorkTree. This is done to allow us to checkout to a test some-branch branch under submodules/gem5 and still use --gem5-worktree some-branch, without conflict for the worktree branch, which can only be checked out once.
38.13.3.2. gem5 private source trees
Suppose that you are working on a private fork of gem5, but you want to use this repository to develop it as well.
Simply adding your private repository as a remote to submodules/gem5 is dangerous, as you might forget and push your private work by mistake one day.
Even removing remotes is not safe enough, since git submodule update and other submodule commands can restore the old public remote.
Instead, we provide the following safer process.
First do a separate private clone of you private repository outside of this repository:
git clone https://my.private.repo.com/my-fork/gem5.git gem5-internal gem5_internal="$(pwd)/gem5-internal"
Next, when you want to build with the private repository, use the --gem5-build-dir and --gem5-source-dir argument to override our default gem5 source and build locations:
cd linux-kernel-module-cheat
./build-gem5 \
--gem5-build-dir "${gem5_internal}/build" \
--gem5-source-dir "$gem5_internal" \
;
./run-gem5 \
--gem5-build-dir "${gem5_internal}/build" \
--gem5-source-dir "$gem5_internal" \
;
With this setup, both your private gem5 source and build are safely kept outside of this public repository.
38.13.4. Buildroot build variants
Allows you to have multiple versions of the GCC toolchain or root filesystem.
Analogous to the Linux kernel build variants but with the --build-id option instead:
./build-buildroot git -C "$(./getvar buildroot_source_dir)" checkout 2018.05 ./build-buildroot --buildroot-build-id 2018.05 git -C "$(./getvar buildroot_source_dir)" checkout - ./run ./run --buildroot-build-id 2018.05
38.14. Optimization level of a build
The --optimization-level option is available on all build scripts and sets the given GCC `-`O optimization level where it has been implemented for guest binaries.
The default optimization level is -O0 to improve guest visibility.
To keep things sane, you generally want to create a separate build variant for each optimization level, e.g. to create an -O3 build:
./build-userland --optimization-level 3 --userland-build-id o3 ./run --userland userland/c/hello.c --userland-build-id o3
Note that for some guest content, there are hard technical challenges why we are not able to forward -O, notably the linux kernel: Disable kernel compiler optimizations.
Our emulators however are build with higher optimization levels by default otherwise running anything would be too unbearably slow.
Emulator builds are also controlled with other mechanisms instead of --optimization-level as explained at: Debug the emulator.
38.15. Directory structure
38.15.1. lkmc directory
lkmc/ contains sources and headers that are shared across kernel modules, userland and baremetal examples.
We chose this awkward name so that our includes will have an lkmc/ prefix.
Another option would have been to name it as includes/lkmc, but that would make paths longer, and we might want to store source code in that directory as well in the future.
38.15.1.1. Userland objects vs header-only
When factoring out functionality across userland examples, there are two main options:
-
use header-only implementations
-
use separate C files and link to separate objects.
The downsides of the header-only implementation are:
-
slower compilation time, especially for C++
-
cannot call C implementations from assembly files
The advantages of header-only implementations are:
-
easier to use, just
#includeand you are done, no need to modify build metadata.
As a result, we are currently using the following rule:
-
if something is only going to be used from C and not assembly, define it in a header which is easier to use
The slower compilation should be OK as long as split functionality amongst different headers and only include the required ones.
Also we don’t have a choice in the case of C++ template, which must stay in headers.
-
if the functionality will be called from assembly, then we don’t have a choice, and must add it to a separate source file and link against it.
38.15.2. buildroot_packages directory
Source: buildroot_packages/.
Every directory inside it is a Buildroot package.
Those packages get automatically added to Buildroot’s BR2_EXTERNAL, so all you need to do is to turn them on during build, e.g.:
./build-buildroot --config 'BR2_PACKAGE_SAMPLE_PACKAGE=y'
then test it out with:
./run --eval-after '/sample_package.out'
and you should see:
hello sample_package
You can force a rebuild with:
./build-buildroot --config 'BR2_PACKAGE_SAMPLE_PACKAGE=y' -- sample_package-reconfigure
Buildroot packages are convenient, but in general, if a package if very important to you, but not really mergeable back to Buildroot, you might want to just use a custom build script for it, and point it to the Buildroot toolchain, and then use BR2_ROOTFS_OVERLAY, much like we do for Userland setup.
A custom build script can give you more flexibility: e.g. the package can be made work with other root filesystems more easily, have better 9P support, and rebuild faster as it evades some Buildroot boilerplate.
38.15.2.1. kernel_modules buildroot package
An example of how to use kernel modules in Buildroot.
Usage:
./build-buildroot \ --build-linux \ --config 'BR2_PACKAGE_KERNEL_MODULES=y' \ --no-overlay \ -- \ kernel_modules-reconfigure \ ;
Then test one of the modules with:
./run --buildroot-linux --eval-after 'modprobe buildroot_hello'
As you have just seen, this sets up everything so that modprobe can correctly find the module.
./build-buildroot --build-linux and ./run --buildroot-linux are needed because the Buildroot kernel modules must use the Buildroot Linux kernel at build and run time, see also: Buildroot vanilla kernel.
The --no-overlay is required otherwise our modules.order generated by ./build-linux and installed with BR2_ROOTFS_OVERLAY overwrites the Buildroot generated one.
38.15.3. patches directory
38.15.3.1. patches/global directory
Has the following structure:
package-name/00001-do-something.patch
The patches are then applied to the corresponding packages before build.
Uses BR2_GLOBAL_PATCH_DIR.
38.15.3.2. patches/manual directory
Patches in this directory are never applied automatically: it is up to users to manually apply them before usage following the instructions in this documentation.
These are typically patches that don’t contain fundamental functionality, so we don’t feel like forking the target repos.
38.15.4. rootfs_overlay
Source: rootfs_overlay.
We use this directory for:
-
customized configuration files
-
userland module test scripts that don’t need to be compiled.
Contrast this with C examples that need compilation.
This directory is copied into the target filesystem by:
./copy-overlay ./build-buildroot
Source: copy-overlay
Build Buildroot is required for the same reason as described at: Section 2.2.2.2, “Your first kernel module hack”.
However, since the rootfs_overlay directory does not require compilation, unlike say kernel modules, we also make it 9P available to the guest directly even without ./copy-overlay at:
ls /mnt/9p/rootfs_overlay
This way you can just hack away the scripts and try them out immediately without any further operations.
38.15.4.1. out_rootfs_overlay_dir
This path can be found with:
./getvar out_rootfs_overlay_dir
This output directory contains all the files that LKMC will put inside the final image, including for example:
-
Userland content that needs to be compiled
-
rootfs_overlay content that gets put inside the image as is
LKMC first collects all the files that it will dump into the guest there, and then in the very last step dumps everything into the final image.
In Buildroot, this is done by pointing BR2_ROOTFS_OVERLAY to that directory, which is documented at: https://buildroot.org/downloads/manual/manual.html#rootfs-custom
This does not include native image modification mechanisms such as Buildroot packages, which we let Buildroot itself manage.
38.15.4.1.1. disk_image_2
A squashfs of out_rootfs_overlay_dir that gets passed as the second argument.
Especially useful with gem5 as a way to gem5 checkpoint restore and run a different script via Secondary disk since setting up gem5 9P is slightly laborious.
38.15.5. lkmc.c
The files:
contain common C function helpers that can be used both in userland and baremetal. Oh, the infinite joys of Newlib.
Those files also contain arch specific helpers under ifdefs like:
#if defined(__aarch64__)
We try to keep as much as possible in those files. It bloats builds a little, but just makes everything simpler to understand.
Link with lkmc.o is enabled with the path_properties.py
'extra_objs_lkmc_common': False,
38.15.6. lkmc_home
lkmc_home refers to the target base directory in which we put all our custom built stuff, such as userland executables and kernel modules.
The current value can be found with:
./getvar guest_lkmc_home
In the past, we used to dump everything into the root filesystem, but as the userland structure got more complex with subfolders, we decided that the risk of conflicting with important root files was becoming too great.
To save you from typing that path every time, we have made our most common commands cd into that directory by default for you, e.g.:
-
interactive shells
cdthere through BusyBox shell initrc files -
--evaland--eval-afterthrough Replace init and Run command at the end of BusyBox init
Whenever a relative path is used inside a guest sample command, e.g. insmod hello.ko or ./hello.out, it means that the path lives in lkmc_home unless stated otherwise.
38.15.7. path_properties.py
In order to build and run each userland and baremetal example properly, we need per-file metadata such as compiler flags and required number of cores.
This data is stored is stored in path_properties.py at path_properties_tuples.
Maybe we should embed it magically into source files directories to make it easier to see? But one big Python dict was easier to implement so we started like this. And it allows factoring chunks out easily.
The format is as follows:
'path_component': (
{'property': value},
{
'child_path_component':
{
{'child_property': },
{}
}
}
)
and as a shortcut, paths that don’t have any children can be written directly as:
'path_component': {'property': value}
Properties of parent directories apply to all children.
Lists coming from parent directories are extended instead of overwritten by children, this is especially useful for C compiler flags.
To quickly determine which properties a path has, you can use getprops, e.g.:
./getprops userland/c/hello.c
which outputs values such as:
allowed_archs=None allowed_emulators=None arm_aarch32=False arm_sve=False baremetal=True
38.15.8. rand_check.out
Print out several parameters that normally change randomly from boot to boot:
./run --eval-after './linux/rand_check.out;./linux/poweroff.out'
Source: userland/linux/rand_check.c
This can be used to check the determinism of:
38.16. Test this repo
38.16.1. Automated tests
Run almost all tests:
./build-test --all-archs --all-emulators --size 3 && \ ./test --size 3 echo $?
should output 0.
Sources:
The test script runs several different types of tests, which can also be run separately as explained at:
test does not all possible tests, because there are too many possible variations and that would take forever. The rationale is the same as for ./build all and is explained in ./build --help.
38.16.1.1. Test arch and emulator selection
You can select multiple archs and emulators of interest, as for an other command, with:
./test-executables \ --arch x86_64 \ --arch aarch64 \ --emulator gem5 \ --emulator qemu \ ;
You can also test all supported archs and emulators with:
./test-executables \ --all-archs \ --all-emulators \ ;
This command would run the test four times, using x86_64 and aarch64 with both gem5 and QEMU.
Without those flags, it defaults to just running the default arch and emulator once: x86_64 and qemu.
38.16.1.2. Quit on fail
By default, continue running even after the first failure happens, and they show a summary at the end.
You can make them exit immediately with the --no-quit-on-fail option, e.g.:
./test-executables --quit-on-fail
38.16.1.3. Test userland in full system
TODO: we really need a mechanism to automatically generate the test list automatically e.g. based on path_properties.py, currently there are many tests missing, and we have to add everything manually which is very annoying.
We could just generate it on the fly on the host, and forward it to guest through CLI arguments.
Run all userland tests from inside full system simulation (i.e. not User mode simulation):
./test-userland-full-system
This includes, in particular, userland programs that test the kernel modules, which cannot be tested in user mode simulation.
Basically just boots and runs: rootfs_overlay/lkmc/test_all.sh
Failure is detected by looking for the Magic failure string
Most userland programs that don’t rely on kernel modules can also be tested in user mode simulation as explained at: Section 11.2, “User mode tests”.
38.16.1.4. GDB tests
We have some pexpect automated tests for GDB for both userland and baremetal programs!
Run the userland tests:
./build --all-archs test-gdb && \ ./test-gdb --all-archs --all-emulators
Run the baremetal tests instead:
./test-gdb --all-archs --all-emulators --mode baremetal
Sources:
If a test fails, re-run the test commands manually and use --verbose to understand what happened:
./run --arch arm --background --baremetal baremetal/c/add.c --gdb-wait & ./run-gdb --arch arm --baremetal baremetal/c/add.c --verbose -- main
and possibly repeat the GDB steps manually with the usual:
./run-gdb --arch arm --baremetal baremetal/c/add.c --no-continue --verbose
To debug GDB problems on gem5, you might want to enable the following tracing options:
./run \ --arch arm \ --baremetal baremetal/c/add.c \ --gdb-wait \ --trace GDBRecv,GDBSend \ --trace-stdout \ ;
38.16.1.5. Magic failure string
We do not know of any way to set the emulator exit status in QEMU arm full system.
For other arch / emulator combinations, we know how to do it:
-
aarch64: aarch64 semihosting supports exit status
-
gem5: m5 fail works on all archs
-
user mode: QEMU forwards exit status, for gem5 we do some log parsing as described at: Section 11.7.2, “gem5 syscall emulation exit status”
Since we can’t do it for QEMU arm, the only reliable solution is to just parse the guest serial output for a magic failure string to check if tests failed.
Our run scripts parse the serial output looking for a line line containing only exactly the magic regular expression:
lkmc_exit_status_(\d+)
and then exit with the given regular expression, e.g.:
./run --arch aarch64 baremetal/return2.c echo $?
should output:
2
This magic output string is notably generated by:
-
rootfs_overlay/lkmc/test_fail.sh, which is used by Test userland in full system
-
the
exit()baremetal function whenstatus != 1.Unfortunately the only way we found to set this up was with
on_exit: https://github.com/cirosantilli/linux-kernel-module-cheat/issues/59.Trying to patch
_exitdirectly fails since at that point some de-initialization has already happened which prevents the print.So setup this
on_exitautomatically from all our Baremetal bootloaders, so it just works automatically for the examples that use the bootloaders: https://stackoverflow.com/questions/44097610/pass-parameter-to-atexit/49659697#49659697The following examples end up testing that our setup is working:
Beware that on Linux kernel simulations, you cannot even echo that string from userland, since userland stdout shows up on the serial.
38.16.2. Non-automated tests
38.16.2.1. Test GDB Linux kernel
For the Linux kernel, do the following manual tests for now.
Shell 1:
./run --gdb-wait
Shell 2:
./run-gdb start_kernel
Should break GDB at start_kernel.
Then proceed to do the following tests:
-
./count.shandbreak __x64_sys_write -
insmod timer.koandbreak lkmc_timer_callback
38.16.2.2. Test the Internet
You should also test that the Internet works:
./run --arch x86_64 --kernel-cli '- lkmc_eval="ifup -a;wget -S google.com;poweroff;"'
38.16.2.3. CLI script tests
build-userland and test-executables have a wide variety of target selection modes, and it was hard to keep them all working without some tests:
38.17. Bisection
When updating the Linux kernel, QEMU and gem5, things sometimes break.
However, for many types of crashes, it is trivial to bisect down to the offending commit, in particular because we can make QEMU and gem5 exit with status 1 on kernel panic as mentioned at: Section 17.6.1.3, “Exit emulator on panic”.
For example, when updating from QEMU v2.12.0 to v3.0.0-rc3, the Linux kernel boot started to panic for arm.
We then bisected it as explained at: https://stackoverflow.com/questions/4713088/how-to-use-git-bisect/22592593#22592593 with the bisect-qemu-linux-boot script:
root_dir="$(pwd)"
cd "$(./getvar qemu_source_dir)"
git bisect start
# Check that our test script fails on v3.0.0-rc3 as expected, and mark it as bad.
"${root_dir}/bisect-qemu-linux-boot"
# Should output 1.
echo #?
git bisect bad
# Same for the good end.
git checkout v2.12.0
"${root_dir}/bisect-qemu-linux-boot"
# Should output 0.
echo #?
git bisect good
# This leaves us at the offending commit.
git bisect run "${root_dir}/bisect-qemu-linux-boot"
# Clean up after the bisection.
git bisect reset
git submodule update
"${root_dir}/build-qemu" --clean --qemu-build-id bisect
Other bisection helpers include:
38.18. Update a forked submodule
This is a template update procedure for submodules for which we have some patches on on top of mainline.
This example is based on the Linux kernel, for which we used to have patches, but have since moved to mainline:
# Last point before out patches.
last_mainline_revision=v4.15
next_mainline_revision=v4.16
cd "$(./getvar linux_source_dir)"
# Create a branch before the rebase in case things go wrong.
git checkout -b "lkmc-${last_mainline_revision}"
git remote set-url origin git@github.com:cirosantilli/linux.git
git push
git checkout master
git fetch up
git rebase --onto "$next_mainline_revision" "$last_mainline_revision"
# And update the README to show off.
git commit -m "linux: update to ${next_mainline_revision}"
38.19. Release
38.19.1. Release procedure
Ensure that the Automated tests are passing on a clean build:
mv out out.bak ./build-test --size 3 && ./test --size 3
The ./build-test command builds a superset of what will be downloaded which also tests other things we would like to be working on the release. For the minimal build to generate the files to be uploaded, see: Section 38.19.2, “release-zip”
The clean build is necessary as it generates clean images since it is not possible to remove Buildroot packages
Run all tests in Non-automated tests just QEMU x86_64 and QEMU aarch64.
TODO: not working currently, so skipped: Ensure that the benchmarks look fine:
./bench-all -A
Create a release candidate and upload it:
git tag -a -m '' v3.0-rc1 git push --follow-tags ./release-zip --all-archs # export LKMC_GITHUB_TOKEN=<your-token> ./release-upload
Now let’s do an out-of-box testing for the release candidate:
cd .. git clone https://github.com/cirosantilli/linux-kernel-module-cheat linux-kernel-module-cheat-release cd linux-kernel-module-cheat-release
Test Prebuilt setup.
Clean up, and re-start from scratch:
cd .. rm -rf linux-kernel-module-cheat-release git clone https://github.com/cirosantilli/linux-kernel-module-cheat linux-kernel-module-cheat-release cd linux-kernel-module-cheat-release
Go through all the other Getting started sections in order.
Once everything looks fine, publish the release with:
git tag -a v3.0 # Describe the release int the tag message. git push --follow-tags ./release-zip --all-archs # export LKMC_GITHUB_TOKEN=<your-token> ./release-upload
38.19.2. release-zip
Create a zip containing all files required for Prebuilt setup:
./build --all-archs release && ./release-zip --all-archs
Source: release-zip
This generates a zip file:
echo "$(./getvar release_zip_file)"
which you can then upload somewhere.
38.19.3. release-upload
After:
-
running release-zip
-
creating and pushing a tag to GitHub
you can upload the release to GitHub automatically with:
# export LKMC_GITHUB_TOKEN=<your-token> ./release-upload
Source: release-upload
The HEAD of the local repository must be on top of a tag that has been pushed for this to work.
Create LKMC_GITHUB_TOKEN under: https://github.com/settings/tokens/new and save it to your .bashrc.
The implementation of this script is described at:
38.20. Design rationale
38.20.1. Design goals
This project was created to help me understand, modify and test low level system components by using system simulators.
System simulators are cool compared to real hardware because they are:
-
free
-
make experiments highly reproducible
-
give full visibility to the system: you can inspect any byte in memory, or the state of any hardware register. The laws of physics sometimes get in the way when doing that for real hardware.
The current components we focus the most on are:
-
Linux kernel and Linux kernel modules
-
Buildroot. We use and therefore document, a large part of its feature set.
The following components are not covered, but they would also benefit from this setup, and it shouldn’t be hard to add them:
-
C standard libraries
-
compilers. Project idea: add a new instruction to x86, then hack up GCC to actually use it, and make a C program that generates it.
The design goals are to provide setups that are:
-
highly automated: "just works"
-
thoroughly documented: you know what "just works" means
-
can be fully built from source: to give visibility and allow modifications
-
can also use prebuilt binaries as much as possible: in case you are lazy or unable to build from source
We aim to make a documentation that contains a very high runnable example / theory bullshit ratio.
Having at least one example per section is ideal, and it should be the very first thing in the section if possible.
38.20.2. Setup trade-offs
The trade-offs between the different setups are basically a balance between:
-
speed ans size: how long and how much disk space do the build and run take?
-
visibility: can you GDB step debug everything and read source code?
-
modifiability: can you modify the source code and rebuild a modified version?
-
portability: does it work on a Windows host? Could it ever?
-
accuracy: how accurate does the simulation represent real hardware?
-
compatibility: how likely is is that all the components will work well together: emulator, compiler, kernel, standard library, …
-
guest software availability: how wide is your choice of easily installed guest software packages? See also: Section 38.20.4, “Linux distro choice”
38.20.3. Resource tradeoff guidelines
Choosing which features go into our default builds means making tradeoffs, here are our guidelines:
-
keep the root filesystem as tiny as possible to make Prebuilt setup small: only add BusyBox to have a small interactive system.
It is easy to add new packages once you have the toolchain, and if you don’t there are infinitely many packages to cover and we can’t cover them all.
-
enable every feature possible on the toolchain (GCC, Binutils), because changes imply Buildroot rebuilds
-
runtime is sacred. Faster systems are:
-
easier to understand
-
run faster, which is specially for gem5 which is slow
Runtime basically just comes down to how we configure the Linux kernel, since in the root filesystem all that matters is
init=, and that is easy to control.One possibility we could play with is to build loadable modules instead of built-in modules to reduce runtime, but make it easier to get started with the modules.
-
In order to learn how to measure some of those aspects, see: Section 35, “Benchmark this repo”.
38.20.4. Linux distro choice
We haven’t found the ultimate distro yet, here is a summary table of trade-offs that we care about: Table 8, “Comparison of Linux distros for usage in this repository”.
| Distro | Packages in single Git tree | Git tracked docs | Cross build without QEMU | Prebuilt downloads | Number of packages |
|---|---|---|---|---|---|
Buildroot 2018.05 |
y |
y |
y |
n |
2k (1) |
Ubuntu 18.04 |
n |
n |
n |
y |
50k (3) |
Yocto 2.5 (8) |
? |
y (5) |
? |
y (6) |
400 (7) |
Alpine Linux 3.8.0 |
y |
n (1) |
? |
y |
2000 (4) |
-
(1): Wiki… https://wiki.alpinelinux.org/wiki/Main_Page
-
(2):
ls packages | wc -
(3): https://askubuntu.com/questions/120630/how-many-packages-are-in-the-main-repository
-
(4):
ls main community non-free | wc -
(5): yes, but on a separate Git tree… https://git.yoctoproject.org/cgit/cgit.cgi/yocto-docs/
-
(6): yes, but the initial Poky build / download still took 5 hours on 38Mbps internet, and QEMU failed to boot at the end… https://bugzilla.yoctoproject.org/show_bug.cgi?id=12953
-
(7):
ls recipes-* | wc -
(8): Poky reference system: http://git.yoctoproject.org/cgit/cgit.cgi/poky
Other interesting possibilities that I haven’t evaluated well:
-
NixOS https://nixos.org/ Seems to support full build from source well. Not much cross compilation information however.
-
Gentoo https://en.wikipedia.org/wiki/Gentoo_Linux Seems to support full build from source well.
38.21. Soft topics
38.21.1. Fairy tale
Once upon a time, there was a boy called Linus.
Linus made a super fun toy, and since he was not very humble, decided to call it Linux.
Linux was an awesome toy, but it had one big problem: it was very difficult to learn how to play with it!
As a result, only some weird kids who were very bored ended up playing with Linux, and everyone thought those kids were very cool, in their own weird way.
One day, a mysterious new kid called Ciro tried to play with Linux, and like many before him, got very frustrated, and gave up.
A few years later, Ciro had grown up a bit, and by chance came across a very cool toy made by the boy Petazzoni and his gang: it was called Buildroot.
Ciro noticed that if you used Buildroot together with Linux, and Linux suddenly became very fun to play with!
So Ciro decided to explain to as many kids as possible how to use Buildroot to play with Linux.
And so everyone was happy. Except some of the old weird kernel hackers who wanted to keep their mystique, but so be it.
THE END
38.22. Bibliography
Runnable stuff:
-
https://lwn.net/Kernel/LDD3/ the best book, but outdated. Updated source: https://github.com/martinezjavier/ldd3 But examples non-minimal and take too much brain power to understand.
-
https://github.com/satoru-takeuchi/elkdat manual build process without Buildroot, very few and simple kernel modules. But it seem ktest + QEMU working, which is awesome.
./testthere patches ktest config dynamically based on CLI! Maybe we should just steal it since GPL licensed. -
https://github.com/tinyclub/linux-lab Buildroot based, no kernel modules?
-
https://github.com/linux-kernel-labs Yocto based, source inside a kernel fork subdir: https://github.com/linux-kernel-labs/linux/tree/f08b9e4238dfc612a9d019e3705bd906930057fc/tools/labs which the author would like to upstream https://www.reddit.com/r/programming/comments/79w2q9/linux_device_driver_labs_the_linux_kernel/dp6of43/
-
Android AOSP: https://stackoverflow.com/questions/1809774/how-to-compile-the-android-aosp-kernel-and-test-it-with-the-android-emulator/48310014#48310014 AOSP is basically a uber bloated Buildroot (2 hours build vs 30 minutes), Android is Linux based, and QEMU is the emulator backend. These instructions might work for debugging the kernel: https://github.com/Fuzion24/AndroidKernelExploitationPlayground
-
https://github.com/s-matyukevich/raspberry-pi-os Does both an OS from scratch, and annotates the corresponding kernel source code. For RPI3, no QEMU support: https://github.com/s-matyukevich/raspberry-pi-os/issues/8
-
https://github.com/pw4ever/linux-kernel-hacking-helper as of bd9952127e7eda643cbb6cb4c51ad7b5b224f438, Bash, Arch Linux rootfs
-
https://github.com/MichielDerhaeg/build-linux untested. Manually builds musl and BusyBox, no Buildroot. Seems to use host packaged toolchain and tested on x86_64 only. Might contain a minimized kernel config.
-
https://eli.thegreenplace.net and the accompanying code: https://github.com/eliben/code-for-blog
Theory:
-
http://cs241.cs.illinois.edu/coursebook/index.html "CS 241: System Programming" from the University of Illinois at Urbana-Champaign. Has a PDF, Tex source at: https://github.com/illinois-cs241/coursebook TODO any runnable code?
-
https://github.com/0xAX/linux-insides wait, how come they have 10x more starts as this repo? :-) Just kidding, awesome effort.
-
http://nairobi-embedded.org you will fall here a lot when you start popping the hard QEMU Google queries. They have covered everything we do here basically, but with a more manual approach, while this repo automates everything.
I couldn’t find the markup source code for the tutorials, and as a result when the domain went down in May 2018, you have to use http://web.archive.org/ to see the pages…
-
https://balau82.wordpress.com awesome low level resource
-
https://rwmj.wordpress.com/ awesome red hatter
Awesome lists: